Par | Technologie sans froid
Le 24 avril, une étape importante a été franchie dans le domaine des grands modèles en Chine. La version préliminaire de DeepSeek-V4 a été officiellement lancée et simultanément rendue open source, faisant de la gestion de contextes ultra-longs de 1 million de mots (1M) une configuration standard des services officiels.
Il y a un an, cette capacité de traitement de texte long était encore réservée aux grands groupes étrangers, derrière des paywalls professionnels. Aujourd'hui, elle est mise à disposition de la communauté open source, devenant une infrastructure que les développeurs peuvent utiliser à volonté. Pour les développeurs qui travaillent tard sur de longues bases de code ou des contrats juridiques complexes, c'est une excellente nouvelle.
Mais derrière cette mise à disposition technologique, le communiqué officiel comporte un aveu très sobre : « En raison de limitations en matière de capacité de calcul haut de gamme, le débit de service de DeepSeek-V4-Pro est actuellement très limité. »
Pour ceux qui ont l'habitude des présentations où les fabricants vantent leurs réserves de calcul, cette franchise dégage une rare froideur.
Dans la seconde moitié de la course aux grands modèles, le secteur sait très bien qui dispose de quelles ressources matérielles haut de gamme. Plutôt que de maintenir une course aux paramètres, il vaut mieux exposer la réalité industrielle. La manœuvre de DeepSeek abandonne en fait l'obsession des simples benchmarks et trouve un compromis entre les avancées algorithmiques fondamentales, l'écosystème hétérogène de calcul encore en développement en Chine, et les réalités commerciales des entreprises, pour concilier progression technologique et contraintes matérielles.
L'industrie chinoise de l'IA se débarrasse de son habit early-stage de gaspillage d'argent aveugle pour entrer dans une ère extrêmement réaliste de « livre de compte de la capacité de calcul ».
Comment équilibrer le livre de compte de la version Pro ?
Examinons de plus près ce V4-Pro au débit explicitement limité. En tant que fleuron de l'écosystème, le V4-Pro possède un total de paramètres colossal de 1,6 T, mais n'en active que 49B lors de l'inférence. Cette conception extrêmement clairsemée n'est pas un modèle vitrine ; sous le contrôle rigoureux des lignes de production réelles, sa base technologique présente une robustesse défensive remarquable.
La capacité à gérer du code complexe et des raisonnements logiques est la pierre de touche pour déterminer si un grand modèle peut vraiment entrer dans les maillons essentiels de la production. Dans l'environnement d'évaluation Agentic Coding (code agent intelligent), les performances pratiques du V4-Pro se placent solidement dans le premier tier des modèles open source actuels.
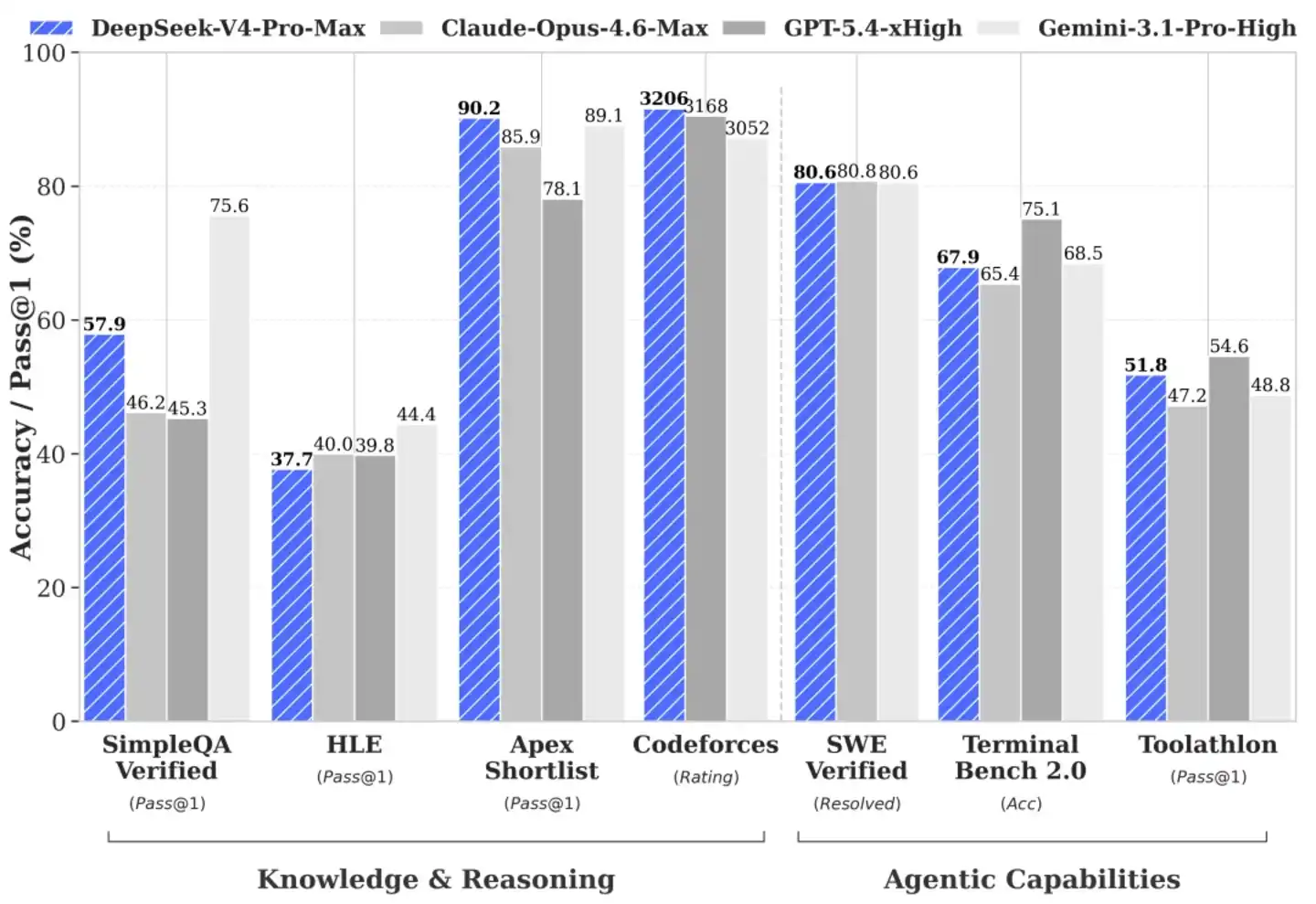
DeepSeek l'a déjà intégré dans sa propre chaîne de production de code, en faisant un outil de productivité indispensable pour ses ingénieurs de première ligne. Les retours des chercheurs indiquent que son expérience de génération et de correction de code est supérieure à Sonnet 4.5, et se rapproche de celle d'Opus 4.6 dans les scénarios ne nécessitant pas une réflexion profonde, bien qu'un écart subsiste avec le mode de raisonnement d'Opus 4.6.
Derrière ces performances en conditions réelles se trouve une exploration extrême de la profondeur algorithmique par l'équipe de R&D. Dans les évaluations des connaissances mondiales, qui testent la qualité du nettoyage des données de pré-entraînement et la densité des connaissances, le V4-Pro devance la plupart des modèles open source existants, n'étant actuellement légèrement inférieur qu'au modèle propriétaire de pointe Gemini-Pro-3.1. Pour les évaluations en mathématiques, STEM (Sciences, Technologie, Ingénierie, Mathématiques) et code de type compétition, il a obtenu son ticket pour rivaliser avec les grands acteurs propriétaires mondiaux.
Obtenir une telle puissance ne repose clairement pas sur une simple accumulation de cartes de calcul. Les équipes chinoises savent pertinemment qu'il n'est pas réaliste de rivaliser en termes de réserves de cartes graphiques haut de gamme. La capacité du V4-Pro à traiter des contextes ultra-longs de 1M avec une mémoire limitée est soutenue en profondeur par une refonte du mécanisme d'attention par l'équipe de R&D. Ils ont mis en œuvre un nouveau schéma de compression de l'attention, effectuant une compression intense au niveau des tokens, couplée à leur technologie signature d'attention clairsemée DSA (DeepSeek Sparse Attention).
Cette voie technologique originale, ajoutée à l'introduction pionnière d'une fenêtre glissante (KV Cache sliding window) et d'algorithmes de compression, contrôle efficacement les coûts de calcul et l'occupation mémoire induits par le traitement de longues séquences. Pour permettre aux développeurs d'exploiter réellement ces capacités dans leurs activités, l'équipe de R&D a spécifiquement adapté en profondeur des outils d'agent principaux comme Claude Code et OpenClaw.
La documentation technique indique même explicitement que les développeurs peuvent directement activer le mode de raisonnement (thinking mode) pour les tâches complexes, en réglant le paramètre reasoning_effort sur max. Cette optimisation systémique réalisée avec des ressources de calcul limitées démontre précisément au secteur que, même avec une capacité de calcul haut de gamme contrainte, les équipes locales peuvent encore élargir les limites de performance des modèles grâce à une conception architecturale native.
Les 13B activés, un seuil pour qui ?
Ceux qui se focalisent sur les goulots d'étranglement du débit de la version Pro négligent souvent le point d'appui commercial que DeepSeek cache en arrière-plan : la version Flash. Certains dans le secteur estiment qu'il ne s'agit que d'un produit de compromis dû à la pénurie de capacité de calcul, une opinion qui sous-estime clairement la réflexion à long terme de l'équipe de direction. Il s'agit d'un positionnement pragmatique sur l'écosystème de masse, soigneusement calculé en termes de coûts.

Selon les informations divulguées dans le code d'adaptation public, le nombre total de paramètres de la version Flash reste à un niveau important de 284B, mais ses paramètres activés sont précisément calibrés à 13B.
13B, dans un contexte où les concurrents tentent de pousser les paramètres vers des échelles de billions, peut sembler peu impressionnant. Mais cela reflète justement la logique économique de l'architecture Mixture of Experts (MoE) dans le déploiement commercial : le nombre total de paramètres détermine l'étendue des connaissances du modèle, tandis que les paramètres activés déterminent directement à chaque appel d'API les coûts électriques et la bande passante mémoire que le serveur doit engager.
Maintenir le volume d'activation à 13B extrait directement les grands modèles des centres de calcul intelligents ultra-coûteux. Ses besoins en mémoire graphique par carte et en pic de calcul sont très modestes. Les tests pratiques montrent que la version Flash maintient une vitesse de réponse et un taux de précision stables face à des tâches quotidiennes simples mais massives et à haute fréquence, sans baisse notable de ses capacités de raisonnement général sous-jacentes. Pour les nombreux petits développeurs et entreprises de la longue traîne qui doivent traiter des milliers d'appels d'API par jour, c'est véritablement un outil de production abordable et utilisable.
La logique industrielle plus profonde réside dans le fait que les puces de calcul hétérogènes grand public en Chine sont encore en phase de rattrapage en termes de performances absolues par carte. Les systèmes de calcul supportant une activation complète heurtent facilement le mur de la mémoire, entraînant une faible efficacité opérationnelle ; mais face à la version Flash avec seulement 13B activés, ces puces peuvent fonctionner fluidement avec une consommation énergétique faible à moyenne.
Cette étape de DeepSeek valorise les nombreuses ressources de calcul low-end et mid-range inutilisées en Chine, offrant un terrain d'essai parfaitement adapté aux puces nationales qui ont un besoin urgent de scénarios de déploiement. Cette logique de construction d'infrastructure inclusive vers le bas est bien plus en phase avec la réalité commerciale actuelle que le simple fait de grimper dans les classements des divers benchmarks.
Les puces chinoises sont-elles prêtes ?
Ce qui a suscité de vives discussions dans le secteur suite à cette annonce, c'est l'étiquette « déploiement full-stack national » affichée. Pendant longtemps, un décalage a existé entre les entreprises d'algorithmes et les fabricants de puces chinoises : les éditeurs de modèles craignaient qu'un écosystème matériel immature ne ralentisse le développement, tandis que les fabricants de puces manquaient de modèles de pointe pour un réglage fin en profondeur. Cette fois, l'impasse est rompue.
Huawei Computing a rapidement annoncé que toute la gamme de produits Ascend Super Node supportait pleinement le nouveau modèle. D'un point de vue technique, les puces Ascend sous-jacentes, s'appuyant sur la fusion des kernels (fusion kernel) et la technologie multi-flux parallèles, réduisent efficacement les frais généraux de calcul du système, stabilisant ainsi les performances d'inférence dans les scénarios de texte long. Cambricon a également rapidement réalisé une adaptation Day 0 et open-sourcé le code bas niveau. Haiguang DCU a simultanément annoncé avoir bouclé la boucle.
Mais il faut percer la surface de cette prospérité écologique pour examiner les résistances réelles rencontrées lors de la jonction logiciel-matériel dans les salles de serveurs. Prenons l'exemple de la puce Ascend 950系列. Selon des sources sectorielles, cette puce dispose de 112 GB de HBM (mémoire à bande passante élevée) autonome, d'une bande passante de 1,4 TB/s, et d'une consommation par carte atteignant 600 watts. Dans des précisions d'inférence spécifiques (comme FP4), sa puissance de calcul par carte affiche des performances de données très solides, atteignant 2,87 fois celle du Nvidia H20. Mais dans les plages de précision d'entraînement général plus exigeantes comme FP16 ou FP32, le fossé de performance entre le matériel chinois et Nvidia persiste.
De plus, la prétendue « adaptation Day 0 » est encore loin d'une exploitation professionnelle enterprise sans perte, devant surmonter les coûts cachés liés à l'opacité de la chaîne d'approvisionnement. Les normes de connexion haute vitesse du matériel Super Node sont extrêmement fermées, la circulation des composants clés ressemblant à une boîte noire informationnelle. Ces barrières à l'approvisionnement complexifient sans aucun doute le déploiement et la maintenance à grande échelle des systèmes de calcul.
Parallèlement, ce système dépend fortement pour le moment des gros contrats groupés de quelques grandes institutions nationales. Le manque de commandes sur le marché international signifie que cette bataille pour percer dans le calcul ne peut se jouer qu'en circuit interne. Cette boucle commerciale unique signifie que l'efficacité opérationnelle de l'ensemble du système logiciel-matériel a un besoin urgent d'être trempée dans des environnements commerciaux plus diversifiés.
La tension dans la montée en puissance de la production de calcul haut de gamme conduit directement DeepSeek à reconnaître dans son communiqué que pour une baisse significative du prix de la version Pro, il faudra attendre la mise sur le marché en volume des Super Nodes dans le second semestre. Les grands modèles et les puces chinoises ont certes réalisé un engrenage physique préliminaire, mais avec l'écart technologique et les contraintes de la chaîne d'approvisionnement, cette course effrénée et blessée est précisément la coupe transversale la plus réaliste de la survie de l'écosystème de calcul national.
Si les gens partent, la technologie peut-elle encore tourner ?
En revenant à la concurrence commerciale réelle, l'avènement de DeepSeek-V4 constitue une défense stratégique extrêmement précise. Durant les derniers mois, cette entreprise a constamment sous pression. Le segment B2C est devenu une mer rouge, les acteurs leaders utilisant des masses de capitaux pour des déploiements intensifs. Les données de QuestMobile présentent une tendance concurrentielle claire : fin mars 2026, Doubao (豆包) atteignait 345 millions d'utilisateurs actifs mensuels (MAU), Qianwen (千问) 166 millions, et DeepSeek maintenait son cœur de métier avec 127 millions.
La concurrence externe pour le trafic est féroce, et l'équipe technique interne fait face à des tests de mobilité. La concurrence pour débaucher est acharnée dans le secteur, avec des départs successifs de personnel clé de plusieurs lignes métier. Selon les CV publics et les informations du secteur, l'auteur principal de la première génération de grands modèles de langage a confirmé avoir rejoint Tencent, un contributeur clé de V3 est parti chez Xiaomi, un chercheur principal de R1 a rejoint ByteDance, et les forces clés dans le domaine multimodal ont également confirmé de nouvelles destinations. Selon des rumeurs sectorières, Wei Haoran (魏浩然), auteur principal dans le domaine OCR, aurait également démissionné.
Les changements parmi les membres clés de la R&D ne manqueront pas de susciter un examen strict de leur capacité d'innovation future : la capacité d'innovation de l'architecture sous-jacente de cette entreprise basée sur la technologie sera-t-elle affectée ?
À ce stade, la publication de la version préliminaire de V4 constitue la réponse la plus directe. Elle démontre au marché que l'entreprise a établi un pipeline de R&D systématique capable de résister aux risques. Même face à des ajustements structurels du personnel, la logique de son évolution technologique peut continuer à fonctionner avec précision. Cette résilience organisationnelle basée sur un système d'ingénierie a rapidement obtenu un retour positif sur le marché capitalistique.
Récemment, DeepSeek aurait cherché à lever des fonds avec une valorisation d'au moins 10 milliards de dollars américains, afin de reconstituer ses réserves. Selon des médias sectoriers citant des sources proches des négociations, des rumeurs de marché font état d'un géant internet de premier plan prévoyant d'injecter des capitaux, ce qui pourrait faire monter la valorisation de ce tour de table. Si cette transaction se concrait, elle réécrirait le record de valorisation dans la course aux grands modèles en Chine, dépassant la performance précédente de MoonShot (月之暗面). En présentant des résultats tangibles avec le contexte d'un million de mots et l'adaptation full-stack nationale durant une phase clé de négociations de financement, la direction pose une pièce rationnelle pour stabiliser le jeu stratégique et répondre aux doutes externes.
Pour conclure
Dans le contexte commercial technologique où les concepts évoluent fréquemment, les équipes愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意愿意极少数专注于 la construction d'infrastructures sous-jacentes. Le lancement de DeepSeek-V4 établit un ton pragmatique et froid pour la seconde moitié de la course aux grands modèles.
Face au goulot d'étranglement de la capacité de calcul, ils n'ont pas choisi de le masquer, mais ont exposé la réalité de l'offre et de la demande du matériel haut de gamme national au marché ; face aux besoins de déploiement de masse, ils ont utilisé la version Flash avec 13B activés pour offrir un espace de survie aux puces de calcul nationales encore en phase de rattrapage ; face à l'encerclement du trafic externe et à la concurrence pour les talents, ils ont répondu au niveau du secteur avec des capacités concrètes de traitement de texte long.
La citation des « Entretiens de Confucius » (Note : Correction, il s'agit en réalité d'une citation de Xunzi 《荀子》, comme indiqué ensuite) reprise par l'équipe officielle le jour du lancement est très significative : « Ne pas être séduit par la louange, ne pas être effrayé par la calomnie, suivre la voie et agir, se rectifier avec droiture. » (不诱于誉,不恐于诽,率道而行,端然正己。)
Le modèle peut être open source, mais la capacité de calcul n'est pas gratuite. Ce que DeepSeek a livré cette fois, ce n'est pas un modèle plus puissant, mais une solution sur la manière dont les capacités sont redistribuées une fois que la capacité de calcul devient une contrainte. Dans une réalité où la capacité de calcul est encore imparfaite, c'est peut-être la direction de l'évolution la plus proche de l'essence de l'industrie.