« K2.6 est notre modèle de code le plus puissant à ce jour », écrit Kimi sur son compte officiel WeChat.
Le 20 avril dans la soirée, Kimi a officiellement lancé le modèle open source K2.6, aux performances renforcées en programmation et en capacités d'agent, environ un trimestre après la publication de la version précédente, K2.5.
Il y a aussi un petit aparté : la rumeur veut que DeepSeek V4 soit également publié cette semaine. Si tout se déroule comme prévu par les observateurs externes, ce sera la N-ième fois que Kimi et DeepSeek se retrouvent en concurrence directe. Mais à un niveau infrastructurel plus fondamental, une autre ligne sous-jacente existe : Kimi et DeepSeek, ces deux startups de grands modèles, finiront par entrer dans le même fleuve – avançant de concert avec les startups chinoises de puces.
Remontons le temps jusqu'en mars 2026, lorsque Yang Zhilin, sur la scène de conférence NVIDIA GTC, a parlé de la feuille de route technologique de Kimi. Il a déclaré : « De nombreuses normes technologiques couramment utilisées aujourd'hui sont, par essence, des produits d'il y a huit ou neuf ans, et deviennent progressivement un goulot d'étranglement pour le Scaling. »
Pour résoudre ce type de problèmes, Kimi a contribué à la communauté open source avec l'optimiseur de second ordre MuonClip, première application à grande échelle, l'architecture Kimi Linear qui rend le traitement des longs contextes par les grands modèles plus efficace, et les Attention Residuals qui optimisent la connexion des couches de réseaux neuronaux profonds.
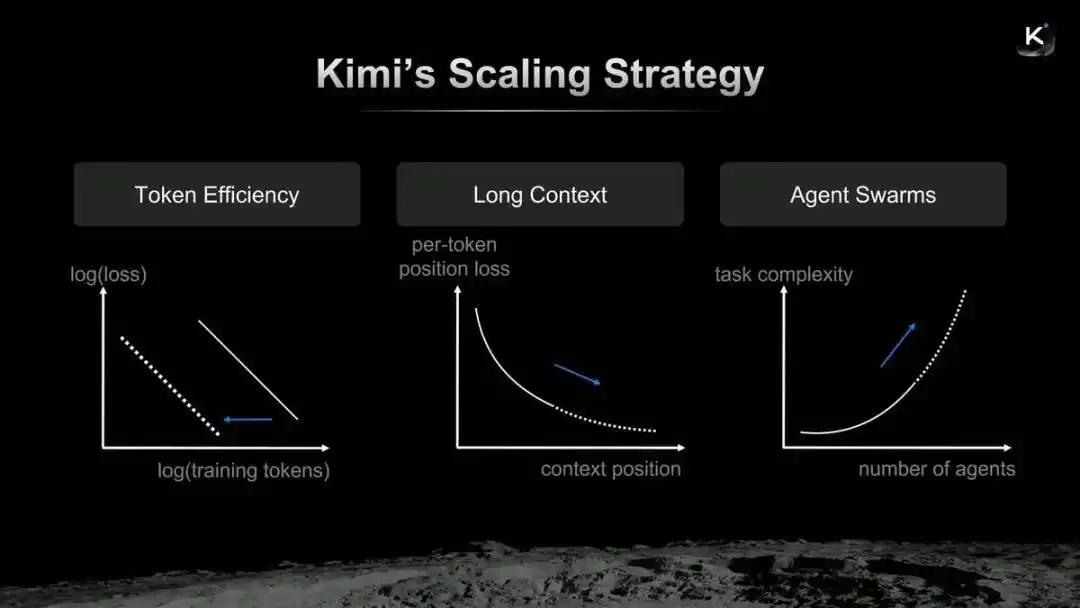
Stratégie de Scaling de Kimi
Yang Zhilin estime que la logique d'évolution de Kimi peut se résumer à la fusion de l'efficacité des Tokens, du long contexte et des clusters d'agents. Le Kimi K2.6, récemment mis en ligne, peut être compris comme les nouveaux devoirs rendus par Yang Zhilin sur cette voie de Scaling.
Le site officiel de Kimi a intégré K2.6
Code, Agent, et quoi d'autre ?
En tant que l'une des capacités les plus facilement standardisables, le code est un champ de bataille incontournable pour les modèles de pointe.
De K2 à K2.5, puis à K2.6, Kimi maintient un rythme d'itération d'environ un trimestre en moyenne sur plusieurs modèles open source, mais comme il s'agit d'un petit numéro de version, cela suggère que Yang Zhilin pourrait avoir encore plus de cartes en main.
« Les capacités de codage à long terme de K2.6 sont considérablement améliorées ; lors des tests, il peut coder sans interruption pendant 13 heures, écrire ou modifier plus de 4000 lignes de code », écrit Kimi dans un document de communication. « Sur le benchmark interne strict de code de Kimi, le Kimi Code Bench, qui couvre diverses tâches complexes de bout en bout, les résultats de K2.6 sont environ 20 % meilleurs que ceux de K2.5. »
Il faut savoir que K2.5 était déjà un modèle très « combatif », ayant dominé le classement d'OpenRouter en février. Une personne proche de Kimi a partagé une capture d'écran du message que le cofondateur Zhang Yutao avait posté sur son moment WeChat à l'époque : « Il avait l'air très satisfait de cette version. »

Performances de K2.6 sur les tests de référence des agents généraux, de programmation et des agents visuels
Pour les frameworks d'agents comme OpenClaw et Hermes, les améliorations principales de K2.6 se concentrent sur la précision des appels d'API et la stabilité des exécutions de longue durée – l'une augmente le coût d'exécution des tâches, l'autre optimise l'efficacité de leur exécution.
Dans la version K2.5 lancée en janvier, Kimi a introduit le concept de « cluster d'agents », divisant une tâche en plusieurs sous-projets, les attribuant automatiquement à différents agents spécialisés pour un suivi et un traitement, réduisant ainsi le temps de traitement des tâches et évitant le risque d'effondrement de l'ensemble du projet dans un flux de tâches séquentielles.
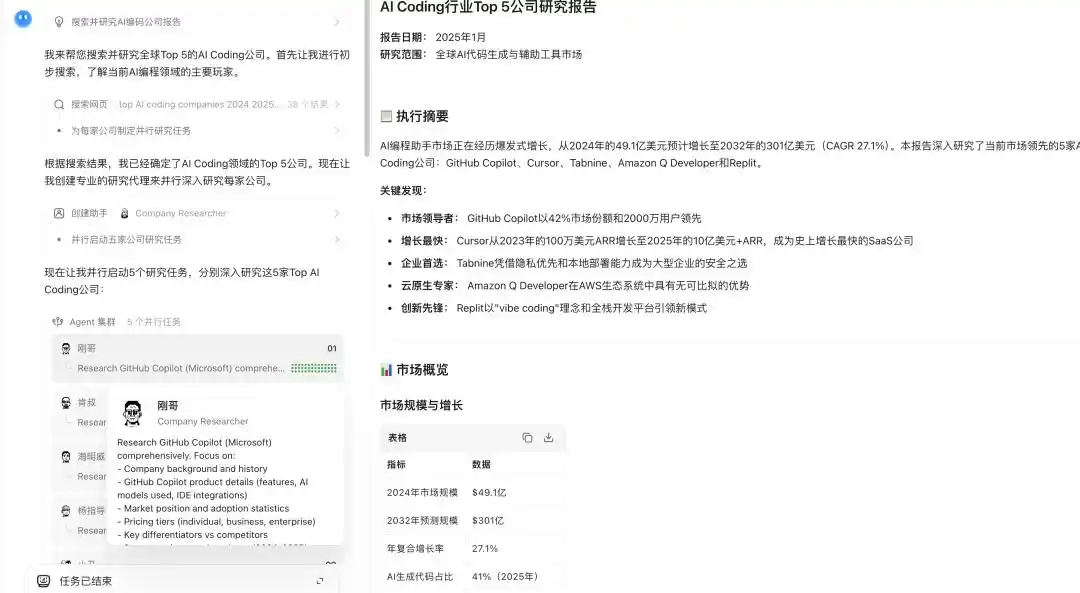
Démonstration des capacités du cluster d'agents de Kimi K2.6
Dans la nouvelle version K2.6, cette capacité est encore amplifiée, intégrant et traitant en parallèle la recherche large et l'exploration en profondeur, l'analyse de documents à grande échelle et la réaction de longs textes, ainsi que la génération de contenu multi-format, prenant en charge jusqu'à 300 sous-agents exécutant parallèlement 4000 étapes de collaboration.
Pour résumer brièvement les points forts de Kimi K2.6, on peut citer : l'évolution des capacités de code et des tâches longues, l'évolution des capacités des clusters d'agents et l'optimisation de l'adaptation aux frameworks d'agents mainstream.
Si je devais choisir une préférence personnelle parmi ces caractéristiques fonctionnelles, je dirais que le cluster d'agents est la capacité la plus précieuse, car elle matérialise directement la capacité explosive du calcul parallèle – que ce soit le code ou la stabilité des tâches longues, ce sont des choses que le modèle doit faire de toute façon pour itérer. Plus important encore, sur la base de ces améliorations de capacités, il pousse l'innovation dans les modes de travail, l'efficacité et même les modes d'interaction des agents.
Après tout, en tant qu'utilisateur, ce que je veux, ce n'est pas qu'il me dise ce qu'il peut faire, mais qu'il pilote des agents pour résoudre mes problèmes concrets et crée une productivité effective.
Lors de la sortie de K2.5, un chercheur universitaire a commencé à utiliser ce modèle pour mener des projets de recherche. Son évaluation à l'époque était qu'il n'avait pas de point faible et pouvait servir d'assistant de recherche.
« Les multi-agents fournis officiellement sont vraiment efficaces, l'année dernière, beaucoup d'agents chinois n'étaient encore que des jouets. »
Si les évaluations internes et externes de Kimi K2.5 étaient déjà bonnes, à quel point K2.6, qui va encore plus loin, sera-t-il efficace ?
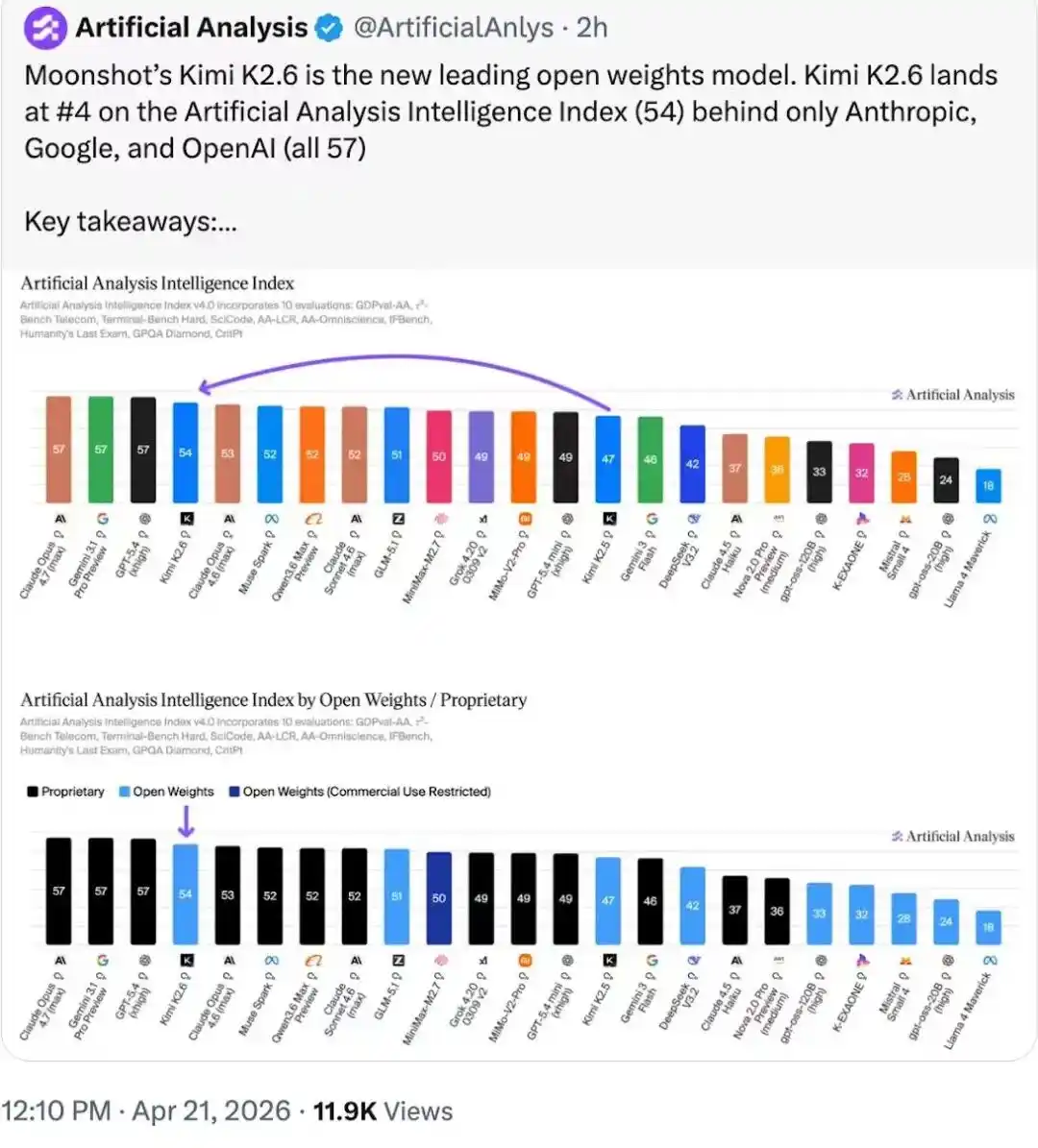
Classement intelligent Artifacial Analysis, Kimi K2.6 se classe juste après trois modèles privateurs et mène le classement des poids des modèles open source
La « nouvelle histoire » dans la feuille de route
Kimi surprend toujours l'industrie avec de nouvelles idées, y compris celles mentionnées dans la feuille de route évoquée par Yang Zhilin lors de sa conférence : MuonClip, Kimi Linear, Attention Residuals. Certaines de ces explorations ont même reçu des retours positifs de la part des leaders du secteur.
Mi-mars, Kimi a publié l'article de recherche sur les Attention Residuals, proposant d'utiliser le mécanisme d'attention pour remodeler les connexions résiduelles. Musk a directement tweeté en disant que c'était « une avancée impressionnante de Kimi ».

Le week-end dernier, Kimi a publié un nouvel article de recherche intitulé « Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter » (PrfaaS, Préremplissage en tant que Service), évoquant de nouvelles explorations architecturales de Kimi, discutant toujours au cœur de la séparation PD (Prefill et Decode).
La séparation PD n'est pas un nouveau sujet – la phase Prefill de l'inférence du modèle est une tâche intensive en calcul, tandis que la phase Decode dépend de la bande passante mémoire, la mémoire devant lire et écrire来回 le KV Cache – cette architecture vise à découpler les tâches intensives en calcul et les tâches intensives en bande passante, améliorant ainsi l'utilisation et le débit de calcul, et réduisant les coûts.
Bien que la séparation PD soit avantageuse, elle a aussi un point bloquant : elle doit reposer sur un réseau RDMA haute vitesse dans le même datacenter.
L'article PrfaaS de Kimi a pour point central : basé sur un modèle hybride (Kimi Linear) réduisant considérablement le volume du cache KV, puis découplant complètement le Prefill et le Decode vers différents clusters hétérogènes.
L'exemple expérimental mentionné dans l'article montre que le cluster dédié au préremplissage PrfaaS utilise 32 H200, spécialisés dans le calcul haute performance ; le cluster local de décodage PD utilise 64 GPU H20 interconnectés via un réseau interne RDMA ; les deux clusters sont connectés via une ligne dédiée VPC, la bande passante totale inter-clusters étant d'environ 100 Gbps. Le modèle testé est un modèle d'attention hybride Kimi Linear avec 1T de paramètres.
Les résultats des tests montrent que la solution PrfaaS‐PD inter-datacenters, comparée à une solution PD classique utilisant 96 cartes H20 dans le même cluster, améliore le débit de 54 %, réduit le P90 TTFT (le temps d'attente pour 90 % des utilisateurs, entre l'envoi de la requête et la réception du premier caractère) de 9,73 s à 3,51 s, soit une réduction de 64 %, et la bande passante de transmission du cache KV inter-datacenters n'utilise que 13 % de la bande passante totale de 100 Gbps.
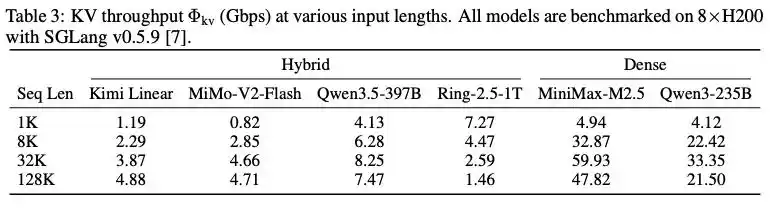
Comparaison du débit KV entre les modèles à architecture hybride et les modèles denses à différentes longueurs de contexte
Pour prouver l'avantage de l'architecture de modèle hybride, l'article mentionne une série d'expériences : sur 8 cartes H200 et avec le framework d'inférence SGLang v0.5.9, des tests de référence ont été effectués sur plusieurs modèles mainstream. Pour une longueur de contexte de 32K, le débit KV du modèle MiMo‐V2‐Flash utilisant l'attention hybride n'était que de 4,66 Gbps, tandis que le modèle d'attention dense de même échelle MiniMax‐M2.5 atteignait 59,93 Gbps, prouvant directement que l'architecture d'attention hybride peut réduire les besoins de transmission du cache KV à une plage pouvant être supportée par Ethernet standard.
« Datacenters croisés + matériel hétérogène, déverrouillant le potentiel de réduction significative du coût par token. » a déclaré Kimi sur son compte officiel.
Concernant la réduction des coûts par Token, j'en ai parlé dans l'article « Le peuple pense à DeepSeek », il y a une marge d'optimisation au niveau du modèle et du matériel. Le professeur Hu Yanping de l'Université de Finance et d'Économie de Shanghai a spécialement posté un message sur son moment WeChat, soulignant que la réduction des coûts ne peut pas reposer uniquement sur un seul DeepSeek. « La solution du problème dépend de l'efficacité coût de l'offre de calcul, de l'amélioration intergénérationnelle de la qualité des modèles, de l'avancement continu des paradigmes d'intelligence, des effets d'amplification de la circulation des flux de travail et des scénarios, etc. »
Sous cet angle, Kimi raconte une nouvelle histoire de réduction des coûts par Token à l'industrie.
Les modèles chinois appellent les puces chinoises
Dans l'article sur le préremplissage en tant que service, la plupart des gens n'ont remarqué que le récit inter-datacenters, ignorant le point sur le matériel hétérogène.
Il est important de noter que les H200 et H20 sont toujours basés sur l'architecture Hopper. L'hétérogénéité mentionnée dans l'article fait référence à l'hétérogénéité en termes de bande passante et de puissance de calcul. Son enseignement est le suivant : nous pouvons utiliser une partie des cartes chinoises puissantes en calcul pour faire le Prefill, ou des cartes chinoises à forte bande passante pour faire le Decode, et bien sûr, les mélanger avec des cartes étrangères pour réaliser des économies et améliorer l'efficacité.
On peut dire que c'est une porte que Kimi ouvre à la puce chinoise pour l'inférence des grands modèles.
De l'avis d'un expert en calcul chinois, pour capter ce flux favorable apporté par ce type de solution de préremplissage en tant que service, il faut encore faire face à ce vieux problème qu'est l'écosystème.
Au cours des dernières années, les grands modèles chinois ont été bloqués hors du calcul national à cause des difficultés de l'écosystème, mais il y a un autre détail passé inaperçu : des produits comme le H20 sont coupés depuis un an. En d'autres termes, à court terme, il n'y a qu'une seule option pour les puces d'inférence : les puces nationales.
Avec l'explosion de la demande d'inférence, comparé au problème d'approvisionnement, le défi de l'écosystème deviendra secondaire – la dépendance des grands modèles chinois vis-à-vis du calcul national est passée de « utilisable ou non » à « indispensable ». C'est aussi pour cette raison que de nombreuses prédictions discutent de l'adaptation de DeepSeek V4 au calcul national.
Dans « La dernière lettre de rappel pour DeepSeek » que j'ai co-écrite avec le professeur Hu Yanping, nous disions que l'adaptation au calcul national est une voie très difficile pour les modèles chinois, mais qu'à long terme, elle doit être faite. Une chose qui doit être faite doit bien avoir un point de départ, et peut-être que DeepSeek V4 sera ce point de départ.
Maintenant, DeepSeek V4 n'est pas encore arrivé, et Kimi a déjà utilisé sa propre pratique pour explorer une voie viable pour l'union des modèles chinois et des puces chinoises.
Kimi, en tant que représentant des modèles, tend率先 la main en premier, le problème est maintenant confié aux startups de puces chinoises.
Vous souvenez-vous de la réaction de Huang Renxun dans le dernier podcast de « the Dwarkesh Podcast » lorsqu'on lui a demandé à propos de l'interdiction d'exporter des puces vers la Chine ? Il a dit que les puces ne sont pas de l'enrichissement d'uranium, que l'embargo ne peut pas arrêter les progrès des puces chinoises, et qu'ils peuvent toujours développer des modèles par empilement violent de puces nationales.
Pourquoi Huang Renxun dit-il cela ? La prochaine étape de DeepSeek et Kimi est la réponse standard.
Cet article provient du compte officiel WeChat « Tencent Technology », auteur : Su Yang, éditeur : Xu Qingyang





