Par Sun Yongjie
En 2026, la fenêtre de publication de DeepSeek V4 a été reportée à plusieurs reprises, ce qui a paradoxalement enflammé les discussions mondiales sur la "dé-CUDA-isation" dans le milieu de l'IA. D'après les reportages de plusieurs médias, ce modèle open source multimodal, dont la taille des paramètres devrait atteindre mille milliards et prendre en charge un contexte de centaines de milliers de tokens, est en cours d'adaptation intensive aux puces Huawei Ascend, avec une réécriture du code cœur via le framework CANN.
Si cela se concrétise, ce serait la première fois que l'écosystème d'IA chinois explore systématiquement, dans un environnement de production réel, la possibilité d'héberger des capacités de modèles cœur sur une plateforme non-CUDA. En d'autres termes, il ne s'agit pas seulement du lancement d'un modèle, mais plutôt d'un "test de résistance" des routes technologiques sous-jacentes.
Cependant, comme l'a souligné Liang Wenfeng, fondateur de DeepSeek, dans des communications internes, ce n'est que le "premier pas d'une Longue Marche". L'avenir recèle à la fois des risques et des opportunités. L'équilibre, voire l'arbitrage, entre compatibilité et autonomie, déterminera si l'IA chinoise pourra véritablement tracer sa propre voie de développement.
Le report de DeepSeek V4, le coût inévitable de la conversion des plates-formes de calcul IA de base
Comme mentionné précédemment, la version V4, initialement prévue pour le Nouvel An lunaire chinois ou entre février et mars de cette année, a manqué à plusieurs reprises sa fenêtre de publication, jusqu'à ce que des médias confirment début avril une sortie "sous quelques semaines". La raison principale en est l'adaptation approfondie côté inférence avec les puces Huawei Ascend. Mais le problème est que cette voie est bien plus complexe qu'imaginé. Pour comprendre cette complexité, il faut d'abord revenir aux caractéristiques techniques de DeepSeek V4 lui-même.
Comme on le sait, en 2026, la taille des paramètres des grands modèles a franchi le seuil du "mille milliards" et s'oriente vers plusieurs milliers de milliards. Dans ce contexte, bien que V4 adopte une architecture MoE (Mixture of Experts) plus agressive, réduisant théoriquement la quantité de calcul par inférence via "l'activation d'experts à la demande", le prix à payer est une demande extrême sur les capacités système, incluant la bande passante mémoire, l'interconnexion entre puces (Interconnect) et la gestion du KV Cache, entre autres.
En d'autres termes, la pression de calcul passe du "calcul pur" à la "planification système et aux communications". Et dans l'écosystème NVIDIA, ce problème a une solution relativement mature.
Par exemple, basé sur les H100 ou B200, une interconnexion haut débit construite via NVLink et NVSwitch peut atteindre des bandes passantes de l'ordre du TB/s entre GPU au sein d'un nœud, formant un réseau de calcul quasi "entièrement connecté" où les données circulent entre les puces comme sur une autoroute, compressant considérablement la latence et les coûts de synchronisation. Mais lorsque DeepSeek tente de migrer ce système complexe vers la plateforme Huawei Ascend, il se confronte à une topologie matérielle totalement différente.
Il est indéniable que les puces Ascend ont progressé de manière significative ces dernières années, mais des écarts physiques persistent avec NVIDIA concernant la capacité de "connexion totale" des grappes à très grande échelle. Par exemple, limité par les procédés de fabrication et les capacités IP SerDes, Ascend dépend davantage de modules optiques pour l'extension inter-nœuds. Bien que viable, cette solution "d'échange d'espace contre bande passante" introduit des trajets physiques plus longs, entraînant une complexité accrue en termes de latence des signaux, de surcharge de synchronisation, ainsi que de gestion de la consommation énergétique et de la dissipation thermique.
Parallèlement, l'écart au niveau logiciel est tout aussi notable. Le framework CANN d'Ascend, en termes de couverture des opérateurs, de parallélisme automatique, de fusion de noyaux (kernel fusion) et de planification des communications distribuées, présente globalement une maturité inférieure à celle de l'écosystème CUDA. Cela signifie que l'équipe d'ingénierie de DeepSeek doit effectuer des optimisations ciblées sur une multitude de détails de bas niveau, voire réécrire manuellement des opérateurs clés.
Plus problématique encore, ce retard est souvent systémique plutôt que linéaire. Il se manifeste concrètement par le fait qu'une baisse de performance d'un opérateur peut affecter toute la chaîne de calcul ; une réduction de l'efficacité d'une communication peut entraîner d'importantes fluctuations du débit global. Le résultat final pourrait être que le modèle fonctionne encore, mais qu'il reste loin d'être stable, efficace et scalable.
Sous cet angle, le report de DeepSeek V4 n'est pas une simple question de calendrier produit, mais le coût inévitable d'un rodage approfondi entre une équipe algorithmique chinoise d'élite et un système de puces national. Bien que le processus soit difficile, il est d'une grande importance.
Plus important encore, ce processus envoie un signal clair : la concurrence dans l'IA passe d'une "course aux capacités des modèles" à une "course aux capacités d'ingénierie système". Et à ce stade, celui qui pourra faire "tourner, stabiliser et réduire le coût" des modèles le plus rapidement se rapprochera véritablement d'un avantage au niveau industriel.
Monopole de CUDA difficile à briser, compromis无奈 de CANN
Si les difficultés d'adaptation côté inférence de DeepSeek V4 mentionnées ci-dessus révèlent des goulots d'étranglement pratiques au niveau de l'ingénierie, en poussant plus loin la réflexion, une question plus fondamentale émerge : pourquoi simplement migrer un modèle d'une plateforme de calcul à une autre devient-il si difficile ?
En repensant à l'alliance Wintel de l'ère PC, Microsoft et Intel, bien qu'en situation de monopole conjoint, entretenaient une relation de concurrence et de coopération, ce qui a laissé un espace pour l'émergence ultérieure de Linux, d'AMD, voire du système Apple. Cependant, NVIDIA a établi dans le domaine de l'IA un "monopole vertical monolithique", fusionnant les rôles de Microsoft et d'Intel.
Concrètement, au niveau matériel, NVIDIA a défini la structure physique des SM (Streaming Multiprocessors) et la logique de calcul des Tensor Cores ; au niveau logiciel, CUDA fournit des bibliothèques propriétaires comme cuBLAS et cuDNN, parfaitement adaptées 1:1. Leur combinaison conduit à une réalité extrêmement contraignante : plus de 6 millions de développeurs dans le monde optimisent des algorithmes, des frameworks (PyTorch, TensorFlow) en priorité pour CUDA autour de cuBLAS, cuDNN, NVLink/NVSwitch ; même les grappes hétérogènes "anti-NVIDIA" comme AWS Trainium + Cerebras WSE nécessitent toujours le logiciel NVIDIA NIXL et AWS EFA pour la migration du cache KV.
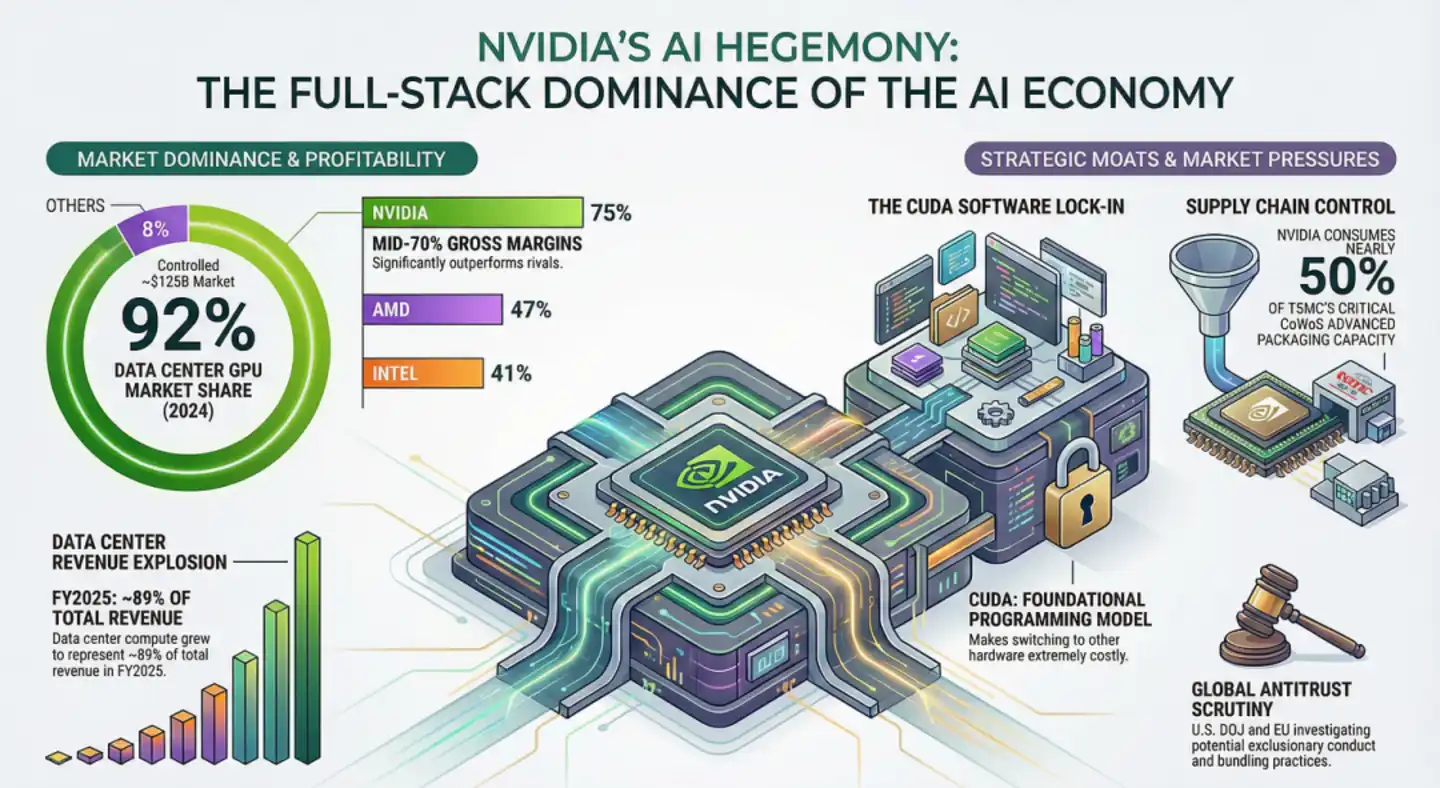
Ainsi, il ne s'agit plus de simples détails techniques ponctuels, mais d'un verrouillage ecosystemique : avant même que la portabilité des modèles ne devienne inefficace, la tendance des développeurs à "penser dans le langage des caractéristiques matérielles de NVIDIA" est devenue une inertie. Et c'est cette inertie ecosystemique qui fait de NVIDIA un immense trou noir, absorbant plus de 90% des bénéfices de l'innovation mondiale.
Dans ce contexte, CANN de Huawei, son concurrent le plus sérieux, a initialement tenté de suivre une voie relativement indépendante. Mais avec l'avènement de l'ère des grands modèles, des problèmes sont apparus, comme la réticence des développeurs à migrer, la peur des entreprises de prendre des risques, et une croissance lente de l'écosystème. Sous la pression du temps (comme l'itération rapide des grands modèles), la voie de l'autonomie complète est devenue moins réaliste.
Sur cette base, CANN a progressivement introduit une conception par couches d'abstraction similaire à CUDA. Par exemple, dans CANN Next, il tente d'aligner les interfaces sur cuBLAS, cuDNN pour atteindre une compatibilité élevée, réduisant le coût de migration des modèles de "plusieurs semaines voire mois" à "quelques heures". Au niveau architecture, la récente architecture hétérogène 950PR (pré-remplissage/découplage de décodage) imite délibérément le service découplé de NVIDIA, plutôt que la voie totalement hétérogène des TPU de Google.
Nous devons admettre que cette stratégie axée sur la "compatibilité d'abord" est un succès à court terme. Elle abaisse la barrière à l'entrée, permettant à Ascend d'acquérir rapidement une base d'applications sur le marché national et à des entreprises comme DeepSeek, Tencent, ByteDance d'expérimenter la puissance de calcul nationale avec un seuil relativement bas. Par exemple, CANN Next, grâce à son modèle de programmation SIMT, atteint une compatibilité CUDA supérieure à 95%, aidant déjà plusieurs entreprises à réduire considérablement leur temps de migration à l'échelle horaire, accélérant ainsi la mise en œuvre pratique.
Mais le défi qui en découle est qu'une fois les innovations de pointe abordées, la couche de compatibilité devient un "plafond".
Par exemple, lorsque les développeurs utilisent réellement en profondeur la plateforme Ascend, ils découvrent que si les chemins communs sont aplatis, dès qu'il s'agit d'opérateurs de bas niveau moins courants ou innovants, le support de CANN diminue et les performances deviennent erratiques. Les difficultés rencontrées par DeepSeek V4 lors de l'adaptation, comme lors de tentatives d'introduction d'architectures hybrides non-Transformer telles que SSM (State Space Model) ou Mamba, où il a été constaté que les optimisations de bas niveau de CANN restent principalement orientées vers la multiplication matricielle (GEMM), sont largement dues au fait qu'en tentant des optimisations algorithmiques hors normes, ils ont heurté les "limites" de la couche de compatibilité de CANN.
Le problème plus profond est qu'une fois la compatibilité choisie, cela signifie que CUDA reste la norme invisible. Vous pouvez remplacer le matériel, mais en termes de sémantique logicielle et de paradigmes de développement, vous suivez toujours les règles définies par l'autre. C'est à la fois un raccourci et une limitation.
La compatibilité cache des défis et des risques, les opportunités futures nécessitent une véritable autonomie
Comme mentionné précédemment, dans le contexte où l'écosystème CUDA est devenu un standard de fait, le choix par Huawei d'une voie de "quasi-compatibilité" est presque inévitable, mais il place également toute l'industrie chinoise de l'IA face à un choix crucial : continuer à être compatible avec CUDA, ou progressivement évoluer vers un écosystème véritablement indépendant ?
À court terme, la réponse ne fait presque aucun doute : il faut être compatible, c'est un choix d'efficacité et de réalité. Mais à long terme, cette voie cache des risques qui ne peuvent être ignorés.
Comme on le sait, lorsqu'un système (comme CANN) est conçu pour être compatible avec un autre (comme CUDA), il hérite inévitablement des limitations de ce dernier.
Le fait est que la plupart des algorithmes open source mondiaux sont développés autour de l'architecture NVIDIA. Si, pour exploiter ces actifs existants, on cherche une compatibilité 1:1, alors nous tomberons dans le "piège de l'imitateur" en matière de conception matérielle. Cela se manifesterait par le fait que si l'architecture matérielle de NVIDIA devait connaître un changement de paradigme à l'avenir, par exemple en passant de Transformer à une nouvelle architecture qui ne repose pas sur la multiplication matricielle à grande échelle mais plutôt sur une logique asynchrone, alors la pile de calcul nationale, toujours dans un état d'"ombre", pourrait faire face à une rupture technologique instantanée. Cette impasse de la "compatibilité bug pour bug" maintiendrait sans aucun doute notre innovation de base perpétuellement dans l'ombre des autres.
Et le risque plus profond réside dans le "décalage temporel". Selon les données statistiques de Bernstein et Epoch AI, bien que la part de Huawei ait explosé nationalement, la proportion de puces nationales dans la puissance de calcul IA mondiale totale n'est que de 5%, restant relativement limitée. Et c'est précisément cet écart d'échelle absolue qui cause une grave "friction d'efficacité en R&D".
Concrètement, les géants américains de l'IA peuvent utiliser la puissante bande passante de communication de Blackwell pour valider les Lois d'échelle (Scaling Laws) de modèles de 10T paramètres en 18 mois, tandis que les talents d'élite chinois doivent consommer plus de 50% de leur capacité de recherche à résoudre des problèmes comme "comment résoudre l'atténuation du signal sur des puces anciennes" et "adapter des compilateurs immatures".
Il faut préciser que ce décalage temporel est amplifié à l'infini à l'ère de l'IA où tout change rapidement. Pendant que nos talents sont occupés à "combler les fossés", l'adversaire peut avoir achevé une croissance exponentielle des capacités des modèles, conduisant à un avantage d'un an de l'adversaire en termes de modèle qui se transforme, après la croissance composée exponentielle combinée des capacités des modèles, de la roue des données et de l'alignement de la sécurité, en un fossé de plus d'un an.
Bien sûr, les défis recèlent souvent des opportunités. Si DeepSeek V4 est publié avec succès, il prouvera la faisabilité de la "stack complète nationale", accélérera la maturation de l'écosystème CANN, attirera plus de développeurs à suivre, et, ajouté au sentiment global de "lassitude envers NVIDIA", le support du secteur pour CANN pourrait dépasser les attentes. Et si les puces Huawei Ascend suivantes atteignent 80 à 90% des performances d'inférence du H100, combiné au dividende de compatibilité de CANN Next, une masse critique de la chaîne d'approvisionnement IA chinoise pourrait se former dans 1 à 2 ans.
Mais il faut reconnaître clairement que la compatibilité ne peut résoudre que le problème de "survie". Seule une véritable autonomie déterminera "jusqu'où nous irons". Les 3 à 5 prochaines années seront une fenêtre cruciale. Si nous pouvons, tout en maintenant la compatibilité, établir progressivement des modèles de programmation, des systèmes d'opérateurs et des architectures système indépendants, l'écosystème IA chinois aura encore une chance d'effectuer un saut qualitatif du suivi à la définition des règles. Sinon, l'IA chinoise pourrait s'enliser dans l'ornière du "train de la réplication approximative".
Pour conclure : Le report de la publication de DeepSeek V4, bien qu'apparemment un "retard" fortuit, révèle en réalité une réalité plus profonde : la concurrence dans l'IA n'est plus depuis longtemps une simple compétition entre modèles, mais un affrontement complet des écosystèmes sous-jacents et des capacités système. La compatibilité avec CUDA est certes le chemin le plus court vers la réalité, mais s'y limiter pourrait aussi verrouiller le plafond futur.
Le vrai défi ne réside donc pas dans la capacité à remplacer une technologie, mais à se libérer de la dépendance aux paradigmes existants et à construire son propre système de règles. Les 3 à 5 prochaines années détermineront si l'IA chinoise deviendra un pôle important dans l'écosystème mondial ou restera longtemps dans une position de "suivi de haut niveau". Bien sûr, tout en poursuivant l'autonomie, il faut également se méfier de l'impact potentiel d'un écosystème fermé sur son attractivité pour les développeurs mondiaux, afin de garantir l'ouverture de l'écosystème et sa compétitivité internationale à long terme.