Un disque SSD de 1 To "consommé" chaque année ?
Codex, l'outil de programmation phare d'OpenAI, est en train de détruire votre disque SSD avec un volume d'écriture annuel de 640 To.

Il y a quelque temps, un développeur a soumis un problème (issue) sur GitHub. Cette issue GitHub, maintenant marquée comme "Closed" et portant le numéro #28224, a pour titre :
Le journal de feedback SQLite de Codex écrit 640 To par an, épuisant rapidement la durée de vie des disques SSD.
Selon les mesures du rapporteur, son disque SSD principal a subi 37 To d'écriture en 21 jours de fonctionnement continu. En extrapolant, cela représente environ 640 To par an, suffisant pour mettre hors service un disque dur grand public dont la TBW (Total Bytes Written) est de 600 To.
Pour étayer ses dires, il a publié deux tableaux.
Dans la preuve 1, cette base de données de journaux ne fait toujours que 1,2 Go en surface, comme si rien ne s'était passé ; mais son ID de ligne auto-incrémenté a déjà atteint 5,5 milliards, alors que le nombre de lignes réellement conservées n'est que d'un peu plus de 500 000, soit un écart de dix mille fois.
Le point clé est que l'usure du disque dur ne compte que le total des écritures, peu importe ce qui reste actuellement : ces 5,5 milliards de lignes ont toutes été écrites sur le disque, et les supprimer ne permet pas de récupérer les écritures déjà effectuées. Donc, quand vous vérifiez le fichier, vous ne voyez toujours que ces 500 000 lignes, mais le disque dur a déjà subi l'écriture de 5,5 milliards de lignes.
La preuve 2 révèle la distribution de ces 5,5 milliards de lignes : plus de 90 % sont du bruit de débogage que même les développeurs eux-mêmes ne reliraient pas. Rien que la copie intégrale de chaque paquet de données WebSocket représente la moitié.
Le coupable est une configuration par défaut Level::TRACE, qui utilise la durée de vie d'écriture de votre disque dur comme du papier brouillon gratuit.
Un commentaire hautement voté sur Hacker News a directement qualifié l'affaire :
C'est l'un des exemples les plus notoires de "logiciel de mauvaise qualité" (slopware).

Cet internaute a aussi lâché avec résignation :
C'est vraiment tragique. Le monde a besoin de quelqu'un pour concurrencer Anthropic.
Plus embarrassant encore, ce problème n'est pas passé inaperçu.
Des retours sporadiques existent depuis avril de cette année. Cela a traîné pendant plus de deux mois, et il a fallu attendre que les utilisateurs mesurent, rédigent un rapport et le fassent monter en tête de Hacker News pour qu'il soit sérieusement pris en compte. Même ainsi, cette vague de corrections n'a réduit que d'environ 85 % l'écriture des journaux.
D'autres ont voulu agir par eux-mêmes mais ont constaté qu'il n'y avait pas de solution : les versions desktop de ces outils sont propriétaires.
Un commentaire génial dans la section des commentaires : Comment le processus de révision n'a-t-il pas bloqué une erreur aussi évidente ? Ah oui... @codex, passe en revue ça.
640 To, comment est-ce possible ?
Que représentent 640 To ?
Les disques SSD grand public courants ont une durée de vie d'écriture nominale d'environ 150 à 600 TBW, suffisante pour un utilisateur moyen pendant dix à vingt ans.
Et cette fonction de journalisation de Codex, qui "enregistre ce qu'il fait", peut remplir cette capacité en un an.
Tout a commencé lorsque cet utilisateur a vérifié l'utilisation de son disque. Sa machine, fonctionnant en continu pendant 21 jours, a vu son disque SSD principal subir 37 To d'écriture.
À cette vitesse, c'est environ 640 To par an.
Mais le mode d'écriture est encore plus absurde.
Codex maintient localement une base de données SQLite, logs_2.sqlite, dédiée à l'enregistrement des journaux de feedback. Cet utilisateur a capturé pendant 15 secondes : 36 211 lignes ont été insérées dans la base de données, tandis que le nombre total de lignes conservées est resté à 681 774 du début à la fin, sans augmentation.
À chaque ligne insérée, une ligne est supprimée. Le nombre de lignes reste constant, mais le disque est réécrit des dizaines de milliers de fois.
Ce mécanisme a un surnom : insert-and-prune (insérer, puis immédiatement supprimer).
Ce qu'il enregistre est encore plus absurde : une série d'événements inotify du système de fichiers.
ld.so.cache a été enregistré 128 764 fois, locale.alias 37 982 fois, passwd 23 843 fois.
Le même fichier, par le même programme, enregistré des centaines de milliers de fois en boucle.
L'ID auto-incrémenté dans les journaux a dépassé les 5,5 milliards, alors que seulement environ 500 000 lignes sont réellement conservées.
Soit un facteur de dix mille.
Ce n'est pas un bug, on dirait plutôt qu'un outil de programmation IA récite en boucle sur son propre disque dur.
Le fichier ne fait que 1 Go, mais l'écriture est de 640 To
En écrivant et supprimant en même temps, quelle taille fait le logs_2.sqlite restant ? Environ 1 Go.
Ce qui amène au point le plus contre-intuitif de toute cette affaire : la durée de vie d'un SSD se mesure par la "quantité d'écriture", et non par la "taille du fichier". Un fichier de 1 Go réécrit 640 fois équivaut, pour le disque dur, à 640 To écrits.
SQLite utilise le mécanisme WAL (Write-Ahead Logging). Chaque modification est d'abord écrite dans un fichier -wal, puis regroupée et rapatriée (checkpoint) dans la base principale. Codex effectue plus de trente mille insertions et suppressions toutes les 15 secondes, chacune devant passer par le WAL, la mise à jour des index, le checkpoint. La même zone de stockage est effacée et réécrite sans cesse.
Une analogie : un cahier de notes de 1 Go que vous effaceriez et réécririez 1750 fois par jour, pendant un an. Le cahier est le même, mais le papier est usé jusqu'à la trame.
C'est aussi pourquoi ce bug a pu rester caché si longtemps : il ne prend pas d'espace, il ne fait que brûler la durée de vie.
Vérifier l'espace disque disponible ne montre rien d'anormal, la taille des fichiers reste stable. Seule la lecture des compteurs de santé SMART du disque dur lui-même permet de voir l'accumulation silencieuse des écritures.
Cause racine, une variable RUST_LOG ignorée
Pourquoi y a-t-il autant de journaux ?
La réponse se trouve dans une ligne de configuration du code source de Codex : le sink (destination) des journaux de feedback SQLite est initialisé avec Targets::new().with_default(Level::TRACE).
En un mot, le niveau de journalisation est par défaut TRACE, le niveau le plus élevé, le plus verbeux, celui qui enregistre tout.
Le framework de journalisation de Codex est `tracing`, de l'écosystème Rust. La pratique standard est de lire la variable d'environnement RUST_LOG. Les utilisateurs ont bien sûr essayé, en réglant RUST_LOG sur info, warn, ou même en la désactivant.
Sans effet.
with_default(Level::TRACE) fixe rigidement le niveau global par défaut à TRACE. RUST_LOG n'a aucun effet sur ce chemin. Vous pensez avoir désactivé les journaux, mais ils continuent de s'écrire.
Ce type de bug est particulièrement vicieux car il ne s'agit pas d'"avoir oublié de configurer", mais de "vous avez configuré, et il fait semblant de ne pas entendre".
Plus frappant encore est une proportion.
En décomposant les journaux conservés par catégorie, TRACE représente 70,7 %, soit environ 732,5 Mo. En ajoutant les deux types de journaux de télémétrie miroir de codex_otel (log_only et trace_safe), on ajoute encore 25,3 %.
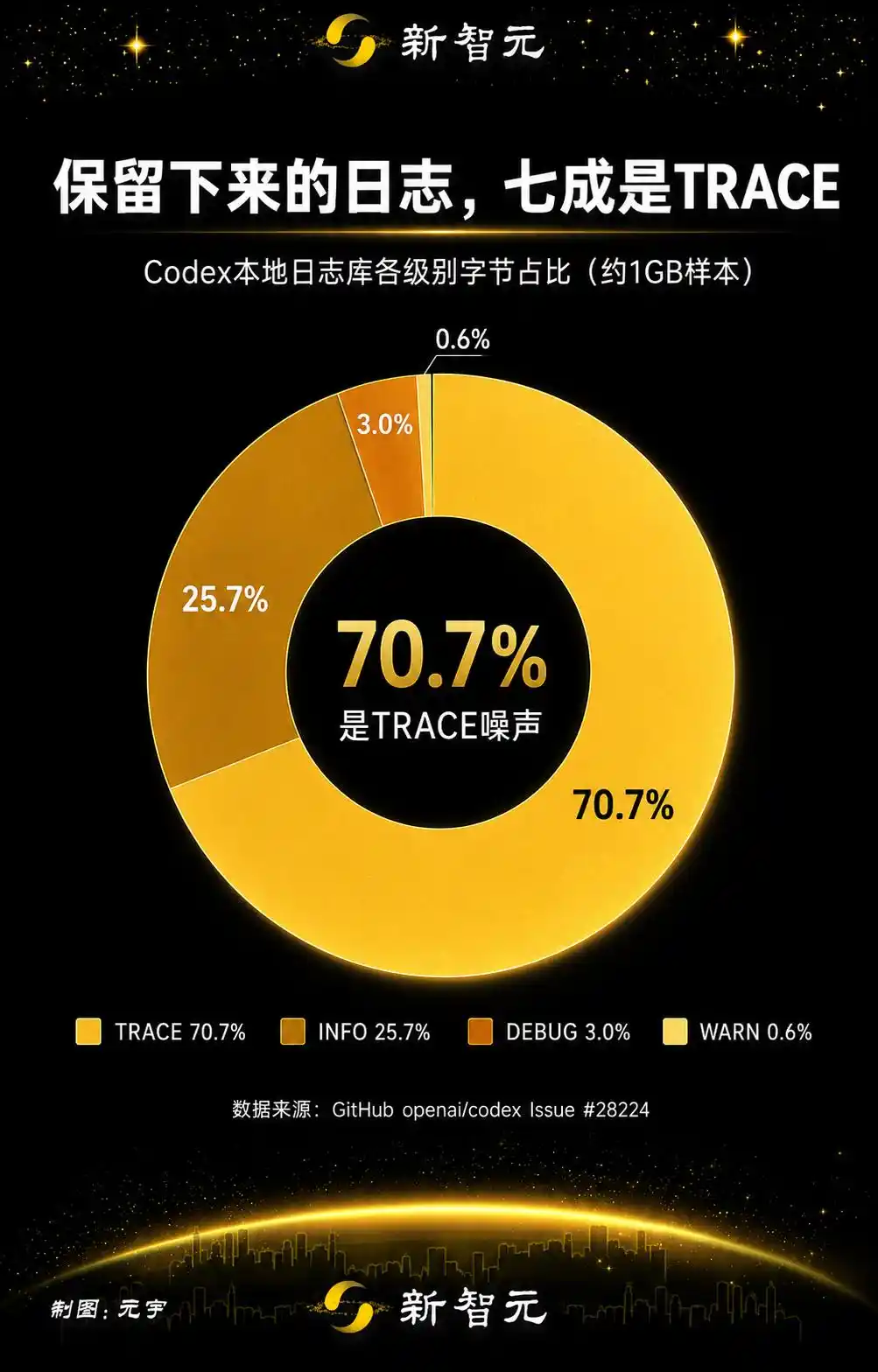
70 % des écritures sont du bruit TRACE, plus la télémétrie miroir, soit 96 % de bavardages inutiles que personne ne regardera.
Seuls 4 % constituent un contenu vraiment significatif.
Ce n'est pas le premier, c'est au moins le neuvième
Le rapporteur a parcouru le dépôt de Codex et a découvert qu'il existe au moins 9 Issues de ce type concernant la "croissance illimitée des journaux".
#17320, écriture frénétique du WAL pendant les réponses en streaming, cause racine identique à cette fois : TRACE ignorant RUST_LOG.
#24275, logs_2.sqlite de la version desktop qui explose.
#22444, WAL qui croît indéfiniment et occupe de l'espace sans le libérer.
#26374, 0,75 Go écrits par jour, pas de rotation.
#27911, une base goals_1.sqlite de 4 Ko, écrite à 11 Mo/s.
#20563, le processus écrit frénétiquement sur le disque même au repos.
#27020, activité disque à 100 % sur Windows.
La source la plus ancienne remonte à #12969, c'est cette Pull Request qui a connecté le sink des journaux de feedback SQLite au niveau TRACE.
Une base de données de 4 Ko écrite à 11 Mo par seconde, à elle seule, mériterait un article. Et elle partage le même produit, les mêmes symptômes du système de télémétrie que celui des 640 To.
Cela montre que le système de journalisation et de télémétrie de Codex n'a, depuis le début, aucun concept de "budget de ressources".
Tout le secteur est en concurrence sur les budgets de token, la longueur du contexte, les capacités des modèles.
Mais presque personne ne demande : pour un Agent résidant en permanence sur la machine de l'utilisateur et fonctionnant 7j/7 et 24h/24, qui gère son budget disque, mémoire, CPU ?
Corrigé, mais corrigé à la manière d'OpenAI
Signalé sur GitHub le 14 juin. Le 23 juin, le rapporteur a ajouté une mise à jour : trois Pull Requests ont été fusionnées. Selon ses propres tests sur Codex, elles réduisent d'environ 85 % les journaux. Il a donc annoncé la fermeture.
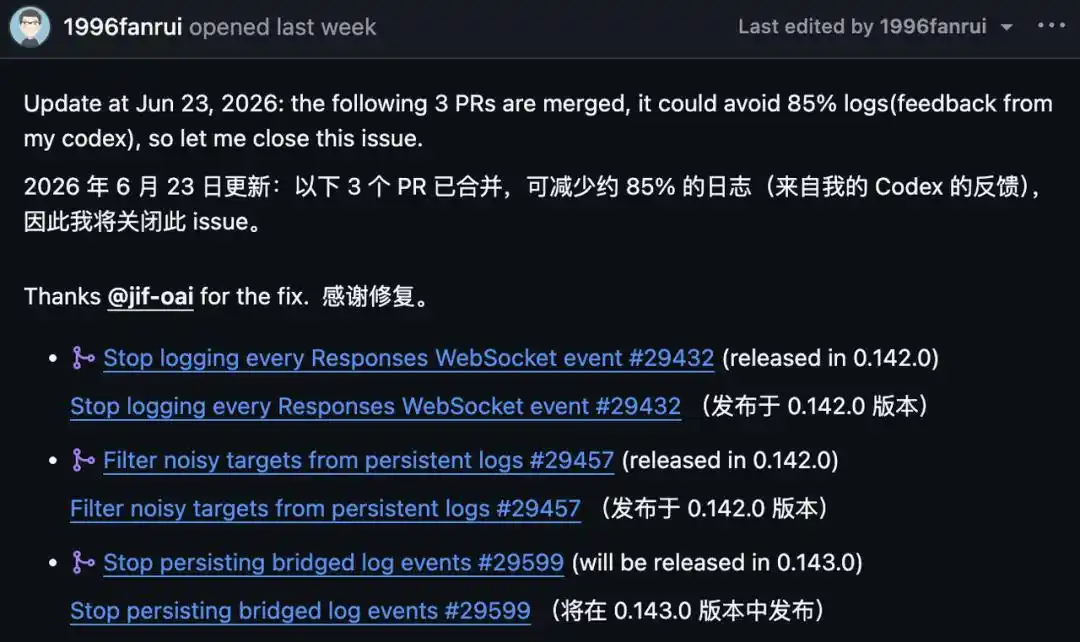
Parlons d'abord de ces 85 % — ce n'est pas 100 %, et ce n'est pas encore entièrement déployé.
Parmi les trois correctifs, #29432 et #29457 ont été publiés avec la version 0.142.0, éliminant les journaux WebSocket ligne par ligne et les cibles de bruit ; le troisième, #29599, désactive un autre type de journaux redondants acheminés, et ne sera disponible qu'avec la version 0.143.0.
Même une fois les trois en place, les 15 % restants représentent encore environ 96 To écrits par an, passant de "un disque dur grillé par an" à "un disque dur grillé en six ans".
Certains le défendent : les journaux de trace sont conçus pour être conservés pour le débogage, ce n'est pas un bug, et c'est effectivement pratique pour OpenAI pour tracer les cas limites.
Mais c'est précisément là le problème : utiliser la durée de vie des SSD des utilisateurs payants comme stockage gratuit pour le débogage du fabricant, est-ce que les utilisateurs ont consenti à cela ?
Le champ de bataille de la programmation, ce ne sont pas que les SSD qui grillent
Il est intéressant de noter que Codex n'est pas le seul nommé.
Les commentaires s'empressent d'ajouter : Claude Code écrit aussi frénétiquement des journaux de débogage en local, certains ont dû créer un lien symbolique (soft link) du répertoire des journaux vers un disque RAM (tmpfs) pour prolonger la vie de leur SSD.
Deux produits phares, la même classe de défaut.
Les commentaires de la communauté ont rapidement dépassé le cadre d'un simple bug pour s'étendre à la question de la qualité globale des outils de programmation IA.
Certains se plaignent que ces agents maintiennent constamment le GPU à 100 %, avec une mémoire atteignant facilement 70 Go. D'autres ont tout simplement baptisé cette génération de logiciels : "slopware" (logiciel de mauvaise qualité).
La suggestion du développeur était extrêmement simple : fixer une limite pour l'application, ne pas dépasser 3 Go. Pour cette simple limite, Codex a nécessité 9 Issues et plusieurs mois avant de l'accepter.
La question est : pourquoi une entreprise qui a constamment "AGI" à la bouche trébuche-t-elle sur un problème qu'un stagiaire en ingénierie pourrait repérer ?
Pourquoi ce défaut a-t-il pu rester caché si longtemps ? Un commentaire a aussi touché le point sensible.
Il y a dix ans, si les journaux étaient réglés sur TRACE, le programme plantait immédiatement, et le bug était corrigé le jour même. Aujourd'hui, les CPU sont assez rapides, la mémoire assez grande, les disques assez puissants pour que ce genre de défaut soit silencieusement absorbé par les performances matérielles. Le programme continue de tourner, l'interface fonctionne normalement, l'utilisateur ne ressent rien, jusqu'au jour où le SSD tombe en panne prématurément.
Ces dernières années, les logiciels se sont remplis de code généré par l'IA. Les fonctionnalités s'empilent, les couches d'abstraction s'épaississent, la consommation de ressources décolle, le tout soutenu par les fabricants de matériel qui produisent chaque année des puces plus rapides pour rattraper le retard.
D'où un cycle absurde : les logiciels sont écrits de plus en plus mal, le matériel devient de plus en plus puissant. Les utilisateurs, avec l'illusion que "ça ne semble pas ralentir", paient pour de nouvelles machines, alors qu'en réalité, les nouvelles machines parviennent tout juste à supporter des logiciels encore pires.
Un petit bug ne peut bien sûr pas faire tomber OpenAI. Mais la concurrence entre Codex et Claude Code s'est déjà étendue des capacités des modèles à l'interface d'entrée du flux de travail des développeurs.
Sur ce front, apporter des changements rapides et répondre aux besoins des développeurs n'a jamais été un avantage concurrentiel, c'est simplement la carte d'entrée.
Références :
https://github.com/openai/codex/issues/28224
https://news.ycombinator.com/item?id=48626930
Cet article provient du compte WeChat public "新智元" (New Intelligence), auteur : ASI启示录






