Eight years ago, ZTE suffered a cardiac arrest.
On April 16, 2018, a ban issued by the U.S. Department of Commerce's Bureau of Industry and Security brought ZTE Corporation, the world's fourth-largest telecommunications equipment manufacturer with 80,000 employees and annual revenue exceeding 100 billion yuan, to a standstill overnight. The content of the ban was simple: for the next seven years, any American company was prohibited from selling components, goods, software, and technology to ZTE.
Without Qualcomm's chips, base station production halted. Without Google's Android authorization, there was no usable system for its phones. Twenty-three days later, ZTE issued an announcement stating that its main business activities could no longer continue.
However, ZTE ultimately survived, but at a cost of $1.4 billion.
A $1 billion fine, paid in one lump sum; a $400 million deposit, placed in an escrow account at a U.S. bank. Additionally, all senior executives were replaced, and a U.S. compliance supervision team was stationed within the company. For the full year of 2018, ZTE reported a net loss of 7 billion yuan, with revenue plummeting 21.4% year-on-year.
Yin Yimin, then chairman of ZTE, wrote in an internal letter: "We are in a complex industry that is highly dependent on the global supply chain." At the time, these words sounded like both reflection and helplessness.
Eight years later, on February 26, 2026, Chinese AI unicorn DeepSeek announced that its upcoming V4 multimodal large model would prioritize deep cooperation with domestic chip manufacturers, achieving for the first time a full-process non-NVIDIA solution from pre-training to fine-tuning.
In other words: We are not using NVIDIA anymore.
The market's first reaction to the news was skepticism. NVIDIA holds over 90% of the global AI training chip market share. Abandoning it—does that make commercial sense?
But behind DeepSeek's choice lies a question larger than commercial logic: What kind of computing independence does Chinese AI truly need?
What Exactly Is Being Strangled
Many people think the chip ban is about hardware. But what truly suffocates Chinese AI companies is something called CUDA.
CUDA, short for Compute Unified Device Architecture, is a parallel computing platform and programming model launched by NVIDIA in 2006. It allows developers to directly utilize the computing power of NVIDIA GPUs to accelerate various complex computational tasks.
Before the AI era arrived, this was just a tool for a few geeks. But when the wave of deep learning hit, CUDA became the foundation of the entire AI industry.
The training of AI large models is essentially massive matrix operations. And this is precisely what GPUs excel at.
Thanks to planning over a decade in advance, NVIDIA used CUDA to build a complete toolchain for global AI developers, spanning from underlying hardware to upper-layer applications. Today, all mainstream AI frameworks worldwide, from Google's TensorFlow to Meta's PyTorch, are deeply tied to CUDA at their core.
A PhD student in AI, from their first day of enrollment, learns, programs, and experiments in the CUDA environment. Every line of code they write reinforces NVIDIA's moat.

As of 2025, the CUDA ecosystem already boasts over 4.5 million developers, covers more than 3,000 GPU-accelerated applications, and is used by over 40,000 companies globally. This number means that over 90% of the world's AI developers are locked into NVIDIA's ecosystem.
The terrifying thing about CUDA is that it's a flywheel. The more developers use it, the more tools, libraries, and code are generated, making the ecosystem more prosperous; the more prosperous the ecosystem, the more it attracts additional developers. Once this flywheel starts spinning, it becomes almost impossible to stop.
The result is that NVIDIA sells you the most expensive shovel and also defines the only way to dig. Want to change shovels? Fine. But you'll have to rewrite all the experience, tools, and code accumulated over the past decade by hundreds of thousands of the smartest brains worldwide using that specific method.
Who pays for that cost?
So, when the first round of controls landed on October 7, 2022, with BIS restricting exports of NVIDIA's A100 and H100 to China, Chinese AI companies collectively felt a ZTE-like suffocation for the first time. NVIDIA subsequently launched "China-specific" A800 and H800 chips, reducing the inter-chip interconnect speed, barely maintaining supply.
But just a year later, on October 17, 2023, a second round of controls tightened further, banning A800 and H800 as well, and adding 13 Chinese companies to the Entity List. NVIDIA had to launch a further neutered version, the H20. By December 2024, the final round of controls during the Biden administration landed, strictly limiting even H20 exports.
Three rounds of controls, escalating step by step.
But this time, the story's direction is completely different from that of ZTE back then.
An Asymmetric Breakout
Under the ban, everyone thought the dream of Chinese AI large models would end there.
They were wrong. Faced with the blockade, Chinese companies did not choose a head-on confrontation but began a breakout. The first battlefield of this breakout was not in chips, but in algorithms.
From late 2024 to 2025, Chinese AI companies collectively turned to a technical direction: Mixture of Experts (MoE) models.
Simply put, this means splitting a huge model into many small experts, activating only the most relevant few when processing a task, rather than engaging the entire model.
DeepSeek's V3 is a typical example of this approach. It has 671 billion parameters, but only activates 37 billion of them during each inference, just 5.5% of the total. In terms of training cost, it used 2048 NVIDIA H800 GPUs, trained for 58 days, with a total cost of $5.576 million. In comparison, external estimates for GPT-4's training cost are around $78 million. A difference of an order of magnitude.
Extreme optimization in algorithms directly reflected in pricing. DeepSeek's API price is $0.028 to $0.28 per million input tokens, and $0.42 for output. GPT-4o's input price is $5, output $15. Claude Opus is even more expensive, $15 input, $75 output. Converted, DeepSeek is 25 to 75 times cheaper than Claude.
This price difference had a huge impact on the global developer market. In February 2026, on OpenRouter, the world's largest AI model API aggregation platform, the weekly call volume for Chinese AI models surged 127% in three weeks, surpassing the U.S. for the first time. A year earlier, Chinese models had less than 2% share on OpenRouter. A year later, it grew 421%, approaching 60%.
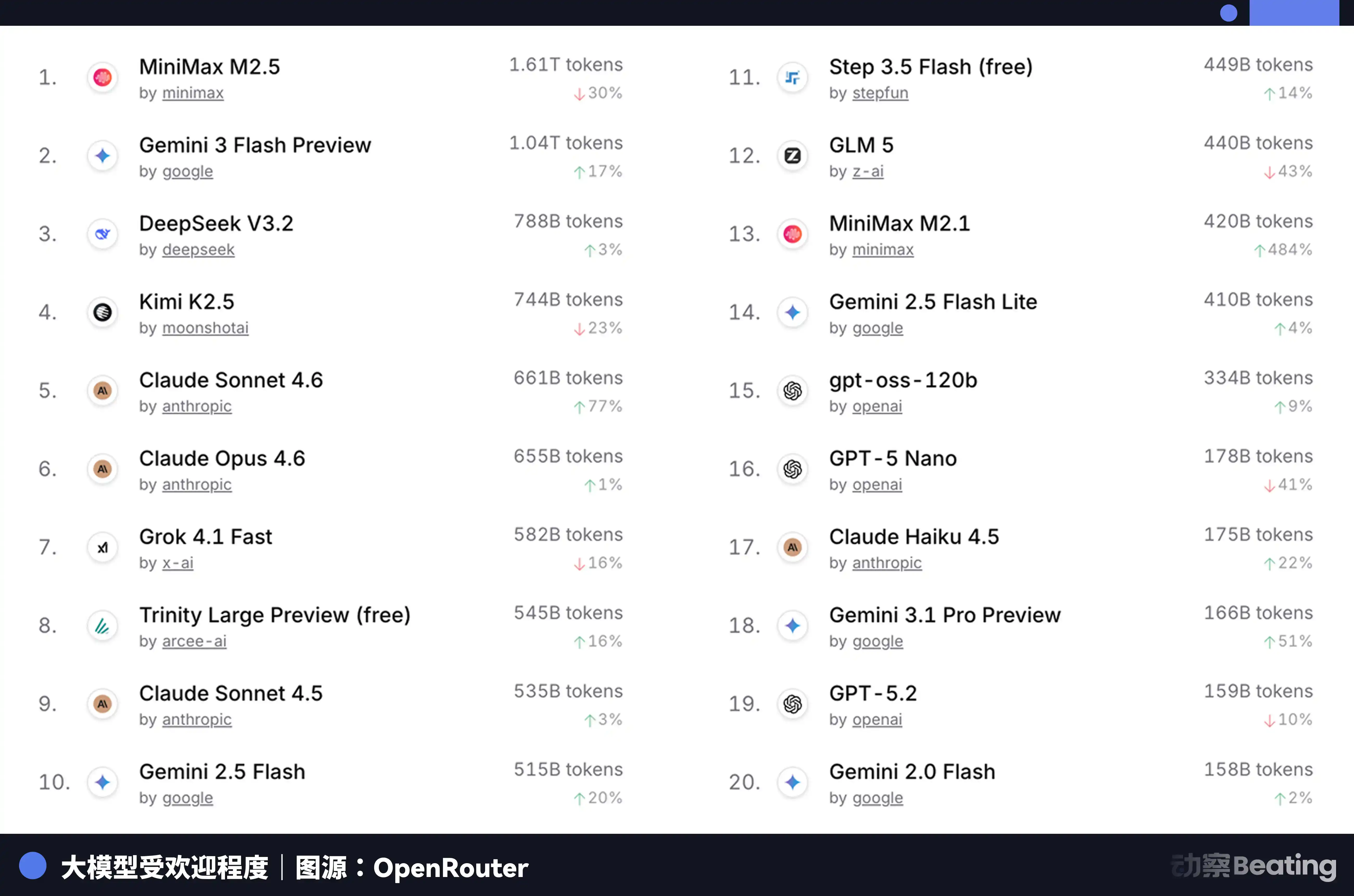
Behind this data lies a structural change that is easy to overlook. Starting in the second half of 2025, the mainstream scenario for AI applications shifted from chat to Agent. In Agent scenarios, the token consumption for a single task is 10 to 100 times that of simple chat. When token consumption grows exponentially, price becomes the decisive factor. The extreme cost-effectiveness of Chinese models恰好踩中了这个窗口 (happened to hit this window perfectly).
But the problem is, reducing inference cost does not solve the fundamental problem of training. A large model that cannot be continuously trained and iterated on new data will see its capabilities degrade rapidly. And training remains that unavoidable computing black hole.
So, where do the "shovels" for training come from?
The Backup Plan Goes Mainstream
Xinghua, Jiangsu, a small city in central Jiangsu, known for stainless steel and health food, previously had no relation to AI. But in 2025, a 148-meter-long production line for domestic computing servers was built and put into operation here, taking only 180 days from signing to production.
The core of this production line is two fully domestic chips: the Loongson 3C6000 processor and the Taichu Yuanqi T100 AI accelerator card. The Loongson 3C6000 is entirely self-developed, from instruction set to microarchitecture. Taichu Yuanqi emerged from the National Supercomputing Center in Wuxi and a Tsinghua University team, adopting a heterogeneous many-core architecture.
At full capacity, this line produces one server every 5 minutes. The total investment for this production line is 1.1 billion yuan, with an expected annual output of 100,000 units.
More importantly, clusters based on these domestic chips, comprising tens of thousands of cards, have begun undertaking real large model training tasks.
In January 2026, Zhipu AI, in collaboration with Huawei, released GLM-Image, the first SOTA image generation model fully trained from start to finish relying on domestic chips. In February, China Telecom's billion-parameter "Star" large model completed its full training process on a domestic 10,000-card computing pool in Shanghai's Lingang.

The significance of these cases is that they prove one thing: domestic chips have transitioned from "usable for inference" to "usable for training." This is a qualitative change. Inference only requires running a pre-trained model, which places relatively lower demands on the chip; training requires processing massive data, performing complex gradient calculations and parameter updates, demanding an order of magnitude higher requirements for chip computing power, interconnect bandwidth, and software ecosystem.
The core force承担这些任务 (undertaking these tasks) is Huawei's Ascend series chips. As of the end of 2025, the Ascend ecosystem had surpassed 4 million developers, with over 3,000 partners; 43 mainstream large models completed pre-training based on Ascend, and over 200 open-source models were adapted. At the MWC conference on March 2, 2026, Huawei also launched its new computing base, SuperPoD, for overseas markets.
Ascend 910B's FP16 computing power is already comparable to NVIDIA's A100. Although the gap still exists, it has gone from unusable to usable, and from usable to becoming good. Ecosystem building cannot wait until the chips are perfect; it must be rolled out on a large scale at the usable stage, using real business needs to force the iteration of chips and software. ByteDance, Tencent, and Baidu's targets for importing domestic computing servers普遍较上一年翻倍增长 (generally doubled compared to the previous year) in 2026. Data from the Ministry of Industry and Information Technology shows China's intelligent computing scale has reached 1590 EFLOPS. 2026 is becoming the first year of large-scale deployment for domestic computing.
U.S. Power Shortages and China's Overseas Expansion
In early 2026, Virginia, which carries a large amount of data center traffic globally, suspended approval for new data center construction projects. Georgia followed suit, extending the suspension until 2027. Illinois and Michigan also introduced restrictions.
According to data from the International Energy Agency, U.S. data center electricity consumption reached 183 TWh in 2024, accounting for about 4% of the nation's total electricity consumption. By 2030, this number is expected to double to 426 TWh, potentially exceeding 12%. Arm's CEO predicted that by 2030, AI data centers would consume 20% to 25% of U.S. electricity.
The U.S. power grid is already overwhelmed. The PJM grid, covering 13 eastern U.S. states, faces a 6GW capacity shortfall. By 2033, the U.S. overall faces a 175GW power capacity gap, equivalent to the electricity consumption of 130 million households. Wholesale electricity costs in data center concentrated areas are 267% higher than five years ago.
The end of computing power is energy. And on the energy dimension, the gap between China and the U.S. is even larger than in chips, just in the opposite direction.
China's annual electricity generation is 10.4 trillion kWh, while the U.S. is 4.2 trillion kWh; China's is 2.5 times that of the U.S. More crucially, residential electricity consumption in China accounts for only 15% of total electricity usage, while in the U.S. this proportion is 36%. This means China has far more industrial electricity surplus available for computing construction than the U.S.
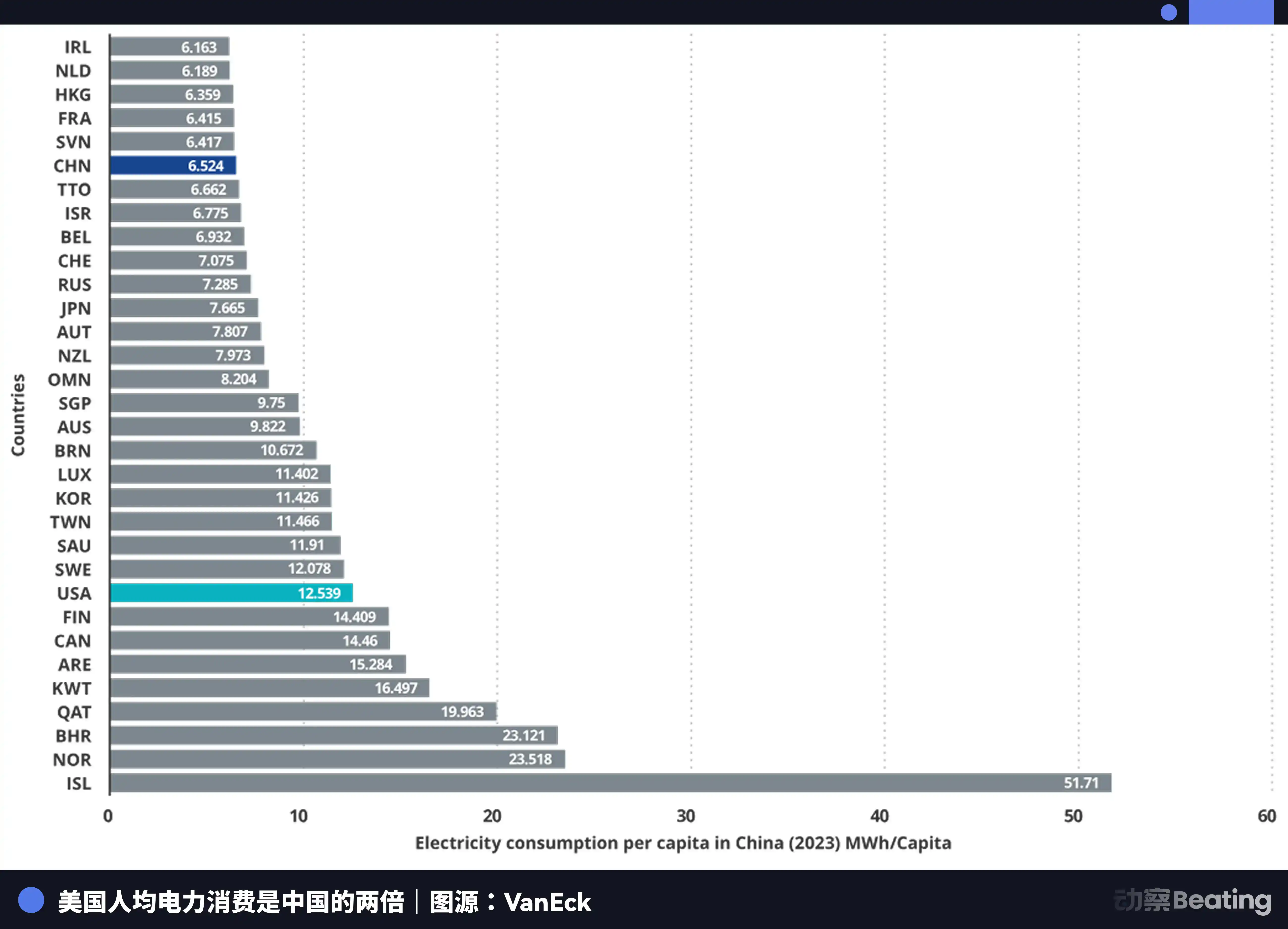
In terms of electricity prices, the price in U.S. AI company hubs is $0.12 to $0.15 per kWh, while industrial electricity prices in western China are about $0.03, only a quarter to a fifth of the U.S. price.
China's power generation growth is already 7 times that of the U.S.
Just as the U.S. worries about electricity, Chinese AI is quietly going global. But this time, what's going overseas is not products, not factories, but Tokens.
Tokens, the smallest unit of information processed by AI models, are becoming a new digital commodity. They are produced in Chinese computing factories and transmitted globally via submarine cables.
DeepSeek's user distribution data is telling: 30.7% in mainland China, 13.6% in India, 6.9% in Indonesia, 4.3% in the U.S., 3.2% in France. It supports 37 languages and is widely popular in emerging markets like Brazil. Globally, 26,000 enterprises have opened accounts, and 3,200 institutions have deployed the enterprise version.
In 2025, 58% of new AI startups included DeepSeek in their tech stack. In China, DeepSeek captured 89% market share. In other sanctioned countries, market share ranged from 40% to 60%.
This scene is reminiscent of another war about industrial autonomy forty years ago.
In Tokyo, 1986, under strong pressure from the U.S., the Japanese government signed the U.S.-Japan Semiconductor Agreement. The core clauses of the agreement were three: requiring Japan to open its semiconductor market, with U.S. chip market share in Japan必须达到 20% 以上 (must reach over 20%); strictly prohibiting Japanese semiconductors from being exported below cost; and imposing 100% punitive tariffs on $300 million worth of chips exported from Japan. Simultaneously, the U.S. vetoed Fujitsu's acquisition of Fairchild Semiconductor.
That year, the Japanese semiconductor industry was at its peak. In 1988, Japan controlled 51% of the global semiconductor market share, while the U.S. had only 36.8%. Six of the world's top ten semiconductor companies were Japanese: NEC ranked second, Toshiba third, Hitachi fifth, Fujitsu seventh, Mitsubishi eighth, and Panasonic ninth. In 1985, Intel lost $173 million in the U.S.-Japan semiconductor war,濒临破产 (on the verge of bankruptcy).
But after the agreement was signed, everything changed.
The U.S., through means like Section 301 investigations, launched a comprehensive suppression of Japanese semiconductor companies. Simultaneously, it扶持 (supported) South Korea's Samsung and Hynix to impact Japan's market with lower prices. Japan's DRAM share fell from 80% to 10%. By 2017, Japan's IC market share was only 7%. Once-invincible giants were either split up, acquired, or left the scene黯然离场 (dimly) amidst endless losses.
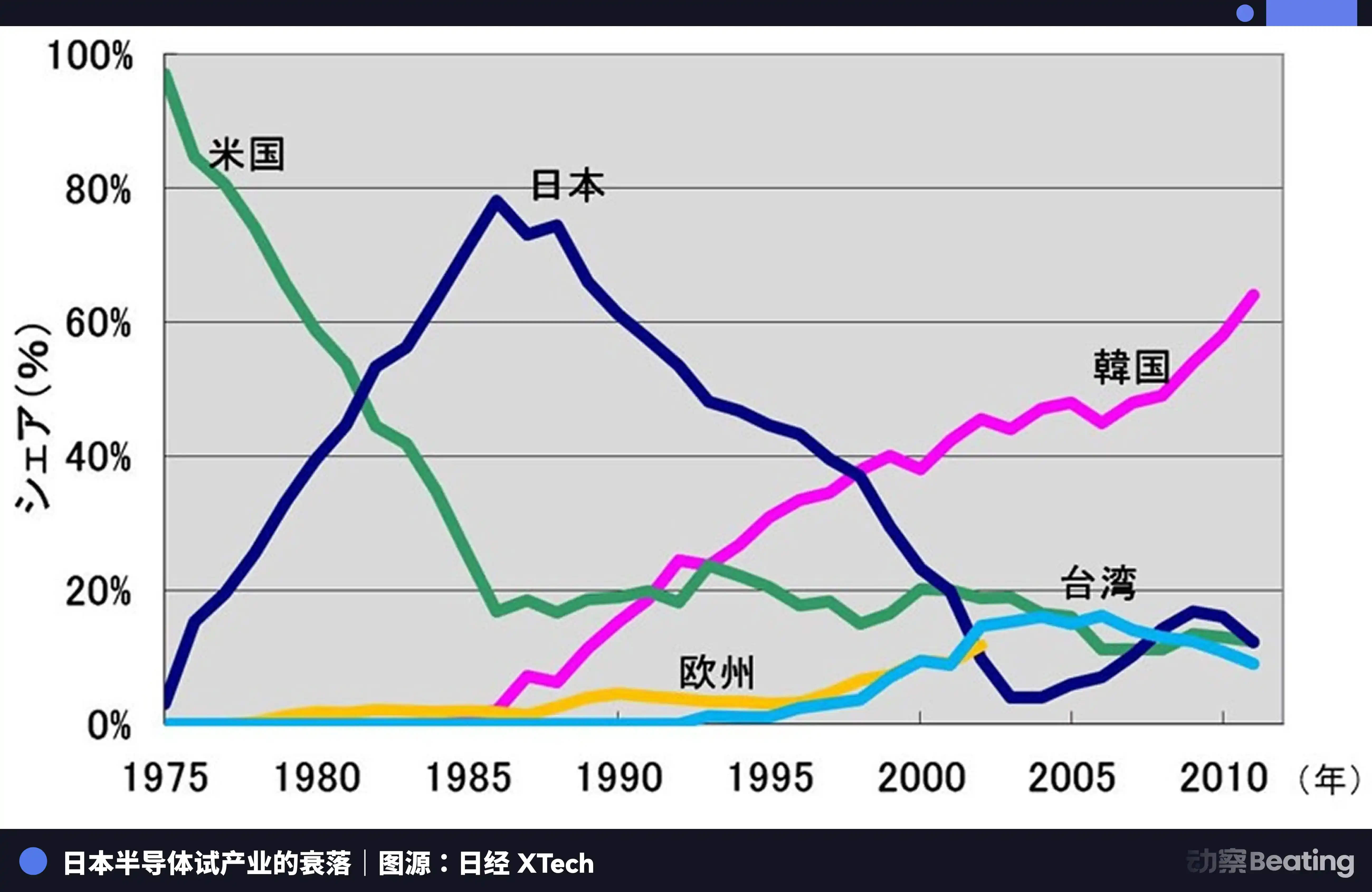
The tragedy of Japanese semiconductors was that they were content being the most excellent producer within a global division of labor system dominated by a single external force, but never thought to build an independent ecosystem of their own. When the tide went out, they found they had nothing but production itself.
Today, China's AI industry stands at a similar yet completely different crossroads.
Similar in that we同样面临着来自外部的巨大压力 (also face huge external pressure). Three rounds of chip controls, escalating step by step, the barrier of the CUDA ecosystem依然高耸 (still stands tall).
Different in that this time, we have chosen a more difficult path. From extreme optimization at the algorithm level, to the leap of domestic chips from inference to training, to the accumulation of 4 million developers in the Ascend ecosystem, to the penetration of global markets through Token exports. Every step on this path is building an independent industrial ecosystem that Japan never possessed back then.
Epilogue
On February 27, 2026, performance reports from three local AI chip companies were released on the same day.
Cambricon, revenue surged 453%, achieving full-year profitability for the first time. Moore Threads, revenue grew 243%, but with a net loss of 1 billion yuan. MetaX, revenue grew 121%, with a net loss of nearly 800 million yuan.
Half flame, half seawater.
The flame is the market's extreme hunger. The 95% void left by Jensen Huang is being filled, inch by inch, by the revenue figures of these local companies. Regardless of performance, regardless of the ecosystem, the market needs a second choice besides NVIDIA. This is a once-in-a-lifetime structural opportunity torn open by geopolitics.
The seawater is the huge cost of ecosystem building. Every cent of loss is real money paid to catch up with the CUDA ecosystem. It's R&D investment, software subsidies, the人力成本 (human cost) of engineers stationed at customer sites solving compilation issues one by one. These losses are not operational failures but the war tax that must be paid to build an independent ecosystem.
These three financial reports, more honestly than any industry report, record the true face of this computing war. It is not a triumphant victory march but a brutal battle of attrition, charging forward while bleeding.
But the form of the war has indeed changed. Eight years ago, we discussed the question of "whether we can survive." Today, we discuss the question of "what price must be paid to survive."
The price itself is progress.







