Titre original : A shallow dive into formal verification
Auteur original : Vitalik
Traduction originale : Peggy, BlockBeats
Note de l'éditeur : Alors que la capacité de programmation de l'IA progresse rapidement, la sécurité des logiciels fait face à un nouveau paradoxe : l'IA peut générer du code plus efficacement, mais elle peut aussi découvrir des vulnérabilités plus efficacement. Pour l'industrie de la cryptographie, cette question est particulièrement cruciale. Si un contrat intelligent, une preuve ZK, un algorithme de consensus ou un système d'actifs on-chain présente un défaut, les conséquences ne sont souvent pas une simple erreur logicielle, mais une perte de fonds irréversible et un effondrement de la confiance.
Dans cet article, Vitalik discute précisément d'une autre voie pour la sécurité du code à l'ère de l'IA : la vérification formelle. En termes simples, elle ne repose pas sur des auditeurs humains vérifiant le code ligne par ligne, mais consiste à écrire les propriétés que le programme doit satisfaire sous forme de propositions mathématiques, puis à vérifier à l'aide de preuves vérifiables par machine si ces propriétés sont respectées. Par le passé, la vérification formelle, en raison de son seuil d'entrée élevé et de son processus fastidieux, est restée confinée à des domaines de recherche et d'ingénierie relativement niche ; mais avec la capacité de l'IA à assister dans l'écriture du code et des preuves, cette approche acquiert une nouvelle pertinence pratique.
Le jugement central de l'article n'est pas que « la vérification formelle peut résoudre tous les problèmes de sécurité ». Au contraire, Vitalik rappelle à plusieurs reprises que la « sécurité prouvée » n'est pas équivalente à une sécurité absolue : les preuves peuvent omettre des hypothèses cruciales, la spécification elle-même peut être mal écrite, le code non vérifié, les limites matérielles et les attaques par canaux auxiliaires peuvent également devenir de nouvelles sources de risque. Mais elle offre néanmoins un paradigme de sécurité plus fiable : exprimer l'intention du développeur de multiples manières, puis laisser le système vérifier automatiquement la compatibilité entre ces expressions.
Cela est particulièrement important pour Ethereum. Le futur Ethereum reposera de plus en plus sur des composants sous-jacents complexes, notamment STARK, ZK-EVM, les signatures post-quantiques, les algorithmes de consensus et les implémentations EVM haute performance. La mise en œuvre de ces systèmes est extrêmement complexe, mais leurs objectifs de sécurité centraux peuvent souvent être formalisés de manière relativement claire. C'est précisément dans ce type de scénario que la vérification formelle assistée par l'IA pourrait déployer sa valeur maximale : laisser l'IA écrire du code et des preuves efficaces, et laisser les humains vérifier que les propositions finalement prouvées correspondent bien aux objectifs de sécurité visés.
D'un point de vue plus large, cet article est aussi une réponse de Vitalik à la sécurité des réseaux à l'ère de l'IA. Face à des attaquants IA plus puissants, la réponse n'est pas d'abandonner l'open source, les contrats intelligents, ou de revenir à la dépendance envers quelques institutions centralisées, mais de comprimer les systèmes critiques en un « noyau de sécurité » plus petit, plus vérifiable et plus digne de confiance. L'IA augmentera la quantité de code grossier, mais elle pourrait aussi rendre le code véritablement important plus sûr qu'auparavant.
Voici le texte original :
Remerciements particuliers à Yoichi Hirai, Justin Drake, Nadim Kobeissi et Alex Hicks pour leurs retours et relectures de cet article.
Ces derniers mois, un nouveau paradigme de programmation émerge rapidement à la pointe de la recherche sur Ethereum et dans de nombreux autres domaines de l'informatique : les développeurs écrivent directement du code dans des langages de très bas niveau, comme le bytecode EVM, l'assembleur, ou en utilisant Lean, et vérifient sa correction par des preuves mathématiques vérifiables automatiquement écrites dans Lean.
Utilisée correctement, cette approche a le potentiel de produire du code extrêmement efficace, et pourrait être bien plus sûre que les méthodes de développement logiciel passées. Yoichi Hirai la qualifie de « forme finale du développement logiciel ». Cet article tentera d'expliquer la logique fondamentale de cette méthode : ce que la vérification formelle des logiciels peut réellement accomplir, et où se situent ses limites et ses frontières – tant dans le contexte d'Ethereum que dans le domaine plus large du développement logiciel.
Qu'est-ce que la vérification formelle ?
La vérification formelle consiste à écrire la preuve d'un théorème mathématique d'une manière qui peut être vérifiée automatiquement par une machine.
Pour donner un exemple relativement simple mais toujours intéressant, prenons un théorème de base sur la suite de Fibonacci : un nombre sur trois est pair, les deux autres sont impairs.

Une preuve simple est d'utiliser la récurrence mathématique, en avançant de trois à chaque étape.
D'abord le cas de base. Soit F1 = F2 = 1, F3 = 2. Par observation directe, on voit que la proposition – « lorsque i est un multiple de 3, Fi est pair ; dans les autres cas, Fi est impair » – est vraie jusqu'à x = 3.
Ensuite l'étape de récurrence. Supposons que la proposition soit vraie jusqu'à 3k+3, c'est-à-dire que nous sachions que F3k+1, F3k+2, F3k+3 sont respectivement impair, impair, pair. Nous pouvons alors calculer la parité du groupe suivant de trois nombres :
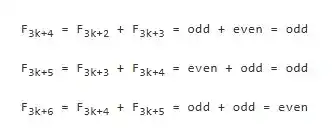
Ainsi, nous avons démontré le passage de « la proposition est connue vraie jusqu'à 3k+3 » à « la proposition est confirmée vraie jusqu'à 3k+6 ». En répétant ce raisonnement, on peut être convaincu que cette loi est vraie pour tous les entiers.
Cet argument est convaincant pour un humain. Mais que faire si ce que vous voulez prouver est cent fois plus complexe, et que vous voulez vraiment être sûr de ne pas vous tromper ? Vous pouvez alors construire une preuve qui convaincra aussi un ordinateur.
Cela ressemblerait à peu près à ceci :

C'est le même raisonnement, mais exprimé en Lean. Lean est un langage de programmation souvent utilisé pour écrire et vérifier des preuves mathématiques.
Cela semble très différent de la preuve « humaine » que j'ai donnée plus haut, et pour une bonne raison : ce qui est intuitif pour un ordinateur est très différent de ce qui est intuitif pour un humain. Ici, ordinateur se réfère au sens ancien – un programme « déterministe » composé d'instructions if/then, et non pas un grand modèle de langage.
Dans la preuve ci-dessus, vous ne soulignez pas le fait que fib(3k+4) = fib(3k+3) + fib(3k+2) ; vous soulignez que fib(3k+3) + fib(3k+2) est impair, et la tactique omega de Lean, au nom plutôt grandiose, combine automatiquement cela avec sa compréhension de la définition de fib(3k+4).
Dans des preuves plus complexes, vous devez parfois préciser à chaque étape quelle loi mathématique vous permet de franchir cette étape, et ces lois portent parfois des noms obscurs comme Prod.mk.inj. Mais d'un autre côté, vous pouvez aussi développer une expression polynomiale énorme en une seule étape, et simplement écrire une expression comme omega ou ring pour conclure l'argument.
Ce manque d'intuitivité et cette lourdeur sont des raisons majeures pour lesquelles les preuves vérifiables par machine, bien qu'existant depuis près de 60 ans, sont restées un domaine de niche. Mais en même temps, de nombreuses choses autrefois presque impossibles deviennent rapidement réalisables grâce aux progrès rapides de l'IA.
Vérifier les programmes informatiques
À ce stade, vous pourriez penser : D'accord, donc nous pouvons faire vérifier par un ordinateur la preuve d'un théorème mathématique, ce qui nous permettra enfin de déterminer quelles nouvelles découvertes folles sur les nombres premiers, par exemple, sont vraies et lesquelles sont des erreurs cachées dans un PDF de cent pages. Peut-être pourrons-nous même déterminer si la preuve de Shinichi Mochizuki sur la conjecture ABC est correcte ! Mais à part satisfaire la curiosité, quelle est l'utilité pratique de cela ?
Il y a plusieurs réponses. Et pour moi, une réponse très importante est : vérifier la correction des programmes informatiques, en particulier ceux impliquant de la cryptographie ou de la sécurité. Après tout, un programme informatique est lui-même un objet mathématique. Prouver qu'un programme informatique s'exécute d'une certaine manière, c'est essentiellement prouver un théorème mathématique.
Par exemple, supposons que vous souhaitiez prouver si un logiciel de communication cryptée comme Signal est véritablement sécurisé. Vous pouvez d'abord écrire mathématiquement ce que « sécurité » signifie dans ce contexte. Grosso modo, vous voulez prouver que, sous certaines hypothèses cryptographiques, seule une personne possédant la clé privée peut obtenir la moindre information sur le contenu du message. En réalité, il existe de nombreuses propriétés de sécurité vraiment importantes.
Et il s'avère qu'une équipe tente effectivement de comprendre cela. L'un des théorèmes de sécurité qu'ils proposent ressemble à ceci :

Voici le résumé par Leanstral de la signification de ce théorème :
Le théorème passive_secrecy_le_ddh est une réduction serrée montrant que, dans le modèle de l'oracle aléatoire, la confidentialité passive des messages de X3DH est au moins aussi difficile à casser que l'hypothèse DDH.
En d'autres termes, si un attaquant peut casser la confidentialité passive des messages de X3DH, alors il peut aussi casser DDH. Puisque DDH est généralement supposé difficile, X3DH peut donc être considéré comme résistant aux attaques passives.
Le théorème prouve que si un attaquant ne peut qu'observer passivement les messages d'échange de clés de Signal, alors il ne peut pas distinguer la clé de session finale d'une clé aléatoire avec un avantage supérieur à une probabilité négligeable.
En combinant cela avec une preuve qu'AES est correctement implémenté, on obtient une preuve que le mécanisme de chiffrement du protocole Signal résiste aux attaquants passifs.
Des projets de vérification similaires existent pour prouver l'implémentation sécurisée de TLS et d'autres composants cryptographiques dans les navigateurs.
Si vous pouvez effectuer une vérification formelle de bout en bout, vous prouvez non seulement qu'une description théorique d'un protocole est sécurisée, mais aussi que le code spécifique que les utilisateurs exécutent réellement est sécurisé en pratique. Du point de vue de l'utilisateur, cela améliore considérablement le degré de « confiance minimale » : pour faire entièrement confiance à ce code, vous n'avez pas besoin de vérifier ligne par ligne l'ensemble de la base de code, vous n'avez qu'à vérifier les affirmations qui ont été prouvées.
Bien sûr, il faut mettre des astérisques très importants, surtout concernant ce que signifie exactement le mot « sécurité ». Il est facile d'oublier de prouver les affirmations réellement importantes ; il est facile de se retrouver dans une situation où l'affirmation à prouver n'a pas de description plus concise que le code lui-même ; il est facile d'introduire subrepticement dans la preuve des hypothèses qui s'avèrent finalement fausses. Il est aussi facile de décider qu'une seule partie du système a réellement besoin d'une preuve formelle, pour finalement être frappé par une vulnérabilité critique dans une autre partie, ou même au niveau matériel. Même l'implémentation de Lean elle-même peut contenir des bugs. Mais avant d'aborder ces détails épineux, examinons d'abord la perspective quasi utopique que la vérification formelle pourrait offrir si elle était réalisée de manière idéale et correcte.
Vérification formelle orientée sécurité
Les bugs dans le code informatique sont déjà inquiétants.
Lorsque vous placez des cryptomonnaies dans des contrats intelligents immuables on-chain, les bugs de code deviennent encore plus effrayants. Parce que si le code est erroné, des pirates nord-coréens peuvent automatiquement transférer tout votre argent, et vous n'avez presque aucun recours.
Lorsque tout cela est enveloppé dans des preuves à connaissance nulle, les bugs de code deviennent encore plus effrayants. Parce que si quelqu'un parvient à casser le système de preuve à connaissance nulle, il peut retirer tous les fonds, et nous pourrions ne pas savoir du tout ce qui n'a pas fonctionné – ou pire, nous pourrions ne pas savoir que le problème s'est produit.
Lorsque nous avons des modèles d'IA puissants, les bugs de code deviennent encore plus effrayants. Des modèles comme Claude Mythos, après deux ans d'amélioration, pourraient automatiser la découverte de ces vulnérabilités.

Face à cette réalité, certains commencent à plaider pour l'abandon de l'idée même de contrat intelligent, voire estiment que l'espace cybernétique ne peut tout simplement pas être un domaine où la défense a un avantage asymétrique par rapport à l'attaque.
Voici quelques citations :
Pour durcir un système, vous devez dépenser plus de tokens pour découvrir les vulnérabilités que l'attaquant n'en dépense pour les exploiter.
Et aussi :
Notre industrie est construite autour du code déterministe. Écrire du code, tester, déployer, puis savoir qu'il fonctionne – mais d'après mon expérience, ce contrat est en train d'être rompu. Parmi les meilleurs opérateurs des entreprises véritablement natives de l'IA, les bases de code commencent à devenir quelque chose que « vous croyez fonctionnel », et cette croyance correspond à une probabilité qui ne peut plus être précisément énoncée.
Pire encore, certains pensent que la seule solution est d'abandonner l'open source.
Ce serait un avenir sombre pour la sécurité des réseaux. Surtout pour ceux qui se soucient de la décentralisation et de la liberté sur Internet. L'esprit crypto-punk tout entier est essentiellement fondé sur l'idée que sur Internet, la défense a l'avantage. Construire un « château » numérique – qu'il s'agisse de chiffrement, de signature ou de preuve – est plus facile que de le détruire. Si nous perdons cela, alors la sécurité d'Internet ne pourra venir que des économies d'échelle, de la traque des attaquants potentiels à l'échelle mondiale, et plus généralement, d'un choix : soit dominer tout, soit sombrer.
Je ne partage pas ce jugement. J'ai une vision bien plus optimiste de l'avenir de la sécurité des réseaux.
Je pense que le défi posé par les capacités puissantes de découverte de vulnérabilités par l'IA est réellement grave, mais c'est un défi transitoire. Une fois la poussière retombée et que nous aurons atteint un nouvel équilibre, nous arriverons à un état plus favorable à la défense qu'auparavant.
Mozilla est d'accord avec cela. En citant leurs propos :
Vous devrez peut-être réorganiser la priorité de toutes les autres tâches, et vous engager dans cette mission de manière continue et concentrée. Mais il y a une lumière au bout du tunnel. Nous sommes très fiers de voir comment l'équipe s'est mobilisée pour relever ce défi, et d'autres le feront aussi. Notre travail n'est pas terminé, mais nous avons franchi un point d'inflexion et commençons à voir un avenir bien meilleur que de simplement « suivre le rythme ». La défense a enfin une chance de remporter une victoire décisive.
......
Le nombre de défauts est fini, et nous entrons dans un monde où nous pouvons enfin tous les trouver.
Maintenant, si vous effectuez une recherche Ctrl+F pour « formal » et « verification » dans cet article de Mozilla, vous constaterez qu'aucun des deux mots n'apparaît. L'avenir positif de la sécurité des réseaux ne dépend pas strictement de la vérification formelle, ni d'aucune autre technologie unique.
Alors de quoi dépend-il ? Fondamentalement, de ce graphique :
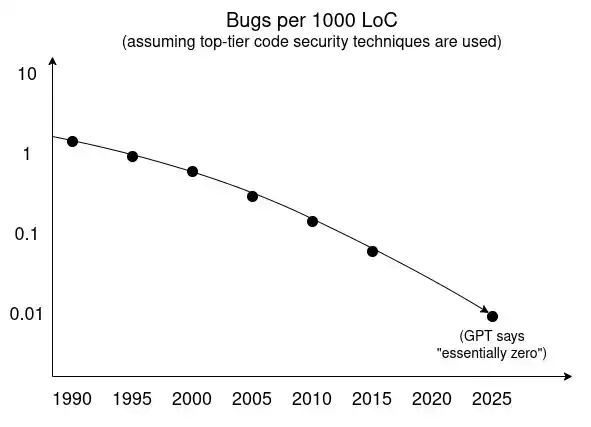
Au cours des dernières décennies, de nombreuses technologies ont favorisé la tendance à la « baisse du nombre de vulnérabilités » :
Les systèmes de types ;
Les langages à sécurité mémoire ;
Les améliorations de l'architecture logicielle, notamment le sandboxing, les mécanismes de permissions, et plus généralement la distinction claire entre la « base de calcul de confiance » (trusted computing base) et le « reste du code » ;
De meilleures méthodes de test ;
L'accumulation de connaissances sur les modèles de codage sécurisés et non sécurisés ;
Un nombre croissant de bibliothèques logicielles pré-écrites et auditées.
La vérification formelle assistée par l'IA ne doit pas être considérée comme un paradigme entièrement nouveau, mais comme un puissant accélérateur : elle accélère une tendance et un paradigme déjà en cours de progression.
La vérification formelle n'est pas une panacée. Mais dans certains scénarios, elle est particulièrement adaptée : lorsque l'objectif est bien plus simple que l'implémentation spécifique. Cela est particulièrement évident dans certaines des technologies les plus difficiles à déployer pour la prochaine itération majeure d'Ethereum, comme les signatures post-quantiques, STARK, les algorithmes de consensus et ZK-EVM.
STARK est un logiciel très complexe. Mais la propriété de sécurité centrale qu'il met en œuvre est facile à comprendre et à formaliser : si vous voyez une preuve pointant vers un hachage H d'un programme P, d'une entrée x et d'une sortie y, alors soit l'algorithme de hachage utilisé par STARK a été cassé, soit P(x) = y. Nous avons donc le projet Arklib, qui tente de créer une implémentation STARK entièrement vérifiée formellement. Un autre projet connexe est VCV-io, qui fournit une infrastructure de calcul d'oracle fondamentale pouvant être utilisée pour la vérification formelle de divers protocoles cryptographiques, dont beaucoup sont eux-mêmes des dépendances de STARK.
Plus ambitieux encore est evm-asm : un projet qui tente de construire une implémentation EVM complète et de la vérifier formellement. Ici, la propriété de sécurité est moins claire. Grosso modo, son objectif est de prouver que cette implémentation est équivalente à une autre implémentation EVM écrite en Lean ; cette dernière pouvant privilégier l'intuitivité et la lisibilité sans se soucier de l'efficacité d'exécution.
Bien sûr, il pourrait théoriquement arriver que nous ayons dix implémentations EVM, toutes prouvées équivalentes entre elles, mais partageant toutes le même défaut fatal, qui permettrait en quelque sorte à un attaquant de transférer tous les ETH depuis une adresse qu'il ne contrôle pas. Mais la probabilité que cela se produise est bien plus faible que celle qu'une seule implémentation EVM ait ce défaut aujourd'hui. Une autre propriété de sécurité dont nous avons réalisé l'importance à nos dépens – la résistance aux DoS – est relativement facile à spécifier explicitement.
Deux autres directions importantes sont :
Le consensus tolérant aux pannes byzantines. Dans cette direction, la définition formelle de toutes les propriétés de sécurité souhaitées n'est pas non plus facile. Mais étant donné que les bugs associés sont très courants, tenter une vérification formelle en vaut la peine. Il existe donc déjà des travaux en cours sur une implémentation de consensus en Lean et ses preuves.
Les langages de programmation de contrats intelligents. Des exemples incluent les travaux de vérification formelle dans Vyper et Verity.
Dans tous ces cas, une énorme valeur ajoutée de la vérification formelle est que ces preuves sont véritablement de bout en bout. Beaucoup des bugs les plus difficiles sont des bugs d'interaction, qui apparaissent à la frontière entre deux sous-systèmes considérés séparément. Pour un humain, raisonner sur l'ensemble du système de bout en bout est trop difficile ; mais un système automatisé de vérification des règles peut le faire.
Vérification formelle orientée efficacité
Revenons à evm-asm. C'est une implémentation EVM.
Mais c'est une implémentation EVM écrite directement en langage assembleur RISC-V.
Littéralement de l'assembleur.
Voici l'opcode ADD :
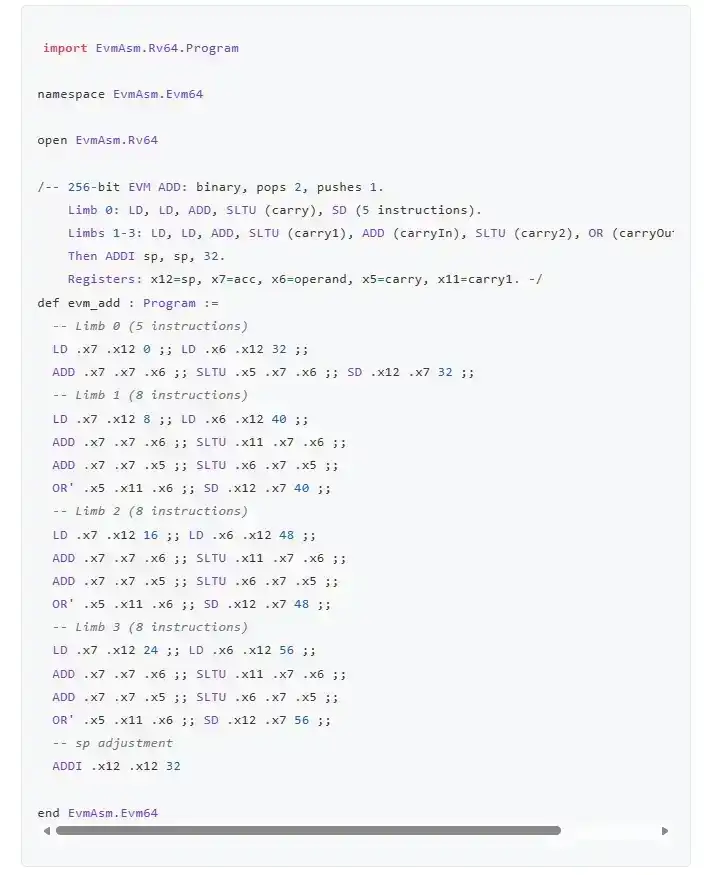
RISC-V est choisi parce que les prouveurs ZK-EVM en cours de construction fonctionnent généralement en prouvant RISC-V et en compilant le client Ethereum vers RISC-V. Donc, si vous écrivez directement une implémentation EVM en RISC-V, elle devrait en théorie être l'implémentation la plus rapide possible. RISC-V peut aussi être simulé très efficacement sur des ordinateurs ordinaires, et des ordinateurs portables RISC-V existent. Bien sûr, pour être véritablement de bout en bout, il faudrait aussi vérifier formellement l'implémentation RISC-V elle-même, ou la représentation arithmétisée du prouveur. Mais ne vous inquiétez pas – ce genre de travail existe déjà.
Écrire du code directement en assembleur, c'est ce que nous faisions souvent il y a cinquante ans. Depuis, nous sommes passés progressivement à l'écriture de code dans des langages de haut niveau. Les langages de haut niveau sacrifient une certaine efficacité, mais en échange, ils rendent l'écriture du code beaucoup plus rapide, et surtout, la compréhension du code des autres beaucoup plus rapide – ce qui est une condition nécessaire à la sécurité.
Avec la combinaison de la vérification formelle et de l'IA, nous avons l'occasion de « retourner vers le futur ». Concrètement, c'est-à-dire laisser l'IA écrire le code assembleur, puis écrire une preuve formelle vérifiant que ce code assembleur possède les propriétés que nous souhaitons. Au minimum, cette propriété cible pourrait simplement être : elle est totalement équivalente à une implémentation écrite dans un langage de haut niveau convivial pour l'homme, optimisée pour la lisibilité.
Ainsi, un même objet code n'aurait plus à faire un compromis entre lisibilité et efficacité. Nous aurions deux objets séparés : une implémentation en assembleur, optimisée uniquement pour l'efficacité et adaptée aux besoins de l'environnement d'exécution spécifique ; et une affirmation de sécurité, ou une implémentation en langage de haut niveau, optimisée uniquement pour la lisibilité. Ensuite, nous utilisons une preuve mathématique pour prouver l'équivalence entre les deux. Les utilisateurs peuvent d'abord vérifier automatiquement cette preuve une fois ; après cela, ils n'ont plus qu'à exécuter la version rapide.
C'est très puissant. Yoichi Hirai l'appelle « la forme finale du développement logiciel », et ce n'est pas sans raison.
La vérification formelle n'est pas une panacée
En cryptographie et en informatique, il existe une tradition presque aussi ancienne que les méthodes formelles elles-mêmes : critiquer les méthodes formelles, ou plus généralement, critiquer la dépendance aux « preuves ». La littérature contient de nombreux exemples pratiques. Commençons par les preuves manuscrites plus simples du début de la cryptographie. Menezes et Koblitz les critiquaient ainsi en 2004 :
En 1979, Rabin proposa une fonction de chiffrement « prouvablement » sûre en un certain sens, c'est-à-dire possédant une propriété de sécurité par réduction.
L'affirmation de sécurité par réduction est : toute personne capable de retrouver le message m à partir du chiffré y doit aussi être capable de factoriser n.
Peu après que Rabin ait proposé son schéma de chiffrement, Rivest fit remarquer qu'il était ironique que la caractéristique même qui lui conférait une sécurité supplémentaire entraînait aussi l'effondrement complet du système face à un autre type d'attaquant. Ce type d'attaquant est appelé attaquant « à chiffré choisi ». Plus précisément, supposons que l'attaquant parvienne d'une manière ou d'une autre à inciter Alice à déchiffrer un chiffré de son choix. Alors, l'attaquant pourrait factoriser n en suivant exactement la même procédure que celle utilisée par Sam dans le paragraphe précédent.
Menezes et Koblitz donnent ensuite plusieurs autres exemples. Ensemble, ils révèlent un modèle : concevoir des protocoles cryptographiques autour de ce qui est « plus facile à prouver » tend à les rendre moins « naturels » et plus susceptibles de s'effondrer dans des scénarios que le concepteur n'avait même pas envisagés.
Revenons maintenant aux preuves vérifiables par machine et au code. Voici un exemple tiré d'un article de 2011, où des bugs ont été trouvés dans un compilateur C vérifié formellement :
Le deuxième problème de CompCert que nous avons trouvé se manifeste par deux bugs. Ces deux bugs génèrent un code ressemblant à ceci : stwu r1, -44432(r1)
Il s'agit d'allouer un très grand cadre de pile PowerPC. Le problème est que le champ de déplacement sur 16 bits déborde. La sémantique PPC de CompCert ne spécifie pas de contrainte sur la largeur de cette valeur immédiate, car elle suppose que l'assembleur attraperait les valeurs hors limites.
Voyons un article de 2022 :
Dans CompCert-KVX, le commit e2618b31 a corrigé un bug : l'instruction « nand » était imprimée comme « and » ; et « nand » n'était sélectionnée que dans le mode rare ~(a & b). Ce bug a été découvert en compilant des programmes générés aléatoirement.
Aujourd'hui, en 2026, Nadim Kobeissi, en décrivant les vulnérabilités des logiciels vérifiés formellement dans Cryspen, écrit :
En novembre 2025, Filippo Valsorda a signalé indépendamment que libcrux-ml-dsa v0.0.3 générait des clés publiques et des signatures différentes sur différentes plateformes pour la même entrée déterministe. Ce bug se trouvait dans le wrapper de la fonction intrinsèque _vxarq_u64, qui implémente l'opération XAR utilisée dans la permutation Keccak-f de SHA-3. Le chemin de repli passait un mauvais paramètre à l'opération de décalage, ce qui corrompait les condensés SHA-3 sur les plateformes ARM64 sans support matériel SHA-3. Il s'agit d'un échec de type I : cette fonction intrinsèque était marquée comme vérifiée, et l'ensemble du backend NEON n'avait pas de preuve de sécurité ou de correction à l'exécution.
Et aussi :
La crate libcrux-psq implémente un protocole de clé pré-partagée post-quantique. Dans la méthode decrypt_out, le chemin de déchiffrement AES-GCM 128 appelait .unwrap() sur le résultat du déchiffrement, au lieu de propager l'erreur. Un chiffré malformé pouvait faire planter le processus.
Ces quatre problèmes peuvent être classés en deux catégories :
La première est que seul une partie du code a été vérifiée, car vérifier le reste était trop difficile ; et il s'est avéré que le code non vérifié était plus sujet aux bugs que les auteurs ne le pensaient, et ces bugs étaient souvent plus critiques.
La seconde est que les auteurs ont oublié de spécifier explicitement une propriété cruciale qui devait être prouvée.
L'article de Nadim classe les modes d'échec de la vérification formelle ; il énumère également d'autres types d'échecs. Par exemple, un autre type majeur est : la spécification formelle elle-même est erronée, ou la preuve contient une affirmation fausse qui est silencieusement acceptée par le système de construction.
Enfin, nous pouvons examiner les échecs de vérification formelle à la frontière entre logiciel et matériel. Un problème courant ici est la vérification de la résistance du système aux attaques par canaux auxiliaires. Même si vous protégez un message avec un chiffrement théoriquement parfaitement sûr, si quelqu'un à quelques mètres peut capturer des fluctuations électriques et extraire votre clé privée après plusieurs centaines de milliers de chiffrements, vous n'êtes toujours pas en sécurité.
L'« analyse différentielle de consommation » (differential power analysis) est un exemple aujourd'hui bien compris de ce type de technique.
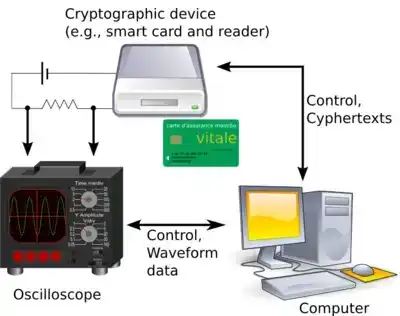
L'analyse différentielle de consommation est une attaque par canal auxiliaire courante. Source : Wikipedia
Des tentatives ont été faites dans le passé pour prouver la résistance des systèmes à ce type d'attaquant. Cependant, toute preuve de ce type nécessite un modèle mathématique de l'attaquant, dans lequel vous pouvez ensuite prouver la sécurité. Parfois, les gens utilisent le « d-probing model » : c'est-à-dire supposer qu'il existe une limite connue au nombre d'emplacements dans le circuit que l'attaquant peut sonder. Mais le problème est que certaines formes de fuite ne sont pas capturées par ce modèle.
Un problème courant observé dans cet article est la fuite transitionnelle (transitional leakage) : si le signal observé ne dépend pas de la valeur spécifique à un emplacement, mais du changement de cette valeur, alors souvent, vous pouvez récupérer l'information souhaitée à partir de deux valeurs – l'ancienne et la nouvelle – plutôt que de dépendre d'une seule valeur. L'article classe également d'autres formes de fuites.
Pendant des décennies, ces critiques de la vérification formelle ont, en retour, aidé la vérification formelle à s'améliorer. Aujourd'hui, nous sommes plus habiles qu'auparavant à nous méfier de ce type de problèmes. Mais même aujourd'hui, ce n'est toujours pas parfait.
En prenant du recul, il y a un fil conducteur ici : la vérification formelle est puissante. Mais quelle que soit la façon dont le marketing la présente comme apportant une « correction prouvée », la « correction prouvée » ne peut fondamentalement pas prouver qu'un logiciel, ou un matériel, est « correct » au vrai sens du terme.
Pour la plupart des gens, « correct » signifie à peu près : cette chose se comporte conformément à la compréhension qu'ont les utilisateurs de l'intention du développeur.
Et « sûr » signifie à peu près : cette chose ne se comporte pas d'une manière qui s'écarte des attentes de l'utilisateur en nuisant à ses intérêts.
Dans les deux cas, la correction et la sécurité se résument finalement à une comparaison : d'un côté, un objet mathématique, de l'autre, l'intention ou l'attente humaine. Strictement parlant, l'intention et l'attente humaines sont elles-mêmes des objets mathématiques – après tout, le cerveau humain fait partie de l'univers, et l'univers suit les lois de la physique ; avec suffisamment de puissance de calcul, on pourrait théoriquement les simuler. Mais ce sont des objets mathématiquement extrêmement complexes, que ni les ordinateurs ni nous-mêmes ne pouvons vraiment comprendre, ni même lire. À des fins pratiques, nous pouvons les considérer comme des boîtes noires. La raison pour laquelle nous avons une certaine compréhension de nos intentions et attentes est simplement que chaque personne a des années d'expérience à observer ses propres pensées et à inférer celles des autres.
Et précisément parce que nous ne pouvons pas fourrer l'intention humaine brute directement dans un ordinateur, la vérification formelle n'a aucun moyen de prouver une comparaison entre un système et l'intention humaine. Par conséquent, la « correction prouvée » et la « sécurité prouvée » ne prouvent pas réellement la « correction » et la « sécurité » telles que les humains les comprennent – et il n'existe aucun moyen d'y parvenir tant que nous ne pourrons pas simuler le cerveau humain.
Alors, à quoi sert réellement la vérification formelle ?
Je tends à considérer les suites de tests, les systèmes de types et la vérification formelle comme différentes implémentations d'une même méthode de sécurité sous-jacente des langages de programmation – c'est peut-être la seule manière cohérente de le voir. Leur point commun est : exprimer de manière redondante notre intention de différentes manières, puis vérifier automatiquement si ces différentes descriptions sont compatibles entre elles.
Par exemple, regardez ce code Python :

Ici, vous exprimez votre intention de trois manières différentes :
Premièrement, directement : en implémentant la formule de Fibonacci dans le code.
Deuxièmement, indirectement : en utilisant le système de types pour indiquer que les entrées, les sorties et les étapes intermédiaires de la récursion sont des entiers.
Troisièmement, en adoptant une méthode de « boîte de cas » : c'est-à-dire les cas de test.
Lors de l'exécution de ce fichier, le système utilise ces exemples pour vérifier si la formule est correcte. Le vérificateur de types peut vérifier la compatibilité des types : additionner deux entiers est une opération valide et donne un autre entier. Les systèmes de types sont souvent utiles en physique computationnelle aussi : si vous calculez une accélération mais obtenez un résultat en m/s au lieu de m/s², vous savez que quelque chose ne va pas. Et les définitions de type « boîte de cas », dont les tests sont une forme, correspondent souvent mieux à la façon dont les humains traitent les concepts que les définitions directes et explicites.
Plus vous pouvez exprimer votre intention de manières différentes, mieux c'est ; idéalement, ces manières devraient être suffisamment différentes pour vous forcer à aborder le même problème avec des modes de pensée différents. Ainsi, si toutes ces expressions s'avèrent finalement compatibles, la probabilité que vous ayez réellement exprimé ce que vous vouliez exprimer est plus élevée.
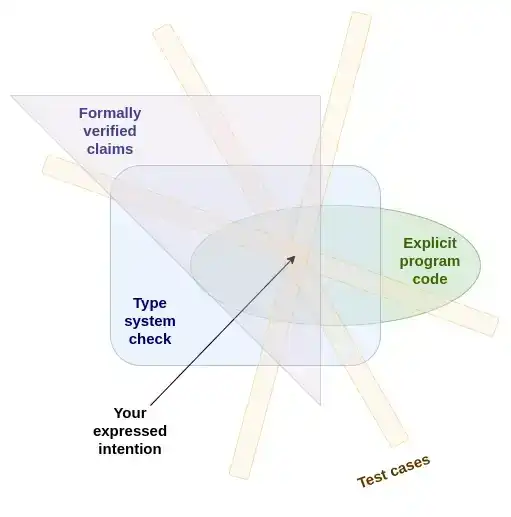
Le cœur de la programmation sécurisée est d'exprimer votre intention de multiples façons différentes, puis de vérifier automatiquement si ces expressions sont compatibles entre elles.
La vérification formelle peut pousser cette méthode plus loin. Avec la vérification formelle, vous pouvez décrire votre intention de pratiquement autant de manières redondantes que vous le souhaitez ; le programme ne passe la vérification que si ces descriptions sont compatibles entre elles.
Vous pouvez écrire simultanément une implémentation optimisée et une implémentation très inefficace mais facile à lire pour un humain, puis vérifier qu'elles sont équivalentes. Vous pouvez demander à dix amis de lister chacun les propriétés mathématiques qu'ils pensent que le programme devrait satisfaire, puis vérifier si le programme les satisfait toutes ; en cas d'échec, déterminer si c'est le programme qui est erroné ou si la propriété mathématique elle-même est problématique. Et l'IA peut rendre tout ce travail extrêmement efficace.
Comment puis-je commencer alors ?
En réalité, vous n'écrirez probablement pas vous-même les preuves. La raison fondamentale pour laquelle les méthodes formelles ne se sont jamais vraiment généralisées est que la plupart des gens ont du mal à comprendre comment écrire ces maudites preuves.
Pouvez-vous me dire ce que signifie ce code ?
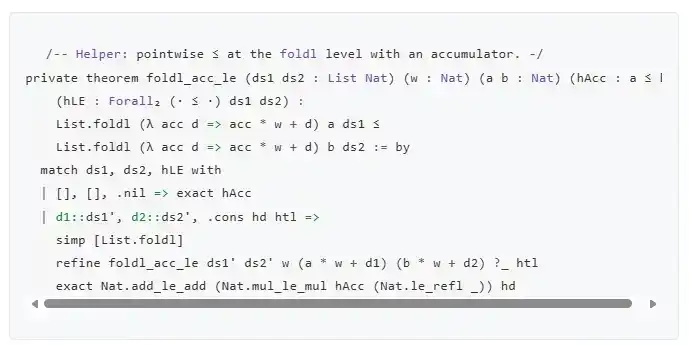
(Si vous voulez savoir, c'est l'un des nombreux sous-lemmes d'une preuve. Cette preuve concerne une affirmation de sécurité spécifique pour une variante de la signature SPHINCS : à moins d'une collision de hachage, générer une signature pour un message donné nécessite d'utiliser une valeur plus haute sur au moins une chaîne de hachage par rapport à toute autre signature de message. Par conséquent, l'information requise ne peut pas être calculée à partir d'une autre signature.)
Au lieu d'écrire vous-même le code et les preuves, vous laissez l'IA écrire le programme pour vous – directement en Lean si vous voulez ; ou en assembleur si vous voulez de la vitesse – et en cours de route, prouver les propriétés que vous souhaitez.
Un avantage de cette tâche est qu'elle est intrinsèquement auto-vérifiée, donc vous n'avez pas besoin de la surveiller constamment. Vous pouvez tout à fait laisser l'IA tourner pendant des heures. Le pire qui puisse arriver est qu'elle tourne en rond sans faire de progrès ; ou comme l'a fait une fois mon Leanstral, pour faciliter son travail, elle a simplement remplacé l'énoncé qu'elle était censée prouver.
Ce que vous devez finalement vérifier est : la proposition qu'elle a prouvée est-elle bien celle que vous vouliez prouver ?
Dans cette variante de signature SPHINCS, l'énoncé final est le suivant :

Cela frôle même à peine la limite du « lisible » :
Si le nombre généré par un condensé de hachage (dig1) n'est pas égal au nombre généré par un autre condensé de hachage (dig2), alors l'affirmation suivante est fausse :
Pour tous les nombres, chaque chiffre de dig1 est inférieur ou égal au chiffre correspondant de dig2 ;
Pour tous les nombres, chaque chiffre de dig2 est inférieur ou égal au chiffre correspondant de dig1.
La comparaison se fait entre les « nombres étendus » (wotsFullDigits) générés après l'ajout d'une somme de contrôle (checksum). C'est-à-dire que, inévitablement, à certaines positions, le nombre étendu de dig1 sera plus élevé ; et à d'autres positions, le nombre étendu de dig2 sera plus élevé.
En ce qui concerne l'écriture de preuves avec de grands modèles de langage, je trouve que Claude est déjà assez bon, et DeepSeek 4 Pro est également très compétent. Leanstral est une alternative prometteuse : c'est un modèle open-source de poids, spécialement affiné pour l'écriture en Lean. Il a 119 milliards de paramètres, mais n'active que 6 milliards de paramètres par token, il peut donc fonctionner localement, bien que lentement – sur mon ordinateur portable, environ 15 tokens par seconde.
D'après les benchmarks, Leanstral surpasse de nombreux modèles généraux beaucoup plus grands :
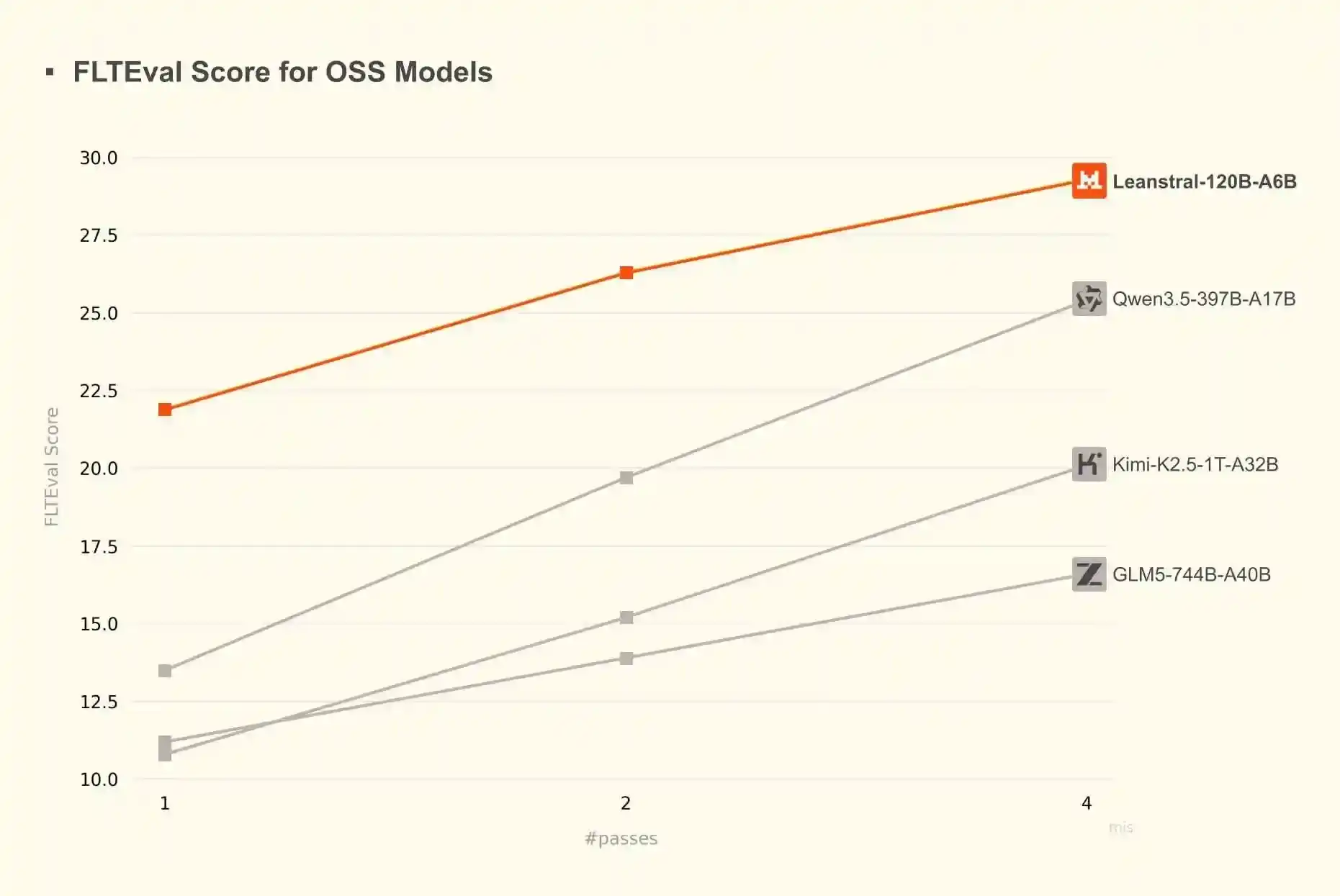
D'après mon expérience personnelle actuelle, il est légèrement moins performant que DeepSeek 4 Pro, mais reste efficace.
La vérification formelle ne résoudra pas tous nos problèmes. Mais si nous voulons établir un modèle de sécurité pour Internet qui ne consiste pas à faire confiance à quelques organisations puissantes, alors nous devons pouvoir nous fier au code à la place – y compris face à des adversaires IA puissants. La vérification formelle assistée par l'IA peut nous faire faire un pas important dans cette direction.
Comme la blockchain et les ZK-SNARKs, l'IA et la vérification formelle sont des technologies hautement complémentaires.
La blockchain apporte une vérifiabilité ouverte et une résistance à la censure au prix de la confidentialité et de l'évolutivité ; et les ZK-SNARKs ramènent la confidentialité et l'évolutivité – en fait, même plus fortes qu'avant.
L'IA vous permet d'écrire du code à grande échelle, mais au prix d'une baisse de précision ; et la vérification formelle ramène la précision – en fait, aussi plus forte qu'auparavant.
Par défaut, l'IA engendrera de grandes quantités de code très grossier, et le nombre de bugs augmentera. En effet, dans certains scénarios, laisser les bugs augmenter est même le bon compromis : si l'impact de ces bugs est léger, alors même un logiciel défectueux est préférable à l'absence d'un tel logiciel. Mais ici, il existe toujours un avenir optimiste pour la sécurité des réseaux : le logiciel continuera à se diviser en « composants périphériques non sécurisés » entourant un « noyau de sécurité ».
Ces composants périphériques non sécurisés s'exécuteront dans des sandboxs et n'auront que les autorisations minimales nécessaires pour accomplir leur tâche. Le noyau de sécurité gérera tout. Si le noyau de sécurité s'effondre, tout s'effondre – vos données personnelles, votre argent, et plus encore seront affectés. Mais si un composant périphérique non sécurisé a un problème, le noyau de sécurité peut toujours vous protéger.
Lorsqu'il s'agit du noyau de sécurité, nous ne laisserons pas le code bogué proliférer sans contrôle. Nous contrôlerons activement la taille du noyau de sécurité, en le gardant suffisamment petit, voire en le réduisant encore. Au contraire, nous dédierons toute la capacité supplémentaire apportée par l'IA à l'amélioration de la sécurité du noyau de sécurité lui-même, afin qu'il puisse supporter le fardeau de confiance extrêmement élevé d'une société hautement numérisée.
Le noyau de votre système d'exploitation, ou du moins une partie de celui-ci, sera l'un de ces noyaux de sécurité. Ethereum en sera un autre. Idéalement, au moins pour tous les calculs non intensifs en performance, le matériel que vous utiliserez constituera un troisième noyau de sécurité. Certains systèmes liés à l'IdO en constitueront un quatrième.
Au moins dans ces noyaux de sécurité, le vieil adage – les bugs sont inévitables, vous ne pouvez qu'essayer de les trouver avant les attaquants – ne sera plus vrai. Il sera remplacé par un monde plus prometteur : un monde où nous pouvons obtenir une véritable sécurité.
Bien sûr, si vous êtes prêt à confier vos actifs et données à des logiciels mal écrits, voire susceptibles de les envoyer accidentellement dans un trou noir, vous aurez toujours cette liberté.
Lien vers l'article original







