Anthropic vient d'officialiser le lancement de son nouveau modèle Claude Sonnet 5, présenté comme « le modèle Sonnet le plus agentique à ce jour », capable d'élaborer des plans, d'utiliser des outils comme un navigateur, un terminal, et de fonctionner de manière autonome à un niveau qui, il y a quelques mois, nécessitait des modèles plus gros et plus coûteux.
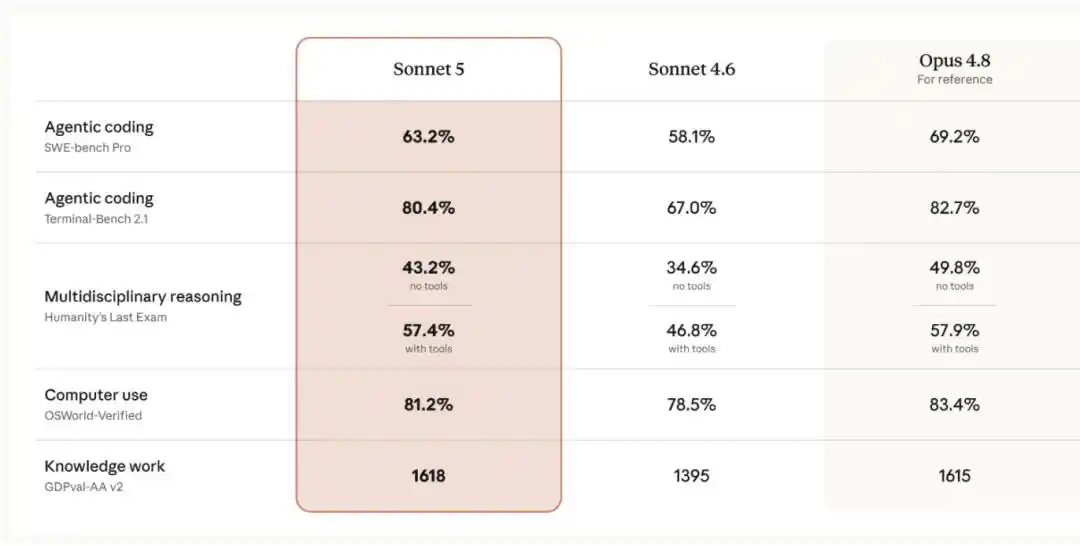
Par rapport à Sonnet 4.6, Sonnet 5 présente des améliorations significatives en matière de raisonnement, d'utilisation d'outils, de programmation et de travail intellectuel, se rapprochant des performances d'Opus 4.8, mais à un prix inférieur.
Selon l'entreprise, pour les développeurs, l'ère des agents IA a vraiment commencé avec les modèles de niveau Sonnet : Claude Sonnet 3.5, 3.6 et 3.7 ont été parmi les premiers à démontrer des capacités impressionnantes en programmation et en utilisation d'outils. Cependant, les progrès les plus marquants en matière de capacités agentiques ont récemment été observés principalement sur les modèles de niveau Opus.
Claude Sonnet 5 réduit sensiblement cet écart : ses performances se rapprochent désormais d'Opus 4.8, mais à un coût moindre. Comparé à sa version précédente, Sonnet 4.6, il affiche des améliorations notables sur des dimensions clés des performances des agents intelligents, comme le raisonnement, l'utilisation d'outils, la programmation et le travail intellectuel. Un comparatif détaillé est présenté ci-dessous :
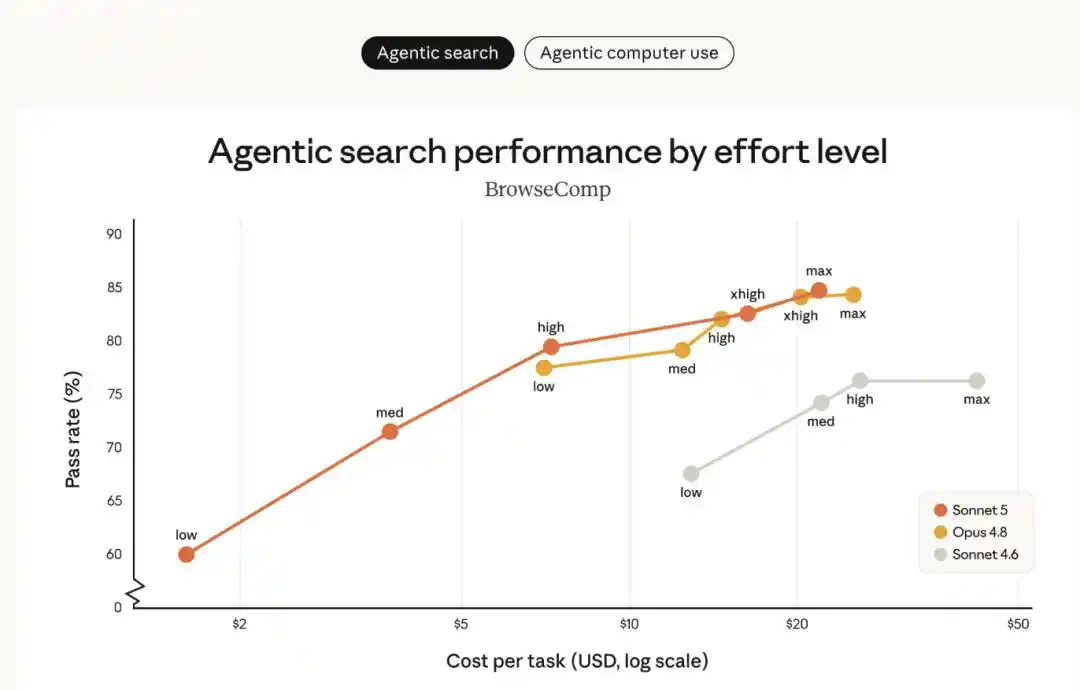
Le graphique suivant compare les performances de Sonnet 5, Sonnet 4.6 et Opus 4.8 sur les benchmarks de recherche agentique BrowseComp et d'utilisation informatique OSWorld‐Verified, à différents niveaux d'« effort » :
- Sonnet 5 (ligne orange) montre une nette amélioration par rapport à Sonnet 4.6 (ligne grise), et offre une gamme d'options coût-performance plus large qu'Opus 4.8 (ligne jaune).
- À un niveau d'effort moyen, Sonnet 5 améliore considérablement le rapport coût-efficacité ; à des niveaux d'effort plus élevés, ses performances peuvent rivaliser avec celles d'Opus 4.8 sur certaines tâches.
- Entre Sonnet 5 et Opus 4.8, les utilisateurs peuvent ajuster le niveau d'effort en fonction de la tâche spécifique, pour trouver le meilleur équilibre entre coût et performance selon leurs besoins.
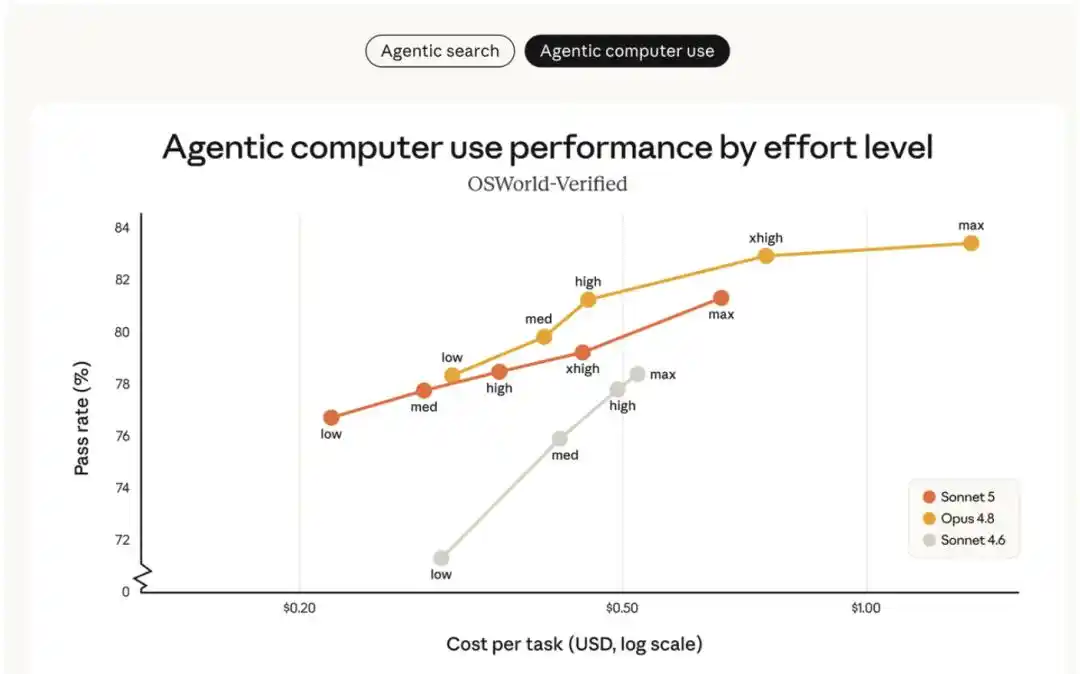
La courbe coût-performance à différents niveaux d'effort est illustrée ci-dessus. Le meilleur modèle Sonnet précédent (Sonnet 4.6) était loin d'atteindre Opus 4.8. Sonnet 5 offre une gamme d'options coût-performance plus étendue que Sonnet 4.6 et peut, dans certains cas, atteindre le niveau de capacité d'Opus 4.8. Le prix affiché pour Sonnet 5 sur ce graphique est de 3 $ / million de tokens en entrée et 15 $ / million de tokens en sortie. Avec le tarif de lancement valable jusqu'au 31 août (2 $ / million de tokens en entrée, 10 $ / million en sortie), le coût réel de Sonnet 5 est même inférieur à celui indiqué sur le graphique. Le tarif d'Opus 4.8 est de 5 $ / million de tokens en entrée et 25 $ / million de tokens en sortie.
Les retours des premiers partenaires ayant eu un accès anticipé à Anthropic sont unanimes : Sonnet 5 est nettement plus agentique (plus capable en tant qu'agent autonome) que son prédécesseur. Les testeurs rapportent qu'il peut accomplir des tâches complexes là où les modèles Sonnet précédents s'arrêtaient en cours de route ; il vérifie activement ses propres sorties sans en avoir reçu l'instruction explicite ; et il réalise tout ce travail agentique à un prix très attractif :
Évaluation de sécurité
L'évaluation de sécurité pré-déploiement d'Anthropic a révélé que Sonnet 5 est globalement plus sûr que Sonnet 4.6. En matière de sécurité des agents autonomes, le modèle est meilleur pour refuser les requêtes malveillantes et résister aux tentatives de détournement par des attaques d'injection de prompt. Ses taux d'hallucination et de comportement de flatterie sont inférieurs à ceux de Sonnet 4.6. Dans l'audit comportemental automatisé (qui teste un large éventail de comportements inappropriés, comme l'assistance à des abus ou la tromperie), Sonnet 5 obtient un score plus bas (c'est-à-dire qu'il est plus sûr).
Cependant, comparé aux modèles plus performants Opus 4.8 et Claude Mythos Preview, il présente effectivement un taux légèrement plus élevé de comportements inappropriés dans cette évaluation.
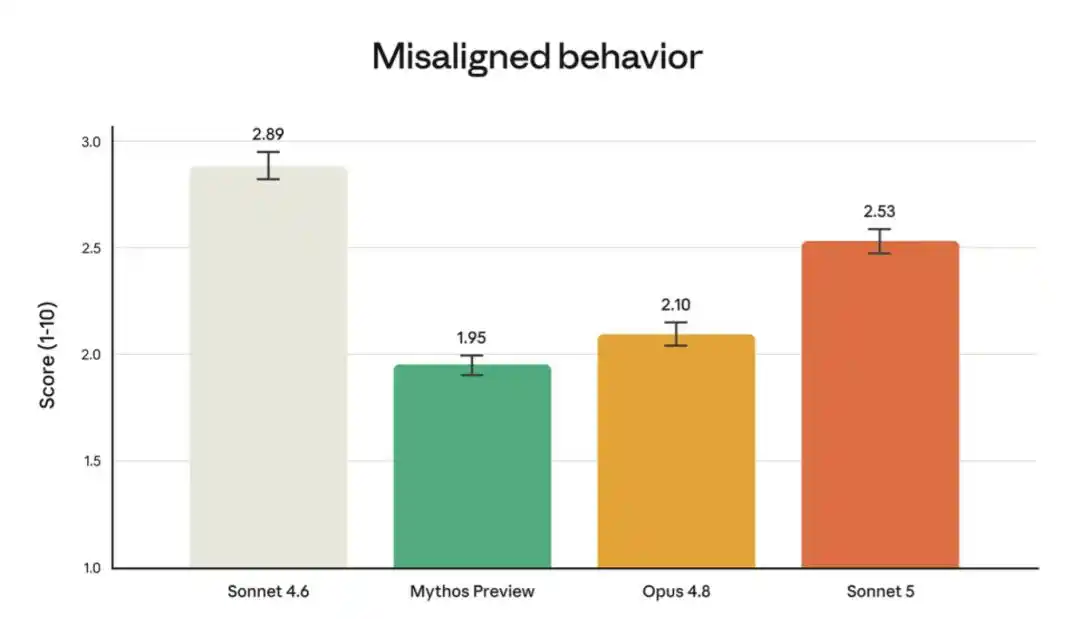
Le graphique ci-dessus montre le taux de comportements inappropriés lors de l'audit comportemental automatisé, qui teste un large éventail de comportements indésirables dans divers contextes (la liste complète et les résultats par comportement sont disponibles dans la section 6.4 de la fiche système de Sonnet 5). Le taux de comportements inappropriés de Sonnet 5 est globalement inférieur à celui de Sonnet 4.6, mais supérieur à ceux de Mythos Preview et d'Opus 4.8.
Anthropic précise qu'ils n'ont pas spécifiquement entraîné Sonnet 5 pour des tâches de cybersécurité. Il peut exécuter certaines tâches réseau courantes et inoffensives, mais ses performances sont significativement inférieures à celles de modèles comme Opus 4.8 et Mythos 5 lorsqu'il est évalué sur des compétences réseau potentiellement dangereuses, comme le développement d'exploits pour des vulnérabilités logicielles.
Le graphique suivant présente les scores de l'une de ces évaluations, qui teste la capacité des modèles à développer des exploits pour une vulnérabilité du navigateur Firefox. Sonnet 5 n'a jamais réussi à développer un exploit complet et fonctionnel, mais son taux de succès partiel est légèrement supérieur à celui de Sonnet 4.6. Cette amélioration pour le modèle précédent pourrait provenir d'une intelligence générale renforcée, plutôt que d'un entraînement spécifique.
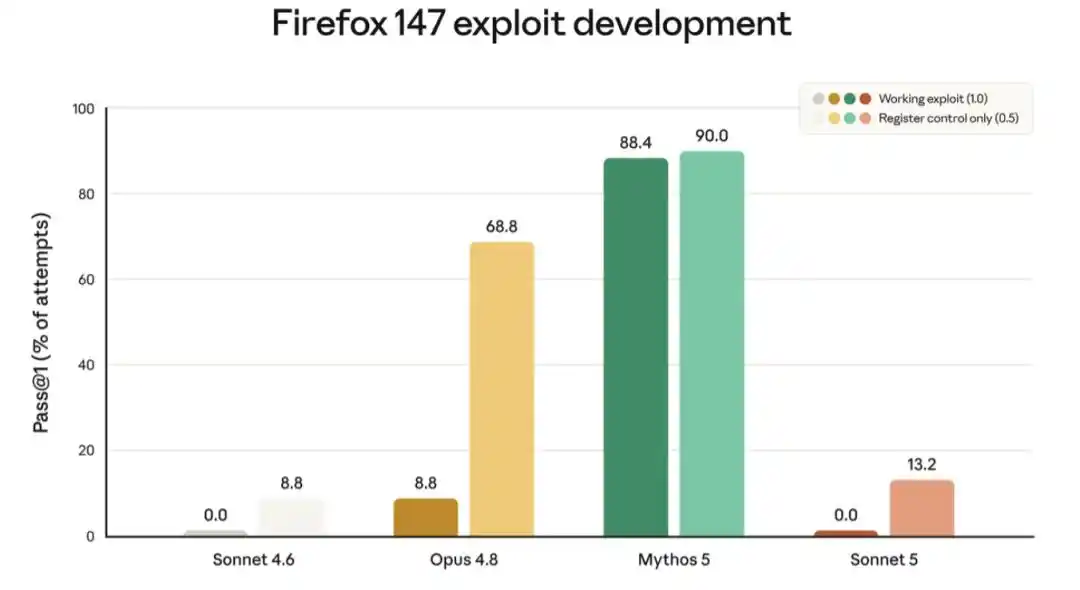
Le graphique ci-dessus montre les scores des modèles pour le développement réussi d'un exploit pour une vulnérabilité logicielle dans Firefox 147 (cette évaluation a été développée en collaboration avec Mozilla ; toutes les vulnérabilités ont été corrigées dans Firefox 148). Pour chaque modèle, la barre de gauche indique la fréquence à laquelle le modèle (sans garde-fous de sécurité) a développé un exploit fonctionnel, la barre de droite indiquant la fréquence des succès partiels. Les deux modèles Sonnet n'ont pas réussi à développer d'exploit fonctionnel (score de 0,0 %) ; le taux de succès partiel de Sonnet 5 est légèrement supérieur à celui de Sonnet 4.6. Les capacités réseau des deux modèles Sonnet sont nettement inférieures à celles d'Opus 4.8 et de Mythos 5.
Étant donné que Sonnet 5 est légèrement plus performant que son prédécesseur sur ces tâches, Anthropic a activé par défaut des garde-fous de cybersécurité. Ces garde-fous – capables de détecter et de bloquer en temps réel les usages réseau dangereux – sont les mêmes que ceux déployés sur Claude Opus 4.7 et 4.8 (car Anthropic estime que le risque global de cybersécurité de Sonnet 5 est faible, ses garde-fous sont donc moins stricts que ceux activés pour Fable 5 – qui bloque un éventail plus large de tâches de cybersécurité).
Le rapport d'évaluation complet d'Anthropic sur Sonnet 5 concernant de multiples aspects de sécurité et de capacités est disponible dans la Fiche système de Claude Sonnet 5.
Tarification
À partir d'aujourd'hui, Claude Sonnet 5 est officiellement disponible sur tous les canaux. Pour célébrer son lancement, Anthropic propose un tarif de lancement promotionnel limité dans le temps :
- Du maintenant au 31 août 2026 : Entrée à 2 $ / million de tokens, Sortie à 10 $ / million de tokens.
- Après cette date, retour au tarif standard : Entrée à 3 $ / million de tokens, Sortie à 15 $ / million de tokens.
Parallèlement, l'entreprise annonce une augmentation générale des limites de débit (rate limits) pour Chat, Cowork, Claude Code et la plateforme Claude, afin de s'adapter à la consommation accrue de tokens induite par les modes d'« effort » plus élevés.
Points à noter
Programme de vérification de cybersécurité
Sonnet 5 est intégré au « Programme de vérification de cybersécurité » d'Anthropic. Ce programme est désormais accessible sur les plateformes suivantes :
- La plateforme native Claude
- La plateforme Claude sur AWS
- Claude dans Microsoft Foundry (hébergé sur Azure et Anthropic)
Claude sur Google Vertex le prendra également en charge prochainement.
Les organisations déjà inscrites à ce programme obtiennent automatiquement un accès équivalent sur Sonnet 5, sans avoir à repostuler. Si vos travaux de cybersécurité nécessitent des restrictions de garde-fous moins strictes, Anthropic recommande d'utiliser Claude Opus 4.8.
Mise à jour du tokenizer et précisions tarifaires
Sonnet 5 est une mise à niveau de Sonnet 4.6, mais il utilise un nouveau tokenizer pour optimiser les performances de traitement de texte (similaire au changement introduit avec Claude Opus 4.7).
La conséquence est la suivante : un contenu d'entrée identique sera maintenant mappé sur un plus grand nombre de tokens, avec une augmentation d'environ 1,0 à 1,35 fois, selon le type de contenu.
C'est pourquoi le tarif de lancement a été fixé par Anthropic pour que le coût global d'utilisation reste globalement stable lors de la transition vers Sonnet 5.
Explications sur l'ajustement des limites de débit
Dès le 26 avril 2026, Anthropic avait déjà augmenté les limites de débit pour les modèles Sonnet et Haiku sur tous les niveaux d'utilisation, et simplifié les forfaits de la plateforme native Claude en trois niveaux : Start, Build, Scale.
Cette mise à jour voit Anthropic augmenter encore les limites de débit pour Chat, Cowork, Claude Code et la plateforme Claude, afin de correspondre à la consommation de tokens plus importante générée par les modes d'« effort » plus élevés.
Vous pouvez consulter votre niveau actuel et les limites spécifiques dans la Console Claude, ou vous référer à la documentation pour plus de détails.
Précisions sur les corrections de scores de benchmarks (supplément)
- Humanity’s Last Exam : Anthropic a mis à jour le modèle de notation de ce benchmark et a ainsi corrigé le score de Sonnet 4.6 à 34,6 % (sans outil) et 46,8 % (avec outil). Ce score diffère donc de celui rapporté dans le blog de lancement de Sonnet 4.6, d'où cette clarification.
- OSWorld‐Verified : Anthropic a optimisé la manière dont ce benchmark est exécuté pour mieux refléter les performances des modèles dans des scénarios réels, et a corrigé le score de Sonnet 4.6 à 78,5 %. C'est également la raison pour laquelle ce score diffère de celui du blog de lancement de Sonnet 4.6.
Retours des développeurs
Dès le lancement de Claude Sonnet 5, les développeurs ont commencé à le tester.
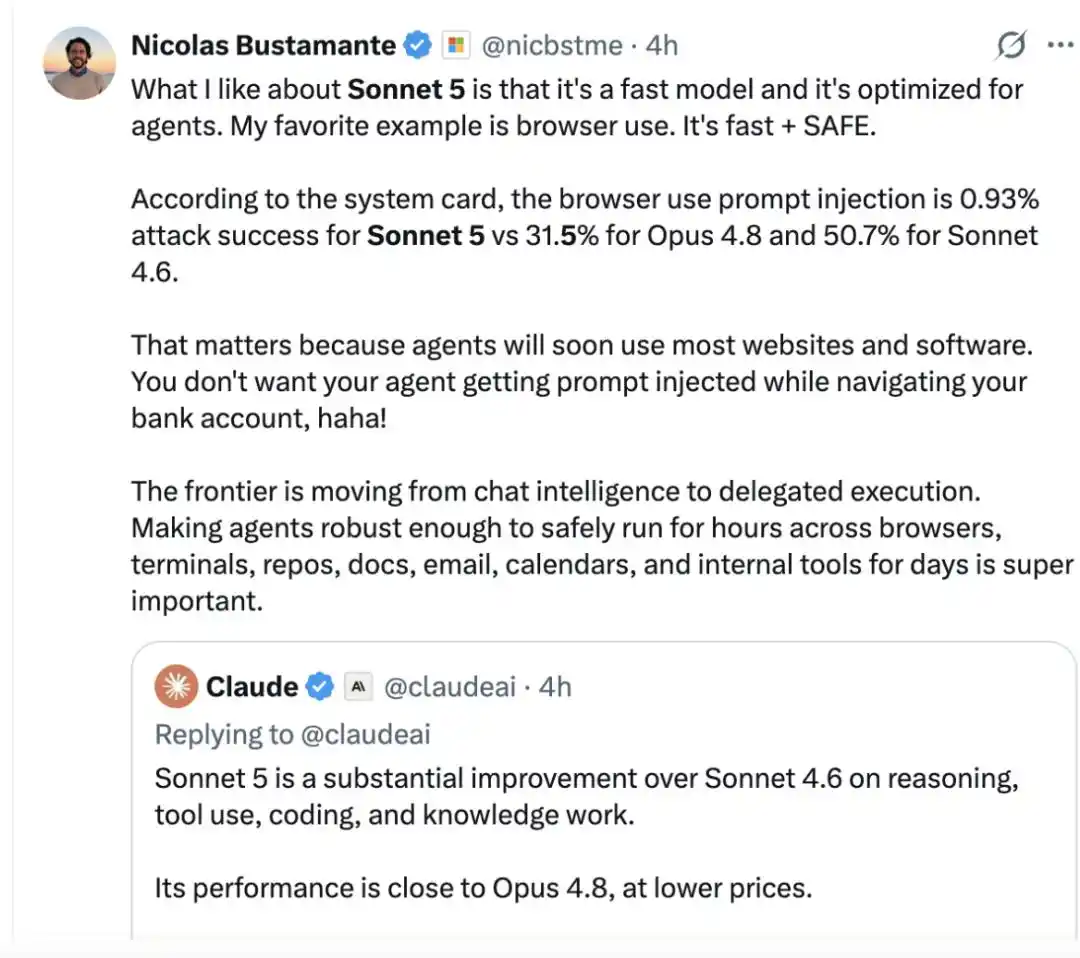
L'utilisateur Nicolas Bustamante a déclaré apprécier Sonnet 5 pour sa rapidité et son optimisation pour les agents. « Ce que je préfère, c'est l'utilisation du navigateur : rapide et sécurisé. »
Selon les résultats de la fiche système, le taux de réussite des attaques par injection de prompt dans les scénarios d'utilisation du navigateur n'est que de 0,93 % pour Sonnet 5, contre 31,5 % pour Opus 4.8 et 50,7 % pour Sonnet 4.6.
Cependant, certains utilisateurs estiment que « c'est trop cher ».
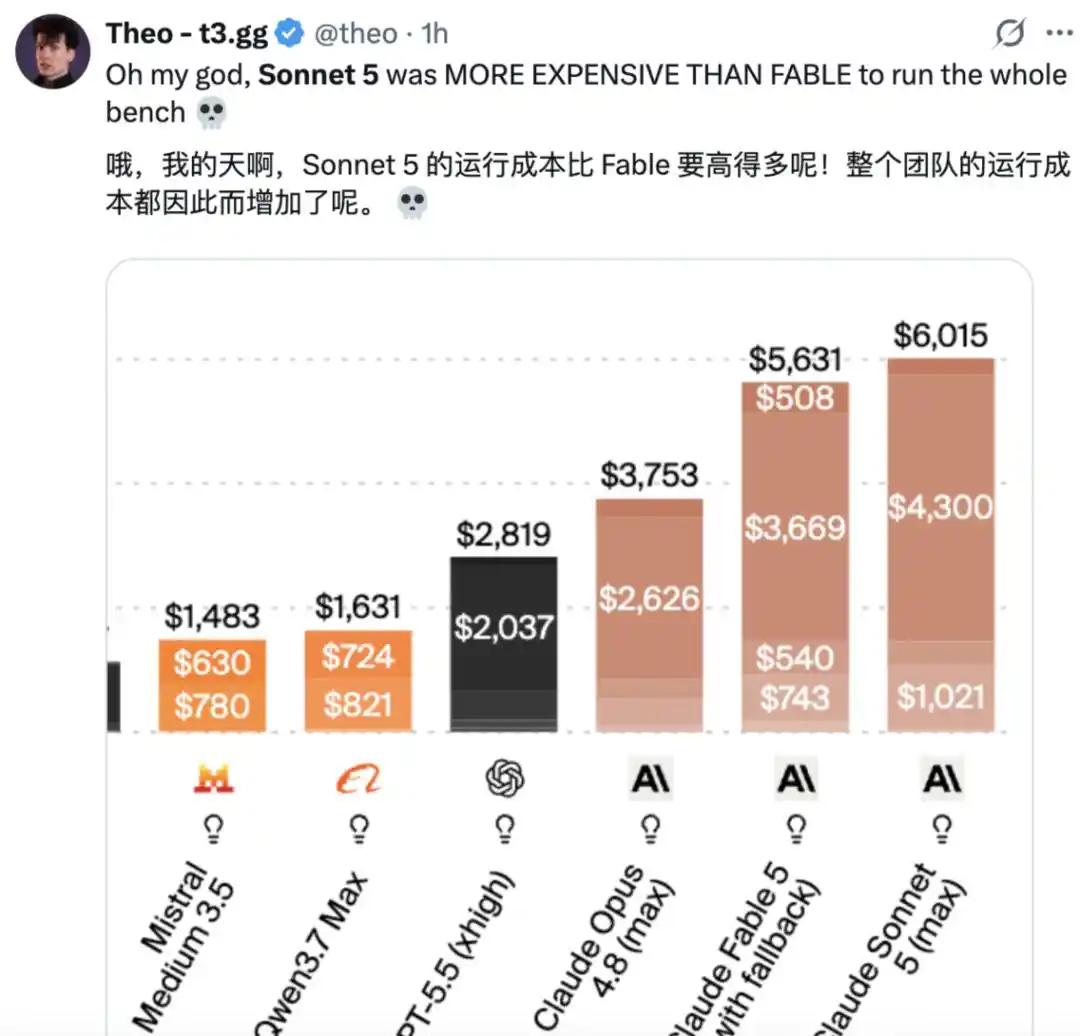
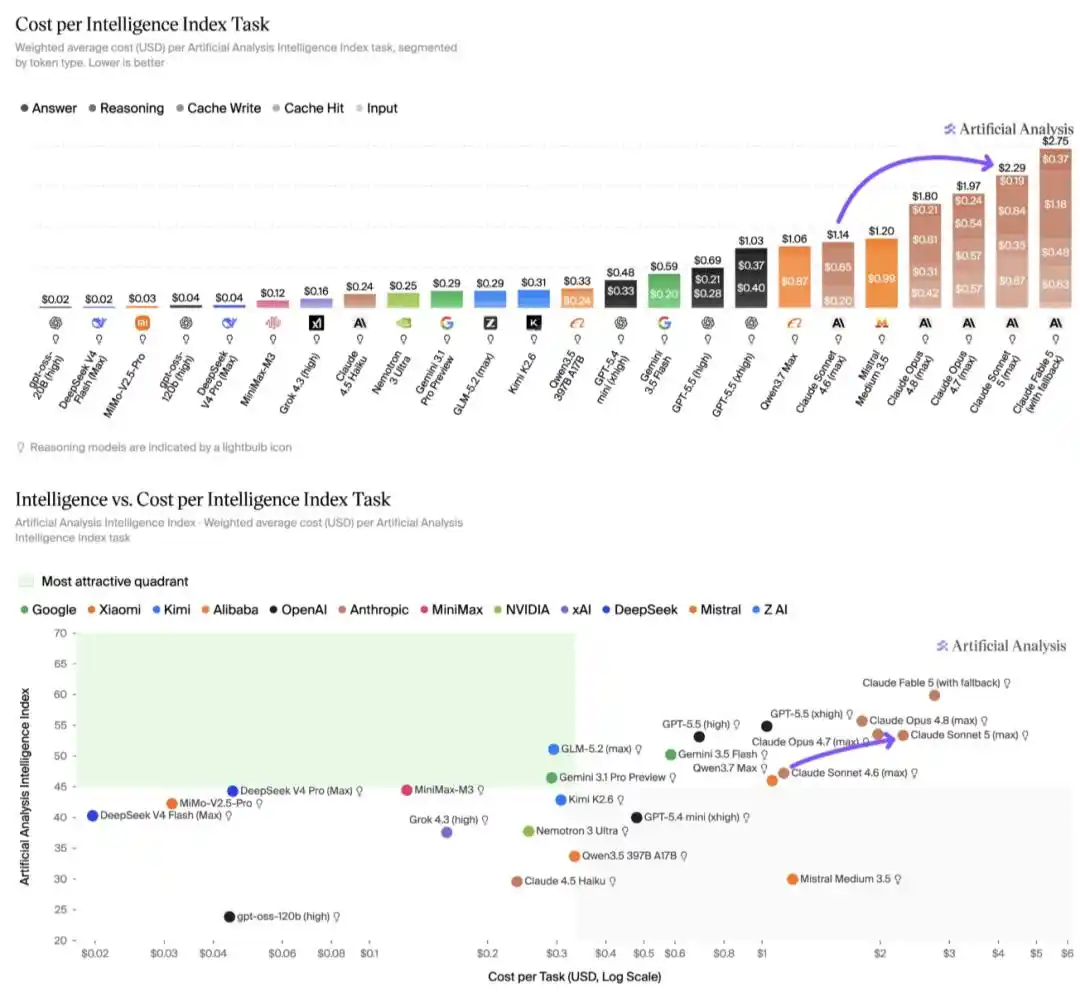
Selon une analyse d'Artificial Analysis, sur l'Indice d'Intelligence, le coût d'exécution de Claude Sonnet 5 est de 2,29 $ par tâche, soit environ 2 fois plus que Sonnet 4.6, et environ 15 % de plus que Claude Opus 4.8. Cette hausse de coût est entièrement due à l'augmentation de l'utilisation de tokens, faisant de Claude Sonnet 5 l'un des modèles les plus coûteux à exécuter, juste derrière Claude Fable 5.
Et vous, que pensez-vous du nouveau modèle ? N'hésitez pas à partager vos avis dans les commentaires !
Liens de référence :
https://x.com/claudeai/status/2072017450611142835
https://www.anthropic.com/news/claude-sonnet-5
https://x.com/ArtificialAnlys/status/2072062595482456431
Cet article provient du compte WeChat public « Machine Heart » (ID : almosthuman2014), auteur : Concerné par l'IA





