La recherche automatisée sort cette fois-ci véritablement de son bac à sable logiciel pour entrer dans le monde physique réel.
Récemment, Jim Fan, responsable du laboratoire GEAR de NVIDIA, a présenté un nouveau projet nommé ENPIRE. C'est la première fois qu'ils ont réalisé une recherche automatisée sur du matériel robotique.
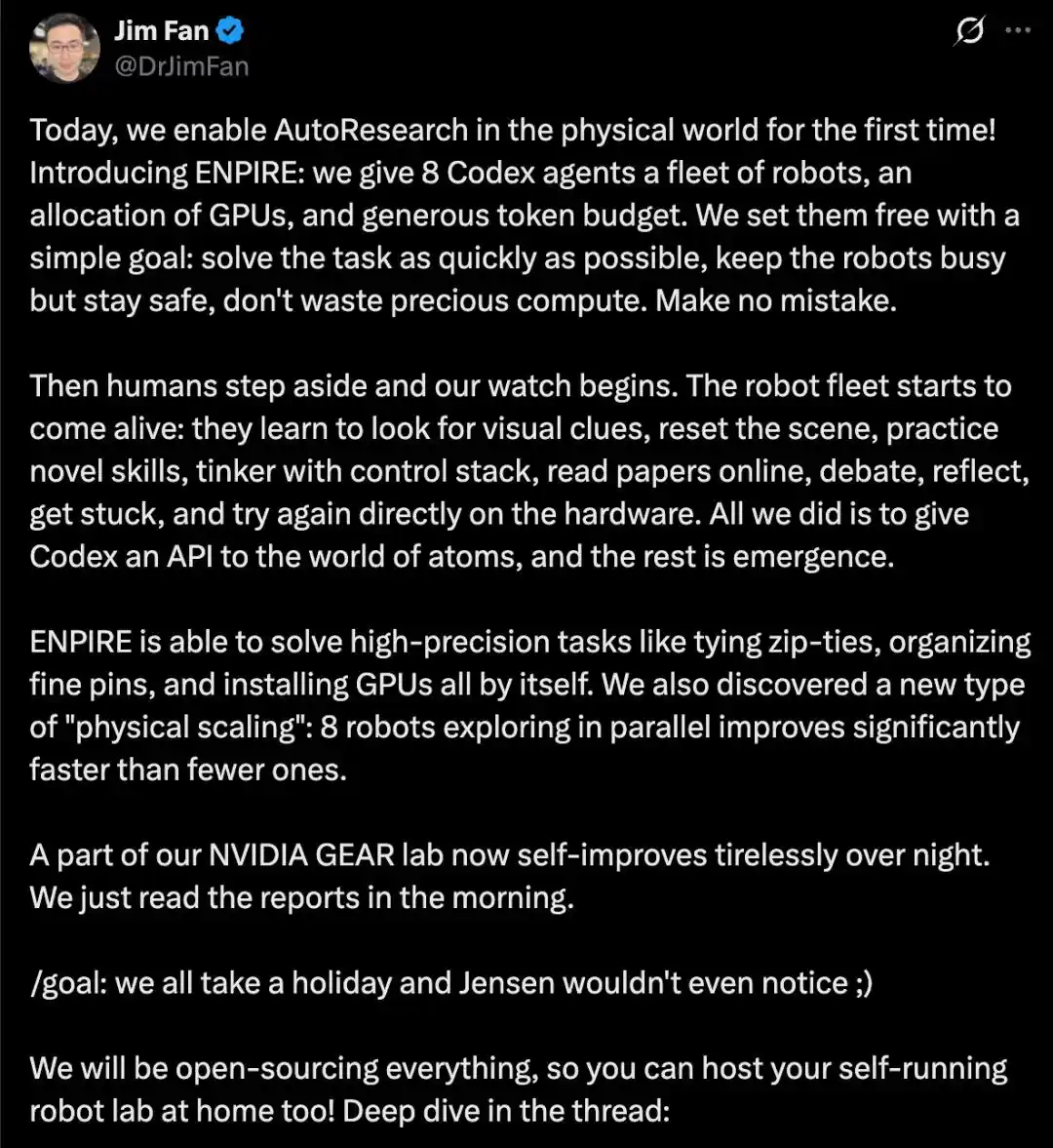
Ils ont placé 8 Agents Codex dans une flotte de robots, leur attribuant une puissance de calcul GPU et un budget de token suffisants, avec pour seul objectif simple : résoudre la tâche le plus rapidement possible, maintenir les robots occupés tout en assurant leur sécurité, et ne pas gaspiller la puissance de calcul.
Ensuite, l'intervention humaine a été pratiquement supprimée. Les Agents ont piloté de manière autonome la boucle complète, comprenant la réinitialisation automatique des scènes, la recherche documentaire, la mise en œuvre d'idées et la construction d'infrastructures, l'entraînement et le déploiement de stratégies, l'auto-vérification, l'analyse des journaux et la modification du code, itérant ainsi jusqu'à l'accomplissement fiable de tâches de manipulation délicates et de haute précision sur du matériel réel, comme attacher des serre-câbles, ranger des épingles dans une boîte, ou installer des GPU.
Ils ont également observé une « loi d'échelle physique » : augmenter le nombre de robots en parallèle (par exemple, passer de quelques-uns à 8) accélère significativement la vitesse de résolution des tâches.
Actuellement, certains systèmes du laboratoire fonctionnent en itération autonome toute la nuit sans intervention humaine, les chercheurs n'ayant qu'à consulter les rapports le matin.
Jim Fan affirme que l'objectif futur est de permettre à l'équipe de partir en vacances l'esprit tranquille, et même que le PDG de NVIDIA, Jensen Huang, ne remarquerait pas que le laboratoire continue de fonctionner de manière autonome.
Le projet ENPIRE est prévu pour être entièrement open source, permettant ainsi à tout développeur de construire chez lui un système similaire de recherche robotique autonome.

Adresse du projet : https://research.nvidia.com/labs/gear/enpire/
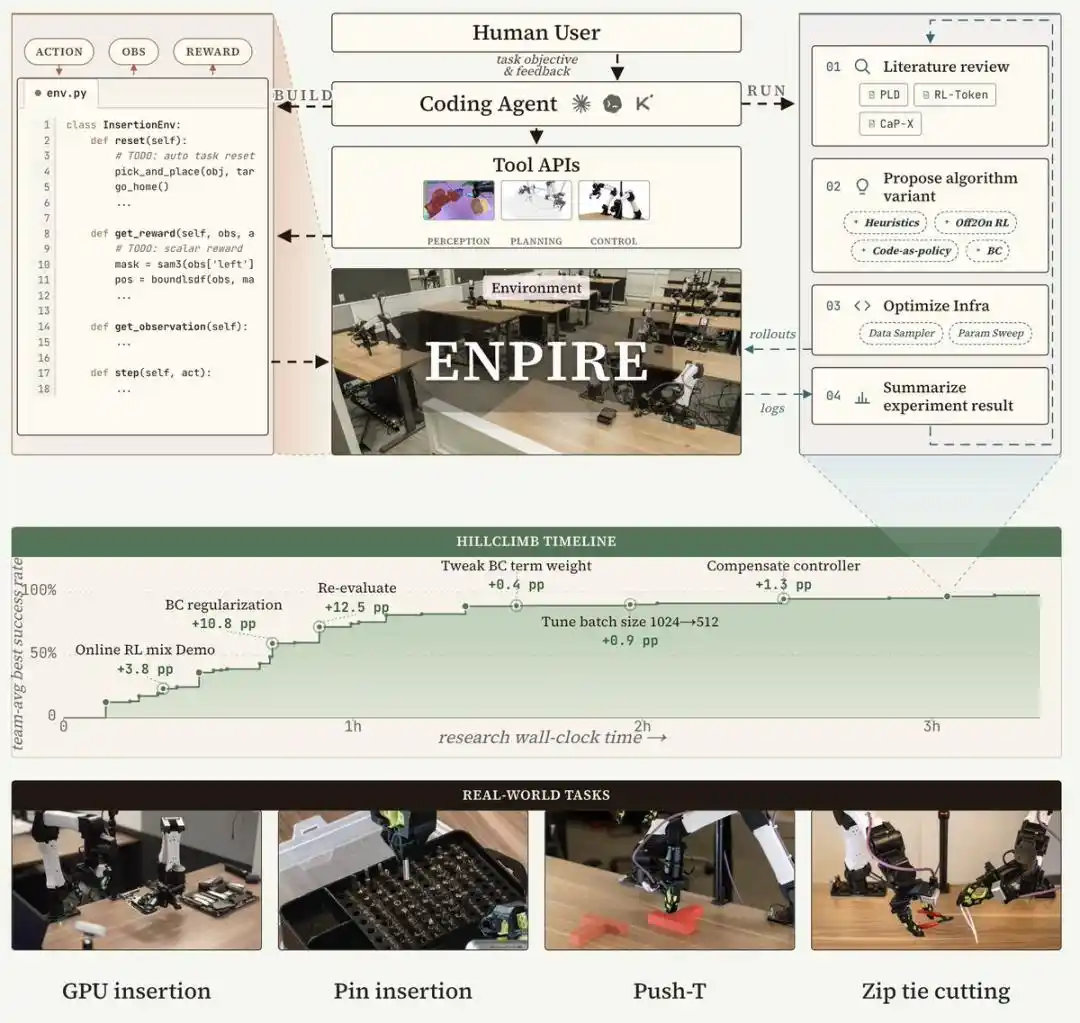
Architecture du système ENPIRE : quatre modules formant une boucle
ENPIRE est un système-cadre conçu pour les Agents de codage, construisant une boucle de rétroaction physique reproductible grâce à quatre modules centraux : le module Environnement (EN) est responsable de la réinitialisation et de la validation automatiques, le module d'Amélioration de la Stratégie (PI) lance l'optimisation de la stratégie, le module de Déploiement (R) permet d'évaluer la stratégie sur un ou plusieurs robots en parallèle, et le module d'Évolution (E) permet à l'Agent de codage d'analyser les journaux, de consulter la littérature, d'améliorer l'infrastructure d'entraînement et le code algorithmique pour résoudre les modes d'échec.
Ce système en boucle fermée transforme l'apprentissage robotique dans le monde réel en un processus d'optimisation contrôlé et géré par des Agents, minimisant ainsi au maximum l'intervention humaine, tout en permettant de réaliser des expériences d'ablation équitables entre différentes recettes d'entraînement et variantes d'Agents.
Grâce à ENPIRE, des Agents de programmation de pointe peuvent développer de manière autonome des stratégies et atteindre un taux de réussite de 99% sur des tâches complexes de manipulation dans le monde réel, telles que PushT, ranger des épingles dans une boîte, ou utiliser un couteau pour couper des serre-câbles.
Observation clé : réinitialiser l'environnement est plus facile que d'accomplir la tâche elle-même
Une observation clé est la suivante : pour de nombreuses tâches robotiques, réinitialiser l'environnement est souvent plus facile que d'accomplir la tâche elle-même.
Par conséquent, l'approche d'ENPIRE consiste à laisser d'abord l'Agent construire un environnement de réinitialisation automatique via Code-as-Policy. Dans de nombreux cas, la réinitialisation est en fait une simple tâche de pick-and-place, résolvable par Cap-X.
Ensuite, l'agent intelligent écrit une fonction de récompense basée sur des règles heuristiques. L'équipe de recherche place ensuite cet environnement dans un sandbox et lance l'Agent pour mener une recherche automatisée autour du score.
Cela fait écho à la définition de Karpathy sur la recherche automatisée : ici, la recherche automatisée ne se limite pas à ajuster un hyperparamètre ou à modifier un petit bout de code. L'Agent explorera différents paradigmes sur Internet et réécrira tout ce qui peut améliorer les performances, y compris les algorithmes, les objectifs d'entraînement, et même le chargeur de données.
Pour la tâche de rangement des épingles, un Agent a même écrit seul un contrôleur de sécurité basé sur la force de contact, surpassant l'effet d'un simple ajustement de quelques paramètres d'apprentissage par renforcement.
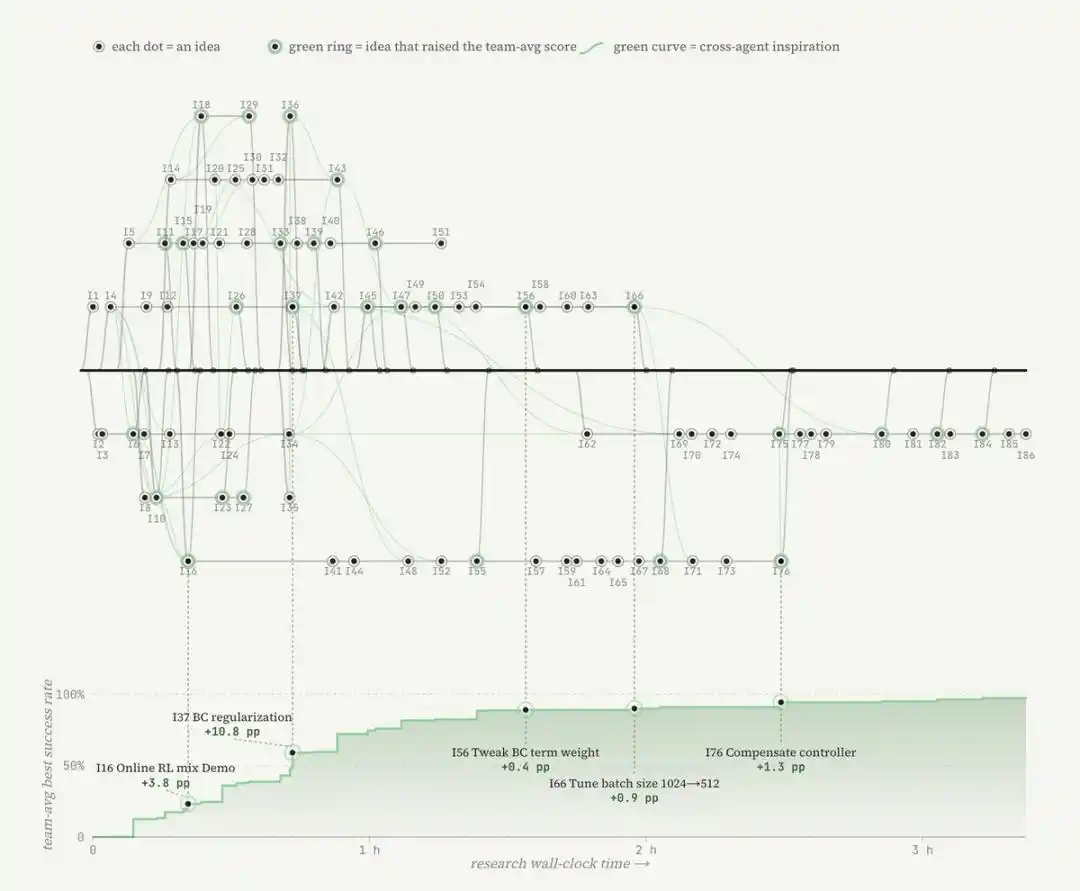
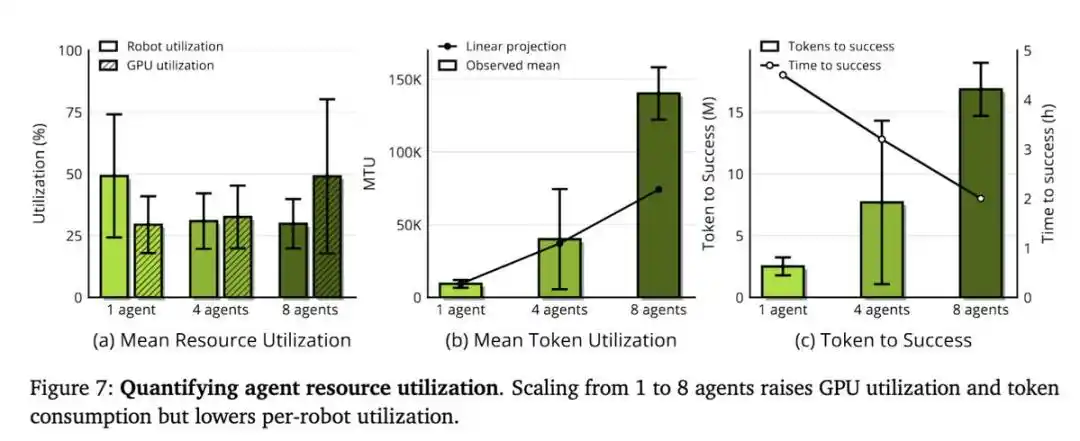
Nouveaux indicateurs : MRU et MTU
La capacité d'extension d'ENPIRE dépend de la taille de l'équipe d'Agents et des ressources de calcul, mais ici, la ressource véritablement rare n'est pas le GPU, mais le temps robotique.
Lorsque l'équipe de recherche a fourni 8 robots aux Agents, au lieu d'un seul, le temps nécessaire pour atteindre une performance quasi parfaite sur la tâche de rangement des épingles est passé de plus de 1,5 heure à environ 40 minutes. Ces Agents se coordonnent via Git : partageant le code, abandonnant les idées non optimales, et sélectionnant de manière autonome les meilleurs résultats d'exécution les uns des autres.
Cela indique un changement plus important : la recherche robotique est en train de devenir un travail de conception d'environnement, consistant à construire pour les Agents de codage un environnement dans lequel ils peuvent mener une recherche automatisée ; le travail algorithmique se déplace vers une couche supérieure, se tournant vers la construction d'une boucle de rétroaction que les Agents peuvent refermer par eux-mêmes.
Et cette boucle s'accumule de manière exponentielle : une compétence acquise aujourd'hui par un Agent devient demain un module de base pour construire et réinitialiser des environnements pour des tâches plus difficiles. Les capacités engendrent de nouvelles capacités.
Dans ce paradigme, la véritable contrainte dure est le budget d'interaction avec le monde réel.
Par conséquent, l'équipe de recherche propose deux indicateurs :
- Taux d'Utilisation Moyen des Robots (Mean Robot Utilization, MRU) : proportion du temps réel total pendant lequel les robots exécutent effectivement des expériences.
- Taux d'Utilisation Moyen des Token (Mean Token Utilization, MTU) : mesure l'efficacité avec laquelle l'Agent convertit les token en progrès de recherche.
Dans leurs expériences, le MRU est toujours inférieur à 50%. Autrement dit, les robots sont à l'arrêt la moitié du temps, attendant que l'Agent réfléchisse. Par conséquent, un meilleur cadre de travail et des modèles plus rapides se traduiront directement en bénéfices réels.
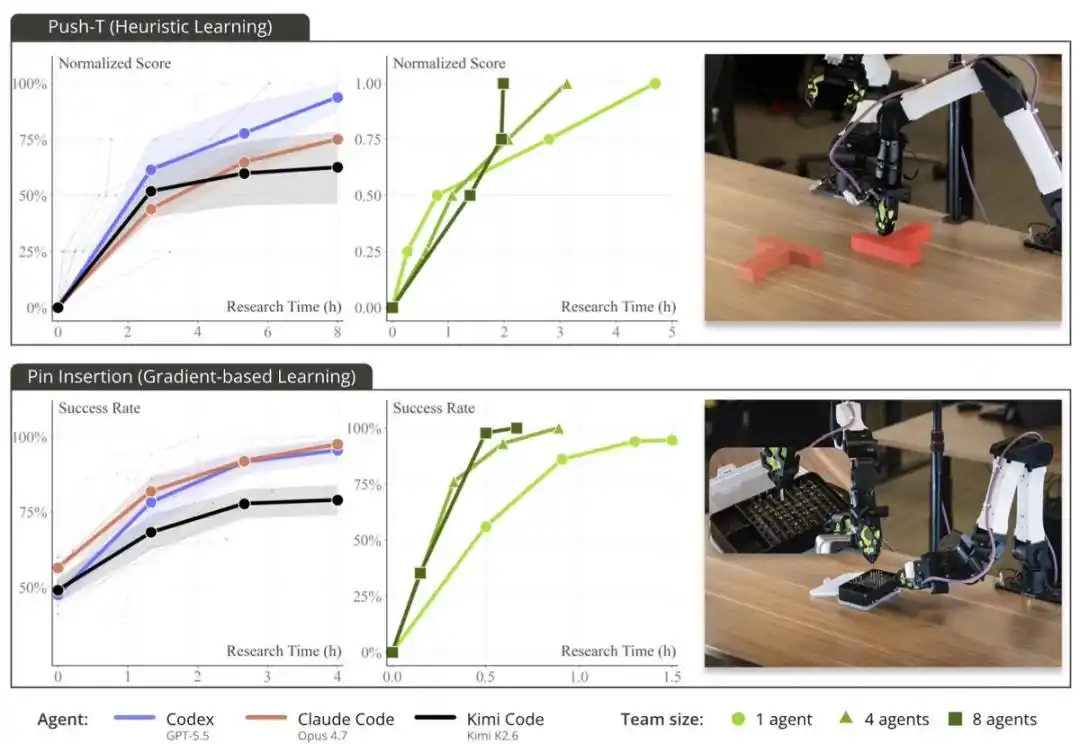
PushT est un benchmark de manipulation robotique utilisé depuis longtemps. Habituellement, accomplir cette tâche nécessite beaucoup de données de démonstration humaines, ainsi que plusieurs heures d'entraînement par clonage comportemental.
Mais ils ont constaté que Codex, Claude Code et Kimi Code ont tous « résolu » cette tâche en moins de 2 heures avec une méthode heuristique basée sur des règles : sans réseau de neurones, sans entraînement, et sans dépendre de données humaines.
Pour permettre à plus de personnes d'essayer la recherche automatisée dans le monde physique à la maison, ils ont développé un système complet basé sur le kit SO-101 de @LeRobotHF + NVIDIA Jetson Thor. Ce système peut accomplir la tâche PushT.
Liens de référence :
https://x.com/_wenlixiao/status/2066913334994358342
https://x.com/DrJimFan/status/2066921736369766762
Cet article provient du compte public WeChat « Machine Heart » (ID : almosthuman2014), auteur : Yang Wen