Le 22 juin 2026, le nouveau modèle Fugu de Sakana AI a fait l'effet d'un séisme au sein de la communauté de l'IA. Sur les benchmarks rigoureux SWE-Bench Pro et TerminalBench, Fugu Ultra a obtenu respectivement 73,7 et 82,1 points, dépassant ainsi GPT-5.5 et Claude Opus 4.8, et revendiquant même des performances comparables à celles de Fable 5 et Mythos Preview, soumis à des restrictions à l'exportation. La surprise est que ce système, au sommet en matière de capacités d'ingénierie et de raisonnement, n'est pas basé sur un géant aux milliers de milliards de paramètres, mais sur un modèle de seulement 7 milliards de paramètres. Il ne travaille pas lui-même, mais agit en tant que « chef de chantier » orchestrant de manière dynamique les meilleurs grands modèles mondiaux. Cette architecture contre-intuitive brise non seulement le mythe « plus de paramètres égale plus de puissance », mais reflète également la voie choisie par le Japon pour percer dans le domaine de l'IA malgré des ressources de calcul limitées.
Un "Chef de Chantier" à 7 Milliards de Paramètres : L'Architecture Contre-Intuitive de Fugu
Pour comprendre l'étrangeté de Fugu, il faut d'abord regarder ses origines. Sakana AI a été fondée à Tokyo en 2023 par Llion Jones, co-auteur de l'article sur le Transformer, et l'ancien chercheur de Google, David Ha. Dès sa création, cette entreprise était imprégnée d'une philosophie « inspirée par la nature », s'efforçant d'utiliser des algorithmes évolutionnaires et l'intelligence collective du monde naturel pour résoudre les problèmes d'IA. En 2025, Sakana AI a reçu des investissements de géants comme NVIDIA et Google, atteignant une valorisation de plus de 25 milliards de dollars. Mais même avec le soutien de ces grands noms, le Japon manque toujours des infrastructures de calcul massives et des réservoirs de données comparables à ceux de la Chine ou des États-Unis. Face à cette contrainte de ressources, Sakana AI n'a pas choisi de défier frontalement les grands modèles à milliers de milliards de paramètres, mais a plutôt opté pour une voie d'« orchestration ».
Le positionnement officiel de Fugu est celui d'« un système d'orchestration multi-agents agissant comme un modèle de base unique ». Dans l'architecture traditionnelle de l'IA, un grand modèle est une « bête monolithique » : l'utilisateur soumet une instruction, et le modèle calcule de la première à la dernière couche de son réseau neuronal pour produire un résultat. Ce mode est très efficace pour les problèmes simples, mais face à des tâches d'ingénierie complexes à plusieurs étapes, il est souvent sujet à des hallucinations ou des ruptures logiques.
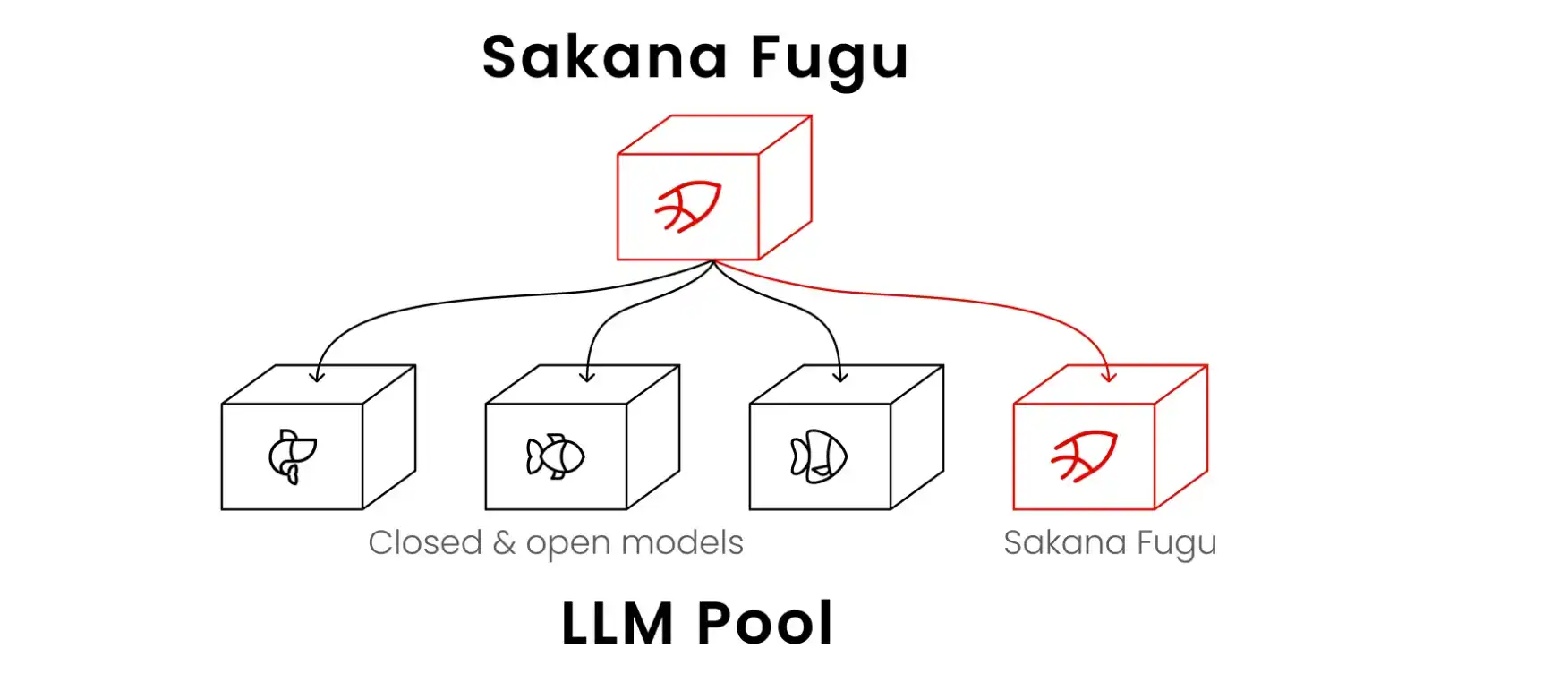
Fugu change radicalement ce paradigme. Son cœur est un modèle de 7 milliards de paramètres entraîné par apprentissage par renforcement, appelé RL Conductor. Ce modèle de 7B ne génère pas directement la réponse finale, mais joue le rôle de « chef de chantier ». Lorsqu'un utilisateur soumet une tâche via l'API unique compatible OpenAI, le RL Conductor analyse dynamiquement le type de tâche, puis distribue les sous-tâches aux modèles de pointe mondiaux dans le pool d'agents, comme GPT-5, Gemini 3.1 Pro ou Claude Opus 4.8. Il est responsable de l'orchestration, de la validation et de la synthèse des sorties de ces modèles, pour finalement fournir un résultat ayant subi de multiples vérifications.
Le soutien théorique de cette architecture provient de deux articles de l'ICLR 2026 : « TRINITY : An Evolved LLM Coordinator » et « Learning to Orchestrate Agents in Natural Language with the Conductor ». Ces articles détaillent comment un modèle à petits paramètres, via l'apprentissage par renforcement, peut « diriger » de grands modèles. Cela change le paradigme du Test-time scaling (mise à l'échelle au moment du test). Autrefois, la puissance de calcul était principalement utilisée pour le raisonnement profond à l'intérieur du modèle, le faisant « s'acharner » sur une réponse ; aujourd'hui, elle est utilisée pour l'orchestration externe, la validation et la synthèse. Les grands modèles traditionnels sont des entités monolithiques polyvalentes ; Fugu est une équipe d'experts. Le RL Conductor de 7B prouve que le nombre de paramètres du modèle n'est plus le seul critère déterminant la capacité ; savoir comment utiliser des outils et des agents externes peut également permettre un bond en avant des performances.
La Vérité Derrière les Scores : À la Haille de Fable et au-delà de GPT-5.5
La raison immédiate de l'impact de Fugu est son score sur des benchmarks rigoureux. Dans l'industrie de l'IA, les benchmarks sont la référence absolue pour mesurer les capacités d'un modèle, mais chacun a un accent différent. Ceux choisis par Sakana AI, SWE-Bench Pro et TerminalBench 2.1, sont tous deux des « casse-tête » orientés vers des environnements d'ingénierie réels.
SWE-Bench Pro se concentre sur les capacités de génie logiciel, exigeant du modèle qu'il localise et corrige des bugs dans de vrais dépôts de code. Selon les données publiées par la console de Sakana AI, Fugu Ultra a obtenu 73,7 points sur SWE-Bench Pro. À titre de comparaison, Claude Opus 4.8 a obtenu 69,2, GPT-5.5 58,6 et Gemini 3.1 Pro 54,2. Sur TerminalBench 2.1, un autre test évaluant les capacités opérationnelles du système, Fugu Ultra a obtenu 82,1 points, surpassant les 78,2 de GPT-5.5 et les 74,6 d'Opus 4.8. Ces deux tests évaluent non seulement la capacité de génération de code du modèle, mais aussi sa stabilité logique et sa capacité à utiliser des outils dans des tâches à plusieurs étapes et chaînes longues. L'avance de Fugu Ultra signifie qu'il est moins sujet aux plantages en cours de route ou aux déviations par rapport à l'objectif lorsqu'il traite des problèmes d'ingénierie complexes.
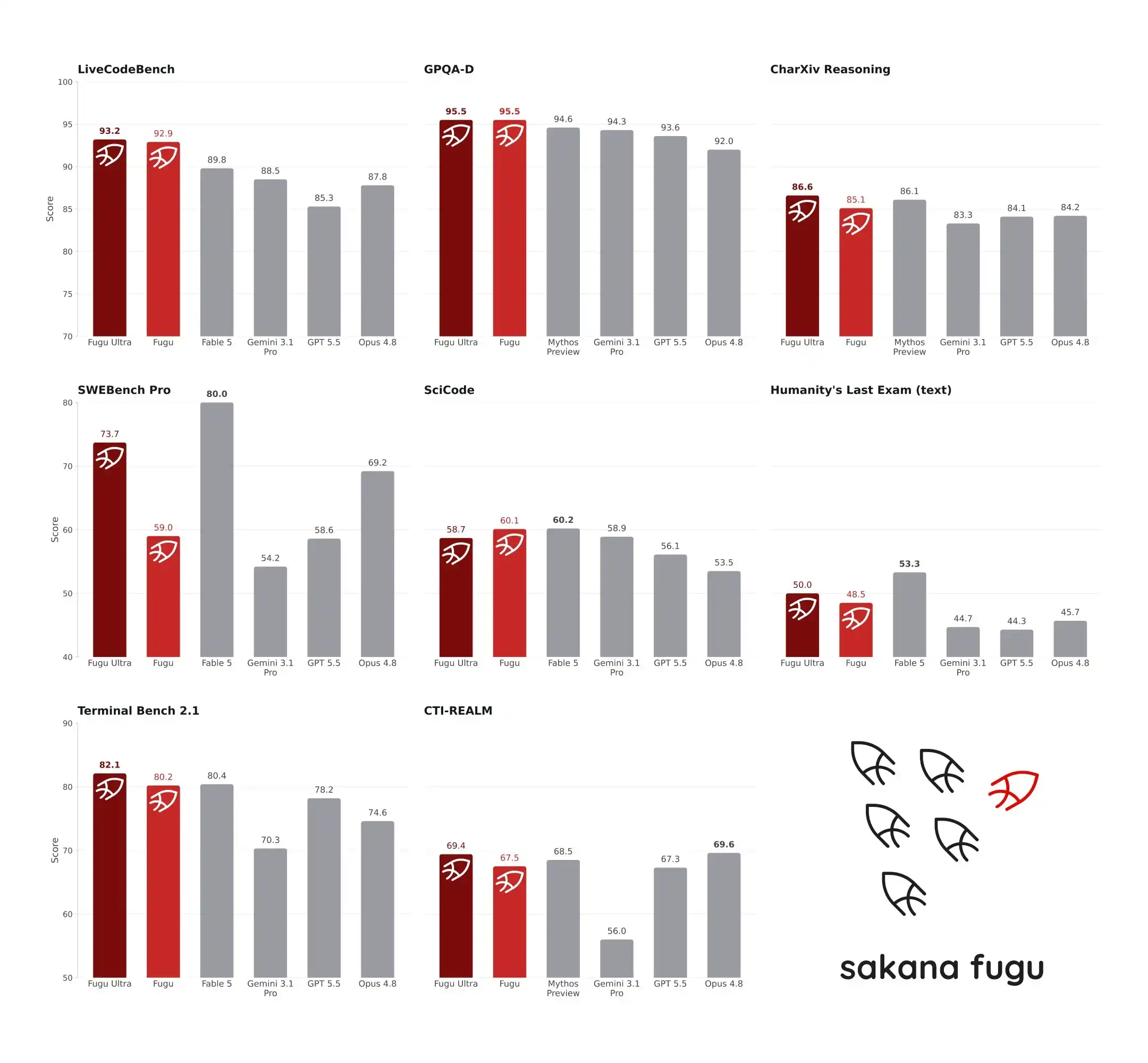
La comparaison avec Fable 5 et Mythos Preview attire encore plus l'attention. La série Fable d'Anthropic et la série Mythos d'un autre laboratoire de pointe représentent actuellement le plus haut niveau des capacités de raisonnement de l'IA. Cependant, en raison de restrictions à l'exportation ou d'un manque de divulgation complète, ces deux modèles ne font pas partie du pool d'agents de Fugu. Sakana AI déclare officiellement que Fugu Ultra est « comparable » à Fable 5 et Mythos Preview sur les benchmarks d'ingénierie et de sciences, mais il est important de préciser que cette comparaison n'est pas basée sur des tests dans le même environnement. Le score de Fugu est basé sur les résultats réels de son propre système, tandis que les données de Fable et Mythos sont basées sur les scores publiés par leurs fabricants respectifs.
Cette méthode de comparaison a suscité certaines controverses au sein de la communauté des développeurs. Certains estiment que les conditions de test dans des environnements différents sont difficiles à aligner parfaitement, et qu'une comparaison directe des scores n'est pas équitable. Mais d'autres développeurs soulignent qu'en l'absence d'un environnement de test unifié, se référer aux données publiées par les fabricants est une pratique courante dans le secteur. Mis à part la controverse avec Fable et Mythos, la supériorité de Fugu Ultra sur GPT-5.5 et Opus 4.8 sur SWE-Bench Pro et TerminalBench 2.1 est une comparaison réelle dans des conditions identiques. Cette supériorité ne vient pas du fait que le modèle sous-jacent de Fugu est plus intelligent que GPT-5.5, mais parce que le RL Conductor est plus précis dans la décomposition des tâches et l'orchestration des experts. Dans des expériences nécessitant plusieurs tours de raisonnement et de validation, comme AutoResearch, la résolution de Rubik's Cube ou la conception mécanique, Fugu continue de montrer des avantages. Cela prouve que face aux flux de travail réels, « longs, chaotiques et à plusieurs étapes », l'architecture d'orchestration multi-agents est effectivement plus résiliente que les modèles monolithiques.
Tests en Scénarios Réels de Développement : Revue de Code et Stabilité des Sessions Longues
Pour les développeurs et utilisateurs d'outils d'IA, les benchmarks ne sont qu'une référence. Ce qui détermine réellement l'utilité d'un modèle est sa performance dans des scénarios de travail réels. Avant sa publication, Fugu a fait l'objet de tests bêta auprès de près de 500 utilisateurs précoces, dont les retours ont révélé la valeur unique de Fugu dans des applications pratiques.
La revue de code est l'un des scénarios d'IA les plus couramment utilisés par les développeurs. Les modèles monolithiques traditionnels, lors de la revue de code, ne détectent souvent que des erreurs de surface de syntaxe ou des vulnérabilités logiques courantes. Lors des tests bêta, certains développeurs ont rapporté que Fugu se montrait exceptionnellement minutieux dans la revue de code, capable de trouver des bogues profonds d'architecture, là où d'autres outils ne trouvaient que quelques problèmes superficiels. Cette différence vient de l'architecture de Fugu. Le RL Conductor, après avoir reçu une tâche de revue de code, peut appeler respectivement des modèles spécialisés dans l'analyse statique, le raisonnement logique et la revue de sécurité, pour effectuer une validation croisée sous plusieurs angles sur le même morceau de code. Ce mode de « consultation d'experts » permet naturellement de découvrir plus de problèmes cachés que le « combat en solo » d'un modèle unique.
Un autre avantage fréquemment mentionné est la stabilité des sessions longues. Lors de la construction de produits d'Agent IA, l'un des problèmes les plus frustrants pour les développeurs est la « dérive de personnalité » du modèle dans les conversations longues. Au fur et à mesure que le nombre de tours de dialogue augmente, les modèles monolithiques ont tendance à oublier les paramètres initiaux ou à s'écarter du suivi des instructions. Des cadres d'entreprise ayant testé le modèle ont rapporté que le Persona (personnalité) de Fugu dans les conversations longues était exceptionnellement stable, avec presque aucune dérive. Cela s'explique par le fait que le RL Conductor lui-même n'est pas responsable de maintenir la mémoire du long texte ; il est seulement responsable, à chaque tour de dialogue, de sélectionner avec précision le modèle sous-jacent le plus approprié pour générer la réponse en fonction du contexte actuel. Cette architecture « séparant le contrôle de la génération » améliore considérablement la stabilité de l'Agent lors d'exécutions prolongées.
Dans le domaine de la cybersécurité, Fugu a également démontré des capacités opérationnelles de bout en bout. Lors des tests, Fugu a pu effectuer de manière autonome un processus complet, de la reconnaissance à la détection de vulnérabilités XSS/SQLi, en passant par l'examen d'authentification, et générer un rapport complet de test d'intrusion, tout en respectant strictement les instructions de ne pas franchir les limites et détruire le système. Cette capacité à accomplir des tâches complexes repose sur l'orchestration précise par le RL Conductor de la chaîne d'outils de sécurité et des capacités des différents grands modèles.
De plus, l'efficacité des Tokens est un autre point fort de Fugu. Les grands modèles traditionnels, face à des problèmes complexes, génèrent souvent de longues chaînes de raisonnement, consommant un grand nombre de Tokens. Le RL Conductor de Fugu, grâce à son routage précis, évite la consommation inutile de longs CoT. Les tests officiels et précoces montrent qu'il réduit significativement le gaspillage de Tokens inutiles. Pour les développeurs facturés au Token, cela signifie non seulement une réduction des coûts, mais aussi une amélioration de la vitesse de réponse.
Le Point Faible de la Dépendance Sous-jacente : Le Prix de l'Orchestration Multi-Agents
Bien que Fugu brille par son architecture et ses scores, en tant qu'outil destiné à un travail réel, il n'est pas sans faiblesse. L'architecture d'orchestration multi-agents, tout en apportant des avancées en matière de performances, introduit également des risques et des limites non négligeables.
Le problème central est le risque de dépendance sous-jacente. Le pool d'agents de Fugu dépend fortement des API sous-jacentes des grandes entreprises américaines comme GPT, Claude, Gemini. Bien que le RL Conductor ait une capacité de routage dynamique et puisse basculer vers d'autres modèles en cas de panne ou de limitation de l'un d'eux, cela ne fait qu'éviter le risque d'un fournisseur unique, sans pouvoir se détacher de l'ensemble de l'écosystème d'infrastructure américain de l'IA. Si ces modèles sous-jacents augmentent collectivement leurs prix, imposent des limitations massives ou modifient leurs conditions d'API, la structure des coûts et la stabilité de Fugu seront directement impactées. Ce mode « parasitaire » sur l'infrastructure d'autrui présente une fragilité naturelle en termes de commercialisation et de stabilité à long terme.
Ensuite, il y a l'arbitrage entre latence et structure de coûts. Bien que le RL Conductor économise la consommation de Tokens inutiles grâce à un routage précis, l'orchestration multi-agents implique nécessairement de multiples appels API et des communications entre modèles. Pour les scénarios d'interaction en temps réel nécessitant une latence extrêmement faible, comme les conversations vocales en temps réel ou l'assistance aux transactions à haute fréquence, le temps de « réflexion profonde et d'orchestration » de Fugu Ultra pourrait être plus long que l'appel direct à un modèle monolithique. Dans ces scénarios où la vitesse de réponse est cruciale, l'avantage architectural de Fugu pourrait se transformer en un frein à l'expérience.
De plus, la controverse sur l'équité des comparaisons persiste. Comme mentionné précédemment, Fugu se revendique comparable à Fable et Mythos, mais ces derniers ne font pas partie de son pool d'agents. Au sein de la communauté des développeurs, certains remettent en question la valeur pratique de cette comparaison basée sur des données rapportées par les fabricants. Après tout, les performances des modèles varient considérablement selon la distribution des tâches, et une simple comparaison des scores totaux peut masquer des avantages et inconvénients spécifiques. Pour les développeurs qui ont besoin d'évaluer précisément les capacités d'un modèle, l'absence de données de test dans le même environnement signifie qu'il faut rester prudent lors du choix.
Ne Pas Lutter sur la Puissance de Calcul, mais sur l'Orchestration : La Percée Asymétrique des Grands Modèles Japonais
Au-delà de l'évaluation produit spécifique, la naissance de Fugu a une signification plus profonde pour l'écosystème des grands modèles japonais. Dans la course mondiale à l'armement de l'IA, le Japon occupe une position inconfortable. Il ne dispose ni de la puissance de calcul de pointe inépuisable et de l'accumulation d'algorithmes avancés des États-Unis, ni du vaste réservoir de données et de la concurrence féroce du marché chinois. Plus grave encore, le Japon est également confronté au risque de restrictions à l'exportation des modèles de pointe américains (comme Fable/Mythos). Dans ce contexte, la voie « algorithmes évolutionnaires » et « orchestration multi-agents » de Sakana AI illustre une logique de « percée asymétrique » pour un pays aux ressources limitées.
Le Japon n'est pas dépourvu de fabricants de grands modèles locaux. NTT a lancé tsuzumi, et des organisations comme ELYZA, Rinna et LLM-jp s'efforcent également d'entraîner des modèles linguistiques locaux. Mais la plupart de ces fabricants suivent la voie traditionnelle de « l'entraînement à partir de zéro », et il leur est difficile de rivaliser avec les modèles de pointe sino-américains en termes de taille de paramètres et de capacités générales. Sakana AI est le seul laboratoire parmi eux ayant une influence de pointe au niveau mondial et se concentrant sur une « architecture asymétrique ».
La capacité de routage dynamique de Fugu vise essentiellement à aider les entreprises et institutions japonaises à établir une « souveraineté en IA » (AI Sovereignty). Face à des ressources de calcul limitées, plutôt que de dépenser des sommes énormes pour entraîner un modèle à milliers de milliards de paramètres inférieur à GPT-5.5 en tout point, il est préférable d'entraîner un « chef de chantier » intelligent de 7B. Ce chef de chantier peut se connecter de manière flexible aux meilleurs modèles mondiaux en fonction des besoins de la tâche. Si un jour un modèle américain est soumis à des restrictions à l'exportation ou coupé, le RL Conductor peut rapidement rediriger la tâche vers d'autres modèles disponibles, voire vers des modèles spécialisés japonais. Cette architecture donne au Japon un certain degré d'autonomie et de capacité à résister aux risques dans l'utilisation des capacités d'IA.
OmniTools, en observant l'écosystème mondial des outils d'IA, constate que les capacités des grands modèles tendent progressivement à s'égaliser, et que le champ de bataille principal de la concurrence se déplace du simple empilement de paramètres vers la chaîne d'outils et les scénarios d'application. L'émergence de Fugu confirme cette tendance. Il ne cherche plus à atteindre la perfection sur un seul modèle, mais à optimiser au niveau du système. Cette approche a une signification importante pour les pays et régions qui ne bénéficient pas d'un avantage en termes de puissance de calcul et de données.
Bien sûr, cette « percée asymétrique » a aussi son plafond. Tant que les technologies de base des modèles sous-jacents restent entre les mains de quelques géants, la limite supérieure des capacités du système d'orchestration sera contrainte par les modèles sous-jacents. Fugu prouve qu'un modèle de 7B peut être un excellent commandant, mais il ne peut pas créer de lui-même des capacités que les modèles sous-jacents ne possèdent pas. Pour que les grands modèles japonais réalisent une véritable percée, en plus de l'innovation architecturale en matière d'orchestration, il faut continuer à investir dans la puissance de calcul sous-jacente, les algorithmes de base et les données de haute qualité. Fugu est une innovation astucieuse au niveau du système, mais ce n'est pas une panacée. Pour les développeurs et utilisateurs professionnels, Fugu offre une nouvelle option très compétitive dans les scénarios d'ingénierie complexes, mais il faut également être conscient de la fragilité de ses dépendances sous-jacentes et de l'arbitrage coût/latence lors de son utilisation.







