4-17%. C'est le taux de lecture du cache d'invite (prompt cache) de Claude Code au cours du dernier mois. Le niveau normal est de 97-99%.
Cela signifie que lorsque vous restaurez une session précédente, Claude Code ne réutilise pas le contexte déjà traité, mais retraite l'intégralité du contenu à partir de zéro à chaque fois, consommant ainsi 10 à 20 fois plus d'allocation que la normale. Vous pensez poursuivre une conversation, mais en réalité, vous recommencez à chaque fois une conversation entièrement nouvelle, facturée au tarif plein.
Ce chiffre provient de mesures de surveillance par proxy réalisées par le développeur indépendant ArkNill. En mettant en place un proxy transparent, il a enregistré chaque requête entre Claude Code et l'API d'Anthropic, découvrant au moins deux bogues de cache côté client qui empêchaient le serveur API de faire correspondre le préfixe de conversation déjà mis en cache, le forçant à reconstruire entièrement les tokens à chaque tour.
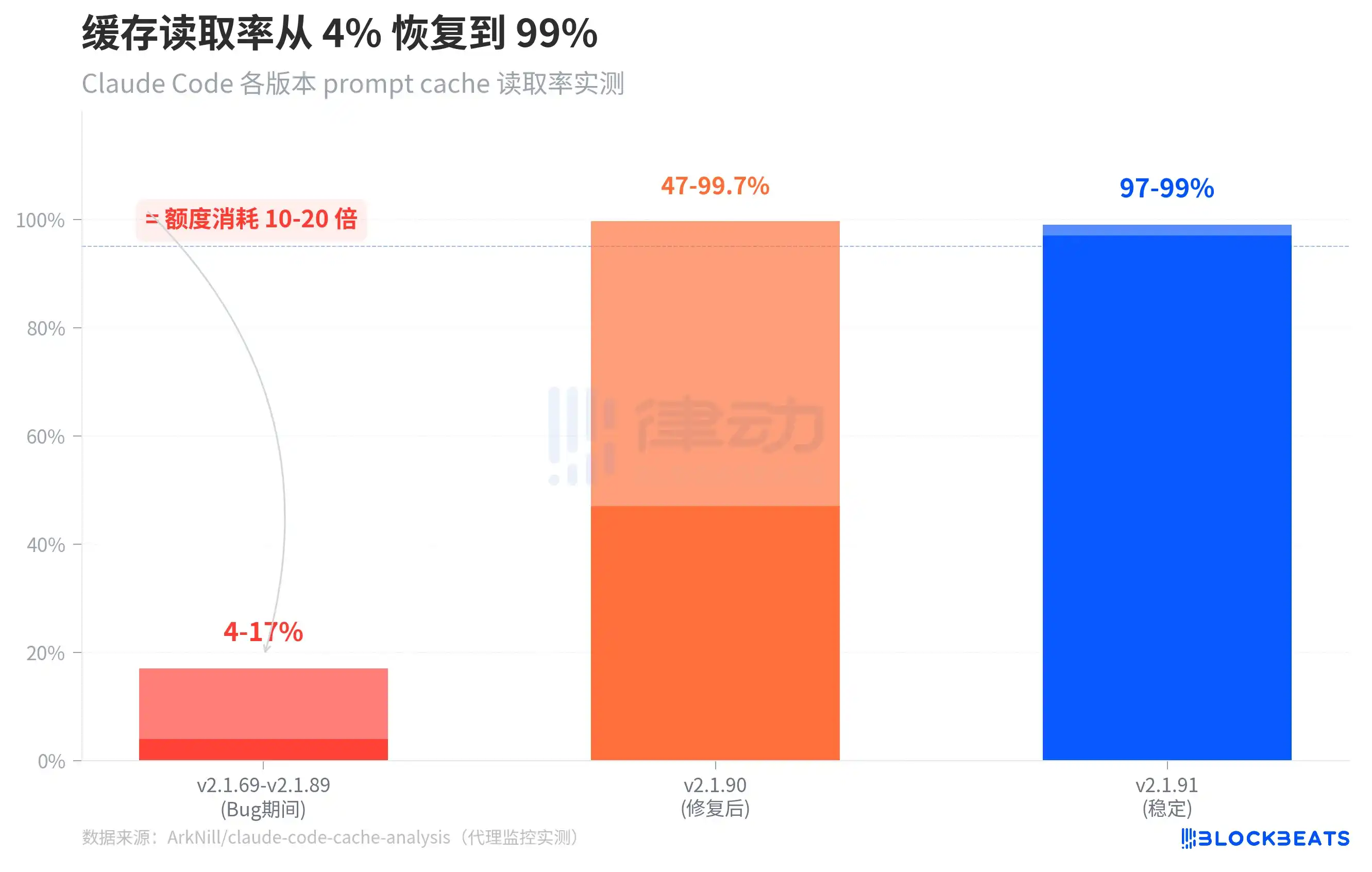
Le graphique ci-dessus montre une comparaison du taux de lecture du cache sur trois périodes. Pendant la période de v2.1.69 à v2.1.89 (période où le bogue était présent), le taux de lecture du cache de la version autonome (standalone) n'était que de 4 à 17%. Après la correction d'un bogue critique dans la v2.1.90, le taux de lecture du cache au démarrage à froid est remonté à 47-99,7%. Avec la v2.1.91, le taux de lecture du cache en fonctionnement stable est revenu à 97-99%.
Il est à noter un détail dans le graphique : la plage de la v2.1.90 est très large (47% à 99,7%), car la session nécessite encore un « préchauffage » du cache lors de la restauration, les premiers tours ayant un taux de réussite faible, mais celui-ci revient rapidement à un niveau normal. Dans la version boguée, ce préchauffage n'a jamais lieu – la lecture du cache reste bloquée sur les 14 500 tokens de l'invite système, et tout l'historique de la conversation est facturé au tarif plein à chaque fois.
28 jours, 20 versions
Ce bogue n'est pas du type « introduit dans une mise à jour, corrigé dans la suivante ». Selon les registres de publication de npm, la v2.1.69, qui a introduit le bogue, a été publiée le 4 mars, et la v2.1.90, qui l'a corrigé, le 1er avril. Soit un intervalle de 28 jours, couvrant 20 versions.
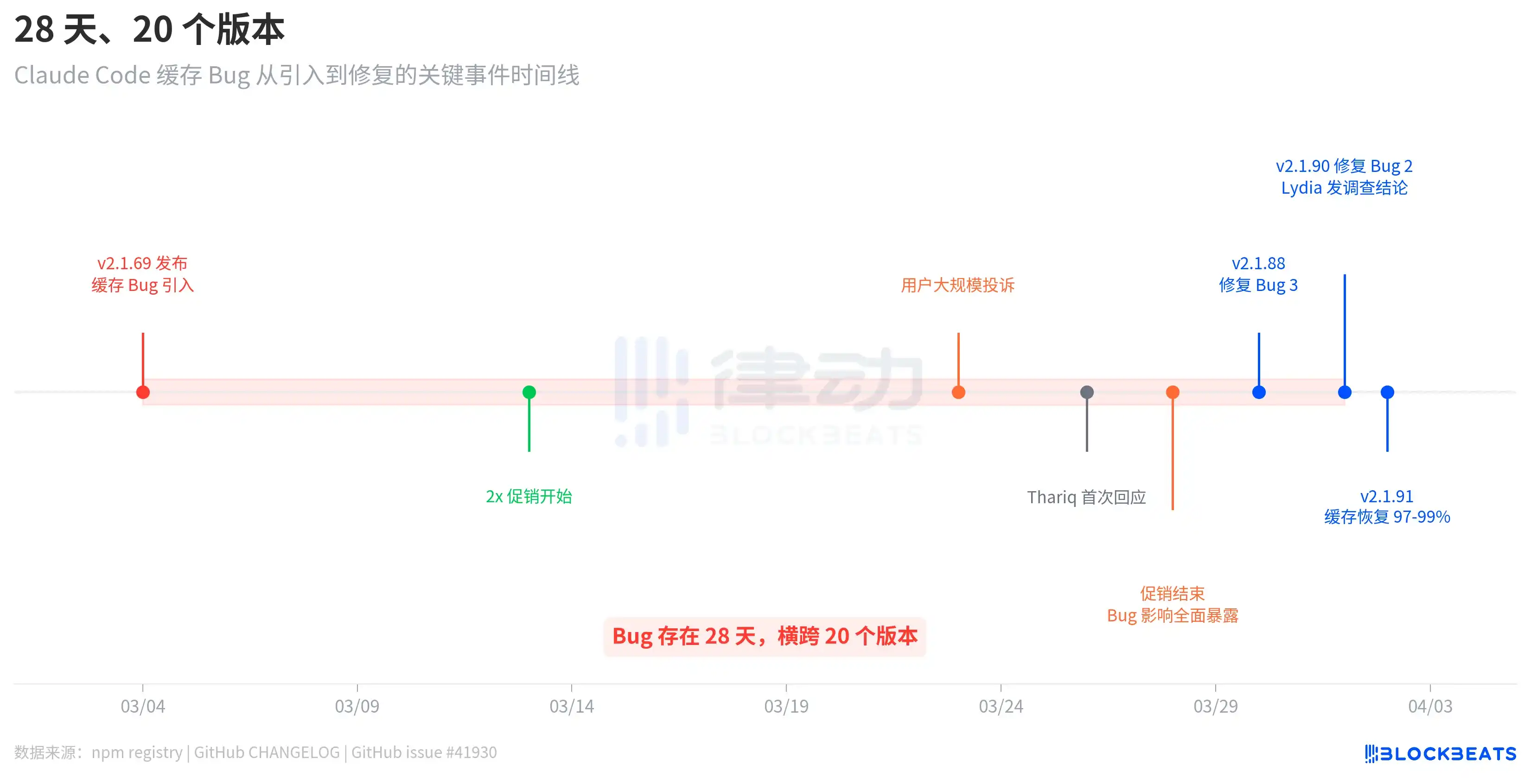
La chronologie révèle un détail intrigant. Après l'introduction du bogue le 4 mars, les utilisateurs n'ont pas immédiatement massivement protesté. Ce n'est que vers le 23 mars que les plaintes ont explosé, avec un intervalle de près de trois semaines. La raison, selon l'analyse de l'issue GitHub #41930, est qu'Anthropic avait mis en place une promotion doublant les allocations (hors heures de pointe) du 13 au 28 mars, ce qui a masqué l'effet du bogue. Une fois la promotion terminée, la consommation due au bogue de cache est revenue à la base de facturation normale, et les allocations des utilisateurs se sont « évaporées » instantanément.
La réponse d'Anthropic n'a pas venue rapidement. Le 26 mars, soit trois jours après l'explosion des plaintes, l'ingénieur Thariq Shihipar a annoncé sur son compte X personnel que les limites pendant les heures de pointe (en semaine de 5h à 11h PT) avaient été resserrées. Le 30 mars, Anthropic a reconnu sur Reddit que « les utilisateurs atteignaient leur limite beaucoup plus vite que prévu », affirmant en avoir fait la priorité absolue de l'équipe. Ce n'est que le 1er avril que la membre de l'équipe Lydia Hallie a publié les conclusions officielles de l'enquête.
Durant tout ce processus, Anthropic n'a publié aucun article de blog, n'a envoyé aucun email de notification, n'a pas mis à jour sa page de statut. Toute la communication officielle s'est faite uniquement via des posts sur les réseaux sociaux personnels des ingénieurs et quelques commentaires sur Reddit.
Combien payez-vous, combien de temps ça dure ?
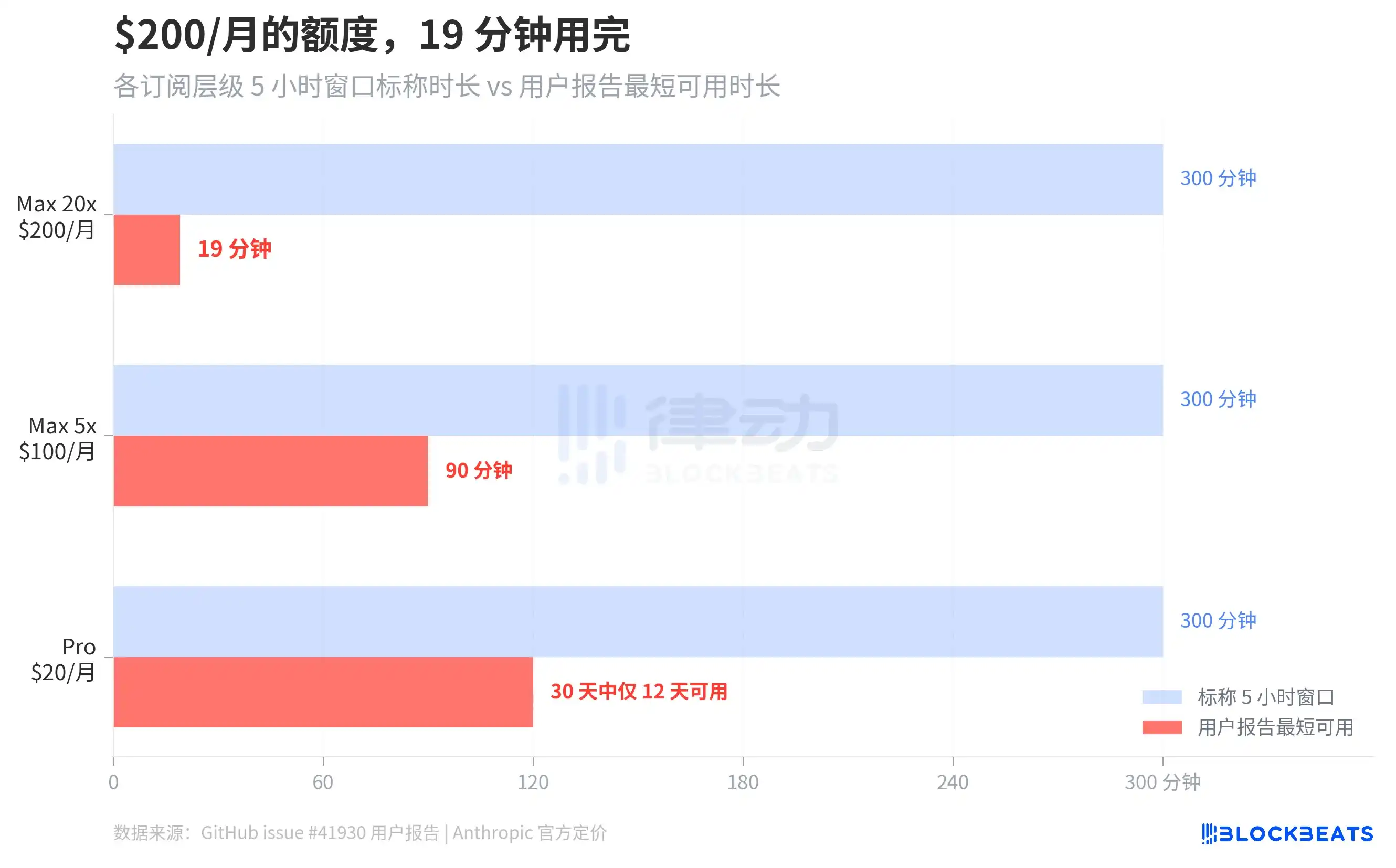
L'issue GitHub #41930 a rassemblé des centaines de rapports d'utilisateurs. Le cas le plus extrême est celui d'un utilisateur abonné Max 20x (200$/mois), dont la fenêtre glissante de 5 heures a été entièrement épuisée en 19 minutes. Des utilisateurs Max 5x (100$/mois) ont rapporté que leur fenêtre de 5 heures était utilisée en 90 minutes. Selon The Letter Two, un utilisateur a même affirmé qu'un simple « hello » avait consommé 13% du quota de session. Un utilisateur Pro (20$/mois) a déclaré sur Discord que son allocation était « épuisée chaque lundi, et ne se réinitialisait que le samedi », ne pouvant l'utiliser normalement que 12 jours sur 30.
Selon les tests de référence d'ArkNill, sur la version boguée v2.1.89, les 100% du quota du forfait Max 20x étaient épuisés en environ 70 minutes. Il a également calculé le coût en allocation d'une seule opération --resume sur une session avec un contexte de 500K tokens, environ 0,15$, car le système rejoue l'intégralité du contexte.
« Vous ne le tenez pas correctement »
Les conclusions de l'enquête de Lydia Hallie ont confirmé deux points : premièrement, les limites pendant les heures de pointe avaient bien été resserrées, et deuxièmement, la consommation des sessions avec un contexte de 1 million de tokens avait augmenté. Elle a déclaré que l'équipe avait corrigé certains bogues, mais a souligné qu'« aucun bogue n'avait entraîné de surfacturation ».
Elle a ensuite donné quatre conseils pour économiser l'allocation :
1. Utiliser Sonnet 4.6 plutôt qu'Opus (Opus consomme environ deux fois plus) ;
2. Baisser l'intensité de raisonnement ou désactiver extended thinking (pensée étendue) lorsque un raisonnement profond n'est pas nécessaire ;
3. Ne pas restaurer les longues sessions inactives depuis plus d'une heure, en ouvrir une nouvelle ;
4. Définir la variable d'environnement CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000 pour limiter la taille de la fenêtre de contexte.
Aucune forme de réinitialisation de quota ou de compensation n'a été mentionnée.
L'animateur de podcast sur l'IA Alex Volkov a résumé cette réponse par « Vous ne le tenez pas correctement » (You're holding it wrong), soulignant qu'Anthropic lui-même a défini le contexte de 1 million de tokens par défaut, a promu Opus comme modèle phare, a présenté extended thinking comme un argument de vente, et recommande maintenant aux utilisateurs payants de ne pas utiliser ces fonctionnalités.
L'affirmation selon laquelle il n'y a « pas eu de surfacturation » est également en tension avec les propres historiques de mise à jour de Claude Code. La veille de la réponse de Lydia, la v2.1.90 corrigeait un bogue de régression de cache présent depuis la v2.1.69 : lors de l'utilisation de --resume pour restaurer une session, les requêtes qui auraient dû toucher le cache provoquaient un prompt cache miss complet, facturé au tarif plein. La réponse de Lydia ne mentionnait pas cette anomalie de facturation confirmée.

En guise de comparaison, OpenAI avait précédemment rencontré un problème similaire de consommation anormale d'allocation avec Codex. La démarche d'OpenAI a été de réinitialiser les quotas des utilisateurs, de distribuer des crédits compensatoires, et d'annoncer en mars la suppression des limites d'utilisation de Codex. La démarche d'Anthropic est de recommander aux utilisateurs de rétrograder de modèle, de désactiver des fonctionnalités, de limiter le contexte, et de rejeter la responsabilité sur la façon dont les utilisateurs utilisent le service.
Anthropic vend un abonnement au « modèle le plus puissant + le plus grand contexte + la plus haute capacité de raisonnement », pour un coût de 20 à 200 dollars par mois. Un bogue de cache de 28 jours a fait s'évaporer l'allocation des utilisateurs payants 10 à 20 fois plus vite, et la réponse officielle est de vous dire de l'utiliser avec parcimonie.







