Datong, Shanxi, una ciudad que una vez dependió del carbón para sostener la mitad de su economía, ahora se sacude el polvo de hollín, cambia su pico por uno más afilado y golpea con fuerza hacia otra mina invisible.
En el centro de oficinas del Centro Internacional Jinmao en el distrito de Pingcheng, ya no hay pozos de ascensor ni camiones de carbón. En su lugar, hay miles de puestos de trabajo con computadoras estrechamente alineados. La Base de Servicios Inteligentes de Big Data Shanghai Runxun Yunzhong Shengu ocupa varios pisos completos, donde miles de jóvenes empleados con auriculares miran fijamente las pantallas, haciendo clic, arrastrando y seleccionando.
Según datos oficiales, hasta noviembre de 2025, la ciudad de Datong había puesto en funcionamiento 745,000 servidores, introducido 69 empresas de etiquetado de datos de llamadas y servicios, generado empleo para más de 30,000 personas localmente y alcanzado un valor de producción de 750 millones de yuanes. En esta mina digital, el 94% de los trabajadores son de origen local.
No es solo Datong. Entre las primeras bases de etiquetado de datos determinadas por la Administración Nacional de Datos de China, aparecen condados del centro y oeste del país como Yonghe en Shanxi, Bijie en Guizhou y Mengzi en Yunnan. En la base de etiquetado de datos del condado de Yonghe, el 80% de los empleados son mujeres. La mayoría son madres rurales o jóvenes que regresan a sus pueblos y no encuentran trabajo adecuado.
Hace cien años, las fábricas textiles de Mánchester, Inglaterra, estaban llenas de agricultores que habían perdido sus tierras. Hoy, frente a las pantallas de computadoras en estos condados remotos, se sientan jóvenes que no encuentran su lugar en la economía real.
Están realizando un trabajo extremadamente futurista pero primitivo por pieza, produciendo el alimento de datos necesario para los grandes modelos de inteligencia artificial de los gigantes tecnológicos de Pekín, Shenzhen y Silicon Valley.
A nadie le parece que esto sea un problema.
La nueva línea de ensamblaje en la meseta de Loess
La esencia del etiquetado de datos es enseñar a las máquinas a reconocer el mundo.
La conducción autónoma necesita reconocer semáforos y peatones; los grandes modelos necesitan distinguir entre un gato y un perro. La máquina en sí no tiene sentido común; primero debe ser un humano quien dibuje un cuadro en la imagen y le diga "esto es un peatón" para que, después de haber devorado millones de imágenes, pueda aprender a reconocerlo por sí misma.
Este trabajo no requiere educación superior, solo paciencia y un dedo índice que pueda hacer clic incessantemente.
En la edad de oro de 2017, un simple cuadro 2D podía valer más de diez céntimos, incluso algunas empresas ofrecían precios tan altos como cincuenta céntimos. Un etiquetador rápido, trabajando más de diez horas al día, podía ganar quinientos o seiscientos yuanes. En un condado, esto era sin duda un trabajo bien pagado y respetable.
Pero a medida que los grandes modelos evolucionan, el lado cruel de esta línea de ensamblaje comienza a manifestarse.
Para 2023, el precio unitario del etiquetado simple de imágenes se había desplomado a 3 o 4 fen (centésimas de yuan), una caída de más del 90%. Incluso para las imágenes de nube de puntos 3D, más difíciles, aquellas compuestas por puntos densos que deben ampliarse enormemente para ver los bordes, el etiquetador debe dibujar en el espacio tridimensional un cuadro tridimensional que contenga largo, ancho, alto y ángulo de desviación, para envolver perfectamente vehículos o peatones. Y un cuadro 3D tan complejo vale solo 5 fen.
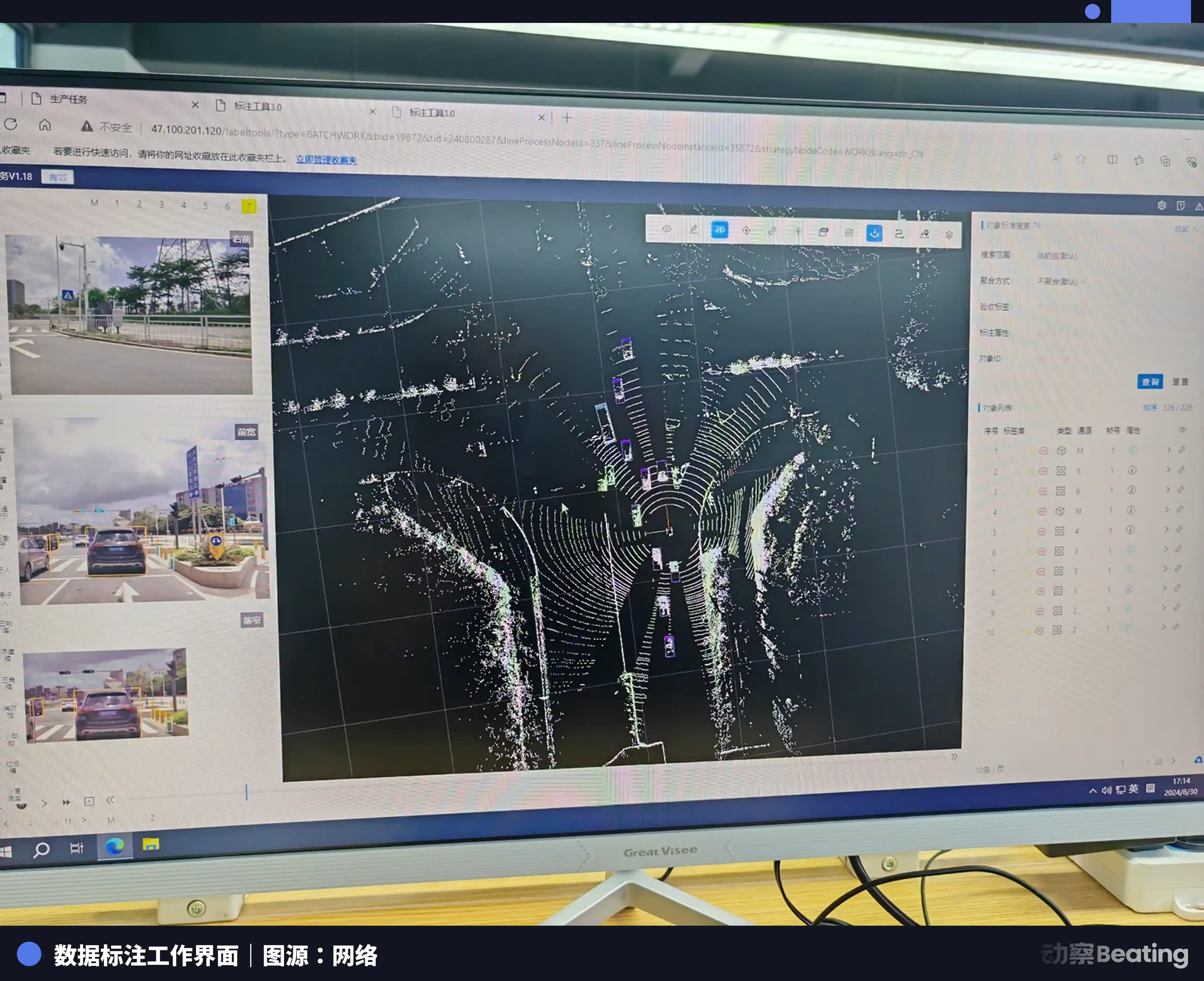
La consecuencia directa del desplome de los precios unitarios es el drástico aumento de la intensidad laboral. Para aferrarse desesperadamente a un salario base de dos o tres mil yuanes al mes, los etiquetadores deben mejorar constantemente su velocidad.
Esto no es en absoluto un trabajo de cuello blanco relajado. En muchas bases de etiquetado, la gestión es tan estricta que asfixia; no se permiten llamadas telefónicas durante el trabajo, los móviles deben guardarse bajo llave en taquillas. El sistema registra con precisión la trayectoria del ratón y el tiempo de inactividad de cada empleado. Si se detiene durante más de tres minutos, una advertencia del sistema llegará como un latigazo.
Lo que es más frustrante es la tasa de error permitida. El listón de aprobación de la industria suele estar por encima del 95%, algunas empresas incluso exigen un 98%-99%. Esto significa que si de 100 cuadros dibujados, te equivocas en 2, toda la imagen será rechazada para correcciones.
Las imágenes dinámicas tienen fotogramas consecutivos, los vehículos que cambian de carril pueden quedar ocultos, el etiquetador debe encontrarlos uno por uno usando la imaginación; en las nubes de puntos 3D, cualquier objeto con más de 10 puntos debe ser enmarcado. En un proyecto complejo de plazas de aparcamiento, las líneas demasiado largas, las etiquetas omitidas, siempre se encuentran fallos en el control de calidad. Es pan de cada día que una imagen sea devuelta para correcciones cuatro o cinco veces. Al final, después de una hora de trabajo, lo que llega a tus manos son solo unos pocos céntimos.
Una etiquetadora de Hunan mostró en una plataforma social su hoja de liquidación: después de un día de trabajo, había dibujado más de 700 cuadros, a un precio unitario de 4 fen, con un ingreso total de 30.2 yuanes.
Es una imagen extremadamente contradictoria.
Por un lado, están los elegantes magnates tecnológicos en las conferencias de prensa, hablando de cómo la AGI (Inteligencia Artificial General) liberará a la humanidad; por el otro, en los condados de la meseta de Loess y las grandes montañas del suroeste, los jóvenes miran fijamente la pantalla de ocho a diez horas al día, dibujando cuadros mecánicamente, miles, decenas de miles, incluso soñando por la noche con los dedos dibujando líneas de carril en el aire.
Alguien dijo una vez que la apariencia de la inteligencia artificial es un coche de lujo que pasa rugiendo, pero si abres la puerta, encontrarás a cien personas pedaleando frenéticamente en bicicletas, apretando los dientes.
A nadie le parece que esto sea un problema.
Los trabajadores a destajo que enseñan a las máquinas "cómo amar"
Cuando se superó el cuello de botella del reconocimiento de imágenes, los grandes modelos experimentaron una evolución más profunda; necesitaban aprender a pensar, hablar e incluso mostrar "empatía" como los humanos.
Esto impulsó el eslabón más central y costoso del entrenamiento de grandes modelos: el Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF).
En pocas palabras, se trata de que personas reales puntúen las respuestas generadas por la IA, indicándole cuál es mejor, más acorde con los valores y preferencias emocionales humanas.
Que ChatGPT parezca "humano" se debe a que detrás hay innumerables etiquetadores de RLHF dándole lecciones.
En las plataformas de crowdsourcing, este tipo de tareas de etiquetado suelen tener un precio explícito: de 3 a 7 yuanes por tarea. El etiquetador debe realizar una puntuación emocional extremadamente subjetiva de la respuesta de la IA, juzgando si la respuesta es "cálida", si "tiene empatía", si "cuida las emociones del usuario".
Un trabajador de base con un salario mensual de dos o tres mil yuanes, agotado por las dificultades de la realidad real, sin tiempo ni para sus propias emociones, debe actuar en el sistema como instructor emocional y juez de valores de la IA.
Necesitan desmenuzar a la fuerza emociones humanas extremadamente complejas y sutiles como la calidez y la empatía, cuantificándolas en frías puntuaciones del 1 al 5. Si su puntuación no coincide con la respuesta estándar establecida por el sistema, se considerará que no cumple con la tasa de precisión y se deducirá su ya escaso salario a destajo.
Es un vaciamiento cognitivo. Las complejas y profundas emociones, la moral y la compasión humanas están siendo arrastradas a la fuerza al embudo del algoritmo. En la fría cuantificación y estandarización, se les extrae hasta el último ápice de calidez. Mientras te asombras de que la bestia cibernética en la pantalla ya ha aprendido a escribir poesía, componer música, mostrar solicitud, incluso vestir una piel melancólica y sensible; fuera de la pantalla, ese grupo de humanos originalmente vibrantes, en el juicio mecánico día tras día, degenera en máquinas de puntuar sin emociones.
Este es el lado más oculto de toda la cadena industrial, que nunca aparece en las noticias de financiación ni en los libros blancos técnicos.
A nadie le parece que esto sea un problema.
Másteres de 985 y jóvenes de pueblos pequeños
El trabajo básico de dibujar cuadros está siendo aplastado por la oruga de la IA, esta línea de ensamblaje cibernética comienza a extenderse hacia arriba, a devorar trabajo intelectual de mayor nivel.
El apetito de los grandes modelos ha cambiado. Ya no se conforma con digerir常识 (conocimiento común simple), necesita devorar conocimiento especializado y lógica avanzada humana.
En las principales plataformas de contratación comenzaron a aparecer con frecuencia anuncios especiales de trabajos a tiempo parcial, como "etiquetado de razonamiento lógico para grandes modelos" o "entrenador humanístico de IA". El listón para este trabajo a tiempo parcial es extremadamente alto, a menudo requiriendo "titulación de máster de 985/211 o superior", en campos profesionales como derecho, medicina, filosofía, literatura, etc.
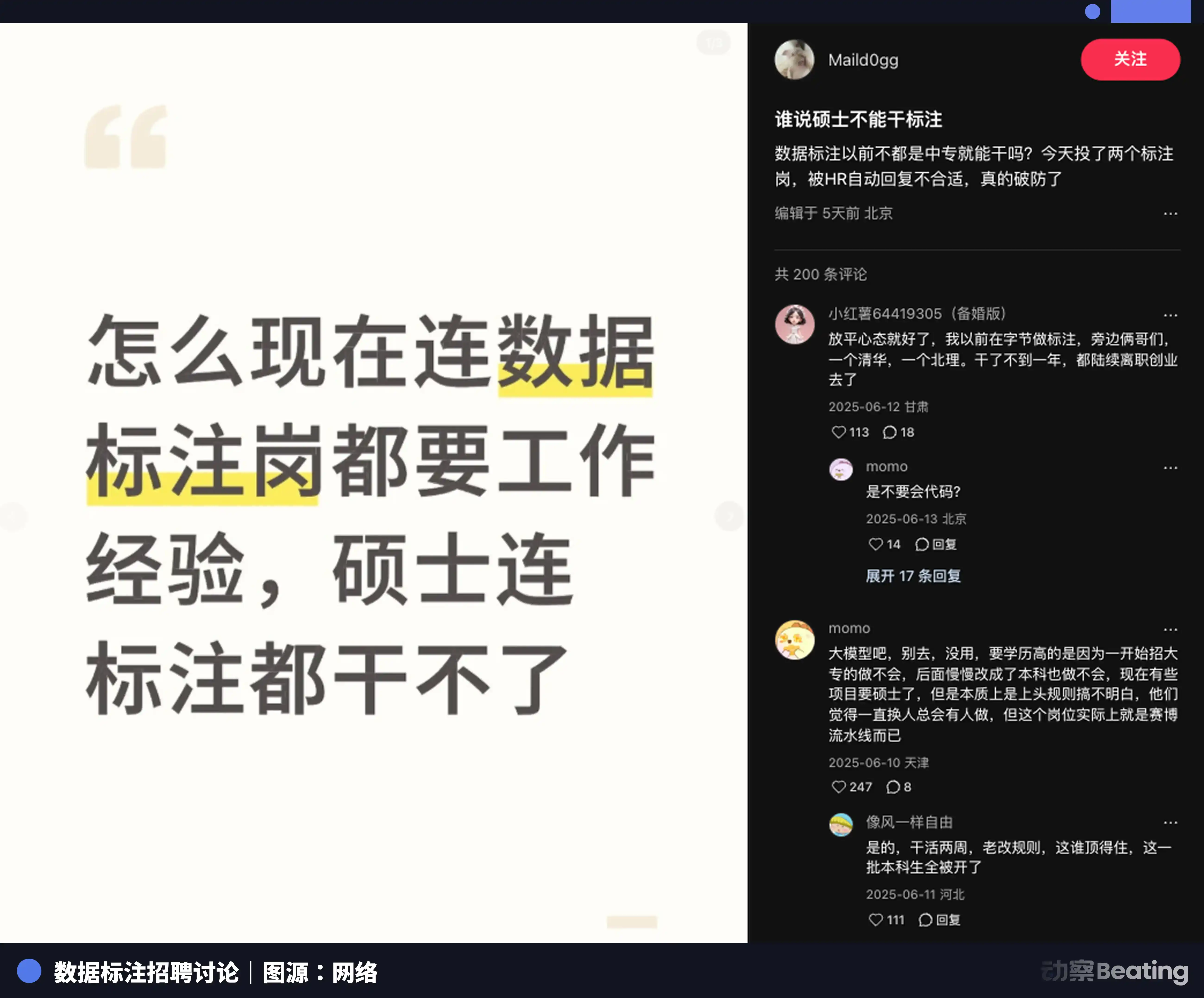
Muchos posgraduados de universidades prestigiosas son atraídos y se unen a estos grupos de subcontratación de las grandes tecnológicas. Pero pronto descubren que esto no es en absoluto una gimnasia mental relajada, sino una tortura psicológica.
Antes de aceptar pedidos formalmente, deben leer documentos de varias decenas de páginas con dimensiones de puntuación y criterios de evaluación, realizar dos o tres rondas de etiquetado de prueba. Una vez alcanzado el standard, durante el etiquetado formal, si la tasa de precisión cae por debajo del promedio, pierden su elegibilidad y son expulsados del grupo.
Lo más asfixiante es que estos standards no son fijos. Frente a preguntas y respuestas similares, usando la misma forma de pensar para puntuar, el resultado puede ser completamente opuesto. Es como hacer un examen interminable que no tiene una respuesta standard correcta. No se puede mejorar la precisión mediante el propio esfuerzo o el estudio, solo se puede dar vueltas en el mismo sitio, consumiendo energía mental y física.
Esta es la nueva explotación de la era de los grandes modelos: el plegamiento de clases.
El conocimiento, esa escalera dorada que una vez se consideró para romper barreras y ascender, ahora se ha convertido en forraje digital más complejo de masticar para ser ofrecido al algoritmo. Ante el poder absoluto del algoritmo y el sistema, los másteres de 985 de la torre de marfil y los jóvenes de pueblos pequeños de la meseta de Loess alcanzan la convergencia más extraña.
Juntos caen en este pozo minero cibernético sin fondo, despojados de su brillo, allanadas sus diferencias, todos convertidos en engranajes baratos y reemplazables en la cinta transportadora.
En el extranjero ocurre lo mismo. En 2024, Apple desmanteló directamente un equipo de 121 personas para etiquetado de voz de IA en San Diego. Estos empleados se encargaban de mejorar la capacidad de procesamiento multilingüe de Siri, alguna vez pensaron que estaban en el borde del negocio central de la gran empresa, pero cayeron instantáneamente al abismo del desempleo.
Para los gigantes tecnológicos, ya sean las señoras que dibujan cuadros en el condado o los entrenadores lógicos graduados de universidades prestigiosas, son esencialmente "consumibles" reemplazables en cualquier momento.
A nadie le parece que esto sea un problema.
La torre de Babel de billones, construida con el sudor de unos céntimos
Según datos publicados por la Academia China de Tecnología de la Información y las Comunicaciones (CAICT), en 2023 el mercado chino de etiquetado de datos alcanzó los 6080 millones de yuanes, se espera que para 2025 sean 20.000~30.000 millones de yuanes, y se predice que para 2030, las ventas globales del mercado de servicios y etiquetado de datos se dispararán hasta los 117,100 millones de yuanes.
Detrás de estas cifras, está la juerga de valoración de los gigantes tecnológicos como OpenAI, Microsoft, ByteDance, que se mueve en billones de yuanes, incluso billones de dólares.
Pero esta riqueza descomunal no fluye hacia aquellos que realmente "alimentan" a la IA.
La industria del etiquetado de datos en China presenta una estructura típica de subcontratación en pirámide invertida. En la cima, están los gigantes tecnológicos que controlan firmemente los algoritmos centrales; en el segundo nivel, los grandes proveedores de servicios de datos; en el tercer nivel, las bases de etiquetado de datos repartidas por todo el país y las pequeñas y medianas empresas subcontratistas; en la base, están esos etiquetadores con salario a destajo, con los pies en el barro.
Cada capa de subcontratación se lleva una buena tajada. Cuando el precio unitario que paga la gran empresa es de 50 céntimos, después de las sucesivas reducciones, lo que llega a las manos del etiquetador del condado puede ser menos de 5 fen.
Yanis Varoufakis, exministro de Finanzas de Grecia, en su libro "Technofeudalism", lanza una idea extremadamente penetrante: los gigantes tecnológicos de hoy ya no son capitalistas en el sentido tradicional, sino "señores de la nube" (Cloudalists).
Lo que poseen no son fábricas y máquinas, sino algoritmos, plataformas, potencia de cálculo, estos son el territorio digital de la era cibernética. En este nuevo sistema feudal, los usuarios no son consumidores, sino arrendatarios digitales; cada like, comentario, visualización que hacemos en las redes sociales es un tributo gratuito de datos a los señores de la nube.
Y esos etiquetadores de datos distribuidos en los mercados de menores ingresos son los siervos digitales más bajos en este sistema. No solo deben producir datos, sino también limpiar, clasificar, puntuar masas de datos en bruto, transformándolos en alimento de alta calidad que los grandes modelos puedan digerir.
Es un movimiento de acaparamiento cognitivo oculto. Al igual que el movimiento de cercamiento en la Inglaterra del siglo XIX expulsó a los campesinos hacia las fábricas textiles, la ola actual de IA expulsa a esos jóvenes que no encuentran lugar en la economía real hacia las pantallas.
La IA no ha allanado la brecha de clases, sino que ha establecido una "cinta transportadora de datos y sudor" que va directamente desde los condados del centro y oeste de China hasta las sedes centrales de los gigantes tecnológicos de Pekín, Shanghái, Cantón y Shenzhen. La narrativa de la revolución tecnológica siempre es grandiosa y华丽 (espléndida), pero su color de fondo es siempre el consumo a gran escala de mano de obra barata.
A nadie le parece que esto sea un problema.
El mañana que ya no necesita humanos
El final más cruel está cerca, cada vez más cerca.
A medida que aumentan las capacidades de los grandes modelos, esas tareas de etiquetado que alguna vez requirieron el trabajo día y noche de humanos, están siendo asumidas por la IA misma.
En abril de 2023, Li Xiang, fundador de Li Auto, reveló en un foro datos: en el pasado, Li Auto hacía aproximadamente 10 millones de fotogramas de calibración manual de imágenes de conducción autónoma al año, con un coste de subcontratación cercano a los cien millones de yuanes. Pero cuando comenzaron a usar grandes modelos para el etiquetado automático, lo que antes tomaba un año hacer, básicamente se podía completar en 3 horas.
La eficiencia es 1000 veces mayor que la humana, y esto ya en 2023. En marzo pasado, Li Auto también lanzó su nuevo motor de etiquetado automático MindVLA-o1.
En la industria circula una autocrítica terriblemente real: "Cuánta inteligencia, cuánta mano de obra". Pero ahora, la inversión de las grandes empresas en la subcontratación de etiquetado de datos ha experimentado una caída en picado del 40%-50%.
Esos jóvenes de pueblos pequeños que se sentaron innumerables días y noches frente a la computadora, con los ojos rojos de cansancio, alimentaron con sus propias manos a una bestia gigante. Y ahora, esta bestia se está volviendo para arrebatarles el tazón de arroz.
Al caer la noche, el edificio de oficinas del distrito de Pingcheng en Datong sigue brillando con una luz blanca como el día. Los jóvenes que cambian de turno intercambian silenciosamente sus cuerpos cansados en el ascensor. En este espacio plegado, firmemente aprisionado por innumerables cuadros poligonales, a nadie le importa qué avance épico ha tenido la arquitectura Transformer al otro lado del océano, ni nadie entiende el rugido del poder de cálculo detrás de los cientos de miles de millones de parámetros.
Su mirada está soldada únicamente a esa barra de progreso roja y verde en el sistema que representa la "línea de aprobación", calculando si esos céntimos, esas monedas del trabajo a destajo, podrán reunirse a fin de mes para formar una vida decente.
Por un lado, están las campanadas de Nasdaq y los extensos reportajes de los medios tecnológicos, los gigantes brindan por la llegada de la AGI; por el otro, esos siervos digitales que alimentaron con su carne y sangre a la IA, solo pueden esperar temblorosamente en sueños doloridos a que la bestia que ellos mismos criaron, en una mañana aparentemente ordinaria, les arrebate descuidadamente su tazón de arroz.
A nadie le parece que esto sea un problema.





