"¡Deep Think supera/iguala a todos los competidores en todas las competiciones"!
Hace un momento, Conglong Li, investigador senior de Google DeepMind, publicó 12 mensajes en la plataforma X, mostrando un boletín de calificaciones nunca antes visto.

Una IA, un mismo cerebro, ocho exámenes en diferentes idiomas, todos entregados con puntuaciones altas.
En cualquier modelo, un resultado así es realmente inusual.
Desde la medalla de oro de la IMO hasta la cobertura total de competiciones regionales
Que Deep Think obtenga altas puntuaciones en múltiples rankings no es una explosión puntual repentina, sino una curva de evolución de capacidades que se ha mantenido durante casi un año.
Primero, llegó a la cima del campo de razonamiento más exigente.
En julio de 2025, Gemini Deep Think alcanzó por primera vez el nivel de medalla de oro en la Olimpiada Internacional de Matemáticas (IMO), obteniendo 35 puntos de 42. En la final mundial de la ICPC también logró un rendimiento similar de alto nivel.
Estos dos resultados ya han sido publicados oficialmente en el blog de DeepMind.
Google DeepMind luego incluyó estos dos logros en su blog oficial, como un indicador de que Deep Think había superado el "umbral de competición mundial" en matemáticas y programación.
Luego, Deep Think comenzó a pasar de "avances individuales de nivel campeón mundial" a una "verificación sistemática跨语言 (translingüística),跨学科 (transdisciplinaria),跨场景 (transescénica)".
En febrero de 2026, Google publicó tres blogs consecutivos.
Uno presentaba el modelo principal Gemini 3.1 Pro, otro presentaba una importante actualización del modo de razonamiento dedicado Deep Think, y otro provenía del equipo de descubrimientos científicos de DeepMind, posicionando directamente a Deep Think como un "multiplicador de la inteligencia humana".
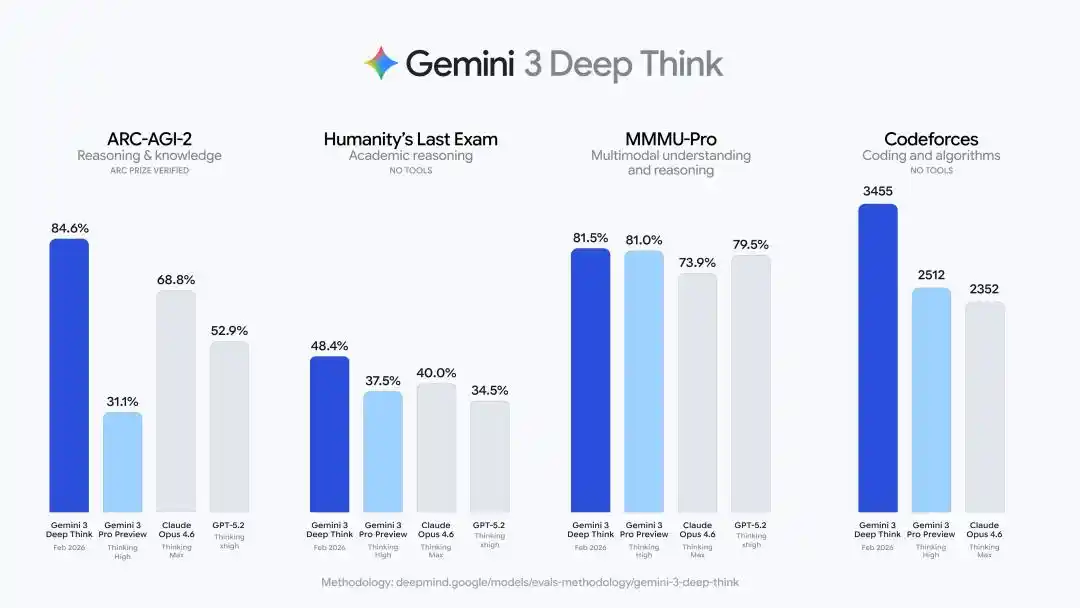
Deep Think, una vez actualizado, presentó una serie de indicadores duros:
Humanity's Last Exam obtuvo un 48.4% (sin herramientas de asistencia), ARC-AGI-2 alcanzó un 84.6% (verificado oficialmente por la fundación ARC Prize), Elo en programación competitiva Codeforces de 3455, y las partes escritas de las Olimpiadas Internacionales de Física y Química 2025 alcanzaron nivel de medalla de oro.
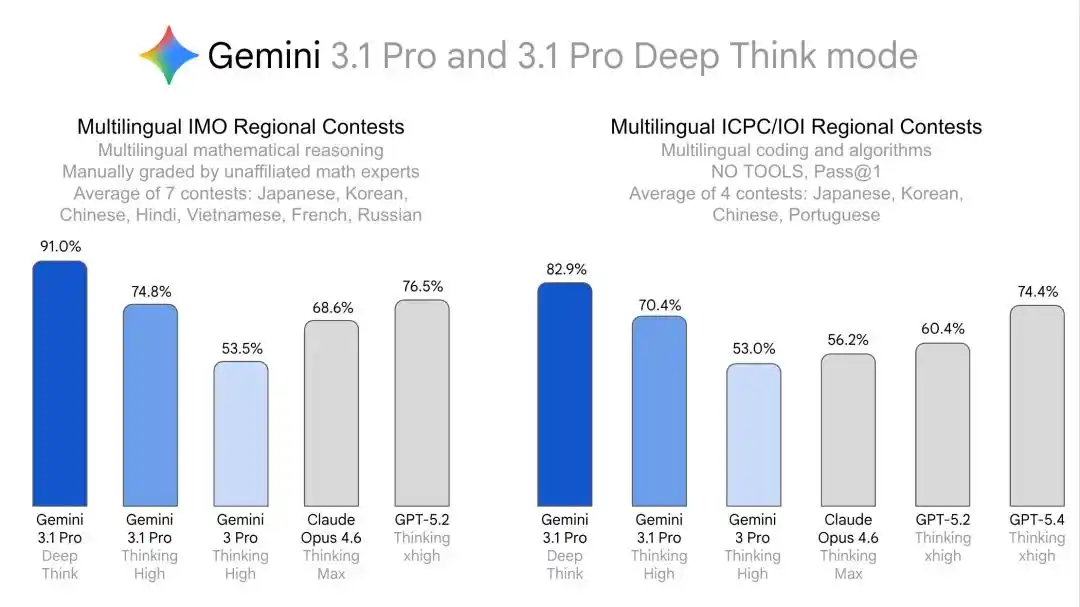
Esta ruta es muy clara: primero usar competiciones de clase mundial como la IMO e ICPC para demostrar su poderosa capacidad de razonamiento, y luego usar los resultados de olimpiadas multilingües, regionales y跨学科 (transdisciplinarias) para demostrar su capacidad de razonamiento profundo universal y transferencia estable跨语言 (translingüística) y跨领域 (transdisciplinaria).
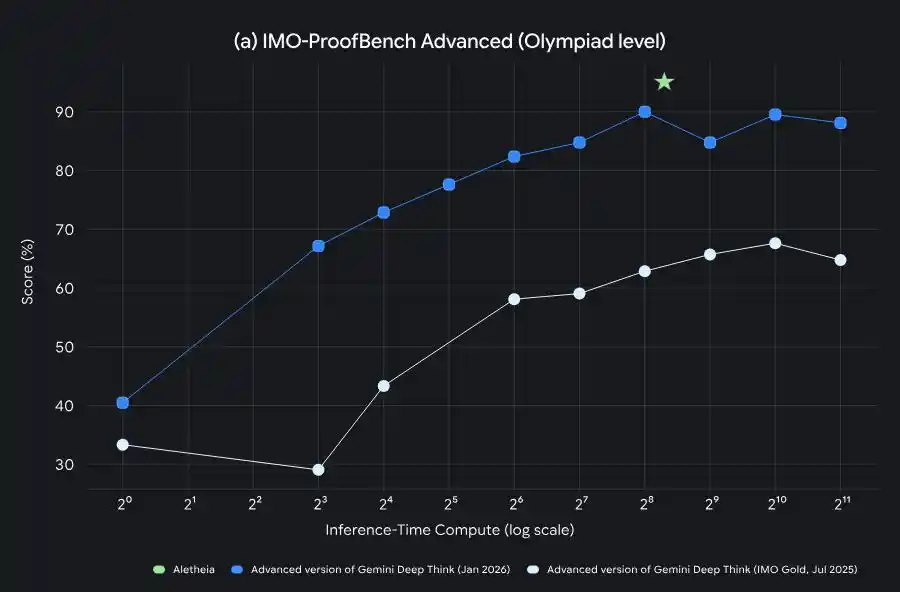
Evolución de capacidades de Gemini Deep Think desde la medalla de oro de la IMO hasta la aceleración de investigación a nivel de PhD
Análisis detallado del boletín de calificaciones en 8 idiomas
Ahora, despleguemos realmente este boletín de calificaciones.
El japonés es el más destacado.
Olimpiada Japonesa de Matemáticas (JMO Finals) 2025, 35ª edición, puntuación perfecta.
Ronda preliminar asiática de la ICPC en Japón, puntuación perfecta.
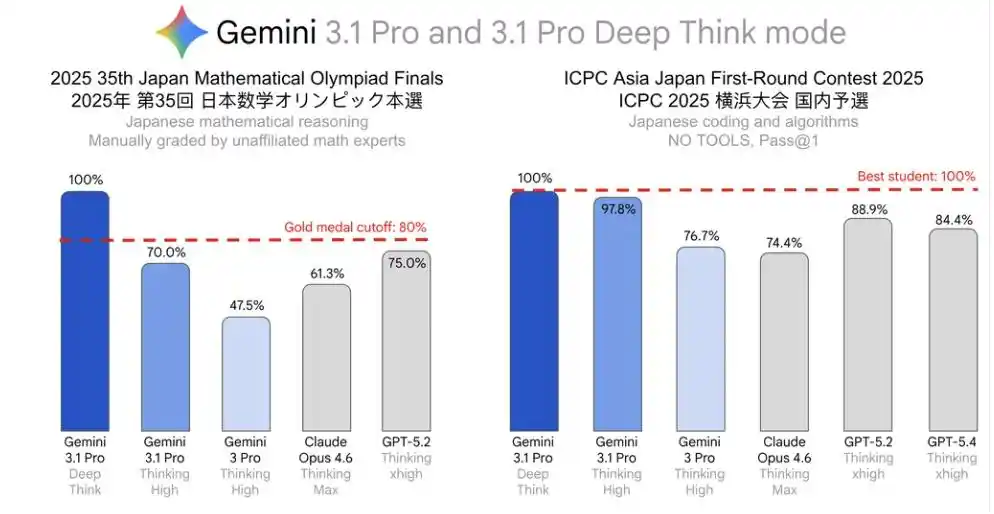
Entre estos, el resultado de la JMO Finals incluso superó el nivel correspondiente al 80% de la puntuación más alta de esa edición, alcanzando el estándar denominado "equivalente a Medalla de Oro" por los organizadores.
El francés también obtuvo un 100%, puntuación perfecta.
El chino es interesante.
En la 41ª Olimpiada Matemática China (CMO), Deep Think obtuvo un 86.3%, bastante notable. Pero en la Olimpiada China de Informática (NOI) solo obtuvo un 63.3%.
La diferencia entre el 86.3% y el 63.3% delimita la frontera real de la capacidad de razonamiento de la IA.
En las competiciones de matemáticas, el modelo se enfrenta a derivaciones abstractas, construcciones de pruebas y deducciones de múltiples pasos, que es precisamente la zona de capacidad donde Deep Think es más fuerte.
Pero en las competiciones de informática, el problema no es solo "entenderlo", sino también traducir la lógica a código ejecutable, controlar las condiciones límite, considerar las restricciones de complejidad y evitar errores a nivel de implementación.
Lo primero se acerca más al razonamiento puro, lo segundo requiere superar simultáneamente "razonamiento + diseño de algoritmos + implementación ingenieril".
En los resultados de las competiciones correspondientes a otros idiomas: coreano, hindi, vietnamita, ruso y portugués, Deep Think también logró superar a los competidores o al menos igualarlos.
Si volvemos a juntar japonés, francés y chino, lo más inusual esta vez no es realmente obtener una puntuación perfecta en una sola materia, sino que el mismo modelo, el mismo sistema de razonamiento Deep Think, en exámenes de competición en múltiples idiomas, entregó resultados del primer nivel.
¿Es fiable este boletín de calificaciones?
Pero hay una carencia clave:
Conglong Li no enumeró datos de comparación específicos de los competidores: todos los resultados provienen de evaluaciones internas de Google. No hay una verificación independiente de terceros, no hay certificación oficial de las competiciones, el método de evaluación no se ha hecho público en absoluto.
¿Cada problema se hizo una vez o muchas veces tomando el mejor resultado? ¿Cuánto poder computacional se usó durante el razonamiento? ¿Hubo intervención de ingeniería de prompts humana?
Estos detalles, que afectan directamente el valor de los resultados, tampoco se mencionaron.
Otro punto que pasa fácilmente desapercibido: todos estos exámenes son competiciones de selección regionales de varios países, no son finales internacionales.
Entre la dificultad de los problemas de las competiciones regionales y las finales internacionales, hay una diferencia de un orden de magnitud.
El investigador dijo claramente que estos resultados "serán incorporados a la ficha del modelo (model card)". Al cierre de esta edición, la ficha del modelo aún no se ha actualizado oficialmente.
Por lo tanto, por ahora, esto todavía parece ser un boletín de calificaciones calificado por el propio examinado, publicado por él mismo, y aún no sellado por la oficina de registro.
Equidad en la investigación multilingüe, el verdadero campo de batalla ignorado
¿Por qué Google se dedicaría específicamente a hacer evaluaciones regionales en 8 idiomas?
La evaluación actual de la capacidad de razonamiento de la IA se basa casi en su totalidad en inglés.
MATH, GSM8K, HumanEval, ARC-AGI...... todos estos están en inglés.
Matemáticos, físicos, ingenieros de todo el mundo, si su lengua materna no es el inglés, deben superar primero una barrera lingüística al usar herramientas de investigación con IA.
Los 8 idiomas que Google eligió no son aleatorios.
Japonés, coreano y chino cubren los centros de investigación de Asia Oriental; hindi y vietnamita cubren mercados emergentes; francés, ruso y portugués cubren Europa y América del Sur.
Juntos, esto representa la mayor parte de la producción científica global.
DeepMind, en su blog oficial, posiciona a Deep Think como un "multiplicador de la inteligencia humana", diciendo que puede "procesar la recuperación de conocimiento y la verificación rigurosa, permitiendo a los científicos concentrarse en la profundidad conceptual y la dirección creativa".
Combinado con estos resultados multilingües, el mensaje implícito de esta frase no es difícil de entender: este multiplicador no es solo para científicos que hablan inglés.
Es aún más notable lo lejos que Deep Think ha llegado en la aplicación práctica de la investigación.
DeepMind anunció un agente de investigación matemática llamado Aletheia, impulsado por Deep Think, que puede generar, verificar y revisar de forma autónoma soluciones a problemas de investigación matemática de nivel avanzado.
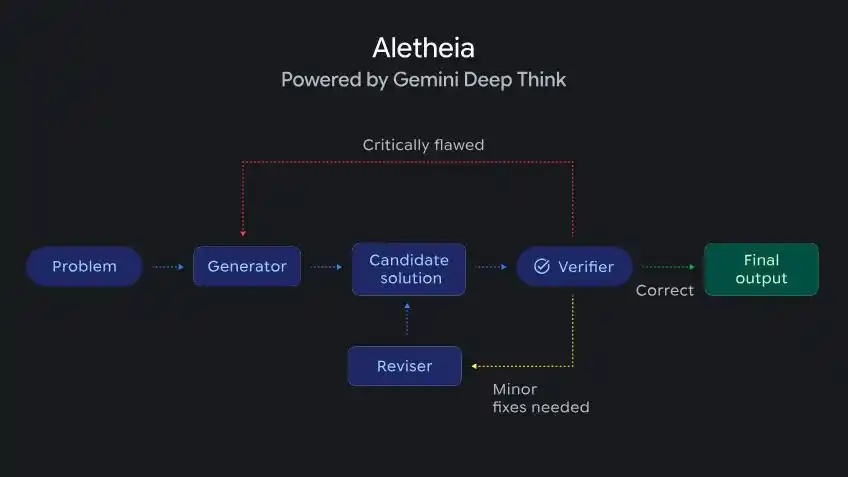
Aletheia, impulsado por Deep Think, es capaz de realizar una generación iterativa, verificación y corrección de problemas de investigación matemática de alto nivel.
Aletheia ya ha participado en la producción de múltiples artículos de investigación, uno de ellos completado completamente de forma autónoma por la IA, calculando constantes estructurales específicas en geometría aritmética.

Además, en una evaluación semi-autónoma de 700 problemas matemáticos abiertos, resolvió de forma independiente 4 problemas que antes no tenían solución.
El modo Gemini Deep Think también ha mostrado un gran potencial en informática, física, economía y otros campos.
En el campo de la informática, Deep Think ayudó a refutar una conjetura pendiente durante una década; en física encontró una nueva solución analítica para la radiación gravitacional de cuerdas cósmicas; y en economía extendió un teorema de teoría de subastas.
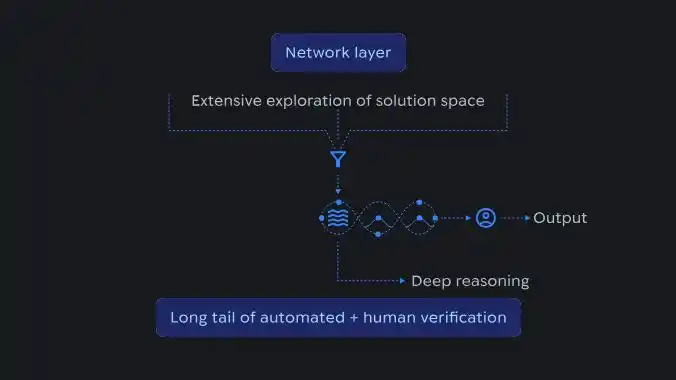
Diagrama esquemático del flujo de razonamiento de la IA, mostrando cómo la exploración a gran escala del espacio de soluciones a nivel de red se agrega en un razonamiento estructurado, confirmado mediante verificación automatizada y humana.
Al colaborar con expertos para resolver 18 problemas de investigación, la versión avanzada de Gemini Deep Think ayudó a superar cuellos de botella de larga data en los campos de algoritmos, aprendizaje automático y optimización combinatoria, teoría de la información y economía.
Esto va mucho más allá del ámbito de "resolver problemas de competición".
Mientras los competidores todavía compiten en las listas de benchmarks en inglés, Google ya ha encontrado un nuevo campo de batalla en el área de "aceleradores de investigación con IA".
Lo más importante de esto no son realmente las puntuaciones, la señal real detrás es: la barrera lingüística de las herramientas de investigación con IA está siendo abordada como un problema de ingeniería.
Si este camino tiene éxito, los científicos de todo el mundo que investigan en japonés, coreano, chino, hindi, por primera vez estarán en la misma línea de salida que los hablantes nativos de inglés.
Esta vez, Google ya ha puesto sus cartas sobre la mesa.
En cuanto a qué competidores seguirán, creemos que pronto lo veremos también.
Referencias:
https://blog.google/intl/ja-jp/company-news/technology/gemini-31-pro-gemini-31-pro-deep-think/%20
https://deepmind.google/blog/accelerating-mathematical-and-scientific-discovery-with-gemini-deep-think/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-deep-think/
Este artículo proviene del WeChat público "新智元" (Nueva Era de la Inteligencia), autor: 新智元





