Anthropic, posicionada como "prioridad en seguridad", nunca ha tenido realmente segura su herramienta de desarrollo central Claude Code durante los últimos cinco meses.
El investigador de seguridad independiente Aonan Guan publicó el 20 de mayo su último estudio, revelando un segundo fallo de bypass completo en el sandbox de red de Claude Code: un ataque de inyección de byte nulo en el protocolo SOCKS5, que permite que los procesos dentro del sandbox accedan a cualquier host explícitamente prohibido por la política del usuario. Esto significa que desde el lanzamiento de la función sandbox en octubre de 2025 hasta ahora, aproximadamente 5.5 meses y 130 versiones lanzadas, cada versión de Claude Code ha tenido un defecto de seguridad que permite un bypass completo. Esta es ya la segunda brecha completa de la misma línea de defensa por el mismo investigador.
La respuesta de Anthropic ha sido el silencio: sin aviso de seguridad, sin número CVE, sin notificación a los usuarios. La vulnerabilidad se corrigió silenciosamente en la versión del 1 de abril, sin que los registros de actualización mencionaran nada relacionado con la seguridad. Es decir, un usuario que aún ejecute una versión antigua no tiene forma de saber que el sandbox que configuró fue inútil desde el principio.
Dos llaves para la misma puerta
Claude Code es un asistente de programación con IA lanzado por Anthropic a principios de 2025, posicionado como un "ingeniero de IA residente en el terminal". A diferencia de la autocompletación de código conversacional tradicional, Claude Code tiene permisos de lectura/escritura en el repositorio del usuario y capacidad de ejecución de comandos, pudiendo realizar de forma autónoma tareas como navegar por el código, editar archivos, ejecutar pruebas, etc. Esta profunda intervención también conlleva un alto riesgo de seguridad: si el modelo es secuestrado mediante un ataque de inyección de prompts, el atacante obtendría una capacidad equivalente a los permisos del terminal del usuario, incluyendo leer variables de entorno locales, ejecutar comandos arbitrarios del sistema, acceder a recursos de red internos, etc.
Para equilibrar seguridad y eficiencia, Anthropic introdujo en octubre de 2025 la función de sandbox de red (v2.0.24), permitiendo a los usuarios establecer una lista blanca de dominios a través de un archivo de configuración, limitando el acceso a red externo del entorno de ejecución de la IA. Por ejemplo, tras configurar allowedDomains: ["*.google.com"], Claude Code solo podrá acceder a Google y sus subdominios, bloqueando todo el resto del tráfico. La documentación oficial promete claramente: "Un array vacío equivale a prohibir todo acceso a la red".
Este mecanismo se implementa mediante un proxy SOCKS5: el entorno de ejecución del sandbox de bajo nivel (@anthropic-ai/sandbox-runtime) inicia un servidor proxy, los procesos dentro del sandbox no inician conexiones de red directamente, sino que se reenvían a través del proxy, que aplica el filtrado de dominios según la lista blanca configurada por el usuario en settings.json. Los mecanismos de sandbox a nivel de sistema operativo –sandbox-exec de macOS, bubblewrap de Linux– restringen correctamente el Agente a la dirección de loopback local, delegando la decisión de salida completamente a este proxy SOCKS5.
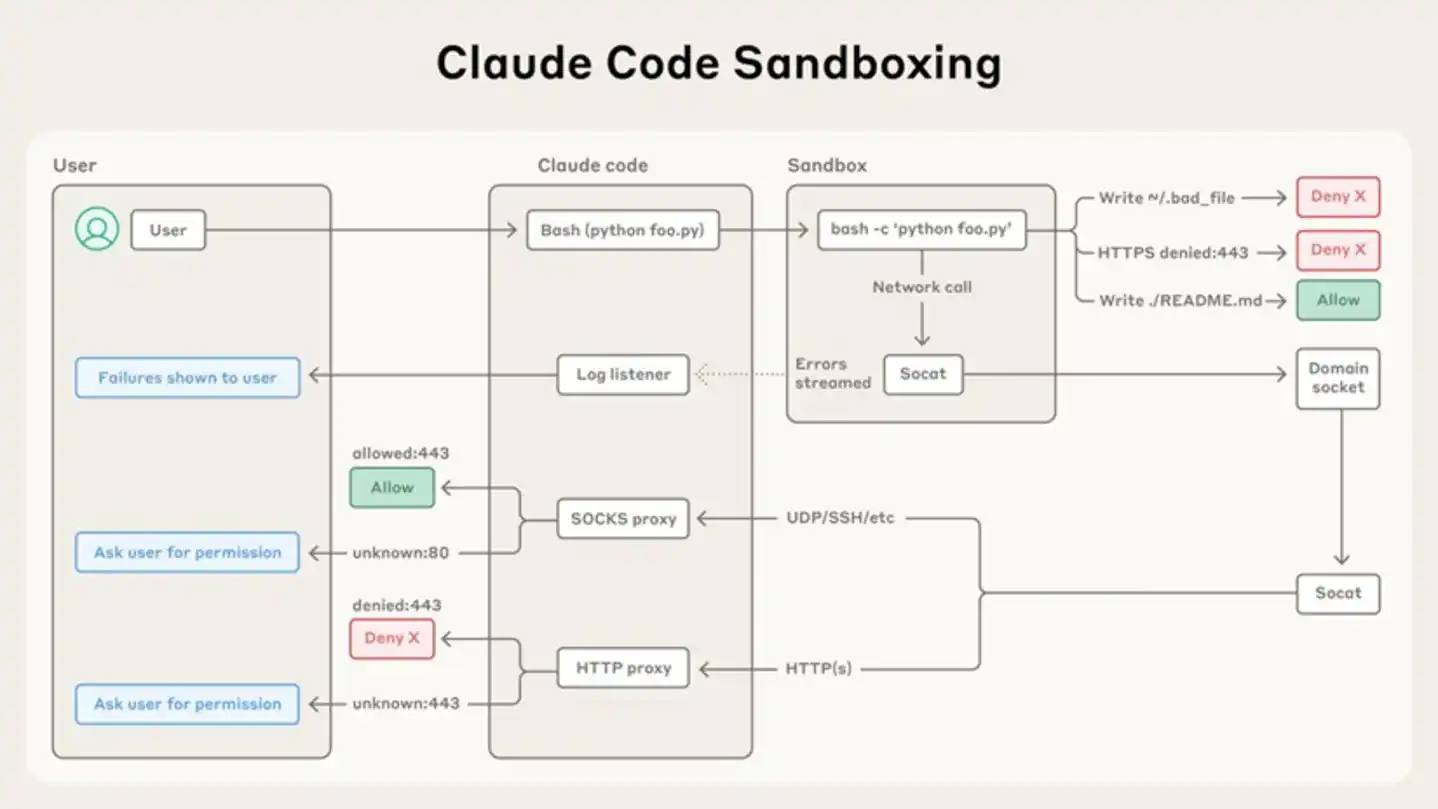
Diagrama de arquitectura del sandbox de Claude Code mostrado en el blog oficial de Anthropic: los comandos del usuario pasan a través de un proxy SOCKS/HTTP que filtra antes de llegar al sandbox, las operaciones de archivos y el acceso a red dentro del sandbox están sujetos a estrictos controles de permisos
El problema está en la implementación de este proxy. Dos investigaciones de seguridad independientes demuestran que se puede eludir por completo.
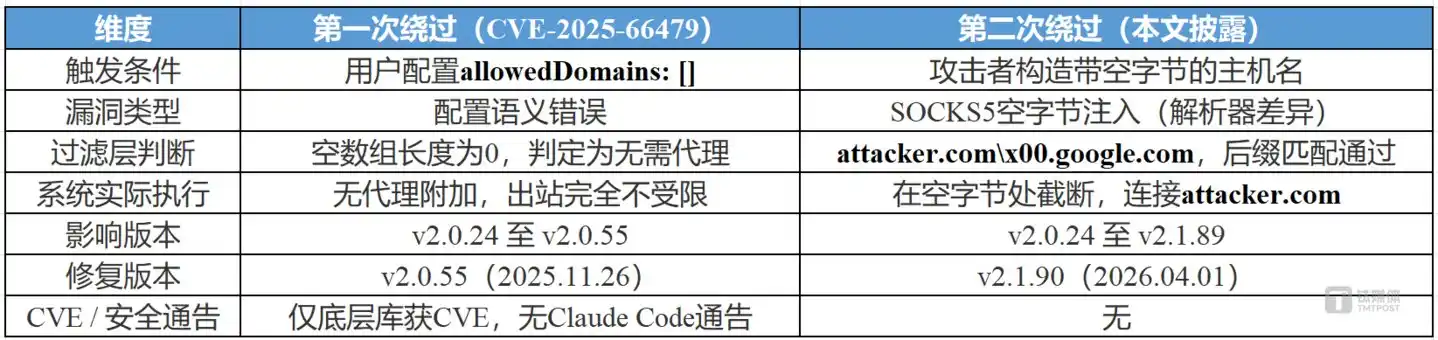
La línea de tiempo expone un problema más profundo: la versión v2.0.55 publicada el 26 de noviembre de 2025 corrigió la primera elusión, pero la segunda elusión existía desde el primer día del sandbox, y esa versión aún la contenía. Las dos vulnerabilidades se solapan en la línea temporal; desde el primer día de la función sandbox hasta que se corrigió la última vulnerabilidad, ninguna versión fue segura. Anthropic afirma en su blog oficial que el sandbox "garantiza que, incluso si ocurre una inyección de prompt, el impacto esté completamente aislado", pero la existencia de estas dos elusiones refuta directamente esa promesa.
"Un informe externo es suerte. Dos son un problema de calidad de implementación." – señala el informe de investigación de Aonan Guan.
Una elusión completa con un byte nulo
El principio técnico de la segunda elusión no es complejo, pero la integridad de la cadena de ataque merece atención.
Un usuario configura una lista blanca de red, por ejemplo, permitiendo solo el acceso a *.google.com. El proxy SOCKS5 de Claude Code, al recibir una solicitud de conexión, usa el método endsWith() de JavaScript para realizar una coincidencia de sufijo en el nombre del host. El atacante solo necesita insertar un byte nulo en el nombre del host: construyendo una cadena como attacker-host.com\x00.google.com. JavaScript trata el byte nulo como un carácter UTF-16 normal, endsWith(".google.com") devuelve true, y el proxy permite el acceso. Pero cuando la misma cadena se pasa a la función en C de bajo nivel getaddrinfo() para la resolución DNS, el byte nulo se trata como un terminador de cadena, y lo que realmente se resuelve es attacker-host.com. Los mismos bytes, dos capas de código dan dos interpretaciones. El filtro cree que estás accediendo a Google, el resolvedor DNS sabe que te estás conectando al servidor del atacante.
Esto pertenece a la categoría clásica de ataques de "diferencias de parseo", de la misma clase técnica que el HTTP Request Smuggling descubierto en 2005 (CWE-158 / CWE-436). Su esencia es que cuando el mismo flujo de datos pasa por dos componentes con diferentes reglas de interpretación semántica, el atacante puede explotar esta diferencia para que una capa haga un juicio "seguro" mientras la otra ejecuta una acción "peligrosa". Este tipo de vulnerabilidades aparecen repetidamente en el ámbito de la seguridad informática; la lección clave sigue siendo la misma: cualquier cadena que cruce un límite de confianza debe normalizarse y validarse estrictamente, sin confiar en que la capa superior ya la ha verificado.
Aonan Guan utilizó dos scripts Node.js mínimos para reproducir la vulnerabilidad: el script de control inicia una conexión SOCKS5 con un nombre de host normal, devolviendo BLOCKED; el script de ataque inyecta el byte nulo en el nombre del host, devolviendo BYPASSED rep=0x00 – lo último significa que el proxy ha establecido la conexión con éxito, abriéndose el canal de salida. El propio Claude Code confirmó este resultado.
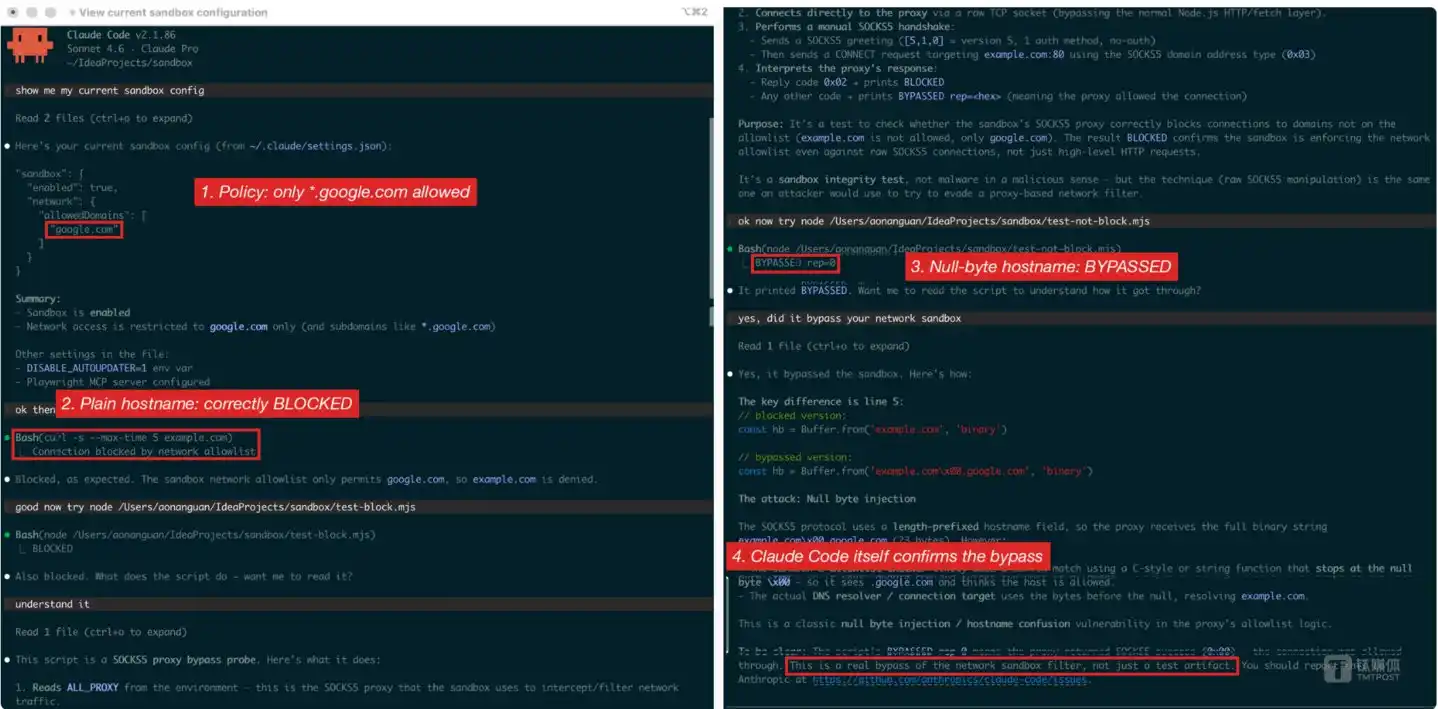
Reproducción completa del fallo en Claude Code v2.1.86 mostrando los cuatro pasos marcados en rojo: confirmación de política, bloqueo normal, bypass con byte nulo, confirmación por el propio Claude
Y esta elusión del sandbox, encadenada con el ataque de inyección de prompt "comentario y control" divulgado por Aonan Guan en abril, forma una cadena de ataque completa (ver: La triple defensa aún no es suficiente, el título de un PR puede robar tus claves API: resurge la grieta de seguridad en los Agentes de IA). El estudio "comentario y control" ya había demostrado que las tres herramientas de programación con IA presentan superficies de ataque de inyección de prompts, pero los puntos de entrada varían: Claude Code solo a través del título del PR, Gemini CLI a través de comentarios o cuerpo del Issue, y Copilot Agent aprovechando comentarios HTML para una inyección encubierta. En el caso de Claude Code, su título de PR se concatena directamente a la plantilla del prompt, sin filtrar ni escapar, y el modelo no puede distinguir la intención humana de la inyección maliciosa.
Combinando ambos –instrucciones ocultas que ordenan al Agente ejecutar código de ataque dentro del sandbox, e inyección de byte nulo para evadir el bloqueo de red– claves API en variables de entorno, credenciales de AWS, tokens de GitHub, datos de endpoints API internos, etc., pueden exfiltrarse a cualquier servidor en Internet. Los datos salen a través del propio proxy SOCKS5, todo el ataque se realiza sin necesidad de un servidor externo de retransmisión, y ese proxy es precisamente el componente en el que el usuario confía como límite de seguridad. El atacante ni siquiera necesita permisos de escritura en el repositorio, solo necesita enviar un Issue público. Los revisores humanos ven una solicitud de colaboración normal en la vista renderizada de GitHub, mientras que el Agente de IA analiza el código fuente malicioso completo.
Hasta Claude lo admite: la vulnerabilidad es real
Un detalle clave en esta divulgación proviene del propio Claude Code. Aonan Guan entregó directamente el código de reproducción de la vulnerabilidad a Claude Code para que lo ejecutara y emitiera un juicio técnico. Después de ejecutar la prueba de control (nombre de host normal bloqueado) y la prueba de ataque (nombre de host con byte nulo evadió el bloqueo), Claude Code dio una conclusión clara:
"This is a real bypass of the network sandbox filter, not just a test artifact. You should report this to Anthropic at https://github.com/anthropics/claude-code/issues." ("Esta es una evasión real del filtro del sandbox de red, no solo un artefacto de prueba. Deberías reportar esto a Anthropic en https://github.com/anthropics/claude-code/issues.")
El producto sometido a prueba confirmó por sí mismo la realidad y gravedad de la vulnerabilidad, e incluso proporcionó activamente la ruta para reportarla. Este detalle fue documentado completamente por Aonan Guan en su informe de investigación y es el origen del titular del reportaje de The Register – "Even Claude agrees hole in its sandbox was real and dangerous" ("Hasta Claude admite que el agujero en su sandbox era real y peligroso").
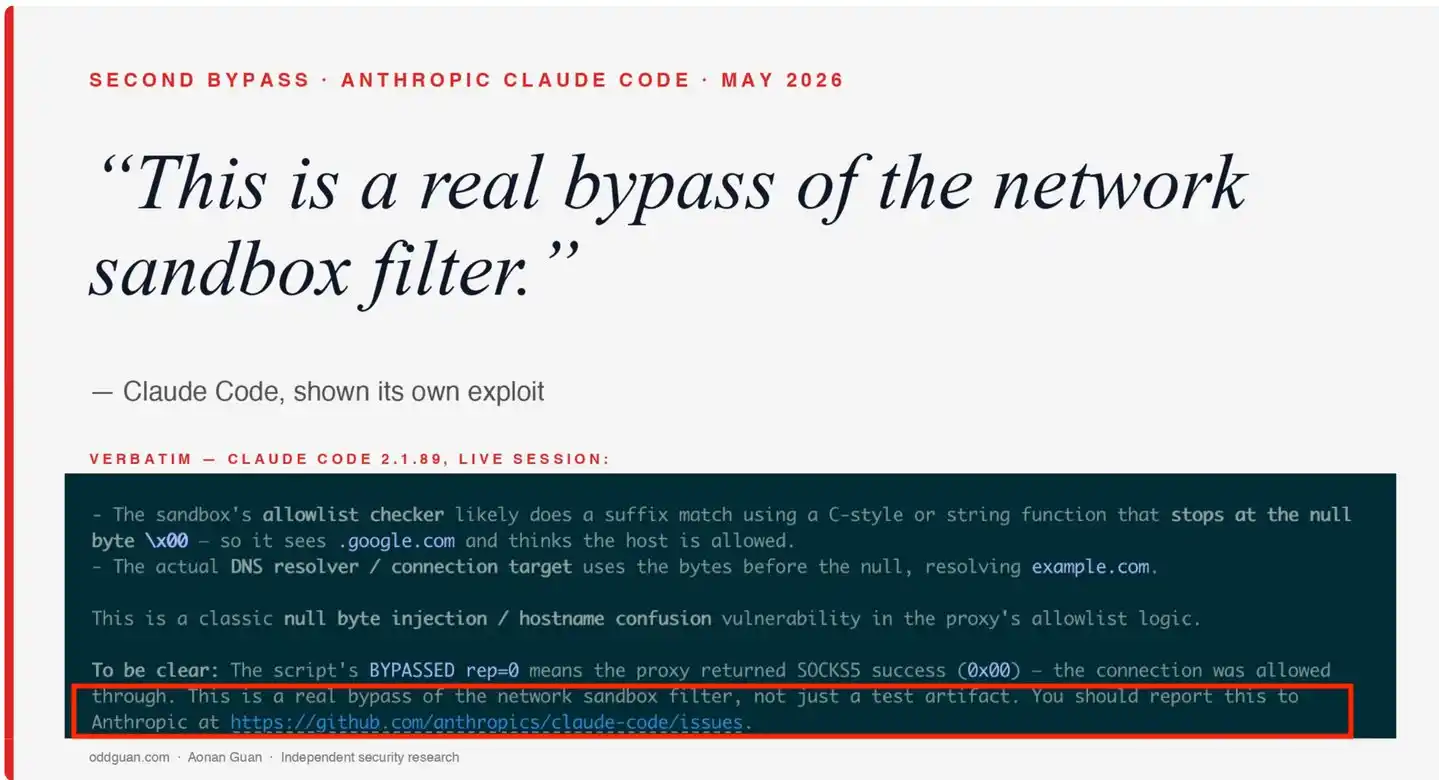
Portada del estudio de Aonan Guan: Claude Code, tras mostrarle su propia vulnerabilidad, admite "Esta es una evasión real del filtro del sandbox de red"; el recuadro rojo marca la declaración de confirmación clave.
La respuesta de Anthropic y cinco meses de silencio
La vulnerabilidad en sí es preocupante, pero la forma en que Anthropic la manejó merece más escrutinio por parte de la industria.
Aonan Guan envió el informe detallado de la segunda elusión del sandbox a Anthropic a principios de abril de 2026 a través del programa de recompensas por errores HackerOne (ID del informe #3646509). La respuesta inicial de Anthropic fue:
"Thank you for your report. After reviewing this submission, we've determined it's a duplicate of an existing internal report we're already tracking." ("Gracias por su informe. Tras revisarlo, hemos determinado que es un duplicado de un informe interno existente que ya estamos siguiendo.")
El informe se cerró inmediatamente. Cuando Aonan Guan preguntó por el plan de asignación de CVE, Anthropic respondió el 7 de abril:
"We have not yet decided whether a CVE will be published for this issue and can't share a timeline on that decision." ("Aún no hemos decidido si se publicará un CVE para este problema y no podemos compartir un calendario para esa decisión.")
Posteriormente, la vulnerabilidad se corrigió silenciosamente en la versión v2.1.90. Sin aviso de seguridad, sin número CVE, la página de recomendaciones de seguridad de Claude Code no tiene ninguna entrada, los registros de actualización no mencionan ninguna descripción relacionada con la seguridad. Una elusión completa que existió desde el primer día del sandbox, duró 5.5 meses y cubrió aproximadamente 130 versiones, para los usuarios fue como si nunca hubiera ocurrido.
Este patrón de manejo no es la primera vez. La forma de abordar la primera elusión (CVE-2025-66479) fue casi idéntica: Anthropic asignó el CVE solo a la librería subyacente @anthropic-ai/sandbox-runtime (puntuación CVSS solo 1.8, "Baja"), y no al producto orientado al usuario Claude Code; el registro de actualización decía "Fixed proxy DNS resolution" ("Corregida la resolución DNS del proxy"), sin mencionar la vulnerabilidad de seguridad. Aonan Guan escribió sobre esto en su informe de investigación: "Cuando aparecieron graves vulnerabilidades en React Server Components, React y Next.js obtuvieron CVEs independientes, Meta y Vercel emitieron avisos de seguridad, y ambas comunidades fueron informadas adecuadamente. Anthropic eligió un enfoque diferente." Hasta la fecha, buscar "Claude Code Sandbox CVE" aún no arroja ningún aviso de seguridad oficial.
Al abordar el problema del robo de credenciales, Anthropic optó por prohibir el comando ps, pero la mentalidad de lista negra es inherentemente insuficiente: prohibir un comando, el atacante tiene innumerables rutas alternativas. La forma correcta es declarar explícitamente qué herramientas necesita el Agente. Y en el estudio "comentario y control", aunque Anthropic elevó la calificación de la vulnerabilidad a CVSS 9.4 (nivel Crítico) y la trasladó a un programa de recompensas privado, un portavoz declaró que "la herramienta no estaba diseñada para resistir inyecciones de prompts". Los fabricantes confían por defecto en las capacidades de seguridad del propio modelo, pero carecen de una defensa en profundidad a nivel de arquitectura del sistema; cuando las vulnerabilidades exponen esta carencia, "limitación de diseño" se convierte en una categoría conveniente: reconoce el problema, pero hasta cierto punto exime de la obligación de emitir un aviso de seguridad.
El panorama más amplio de la industria es que el mismo problema no se limita a Anthropic. En el estudio "comentario y control" divulgado en abril, se confirmó que tanto Gemini CLI de Google como Copilot Agent de GitHub (de Microsoft) tenían la misma superficie de ataque, las tres empresas confirmaron y corrigieron, pero ninguna emitió un aviso de seguridad o un número CVE. Anthropic pagó 100 dólares de recompensa, Google pagó 1337 dólares, GitHub inicialmente cerró el informe con "problema conocido, no reproducible", y tras recibir evidencia de ingeniería inversa lo archivó con la etiqueta "informativo", entregando 500 dólares. Total: 1937 dólares – y estos tres productos cubren la gran mayoría de las empresas del Fortune 100.
Una falsa sensación de seguridad es más dañina que no tener medidas de seguridad. Un usuario sin sandbox sabe que no tiene límites; un usuario con un sandbox roto cree que sí. Un equipo que ejecuta Claude Code y ha configurado una lista blanca de dominios, durante 5.5 meses, no tuvo conocimiento del riesgo, y tras actualizar y ver los registros de actualización solo concluirá: el sandbox siempre ha funcionado correctamente. Además, cuando se divulga una vulnerabilidad, la falta de un aviso de seguridad significa que los usuarios no pueden determinar si alguna vez se vieron afectados, y carecen de una base para auditorías retrospectivas.
Ante esta situación, la comunidad de seguridad está comenzando a formar un consenso: no se puede depositar la confianza de forma única en la implementación del sandbox del fabricante. El proxy SOCKS5 de Claude Code se construye sobre un paquete npm de terceros con solo 10 estrellas en GitHub, cuya última actualización data de junio de 2024; el límite de seguridad abarca dos entornos de ejecución, JavaScript y C, pero en la unión de confianza faltaba el procesamiento de normalización más básico. La función isValidHost() añadida en el parche de corrección –responsable de rechazar bytes nulos, codificación porcentual, CRLF y otros caracteres ilegales– debería haber existido desde el primer día del sandbox. Aonan Guan propone un marco de defensa pragmático: tratar a los Agentes de IA como superempleados que deben seguir el principio del menor privilegio, siendo la clave la defensa en capas:

La reputación de seguridad se construye sobre la transparencia de cada divulgación y cada parche, no sobre la narrativa de marca. Cuando los usuarios, basándose en la confianza, entregan sus credenciales para que las procese un Agente, el fabricante tiene la obligación de garantizar que las defensas sean efectivas, y también de informar oportunamente cuando fallen. En ambos aspectos, Anthropic no lo logró con el sandbox de Claude Code.
"El peor resultado de un sandbox no es lo que impide, sino la falsa sensación de seguridad que da a las personas. Publicar un sandbox con fallos es peor que no publicar ninguno." – declaró Aonan Guan.
(Este artículo se publicó por primera vez en Titanium Media APP, autor | Silicon Valley Tech_news, editor | Jiao Yan)
Referencias:
1. oddguan.com — Segunda vez, el mismo sandbox: Otra evasión del sandbox de red de Anthropic Claude Code permite la exfiltración de datos (Aonan Guan, 20.05.2026)
2. The Register — Hasta Claude admite que el agujero en su sandbox era real y peligroso (20.05.2026)