Hace ocho años, ZTE sufrió un paro cardíaco.
El 16 de abril de 2018, una orden de prohibición de la Oficina de Industria y Seguridad del Departamento de Comercio de Estados Unidos dejó a ZTE, el cuarto mayor fabricante de equipos de comunicaciones del mundo con 80.000 empleados y unos ingresos anuales de más de 100.000 millones de yuanes, paralizada de la noche a la mañana. El contenido de la prohibición era simple: durante los próximos siete años, se prohibía a cualquier empresa estadounidense vender componentes, productos, software y tecnología a ZTE.
Sin los chips de Qualcomm, la producción de estaciones base se detuvo. Sin la autorización de Android de Google, los teléfonos tampoco tenían un sistema utilizable. 23 días después, ZTE emitió un anuncio afirmando que sus principales actividades comerciales ya no podían continuar.
Sin embargo, ZTE finalmente sobrevivió, pero a un costo de 1.400 millones de dólares.
Multa de 1.000 millones de dólares, pagada de una vez; 400 millones de dólares en garantía, depositados en una cuenta de custodia en un banco estadounidense. Además, se reemplazó a toda la alta dirección y se aceptó la llegada de un equipo de supervisión de cumplimiento estadounidense. En todo 2018, ZTE registró una pérdida neta de 7.000 millones de RMB, con unos ingresos que cayeron un 21,4% interanual.
Yin Yimin, entonces presidente de ZTE, escribió en una carta interna: "Estamos en una industria compleja y altamente dependiente de la cadena de suministro global". Esta frase, en ese momento, sonaba a reflexión y también a resignación.
Ocho años después, el 26 de febrero de 2026, el unicornio chino de IA DeepSeek anunció que su próximo modelo multimodal V4 priorizaría la cooperación profunda con fabricantes nacionales de chips, logrando por primera vez un flujo completo desde el preentrenamiento hasta el ajuste fino sin necesidad de soluciones de NVIDIA.
Traducción: ya no usaremos NVIDIA.
La primera reacción del mercado ante la noticia fue de escepticismo. NVIDIA tiene una cuota de mercado de más del 90% en chips para entrenamiento de IA a nivel global. ¿Abandonarlos, es comercialmente razonable?
Pero detrás de la elección de DeepSeek se esconde un problema mayor que la lógica comercial: ¿qué tipo de independencia en potencia de cómputo necesita realmente la IA china?
¿Qué es exactamente lo que se está estrangulando?
Muchos piensan que la prohibición de chips afecta al hardware. Pero lo que realmente asfixia a las empresas chinas de IA es algo llamado CUDA.
CUDA, abreviatura de Compute Unified Device Architecture, es una plataforma de computación paralela y modelo de programación lanzado por NVIDIA en 2006. Permite a los desarrolladores invocar directamente la potencia de cálculo de las GPU de NVIDIA para acelerar diversas tareas computacionales complejas.
Antes de la era de la IA, esto era solo una herramienta para unos pocos geeks. Pero cuando llegó la ola del aprendizaje profundo, CUDA se convirtió en los cimientos de toda la industria de la IA.
El entrenamiento de grandes modelos de IA es, en esencia, operaciones masivas de matrices. Y eso es precisamente el trabajo en el que las GPU son mejores.
Gracias a una planificación de más de una década, NVIDIA utilizó CUDA para construir una cadena de herramientas completa para los desarrolladores de IA globales, desde el hardware subyacente hasta las aplicaciones superiores. Hoy, todos los frameworks principales de IA, desde TensorFlow de Google hasta PyTorch de Meta, están profundamente vinculados con CUDA en su base.
Un estudiante de doctorado en IA, desde su primer día, aprende, programa y experimenta en un entorno CUDA. Cada línea de código que escribe, fortalece la ventaja competitiva de NVIDIA.

Hasta 2025, el ecosistema CUDA ya contaba con más de 4,5 millones de desarrolladores, cubriendo más de 3000 aplicaciones aceleradas por GPU, y más de 40.000 empresas a nivel global utilizaban CUDA. Esta cifra significa que más del 90% de los desarrolladores de IA del mundo están vinculados al ecosistema de NVIDIA.
Lo terrible de CUDA es que es una rueda de la fortuna. Cuantos más desarrolladores lo usen, más herramientas, librerías y código se generan, y más próspero se vuelve el ecosistema; cuanto más próspero es el ecosistema, más atrae a nuevos desarrolladores. Una vez que esta rueda gira, es casi imposible de detener.
El resultado es que NVIDIA te vende la pala más cara y además define la única postura para cavar. ¿Quieres cambiar de pala? Claro. Pero primero tienes que reescribir por completo toda la experiencia, herramientas y código acumulados durante más de una década por decenas de miles de las mentes más brillantes del mundo trabajando bajo esa postura.
¿Quién paga este costo?
Por eso, cuando el 7 de octubre de 2022, entró en vigor la primera ronda de controles de la BIS, restringiendo la exportación a China de las NVIDIA A100 y H100, las empresas chinas de IA sintieron colectivamente por primera vez la misma asfixia que ZTE. NVIDIA luego lanzó las versiones "especiales para China" A800 y H800, reduciendo el ancho de banda de interconexión entre chips, manteniendo a duras penas el suministro.
Pero solo un año después, el 17 de octubre de 2023, una segunda ronda de controles volvió a endurecer las restricciones, prohibiendo también las A800 y H800, y añadiendo 13 empresas chinas a la lista de entidades. NVIDIA se vio obligada a lanzar la H20, aún más limitada. Para diciembre de 2024, la última ronda de controles de la administración Biden entró en vigor, restringiendo estrictamente incluso la exportación de la H20.
Tres rondas de controles, cada vez más estrictas.
Pero esta vez, el desarrollo de la historia es completamente diferente al de ZTE.
Una ruptura asimétrica
Bajo la prohibición, todos pensaron que el sueño del gran modelo de IA china terminaría ahí.
Se equivocaron. Frente al bloqueo, las empresas chinas no optaron por un enfrentamiento directo, sino que comenzaron una ruptura. El primer campo de batalla de esta ruptura no estuvo en los chips, sino en los algoritmos.
A finales de 2024 y en 2025, las empresas chinas de IA se volcaron colectivamente en una dirección tecnológica: el modelo de expertos mixtos (Mixture of Experts, MoE).
En resumen, consiste en dividir un modelo enorme en muchos expertos pequeños, activando solo los más relevantes para una tarea, en lugar de poner en marcha todo el modelo.
El V3 de DeepSeek es un ejemplo típico de este enfoque. Tiene 671.000 millones de parámetros, pero en cada inferencia solo activa 37.000 millones de ellos, solo el 5,5% del total. En cuanto al coste de entrenamiento, utilizó 2048 GPU NVIDIA H800, entrenando durante 58 días, con un coste total de 5,576 millones de dólares. En comparación, las estimaciones externas del coste de entrenamiento de GPT-4 rondan los 78 millones de dólares. Una diferencia de un orden de magnitud.
La optimización extrema en el algoritmo se reflejó directamente en el precio. El precio de la API de DeepSeek es de solo 0,028 a 0,28 dólares por millón de tokens de entrada, y 0,42 dólares por la salida. Mientras que el precio de entrada de GPT-4o es de 5 dólares, y la salida de 15 dólares. Claude Opus es aún más caro, 15 dólares de entrada y 75 de salida. Calculado, DeepSeek es entre 25 y 75 veces más barato que Claude.
Esta diferencia de precio tuvo un gran impacto en el mercado global de desarrolladores. En febrero de 2026, en OpenRouter, la mayor plataforma de agregación de APIs de modelos de IA, el volumen semanal de llamadas a modelos chinos de IA se disparó un 127% en tres semanas, superando por primera vez a los estadounidenses. Hace un año, la cuota de los modelos chinos en OpenRouter era inferior al 2%. Un año después, creció un 421%, acercándose al 60%.
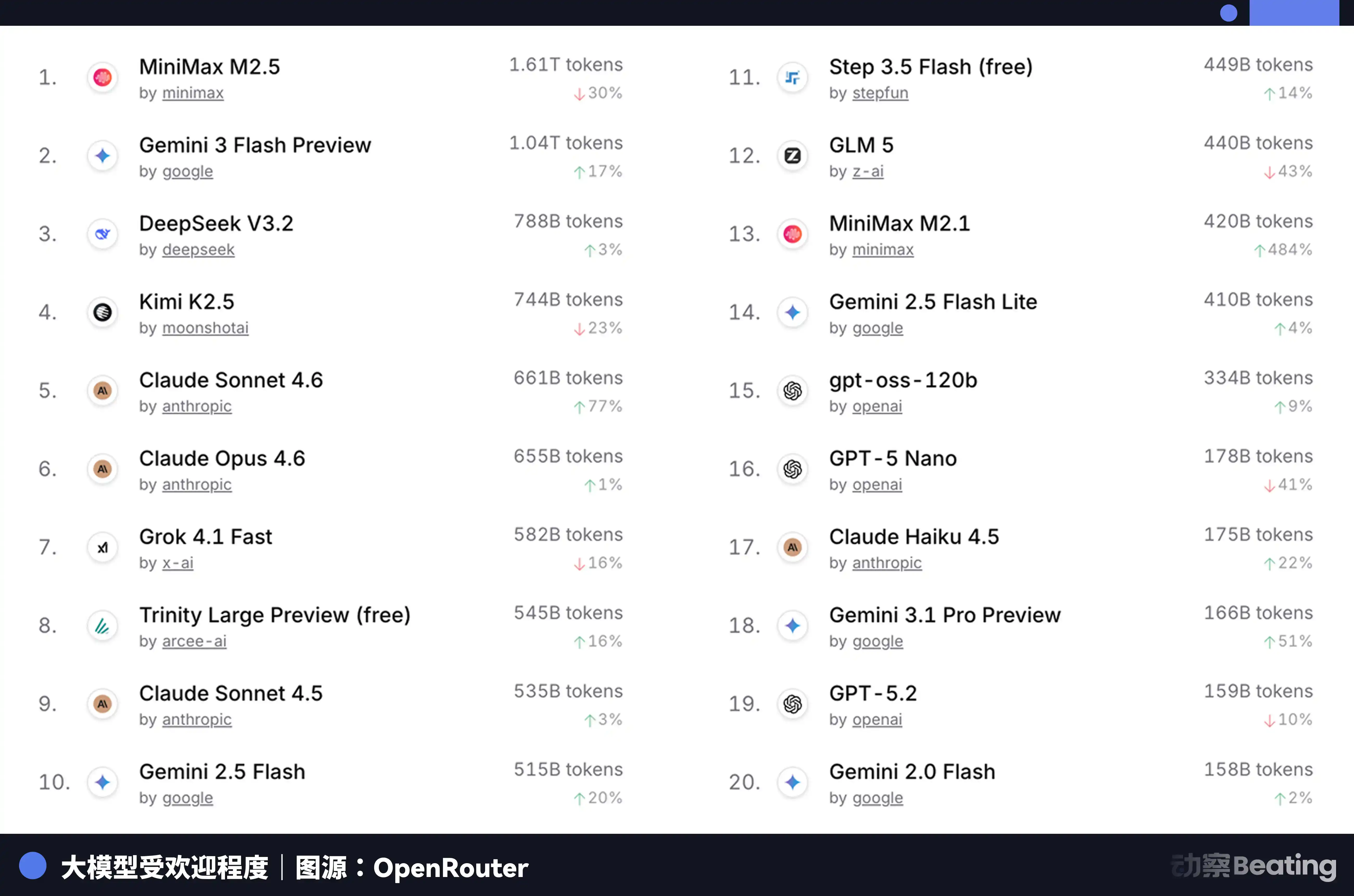
Detrás de estos datos, hay un cambio estructural que suele pasarse por alto. En la segunda mitad de 2025, el escenario principal de las aplicaciones de IA pasó del chat a los Agentes (Agent). En el escenario de Agentes, el consumo de tokens por tarea es de 10 a 100 veces mayor que en un chat simple. Cuando el consumo de tokens crece exponencialmente, el precio se convierte en el factor decisivo. La relación precio-rendimiento extrema de los modelos chinos coincidió precisamente con esta ventana.
Pero el problema es que la reducción del coste de inferencia no resuelve el problema fundamental del entrenamiento. Un modelo grande que no pueda seguir entrenado y actualizado continuamente con datos nuevos verá sus capacidades degradarse rápidamente. Y el entrenamiento sigue siendo ese agujero negro de potencia de cómputo inevitable.
Entonces, ¿de dónde vendrán las "palas" para el entrenamiento?
La normalización del plan B
Xinghua, Jiangsu, una pequeña ciudad del centro de Jiangsu, conocida por el acero inoxidable y los alimentos saludables, no tenía previously ninguna relación con la IA. Pero en 2025, se construyó y puso en marcha allí una línea de producción de servidores de computación nacional de 148 metros de largo, desde la firma del contrato hasta la producción, solo tardó 180 días.
El núcleo de esta línea de producción son dos chips completamente nacionales: el procesador Loongson 3C6000 y la tarjeta aceleradora de IA Taichu Yuanqi T100. El Loongson 3C6000, desde el conjunto de instrucciones hasta la microarquitectura, es totalmente de desarrollo propio. Taichu Yuanqi surgió del Centro Nacional de Supercomputación de Wuxi y del equipo de la Universidad de Tsinghua, adoptando una arquitectura heterogénea de múltiples núcleos.
Cuando esta línea funciona a plena capacidad, produce un servidor cada 5 minutos. La línea requirió una inversión total de 1100 millones de yuanes y se espera que produzca 100.000 unidades al año.
Lo más importante es que los clústeres de diez mil tarjetas basados en estos chips nacionales ya han comenzado a asumir tareas reales de entrenamiento de grandes modelos.
En enero de 2026, Zhipu AI, junto con Huawei, lanzó GLM-Image, el primer modelo de generación de imágenes SOTA entrenado completamente con chips nacionales. En febrero, el gran modelo "Xingchen" de miles de millones de parámetros de China Telecom completó su entrenamiento completo en el grupo de computación nacional de diez mil tarjetas de Lingang, Shanghai.

El significado de estos casos es que demuestran una cosa: los chips nacionales han pasado de "poder usarse para inferencia" a "poder usarse para entrenamiento". Esto es un cambio cualitativo. La inferencia solo necesita ejecutar modelos ya entrenados, los requisitos para los chips son relativamente bajos; mientras que el entrenamiento necesita procesar grandes volúmenes de datos, realizar complejos cálculos de gradiente y actualizaciones de parámetros, los requisitos de potencia de cálculo, ancho de banda de interconexión y ecosistema de software para los chips son un orden de magnitud mayor.
La fuerza central que asume estas tareas es la serie de chips Ascend de Huawei. Hasta finales de 2025, el ecosistema Ascend ya contaba con más de 4 millones de desarrolladores, más de 3000 socios, 43 de los principales modelos del sector completaron el preentrenamiento basado en Ascend, y más de 200 modelos open source se adaptaron. En el MWC del 2 de marzo de 2026, Huawei también lanzó por primera vez para el mercado exterior su nueva base de computación SuperPoD.
La potencia de cálculo FP16 del Ascend 910B ya es comparable a la NVIDIA A100. Aunque la brecha aún existe, ha pasado de ser inutilizable a utilizable, y de utilizable está camino de ser buena. La construcción del ecosistema no puede esperar a que los chips sean perfectos, debe desplegarse masivamente en una fase suficiente, utilizando demandas comerciales reales para impulsar la iteración de chips y software. Los objetivos de ByteDance, Tencent y Baidu para la introducción de servidores de computación nacionales generalmente se duplicaron en 2026 respecto al año anterior. Los datos del Ministerio de Industria y Tecnología de la Información muestran que la escala de la computación inteligente de China ha alcanzado los 1590 EFLOPS. 2026 se está convirtiendo en el año inaugural del despliegue a escala de la computación nacional.
Escasez eléctrica en EE.UU. y expansión global de China
A principios de 2026, el estado de Virginia, que alberga un gran tráfico de centros de datos globales, suspendió la aprobación de nuevos proyectos de centros de datos. Georgia hizo lo mismo, extendiendo la suspensión hasta 2027. Illinois y Michigan también promulgaron medidas restrictivas.
Según datos de la Agencia Internacional de la Energía, en 2024 el consumo eléctrico de los centros de datos de EE.UU. alcanzó los 183 TWh,约占全国总用电量的4% (alrededor del 4% del consumo total de electricidad del país). Para 2030, se espera que esta cifra se duplique a 426 TWh, y la proporción podría superar el 12%. El CEO de Arm predijo incluso que para 2030, los centros de datos de IA consumirán entre el 20% y el 25% de la electricidad de EE.UU.
La red eléctrica estadounidense ya está sobrecargada. La red PJM, que cubre 13 estados del este de EE.UU., enfrenta un déficit de capacidad de 6 GW. Para 2033, EE.UU. enfrentará un déficit general de capacidad eléctrica de 175 GW, equivalente al consumo de electricidad de 130 millones de hogares. El costo mayorista de la electricidad en las áreas concentradas de centros de datos es un 267% más alto que hace cinco años.
El final de la potencia de cómputo es la energía. Y en esta dimensión, la brecha entre China y EE.UU. es aún mayor que en los chips, solo que en la dirección opuesta.
La generación anual de electricidad de China es de 10,4 billones de kWh, la de EE.UU. es de 4,2 billones de kWh, China es 2,5 veces mayor que EE.UU. Más crucial aún, el consumo eléctrico residencial de China solo representa el 15% del consumo total, mientras que en EE.UU. esta proporción es del 36%. Esto significa que China tiene un margen de consumo eléctrico industrial mucho mayor que EE.UU. para invertir en la construcción de capacidad de cómputo.
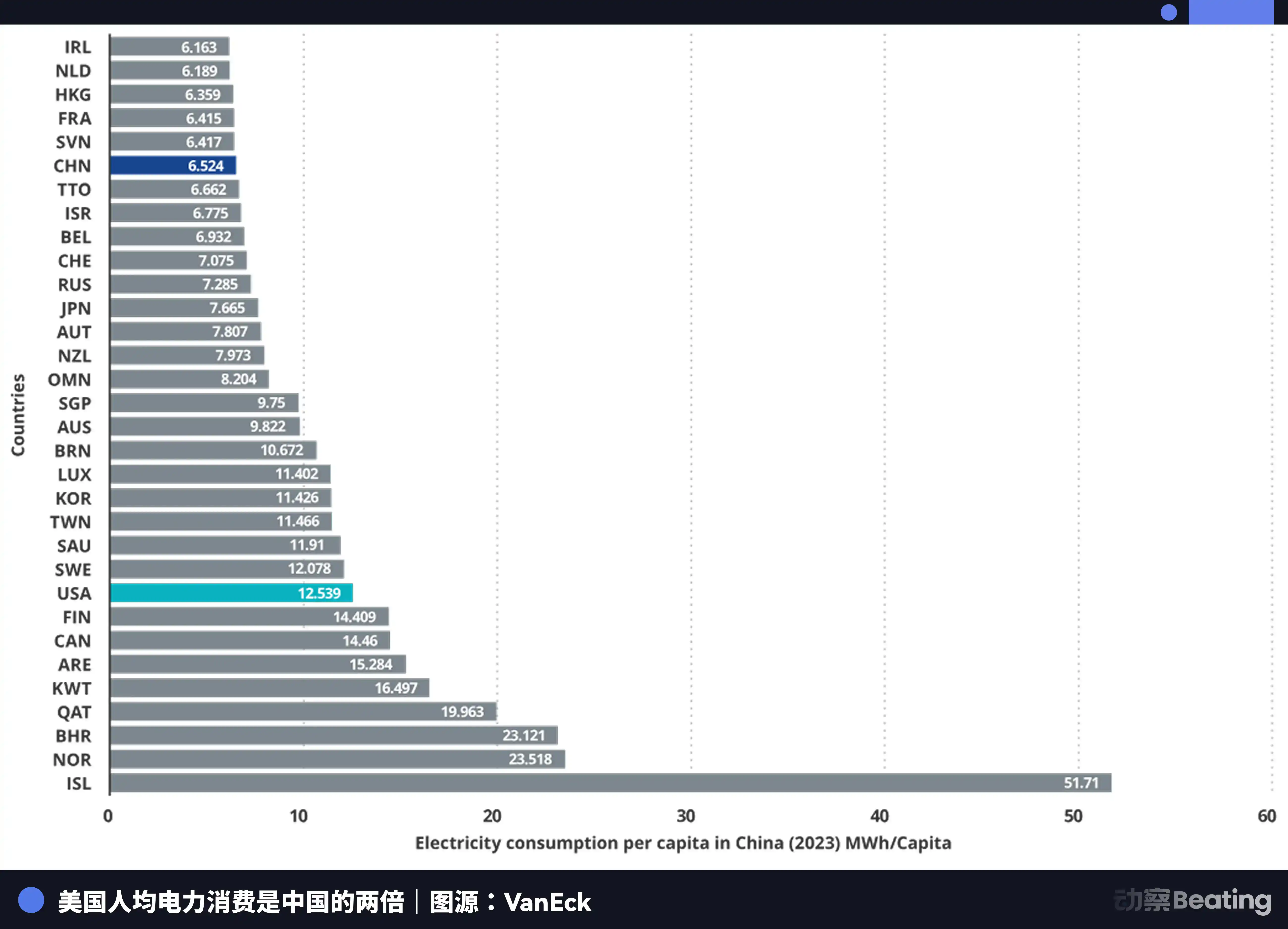
En cuanto al precio de la electricidad, en las áreas donde se agrupan las empresas de IA de EE.UU., el precio ronda entre 0,12 y 0,15 dólares por kWh, mientras que el precio industrial en el oeste de China es de aproximadamente 0,03 dólares, solo una cuarta o quinta parte del estadounidense.
El incremento en la generación de electricidad de China ya es 7 veces mayor que el de EE.UU.
Mientras EE.UU. se preocupa por la electricidad, la IA china se está expandiendo globalmente en silencio. Pero esta vez, lo que sale al exterior no son productos, ni fábricas, sino Tokens.
El Token, la unidad mínima de información procesada por los modelos de IA, se está convirtiendo en una nueva mercancía digital. Se produce en las fábricas de computación de China y se transmite a todo el mundo a través de cables submarinos.
Los datos de distribución de usuarios de DeepSeek son muy ilustrativos: China continental 30,7%, India 13,6%, Indonesia 6,9%, EE.UU. 4,3%, Francia 3,2%. Soporta 37 idiomas y es muy popular en mercados emergentes como Brasil. A nivel global, 26.000 empresas han abierto cuentas y 3200 instituciones han desplegado la versión empresarial.
En 2025, el 58% de las nuevas startups de IA incorporaron DeepSeek en su pila tecnológica. En China, DeepSeek obtuvo el 89% de la cuota de mercado. Y en otros países sancionados, la cuota de mercado oscila entre el 40% y el 60%.
Este panorama se parece mucho a otra guerra sobre la autonomía industrial hace cuarenta años.
En 1986 en Tokio, bajo una fuerte presión de EE.UU., el gobierno japonés firmó el Acuerdo Semiconductor EE.UU.-Japón. Las cláusulas centrales del acuerdo eran tres: exigir a Japón que abriera su mercado de semiconductores, la cuota de mercado de los chips estadounidenses en Japón debía alcanzar al menos el 20%; prohibir estrictamente la exportación de semiconductores japoneses a precios por debajo del coste; imponer un arancel punitivo del 100% sobre 300 millones de dólares en chips exportados por Japón. Simultáneamente, EE.UU. vetó la adquisición de Fairchild Semiconductor por parte de Fujitsu.
Ese año, la industria semiconductor japonesa estaba en su apogeo. En 1988, Japón controlaba el 51% del mercado global de semiconductores, EE.UU. solo el 36,8%. Entre las diez mayores empresas de semiconductores del mundo, Japón ocupaba seis puestos: NEC segundo, Toshiba tercero, Hitachi quinto, Fujitsu séptimo, Mitsubishi octavo, Panasonic noveno. En 1985, Intel, en la guerra semiconductor entre EE.UU. y Japón, perdió 173 millones de dólares, al borde de la quiebra.
Pero después de firmar el acuerdo, todo cambió.
EE.UU., mediante investigaciones bajo el artículo 301 y otros medios, lanzó una represión integral contra las empresas semiconductor japonesas. Simultáneamente, apoyó a Samsung y Hynix de Corea del Sur para impactar el mercado japonés con precios más bajos. La cuota de DRAM de Japón cayó del 80% al 10%. Para 2017, la cuota de mercado de IC de Japón era solo del 7%. Los otrora gigantes imbatibles fueron divididos, adquiridos o se retiraron en silencio en medio de pérdidas interminables.

La tragedia de los semiconductores japoneses radica en que se conformaron con ser el productor más excelente en un sistema de división global dominado por una única fuerza externa, pero nunca pensaron en construir un ecosistema independiente propio. Cuando retrocedió la marea, descubrieron que, aparte de la producción en sí, no tenían nada.
Hoy, la industria china de IA se encuentra en una encrucijada similar pero completamente diferente.
Lo similar es que同样 enfrentamos una enorme presión externa. Tres rondas de control de chips, restricciones cada vez mayores, la barrera del ecosistema CUDA sigue siendo alta.
Lo diferente es que esta vez, hemos elegido un camino más difícil. Desde la optimización extrema a nivel de algoritmo, hasta el salto de los chips nacionales de la inferencia al entrenamiento, pasando por la acumulación de 4 millones de desarrolladores en el ecosistema Ascend, y la penetración en el mercado global mediante la exportación de Tokens. Cada paso en este camino está construyendo un ecosistema industrial independiente que Japón nunca tuvo.
Epílogo
El 27 de febrero de 2026, se publicaron en el mismo día tres informes de resultados preliminares de empresas locales de chips de IA.
Cambricon, ingresos disparados un 453%, logrando por primera vez beneficios anuales. Moore Threads, ingresos crecieron un 243%, pero con una pérdida neta de 1000 millones de yuanes. MetaX, ingresos crecieron un 121%, con una pérdida neta de casi 800 millones de yuanes.
Mitad fuego, mitad agua.
Fuego, es la extrema sed del mercado. El 95% del vacío dejado por Jensen Huang está siendo llenado, centímetro a centímetro, por las cifras de ingresos de estas empresas locales. Sin importar el rendimiento, sin importar el ecosistema, el mercado necesita una segunda opción además de NVIDIA. Esta es una oportunidad estructural única, abierta por la geopolítica.
Agua, es el enorme coste de construir el ecosistema. Cada pérdida es dinero real pagado para ponerse al día con el ecosistema CUDA. Es inversión en I+D, son subsidios de software, es el coste de personal de los ingenieros enviados al sitio del cliente para resolver, uno por uno, los problemas de compilación. Estas pérdidas no son una mala gestión, sino el impuesto de guerra que debe pagar necesariamente para construir un ecosistema independiente.
Estos tres informes financieros registran la verdadera cara de esta guerra de computación con más honestidad que cualquier informe sectorial. No es una victoria de avance triunfal, sino una batalla de posiciones feroz, cargando mientras se sangra.
Pero la forma de la guerra realmente ha cambiado. Hace ocho años, discutíamos el problema de "si podríamos sobrevivir". Hoy, discutimos el problema de "qué precio pagaremos por sobrevivir".
El precio en sí, es progreso.







