TL;DR
Un gráfico que desglosa los aproximadamente 20 dólares mensuales de la suscripción Claude Pro en Estados Unidos para la empresa del modelo, la potencia de cómputo en la nube, la depreciación de las GPU, la electricidad y la cadena de suministro, está haciendo que los inversores vuelvan a debatir cómo valorar realmente los ingresos de las aplicaciones de IA.
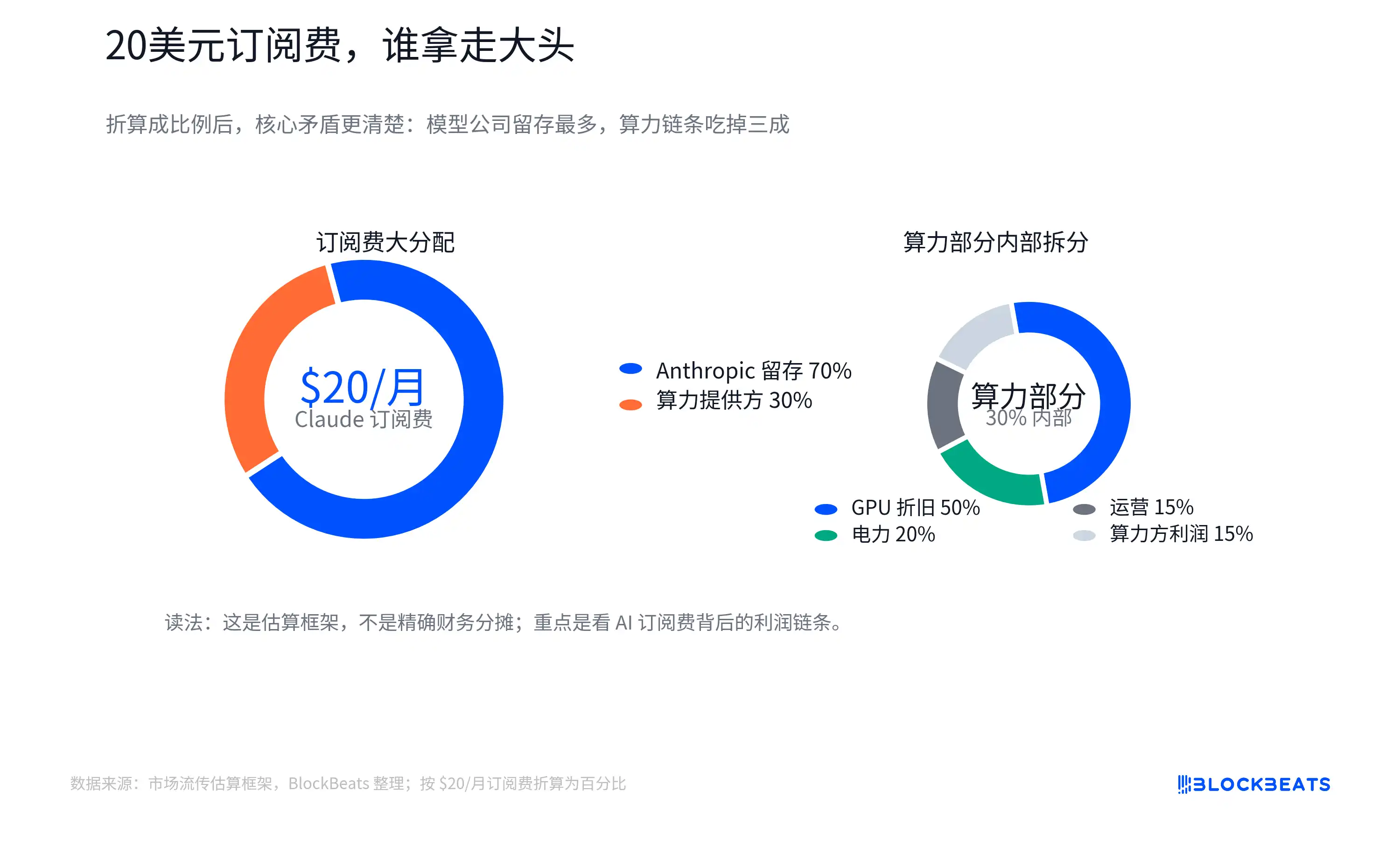
Este gráfico no representa datos oficiales de distribución de ingresos de Anthropic, AWS o Nvidia, ni debe tomarse como un libro contable real de ninguna empresa. Su valor radica en plantear una pregunta más fundamental: ¿cuánto de la suscripción que pagan los usuarios por las aplicaciones de IA puede capitalizarse como margen bruto de software, tal y como ocurre en el SaaS tradicional?
La narrativa de valoración del SaaS tradicional es clara. Una vez desarrollado el software, el coste marginal de vender una licencia adicional suele ser bajo, y las empresas de software maduras suelen tener márgenes brutos superiores al 70% o incluso al 80%. Los inversores están dispuestos a asignar múltiplos elevados porque a medida que crecen los ingresos, la rentabilidad tiene margen para mejorar.
El problema de las aplicaciones de IA es que cada consulta, generación de código, análisis de archivo o llamada a un agente por parte del usuario consume en el fondo tiempo de GPU, electricidad, ancho de banda de memoria y recursos en la nube. En la superficie hay una cuota mensual fija, pero en el núcleo hay una cadena de costes variable según el uso. Los usuarios ligeros pueden ser muy rentables, pero para los usuarios intensivos que ejecutan tareas continuas dentro de sus límites de uso o paquetes de herramientas, los costes pueden aumentar rápidamente.
Por lo tanto, lo que el gráfico de desglose de los 20 dólares cuestiona no es cuántos dólares se lleva exactamente cada empresa, sino si "los ingresos por aplicaciones de IA son intrínsecamente equivalentes a los ingresos por SaaS". Para demostrar que merecen múltiplos elevados, las empresas de IA no solo tienen que demostrar que los usuarios están dispuestos a pagar, sino también que el margen bruto ponderado por el volumen de uso puede mejorar de forma sostenible.
Tras la tarifa de suscripción hay una cadena de costes de inferencia
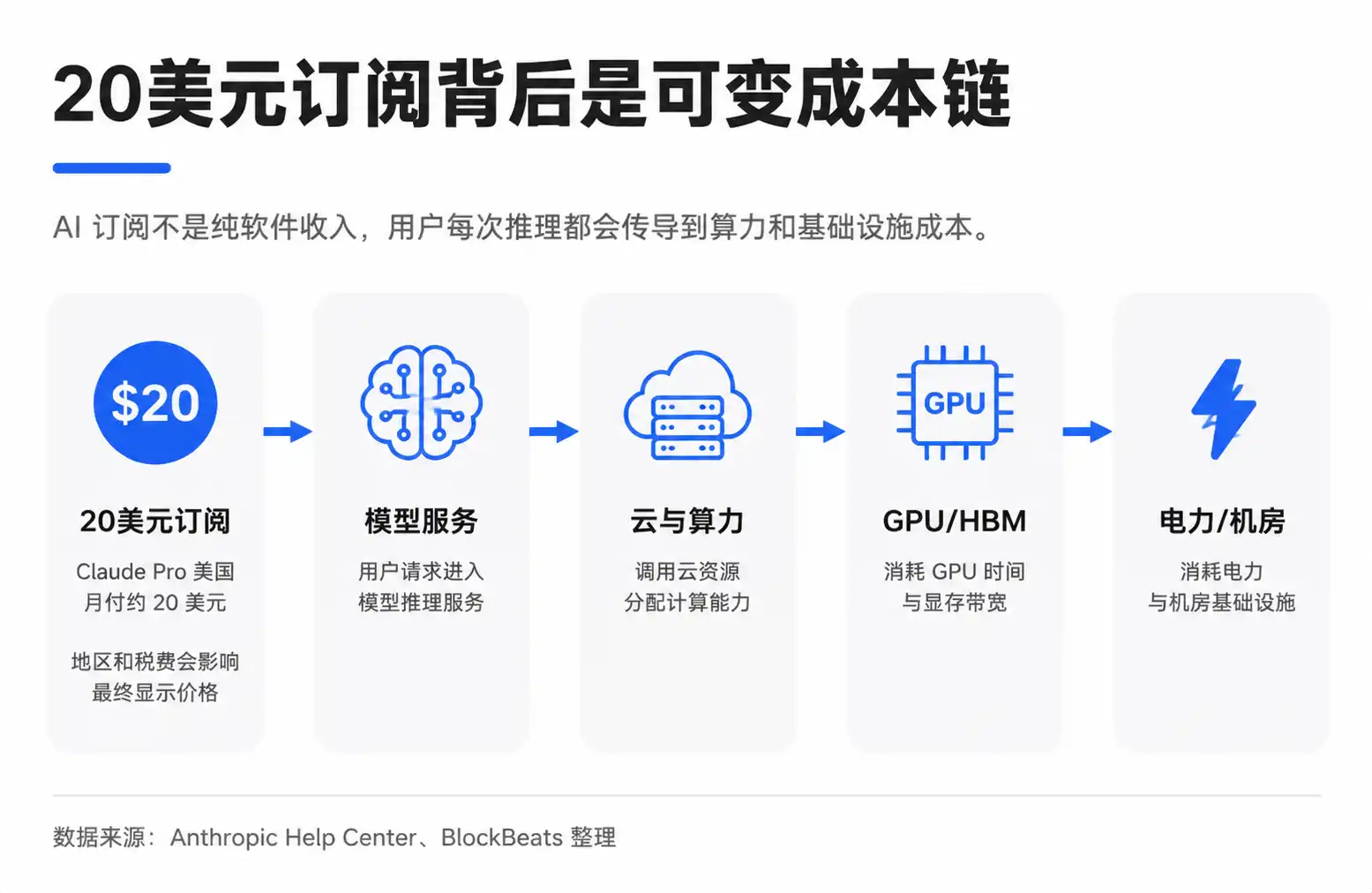
La mayor diferencia entre una suscripción a IA y una suscripción de software normal es que el coste marginal de "usarla una vez" ya no es cercano a cero.
En el SaaS tradicional, cuando un equipo añade una licencia, el proveedor también incurre en costes de servidores, atención al cliente y ancho de banda, pero estos costes no suelen aumentar linealmente con cada clic. Lo realmente caro son el desarrollo previo, las ventas y la adquisición de clientes. Una vez que el producto se escala, una parte considerable de los nuevos ingresos puede retenerse.
Los productos de modelos grandes son diferentes. El usuario introduce una consulta y el modelo genera una respuesta. Este proceso se llama inferencia, es decir, el cálculo real cuando el usuario llama al modelo. El token es la unidad básica para medir el texto que lee y escribe el modelo. Cuanto más pregunte el usuario, más largo sea el contexto y más compleja sea la generación de contenido, más tokens y potencia de cálculo se consumirán.
Esto crea una contradicción entre la suscripción fija y los costes variables. La tarifa mensual de Claude Pro en Estados Unidos ronda los 20 dólares, pero el precio puede verse afectado por la región, los impuestos y los ajustes de Anthropic. Lo que el usuario ve es un precio fijo, pero la empresa del modelo se enfrenta a patrones de uso muy diferentes. Algunos solo redactan correos y buscan información, otros procesan documentos largos, ejecutan tareas de codificación o utilizan flujos de automatización más complejos.
El gráfico de desglose que circula en el mercado intenta concretar esto: de los 20 dólares, una parte se queda en la empresa del modelo, otra paga a los proveedores de nube y cómputo. El coste del cómputo incluye electricidad, operaciones, depreciación de las GPU. La compra de GPU fluye a su vez hacia Nvidia, TSMC, proveedores de HBM (memoria de gran ancho de banda), módulos ópticos, ODM y empresas relacionadas con la electricidad.
Aquí, la "depreciación de las GPU" puede entenderse como que las costosas GPU no amortizan su coste de una vez, sino que se distribuyen gradualmente en el servicio de IA según su vida útil, intensidad de uso o criterios contables. La distribución real se verá afectada por los límites del plan, la proporción de usuarios ligeros e intensivos, los precios de liquidación interna del proveedor en la nube, los descuentos por capacidad reservada, la utilización de las GPU y la vida útil de la depreciación. El coste medio tampoco es igual al coste marginal.
Lo que realmente deben vigilar los inversores es la tendencia: las empresas de aplicaciones de IA no pueden limitarse a informar del crecimiento de los ingresos, también deben responder si los costes de cómputo subyacentes crecen al mismo ritmo. Si el volumen de uso se expande más rápido que la mejora de la eficiencia del modelo, cuanto mayores sean los ingresos por suscripción, mayor puede ser la presión sobre el margen bruto. Solo si la mejora de la eficiencia es lo suficientemente rápida, las empresas de modelos tendrán la oportunidad de volver a acercarse a la estructura de beneficios de una empresa de software.
La infraestructura obtiene primero unos ingresos más seguros
En la fase actual, el crecimiento del uso de IA fluye más directamente hacia la infraestructura, sin capitalizarse completamente en la capa de aplicación.
Independientemente de que el usuario utilice el modelo en Claude, ChatGPT, Gemini o en agentes internos de la empresa, la inferencia acaba recayendo en la potencia de cómputo, la electricidad, la memoria y la red. En la capa de aplicación puede haber rotación de productos, pero el consumo de recursos subyacentes es más rígido. Mientras el uso de la IA siga aumentando, se impulsarán los gastos de capital en la nube, la compra de GPU, la demanda de HBM y el consumo eléctrico de los centros de datos.
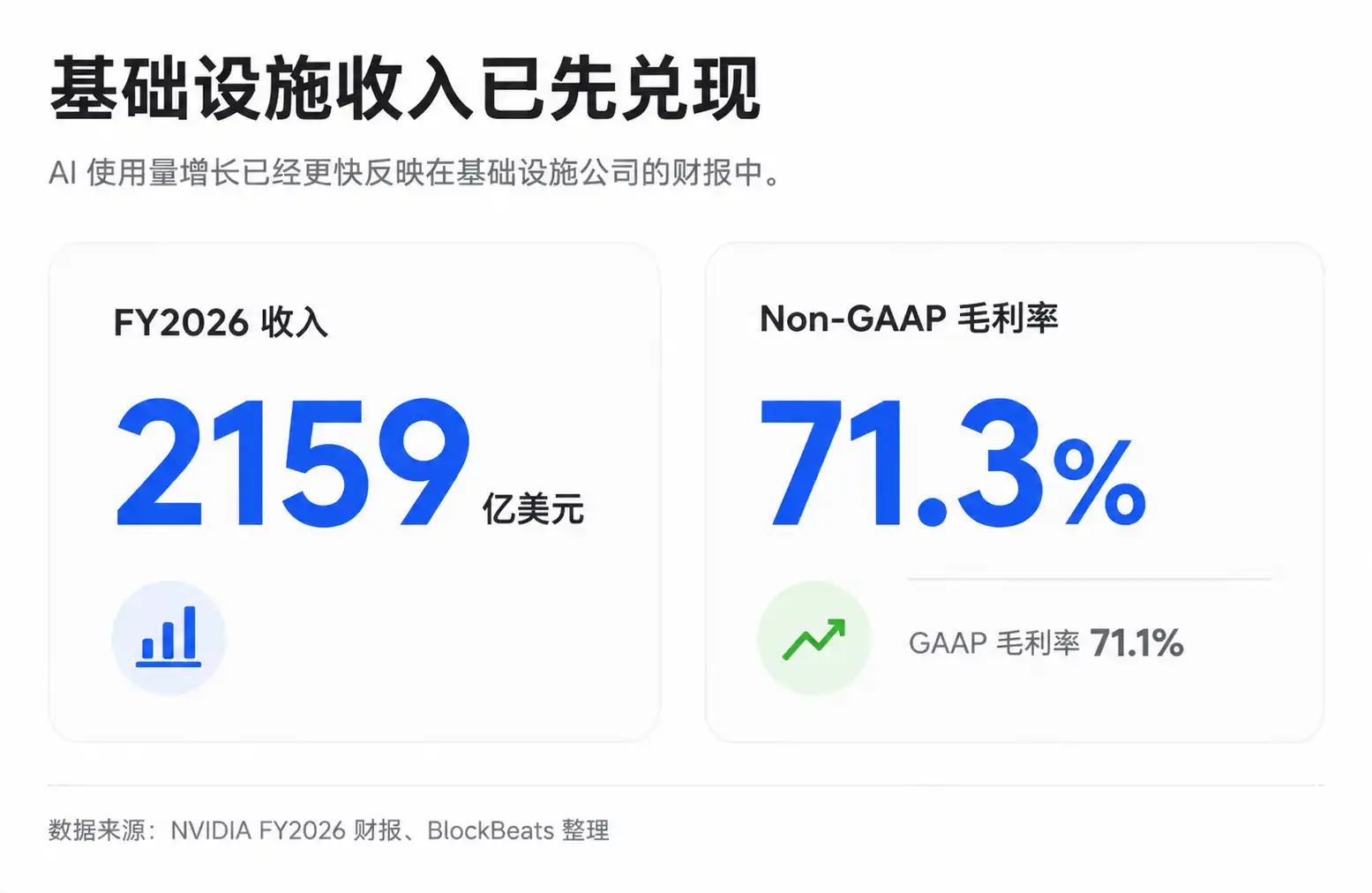
Esta es también la razón por la que la cadena de infraestructura, incluidas empresas como Nvidia, TSMC y SK Hynix, sigue siendo revalorizada por el mercado. El margen bruto global de Nvidia se ha mantenido en niveles altos en los últimos años, siendo el margen bruto GAAP y no GAAP para el año fiscal 2026 aproximadamente del 71,1% y 71,3%, respectivamente, y las orientaciones para los trimestres siguientes también se mantienen altas. Cabe señalar que algunos trimestres pueden verse afectados por partidas específicas, y los informes públicos no siempre permiten desglosar directamente la verdadera estructura del margen bruto de los centros de datos de IA, pero el poder de fijación de precios de la infraestructura escasa ya se refleja en los resultados.
El HBM es un eslabón típico en esta cadena. No es una memoria normal, sino un componente clave en los aceleradores de IA que soporta el cálculo de alto rendimiento. A medida que aumentan el tamaño de los modelos, la longitud del contexto y la demanda de inferencia concurrente, los chips de IA dependen más de la memoria de gran ancho de banda. Las estimaciones de la cadena de suministro muestran que la proporción de HBM en el coste de los chips de IA de nueva generación está aumentando, y esta es también una razón importante por la que SK Hynix, Samsung y Micron han sido reevaluadas en el ciclo de la IA.
La electricidad y los centros de datos también han pasado de ser un coste de fondo a una línea de inversión principal. El consumo energético de una consulta de texto normal individual puede no ser excesivo, pero los agentes complejos, los contextos largos, la generación de código y las tareas de múltiples pasos amplifican el volumen de cálculo. Para los proveedores en la nube y los operadores de centros de datos, la clave no es cuánta energía consume una consulta concreta, sino que cuando se producen de forma continua solicitudes de inferencia masivas, la utilización del clúster, el precio de la electricidad, la refrigeración, la capacidad del centro de datos y el acceso a la red eléctrica se convierten en costes y cuellos de botella.
La ventaja del lado de la infraestructura es que la validación de los resultados es más rápida. Los gastos de capital en IA de los proveedores en la nube ya se han materializado, los ingresos y márgenes de Nvidia se reflejan en sus informes, y los pedidos y precios de los fabricantes de HBM también entrarán relativamente pronto en la cuenta de resultados. En la capa de aplicación de modelos, lo que se negocia principalmente son expectativas futuras: la conversión en suscripciones, la tasa de penetración empresarial, los ingresos por API y la liberación de beneficios una vez que la curva de costes futuros descienda.
La mejora de la eficiencia sigue siendo el argumento central de los alcistas
Los inversores en software y los alcistas en IA no carecen de argumentos en contra. El argumento central de la facción de la eficiencia es que el alto coste actual de la inferencia es solo un fenómeno de la fase inicial, y que la optimización de modelos, el almacenamiento en caché, los modelos pequeños, los chips propios y una mayor utilización de los clústeres reducirán continuamente el coste unitario. Si el coste desciende lo suficientemente rápido, las aplicaciones de IA aún podrían volver a la lógica de software de alto margen.
Este contraargumento tiene una base real. Algunos modelos principales ya han reducido significativamente su precio unitario manteniendo o mejorando sus capacidades. OpenAI ha revelado que el coste por token de GPT-4o mini se ha reducido un 99% en comparación con el antiguo text-davinci-003. El ritmo no es exactamente el mismo en todas las empresas; Anthropic se ha centrado recientemente más en las actualizaciones al mismo precio y en la estratificación de modelos, pero la dirección de la industria sigue siendo ofrecer una mayor capacidad a un coste menor.

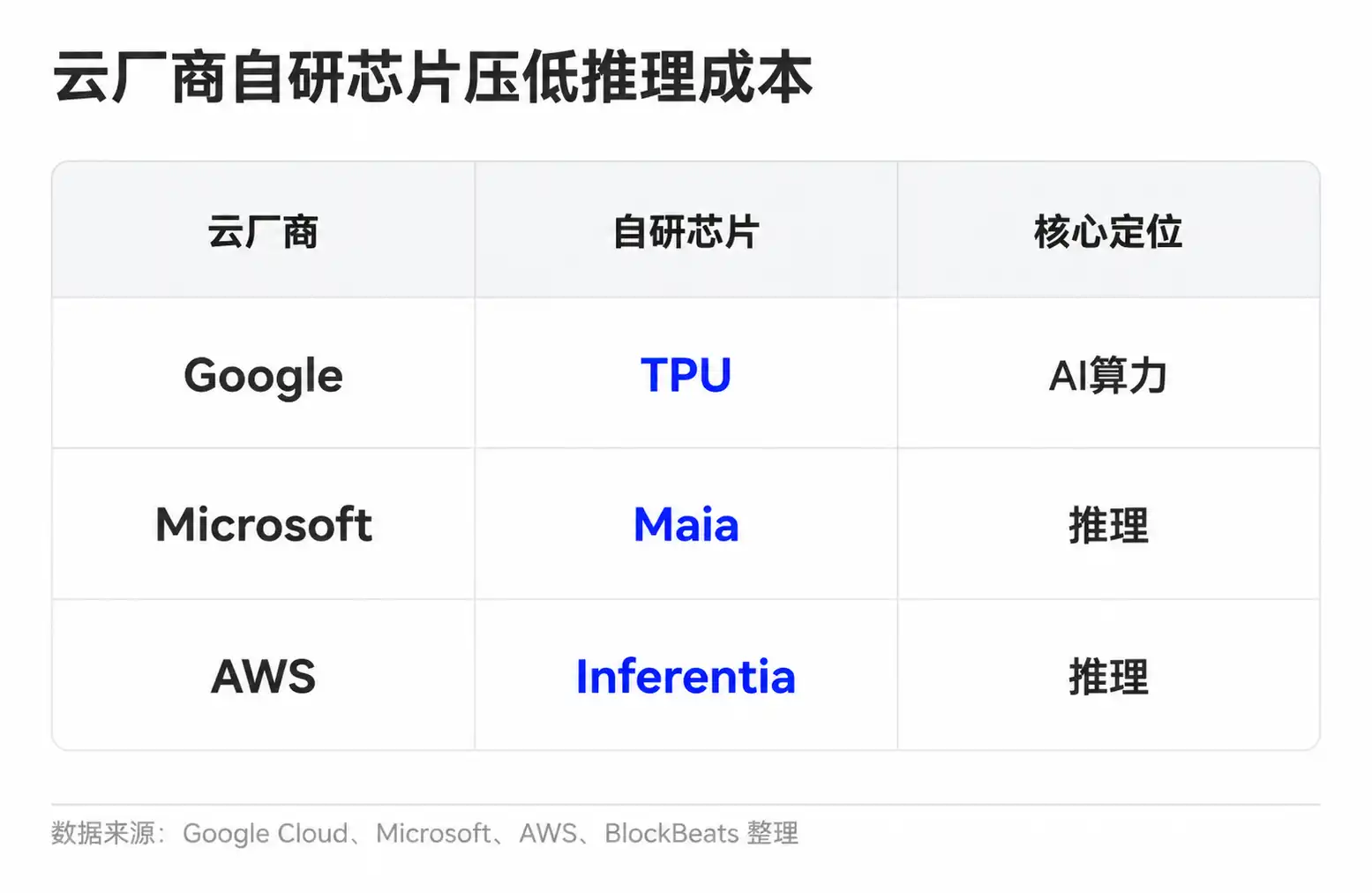
Las empresas de modelos también tienen múltiples métodos para mejorar su economía unitaria. Las tareas sencillas se delegan a modelos pequeños, las consultas comunes se reutilizan mediante caché, y los contextos largos y las tareas complejas se delegan a modelos más potentes. Los proveedores en la nube, por su parte, reducen el coste unitario del cómputo mediante el desarrollo de chips propios y la planificación de clústeres. Google tiene los TPU, Microsoft ha lanzado Maia para inferencia, y Amazon también está avanzando con Trainium e Inferentia.
Si solo nos fijamos en el progreso tecnológico, el margen de beneficio de las aplicaciones de IA tiene realmente margen de mejora. Una inferencia más barata, un mejor enrutamiento de modelos y una mayor capacidad de compresión pueden hacer que la misma suscripción de 20 dólares soporte un mayor volumen de uso. Los usuarios ligeros, los planes empresariales de alto precio, la fijación de precios por capas de la API y límites de uso más estrictos también pueden mejorar la economía unitaria general.
La dificultad radica en que la reducción de costes no es la única variable. Las aplicaciones de IA están pasando del simple chat a cargas de trabajo más intensivas. Antes, los usuarios solo podían hacer preguntas y reformular textos, pero ahora cada vez hay más demanda de agentes de código, procesamiento de documentos largos, generación de vídeo y multimodal, y flujos de automatización empresarial. Estos escenarios tienen un valor mayor, pero también un consumo mayor. Cuanto más útil sea el modelo, más probable será que los usuarios le deleguen tareas más complejas y de mayor duración.
Así, el desacuerdo se vuelve más concreto: si la velocidad de descenso del coste de inferencia puede superar el crecimiento del volumen de uso y la complejidad de las tareas. Si el coste unitario desciende rápidamente, pero el consumo medio de los usuarios crece aún más rápido, el margen bruto ponderado de la empresa del modelo seguirá bajo presión. Por el contrario, si el enrutamiento de modelos, el almacenamiento en caché, los chips propios y la estratificación de precios son lo suficientemente eficaces, las suscripciones a IA podrían desprenderse gradualmente de su característica actual de alto coste.
El número de suscriptores no es igual al margen bruto
El gráfico de desglose de los 20 dólares no debe interpretarse como un resultado final. Es más bien un recordatorio de valoración en la fase actual: mientras el mercado no disponga de datos suficientemente transparentes sobre los márgenes brutos de las empresas de modelos, los inversores necesitan descontar la hipótesis de que "las aplicaciones de IA son intrínsecamente iguales al SaaS".
Para las empresas de modelos no cotizadas, como OpenAI y Anthropic, es difícil para los inversores externos ver sus libros de cuentas completos. Los materiales de financiación, las divulgaciones de los socios, la estructura de costes en la nube, los precios de los planes empresariales, la proporción de ingresos por API y las limitaciones de uso se convertirán en pistas para juzgar. Los datos realmente valiosos no son cuántos usuarios pagan, sino qué proporción son usuarios ligeros e intensivos, si los clientes empresariales están dispuestos a pagar precios más altos por un uso intensivo, si los costes de liquidación en la nube están disminuyendo y si la reducción del coste unitario de inferencia se está trasladando al margen bruto de la empresa.
La validación en la cadena de empresas cotizadas aparecerá más rápidamente en los informes de resultados. El margen bruto global de Nvidia y la tasa de crecimiento de los ingresos de su centro de datos, la demanda de procesos avanzados y ensamblaje de TSMC, los precios y márgenes de los fabricantes de HBM y la intensidad de los gastos de capital de los proveedores en la nube seguirán reflejando si el uso de la IA sigue trasladándose al lado de la infraestructura. Si estos indicadores se mantienen sólidos, mientras que la capa de aplicación de modelos carece de pruebas de mejora del margen bruto, el mercado seguirá dando a la infraestructura una prima de valoración más segura.
En última instancia, para que las empresas de modelos recuperen un ancla de valoración más alta, lo que tienen que demostrar no es solo que los usuarios están dispuestos a pagar 20 dólares, sino que, incluso después de un uso intensivo, estas tarifas de suscripción pueden dejar suficiente margen bruto. La próxima ronda de divergencia en la valoración probablemente no esté en las cifras destacadas de los ingresos recurrentes anuales (ARR), sino en si los costes de inferencia, las limitaciones de los planes y los precios de pago empresarial pueden funcionar simultáneamente.





