Acaba de llegar: Anthropic ha lanzado oficialmente su nuevo modelo Claude Sonnet 5, al que describe como «el modelo Sonnet más orientado a Agentes hasta la fecha», capaz de formular planes, utilizar herramientas como navegadores, terminales, y operar de forma autónoma a un nivel que hace unos meses requería modelos más grandes y costosos.
Sonnet 5 muestra una mejora significativa en razonamiento, uso de herramientas, programación y trabajo con conocimiento en comparación con Sonnet 4.6, acercándose más al rendimiento de Opus 4.8, pero a un precio inferior.
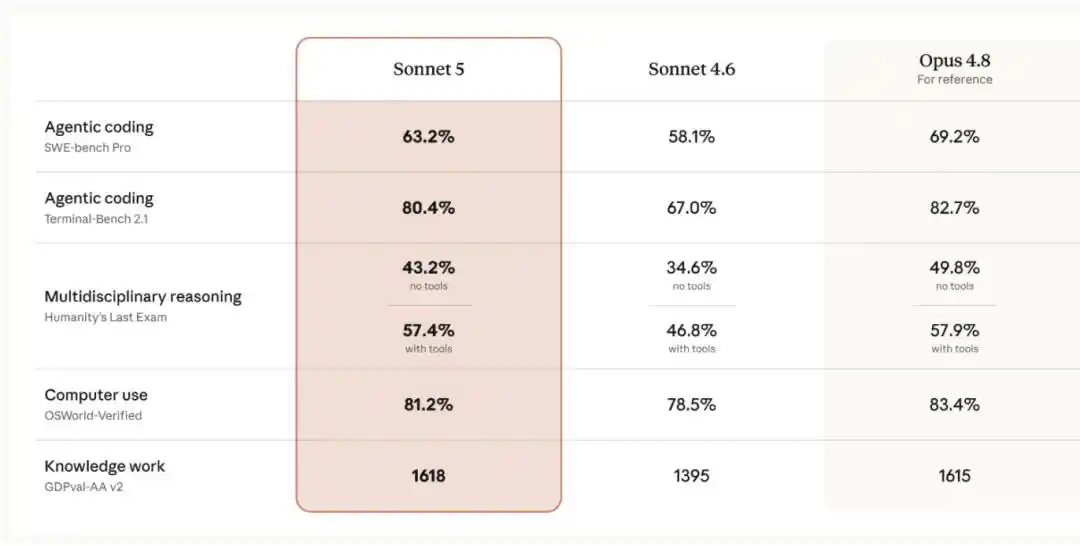
La empresa afirma que, para los desarrolladores, la era de los Agentes de IA realmente comenzó con los modelos de la clase Sonnet: Claude Sonnet 3.5, 3.6 y 3.7 fueron los primeros en mostrar capacidades destacadas en programación y uso de herramientas. Sin embargo, últimamente, las mejoras más notables en capacidades de agente se han visto principalmente en los modelos de la clase Opus.
Claude Sonnet 5 cierra notablemente esta brecha: su rendimiento ya se acerca al de Opus 4.8, pero a un precio más bajo. En comparación con su predecesor Sonnet 4.6, muestra mejoras significativas en dimensiones clave para el rendimiento de agentes como el razonamiento, el uso de herramientas, la programación y el trabajo con conocimiento. La comparación específica se muestra en la siguiente imagen:
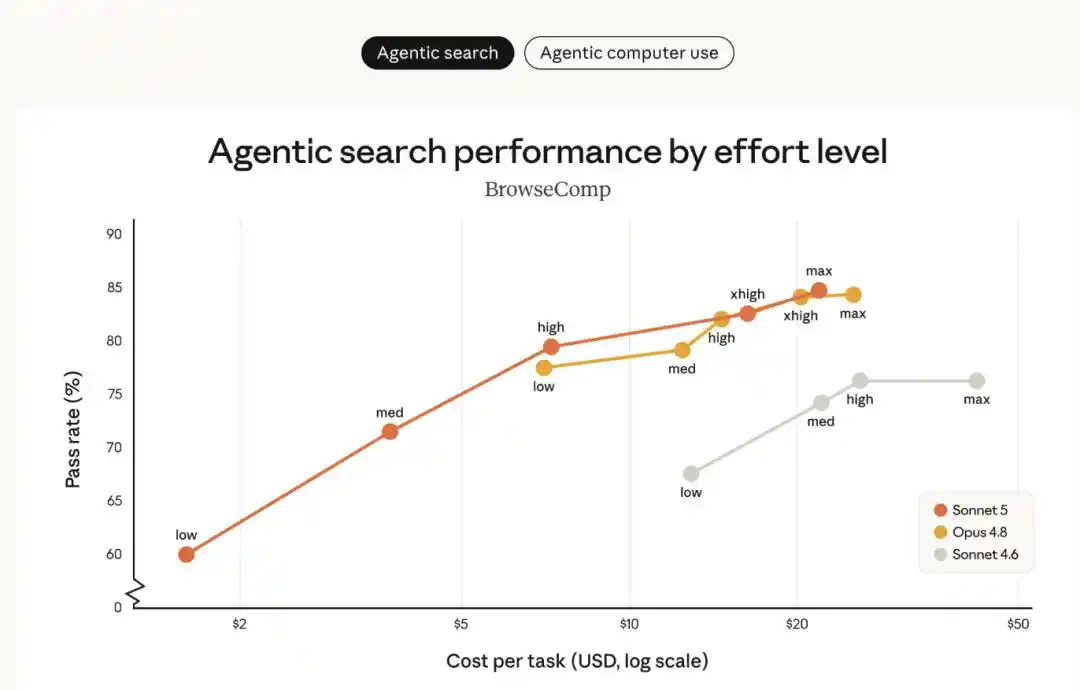
La siguiente imagen compara el rendimiento de Sonnet 5 frente a Sonnet 4.6 y Opus 4.8 en la evaluación de búsqueda para agentes BrowseComp y la evaluación de uso de computadora OSWorld‐Verified, bajo diferentes niveles de «esfuerzo»:
- Sonnet 5 (línea naranja) muestra una clara mejora de rendimiento respecto a Sonnet 4.6 (línea gris), y abarca un rango más amplio de opciones costo-rendimiento que Opus 4.8 (línea amarilla).
- Con un nivel de esfuerzo medio, Sonnet 5 mejora significativamente la eficiencia en costos; con niveles de esfuerzo más altos, su rendimiento en ciertas tareas puede equipararse al de Opus 4.8.
- Entre Sonnet 5 y Opus 4.8, los usuarios pueden ajustar flexiblemente el nivel de esfuerzo según la tarea concreta para encontrar el mejor equilibrio entre costo y rendimiento para sus necesidades.
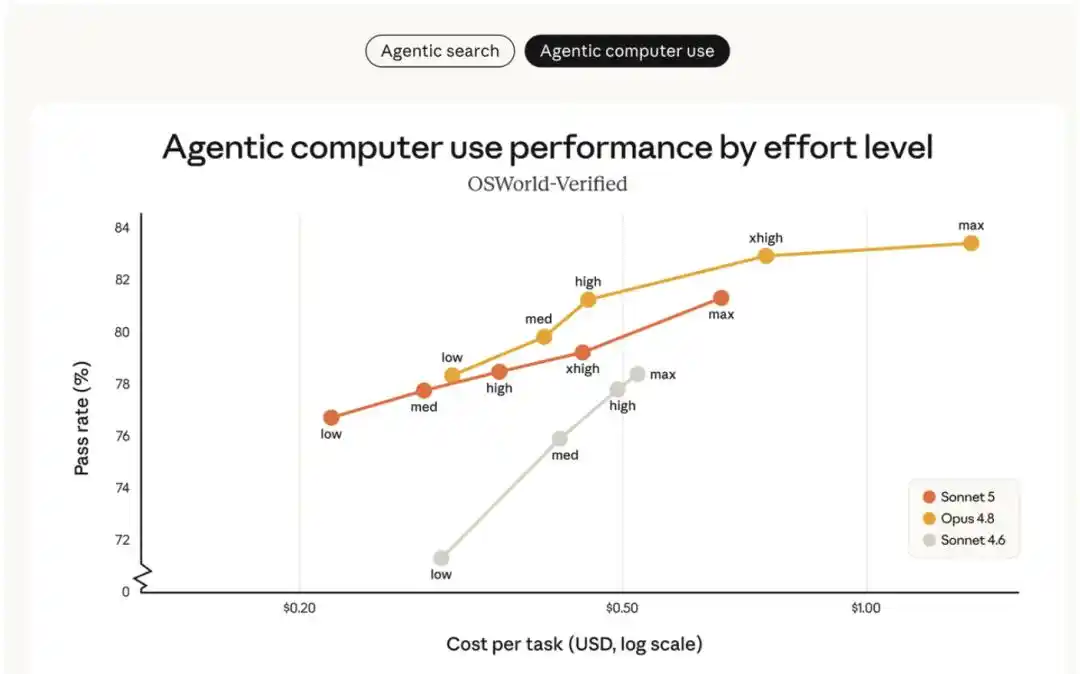
La curva costo-rendimiento bajo diferentes niveles de esfuerzo se muestra en la gráfica anterior. El mejor modelo Sonnet anterior (Sonnet 4.6) estaba muy por debajo de Opus 4.8. Sonnet 5 ofrece un abanico más amplio de opciones costo-rendimiento que Sonnet 4.6, pudiendo alcanzar en algunos casos el nivel de capacidad de Opus 4.8. El precio de Sonnet 5 mostrado en el gráfico es de $3 / millón de tokens para entrada y $15 / millón de tokens para salida. Con el precio promocional hasta el 31 de agosto (entrada $2 / millón de tokens, salida $10 / millón de tokens), el costo real de Sonnet 5 es incluso menor que el mostrado en la gráfica. El precio de Opus 4.8 es de $5 / millón de tokens para entrada y $25 / millón de tokens para salida.
Los comentarios de los socios de acceso temprano de Anthropic han sido consistentes: Sonnet 5 es más capaz como agente autónomo (agentic) que sus modelos predecesores. Los evaluadores describen que puede completar tareas complejas —en las que los modelos Sonnet anteriores se detenían a medio camino—; verifica activamente sus propias salidas sin necesidad de instrucciones explícitas; y realiza todo este trabajo de agente a un precio muy atractivo:
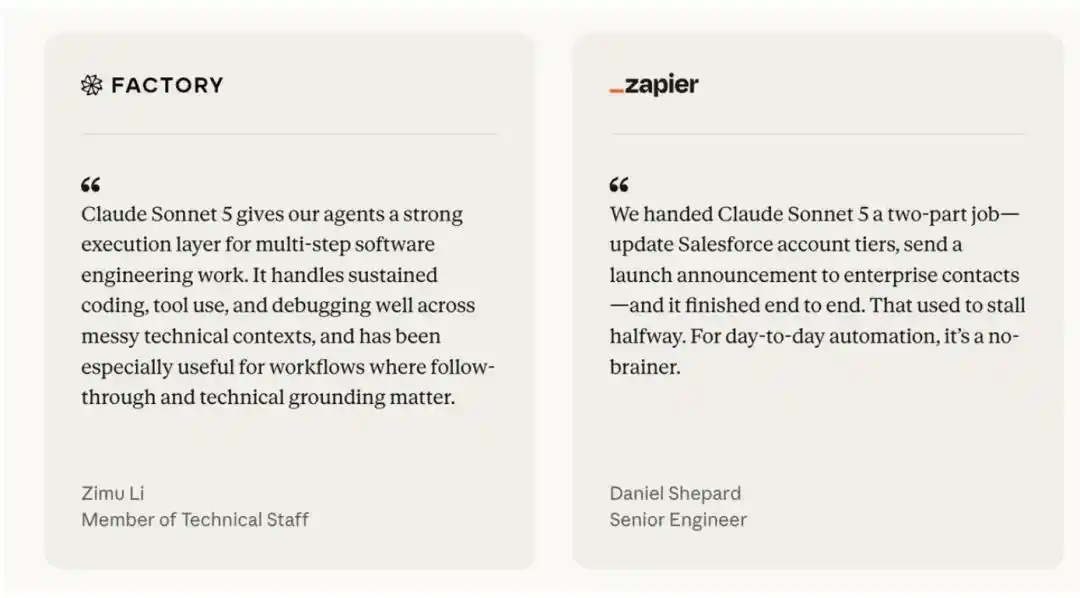
Evaluación de seguridad
La evaluación de seguridad previa al despliegue de Anthropic encontró que Sonnet 5 muestra mejoras generales en comparación con Sonnet 4.6. En cuanto a la seguridad del agente autónomo, el modelo se desempeña mejor rechazando solicitudes maliciosas y resistiendo intentos de secuestro en ataques de inyección de prompts (prompt injection). Las tasas de alucinación y de comportamiento adulador del modelo son inferiores a las de Sonnet 4.6. En la auditoría automatizada de comportamiento (que prueba una amplia gama de comportamientos inadecuados, como facilitar abusos o engaños), Sonnet 5 obtuvo una puntuación más baja (es decir, es más seguro).
Sin embargo, en comparación con los modelos más capaces Opus 4.8 y Claude Mythos Preview, sí muestra una tasa ligeramente superior de comportamientos inadecuados en esta evaluación.
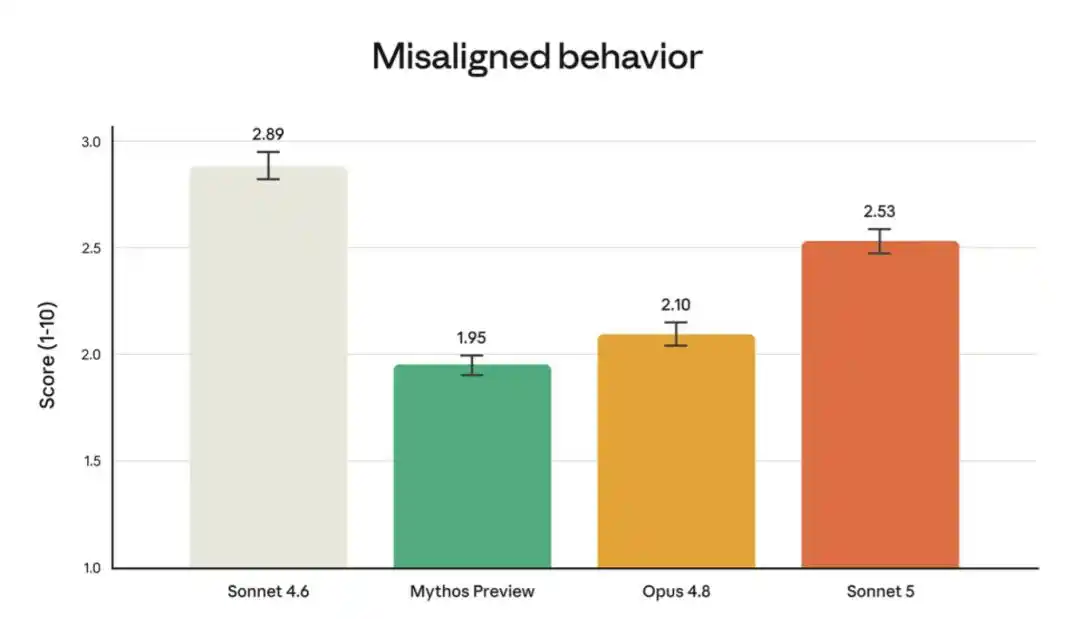
La gráfica anterior muestra la tasa de comportamientos inadecuados en la auditoría automatizada de comportamiento, que evalúa una gran cantidad de conductas problemáticas en diversos contextos y situaciones (para la lista completa y los resultados por comportamiento, ver la sección 6.4 de la ficha técnica del sistema de Sonnet 5). La tasa de comportamientos inadecuados de Sonnet 5 es en general inferior a la de Sonnet 4.6, pero superior a la de Mythos Preview y Opus 4.8.
Anthropic señala que no entrenaron específicamente a Sonnet 5 para tareas de ciberseguridad. Puede realizar algunas tareas de red rutinarias e inofensivas, pero en evaluaciones de habilidades de red potencialmente peligrosas (como desarrollar exploits para vulnerabilidades de software), su rendimiento es significativamente inferior al de modelos como Opus 4.8 y Mythos 5.
La siguiente imagen muestra las puntuaciones de una de estas evaluaciones, que prueba la capacidad del modelo para desarrollar exploits dirigidos a vulnerabilidades del navegador Firefox. Sonnet 5 no logró desarrollar un exploit completamente funcional en ningún caso, pero su tasa de éxito parcial fue ligeramente superior a la de Sonnet 4.6. Esta mejora en este último probablemente se deba a una mejora en la inteligencia general, no a un entrenamiento específico.
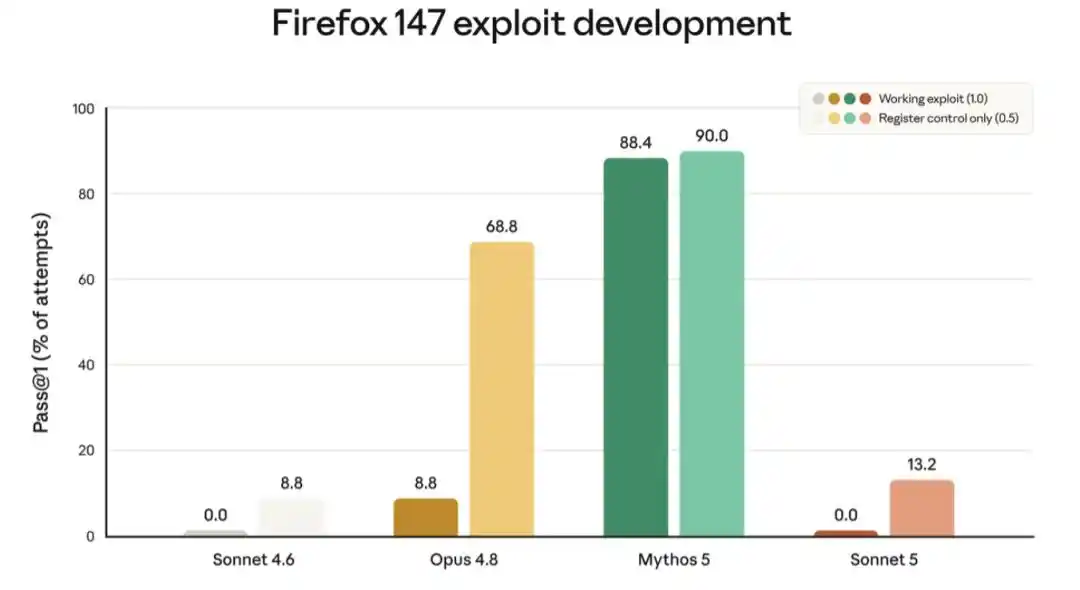
La gráfica anterior muestra las puntuaciones de los modelos para desarrollar con éxito un exploit para una vulnerabilidad de software en Firefox 147 (esta evaluación fue desarrollada en colaboración con Mozilla; todas las vulnerabilidades fueron corregidas en Firefox 148). Para cada modelo, la barra izquierda indica la frecuencia con la que el modelo (sin salvaguardas de seguridad) desarrolló un exploit utilizable, y la barra derecha indica la frecuencia de éxitos parciales. Ninguno de los dos modelos Sonnet logró desarrollar un exploit exitoso (puntuación 0.0% para ambos); la tasa de éxito parcial de Sonnet 5 fue ligeramente superior a la de Sonnet 4.6. Las capacidades de red de ambos modelos Sonnet son significativamente más débiles que las de Opus 4.8 y Mythos 5.
Dado que Sonnet 5 está ligeramente más capacitado que su predecesor para estas tareas, Anthropic ha habilitado por defecto salvaguardas de ciberseguridad. Estas salvaguardas —capaces de detectar y bloquear en tiempo real el uso peligroso de la red— son las mismas que las de Claude Opus 4.7 y 4.8 (porque Anthropic considera que el riesgo general de ciberseguridad de Sonnet 5 es bajo, y sus salvaguardas son menos estrictas que las habilitadas para Fable 5 —que bloquea un rango más amplio de tareas de ciberseguridad—).
El informe completo de evaluación de Anthropic sobre Sonnet 5 en múltiples evaluaciones de seguridad y capacidades está disponible en la Ficha Técnica del Sistema de Claude Sonnet 5.
Precios
A partir de hoy, Claude Sonnet 5 está disponible oficialmente en todos los canales. Para celebrar el lanzamiento, Anthropic ofrece un precio promocional de lanzamiento por tiempo limitado:
- Desde hoy hasta el 31 de agosto de 2026: entrada $2 / millón de tokens, salida $10 / millón de tokens
- Posteriormente, se aplicará el precio estándar: entrada $3 / millón de tokens, salida $15 / millón de tokens
Al mismo tiempo, anuncian un aumento generalizado de los límites de tasa (rate limits) en Chat, Cowork, Claude Code y la plataforma Claude, para adaptarse al mayor consumo de tokens derivado de los modos de mayor «esfuerzo».
Aspectos a tener en cuenta
Verificación de ciberseguridad
Sonnet 5 se ha incorporado al «Programa de Verificación de Ciberseguridad» de Anthropic. Este programa ya está disponible en las siguientes plataformas:
- La plataforma nativa Claude
- Plataforma Claude en AWS
- Claude en Microsoft Foundry (alojado en Azure y Anthropic)
Claude en Google Vertex también lo soportará próximamente.
Las organizaciones que ya forman parte de este programa obtienen automáticamente el mismo nivel de acceso en Sonnet 5, sin necesidad de volver a solicitarlo. Si tu trabajo de ciberseguridad requiere menos restricciones de salvaguardia, Anthropic recomienda usar Claude Opus 4.8.
Actualización del tokenizador y aclaración sobre precios
Sonnet 5 es una actualización de Sonnet 4.6, pero utiliza un nuevo tokenizador para optimizar el rendimiento del procesamiento de texto (similar al cambio de tokenizador introducido en Claude Opus 4.7).
El cambio resultante es: el mismo contenido de entrada ahora se mapea a más tokens, con un aumento de aproximadamente 1.0 a 1.35 veces, dependiendo del tipo de contenido.
Por ello, el precio promocional establecido por Anthropic tiene como objetivo que el costo total para los usuarios que migren a Sonnet 5 se mantenga aproximadamente igual.
Aclaración sobre el ajuste de los límites de tasa
El 26 de abril de 2026, Anthropic ya había aumentado los límites de tasa para los modelos Sonnet y Haiku en todos los niveles de uso, y simplificó los planes de la plataforma nativa Claude a tres niveles: Start, Build y Scale.
Con esta actualización, Anthropic aumenta aún más los límites de tasa en Chat, Cowork, Claude Code y la plataforma Claude, para acompañar el mayor consumo de tokens que implican los modos de mayor «esfuerzo».
Puedes consultar tu nivel actual y los límites específicos en la Consola de Claude, o consultar la documentación para más detalles.
Aclaración sobre corrección de puntuaciones de evaluación (complemento)
- Humanity’s Last Exam: Anthropic actualizó el modelo de puntuación de esta evaluación y, en consecuencia, corrigió la puntuación de Sonnet 4.6 a 34.6% (sin herramientas) y 46.8% (con herramientas). Por lo tanto, esta puntuación difiere de la reportada en el blog de lanzamiento de Sonnet 4.6, se aclara aquí.
- OSWorld‐Verified: Anthropic optimizó la forma en que se ejecuta esta evaluación para reflejar de manera más realista el rendimiento del modelo en escenarios prácticos, y corrigió la puntuación de Sonnet 4.6 a 78.5%. Esta es también la razón por la que esta puntuación difiere de los datos del blog de lanzamiento de Sonnet 4.6.
Comentarios de desarrolladores al probarlo
Tras el lanzamiento de Claude Sonnet 5, muchos ya han comenzado a probarlo y evaluarlo.
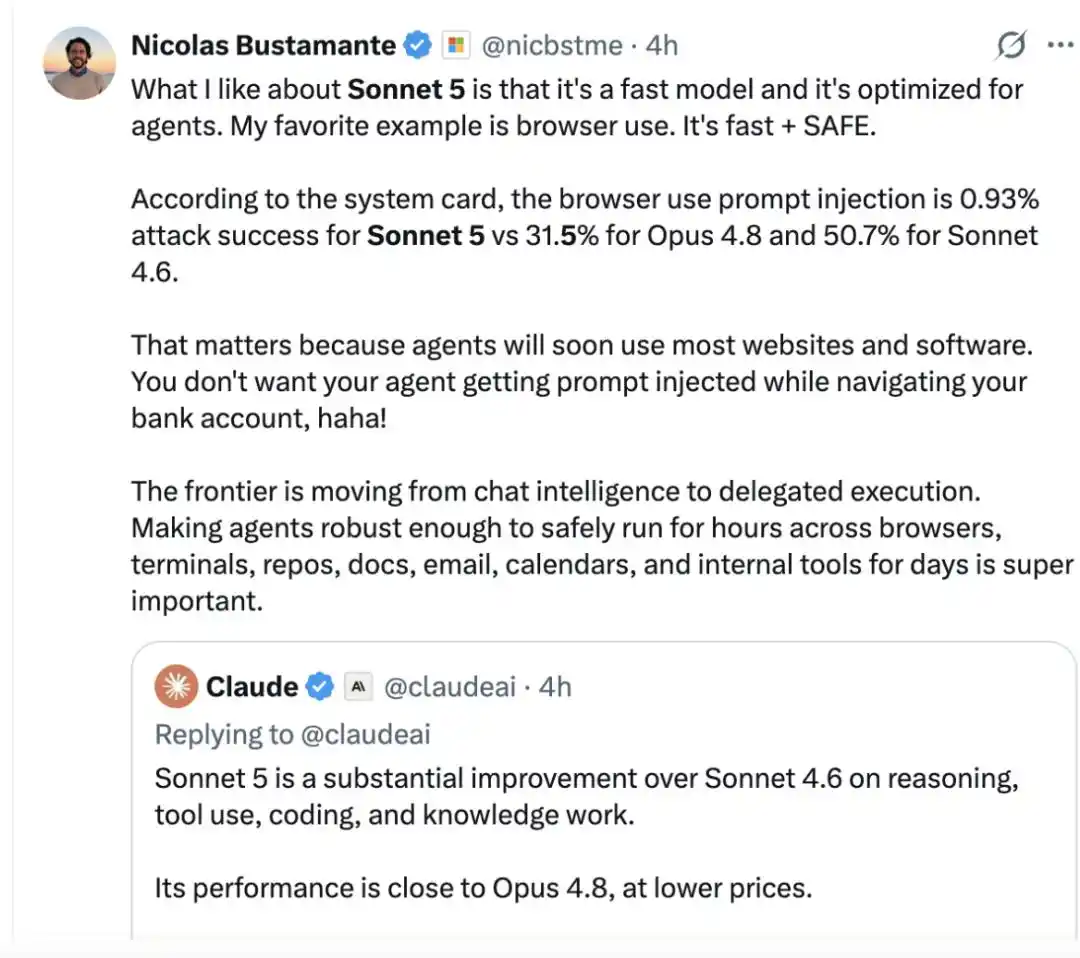
El usuario Nicolas Bustamante comentó que le gusta de Sonnet 5 que es rápido y está optimizado para Agentes. «Mi ejemplo favorito es el uso del navegador: rápido y seguro».
Según los resultados de la ficha técnica del sistema, la tasa de éxito de los ataques de inyección de prompts en escenarios de uso del navegador es solo del 0.93% para Sonnet 5, mientras que para Opus 4.8 es del 31.5% y para Sonnet 4.6 del 50.7%.
Sin embargo, también hay usuarios que opinan que «es demasiado caro».
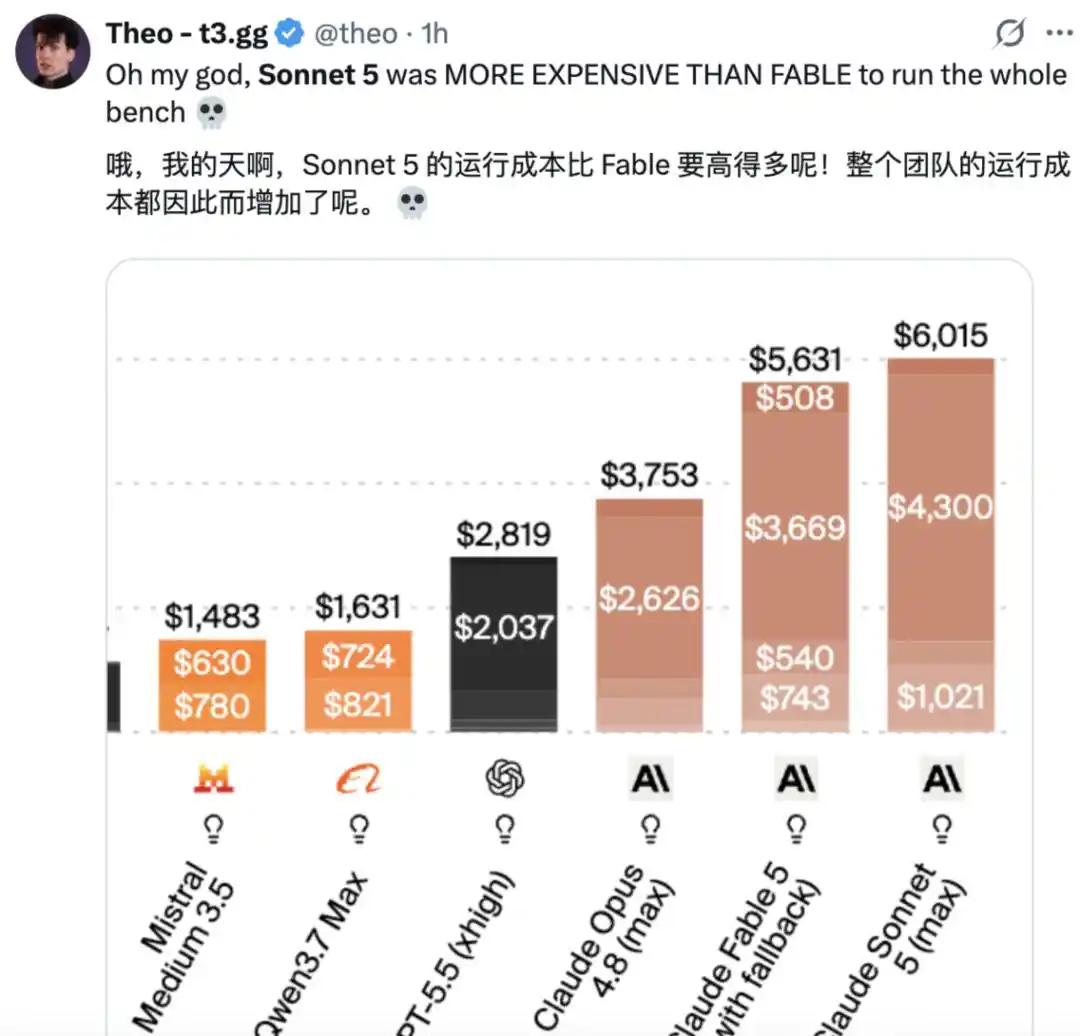
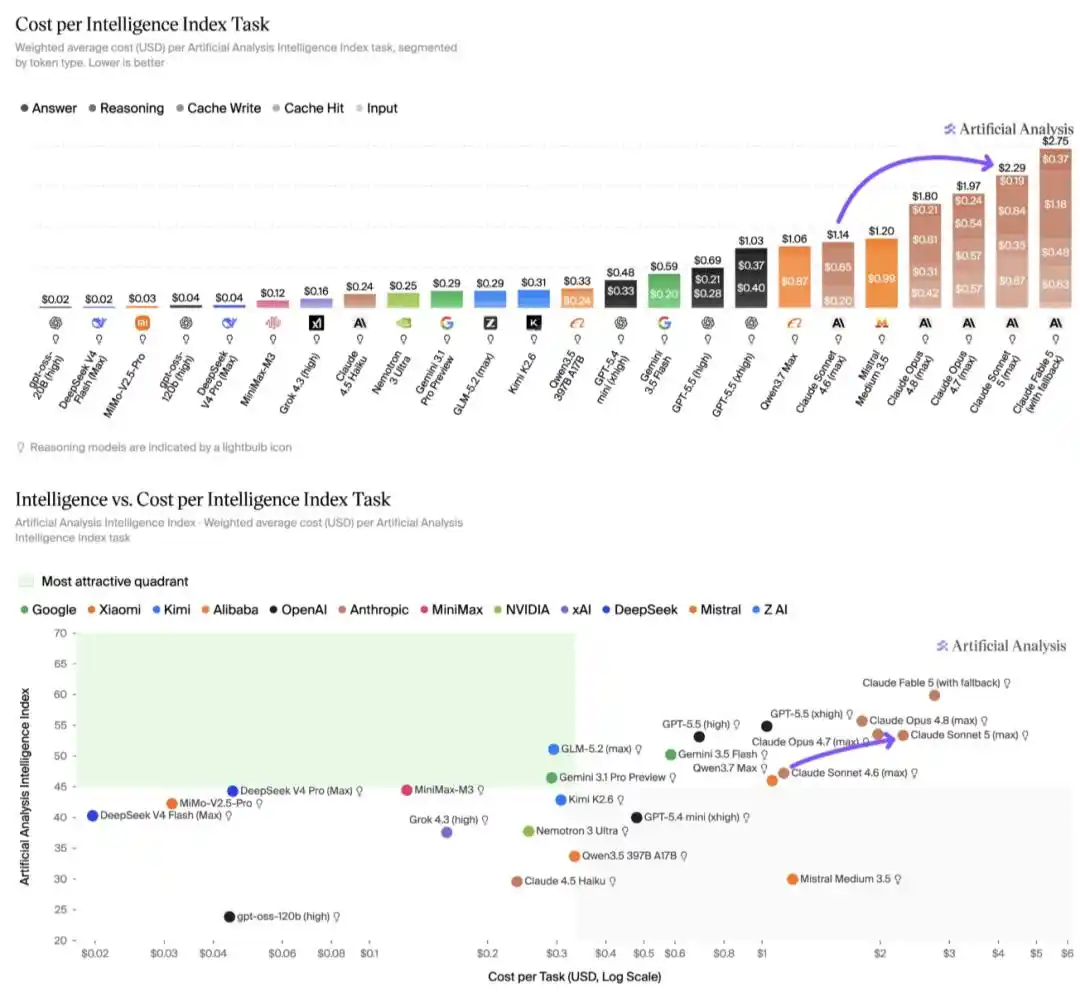
Según un análisis de Artificial Analysis, en el Índice de Inteligencia (Intelligence Index), el costo de ejecución de Claude Sonnet 5 es de 2.29 dólares por tarea, aproximadamente el doble que el de Sonnet 4.6, y también alrededor de un 15% más alto que el de Claude Opus 4.8. Este aumento de costo está completamente impulsado por el mayor uso de tokens, convirtiendo a Claude Sonnet 5 en uno de los modelos más caros de ejecutar, solo superado por Claude Fable 5.
¿Y tú, qué opinas del nuevo modelo? ¡Comparte tus comentarios y experiencias abajo!
Enlaces de referencia:
https://x.com/claudeai/status/2072017450611142835
https://www.anthropic.com/news/claude-sonnet-5
https://x.com/ArtificialAnlys/status/2072062595482456431
Este artículo procede del WeChat oficial «机器之心» (ID:almosthuman2014), autor: 关注AI的





