Por | Sun Yongjie
Al entrar en 2026, la ventana de lanzamiento de DeepSeek V4 se ha pospuesto repetidamente, lo que inesperadamente ha avivado el debate global sobre la "des-CUDA-ización" en el círculo de la IA. Según informes de varios medios, este modelo de código abierto multimodal, que se espera tenga un tamaño de parámetros de billones y admita un contexto de un millón de tokens, se está adaptando intensamente a los chips Ascend de Huawei y reescribiendo su código central mediante el framework CANN.
Si esto se convierte en realidad, será la primera vez que el ecosistema de IA chino explore sistemáticamente en un entorno de producción real la posibilidad de albergar capacidades centrales de modelos en una plataforma no CUDA. En otras palabras, esto no es solo el lanzamiento de un modelo, sino más bien una "prueba de estrés" de la ruta tecnológica subyacente.
Sin embargo, como enfatizó Liang Wenfeng, fundador de DeepSeek, en una comunicación interna, esto es solo el "primer paso de una larga marcha". El futuro conlleva riesgos y oportunidades, y el equilibrio, e incluso la elección, entre compatibilidad y autonomía determinará si la IA china puede realmente forjar su propio camino de desarrollo.
El retraso de DeepSeek V4: El costo inevitable de la transición de la plataforma de computación básica de IA
Como se mencionó, el V4, originalmente planeado para ser lanzado alrededor del Año Nuevo chino o en febrero-marzo de este año, ha perdido repetidamente su ventana, hasta que a principios de abril los medios confirmaron su lanzamiento "en unas semanas". La razón principal es la profunda adaptación en el lado de la inferencia con los chips Ascend de Huawei. Pero el problema es que este camino es mucho más complejo de lo imaginado. Para entender esta complejidad, primero hay que volver a las características técnicas del propio DeepSeek V4.
Como es bien sabido, al entrar en 2026, el tamaño de los parámetros de los modelos grandes ha superado el umbral de los "billones" y avanza hacia decenas de billones. En este contexto, aunque el V4 adopta una arquitectura MoE (Mixture of Experts) más agresiva, que en teoría reduce la carga computacional de inferencia por activación mediante la "activación bajo demanda de expertos", el costo es que impone requisitos extremos en capacidades del sistema como el ancho de banda de memoria, la interconexión entre chips (Interconnect) y la gestión de la KV Cache, entre otros.
En otras palabras, la presión de la potencia de cálculo ha pasado de la "computación pura" a la "planificación del sistema y las comunicaciones". Y dentro del ecosistema de NVIDIA, este conjunto de problemas tiene soluciones relativamente maduras.
Por ejemplo, basándose en H100 o B200, la interconexión de alto ancho de banda construida mediante NVLink y NVSwitch puede alcanzar niveles de TB/s entre GPUs en un solo nodo, formando una red de computación casi "totalmente conectada", donde los datos fluyen entre chips como en una autopista, comprimiendo enormemente la latencia y los costos de sincronización. Pero cuando DeepSeek intenta migrar este sistema preciso a la plataforma Ascend de Huawei, se enfrenta a una topología de hardware completamente diferente.
No se puede negar que los chips Ascend han progresado significativamente en los últimos años, pero aún existe una brecha física con NVIDIA en cuanto a la capacidad de "conectividad total" de los clústeres a gran escala. Por ejemplo, limitados por la tecnología de proceso y la capacidad IP de SerDes, los Ascend dependen más de módulos ópticos para la expansión entre nodos. Aunque este esquema de "intercambiar espacio por ancho de banda" es viable, también introduce trayectos físicos más largos, lo que conlleva complejidades como la latencia de la señal, la sobrecarga de sincronización y la gestión de la energía disipada y la refrigeración.
Al mismo tiempo, la brecha a nivel de software tampoco puede ignorarse. El framework CANN de Ascend, en términos de cobertura de operadores, paralelismo automático, fusión de kernels y planificación de comunicaciones distribuidas, entre otros, aún tiene una madurez general inferior a la del ecosistema CUDA. Esto significa que el equipo de ingeniería de DeepSeek necesita realizar optimizaciones específicas en una gran cantidad de detalles de bajo nivel, incluso reescribiendo manualmente operadores clave.
Lo más complicado es que este retraso a menudo no es lineal, sino sistémico. Se manifiesta concretamente en que una caída en el rendimiento de un operador puede afectar a toda la cadena de cálculo; una reducción en la eficiencia de una comunicación puede causar grandes fluctuaciones en el rendimiento general. El resultado final podría ser que el modelo aún funcione, pero esté lejos de ser estable, eficiente y escalable.
Desde esta perspectiva, el retraso de DeepSeek V4 no es un simple problema de ritmo del producto, sino el costo inevitable de la profunda磨合 (adaptación/maduración) entre un equipo algorítmico chino de primer nivel y el sistema de chips nacional. Aunque el proceso es difícil, es de gran importancia.
Lo más importante es que este proceso envía una señal clara: la competencia en IA está pasando de la "comparación de capacidades de los modelos" a la "comparación de capacidades de ingeniería de sistemas". Y en esta etapa, quien pueda hacer que los modelos "funcionen, funcionen de forma estable y funcionen de manera económica" más rápido, será quien se acerque realmente a una ventaja a nivel industrial.
El monopolio de CUDA es difícil de romper, el CANN se ve obligado a comprometerse
Si las dificultades de adaptación del lado de la inferencia de DeepSeek V4 mencionadas anteriormente revelan cuellos de botella reales a nivel de ingeniería, al profundizar en esta pregunta surge una interrogante más fundamental: ¿Por qué simplemente migrar un modelo de una plataforma de computación a otra se ha vuelto tan difícil?
Mirando hacia atrás a la alianza Wintel de la era PC, Microsoft e Intel, aunque monopolizaban conjuntamente, existía una contienda de intereses entre ambas empresas, lo que dejó espacio para el surgimiento posterior de Linux, AMD e incluso el de Apple. Sin embargo, NVIDIA ha establecido en el campo de la IA un "monopolio vertical monolítico", es decir, la fusión de Microsoft e Intel.
Se manifiesta concretamente en que, a nivel de hardware, NVIDIA define la estructura física del SM (Streaming Multiprocessor) y la lógica de cálculo del Tensor Core; a nivel de software, CUDA proporciona bibliotecas cerradas como cuBLAS y cuDNN que se ajustan perfectamente 1:1 a ello. La superposición de ambos lleva a una realidad extremadamente abrumadora: más de 6 millones de desarrolladores en todo el mundo optimizan algoritmos y frameworks (PyTorch, TensorFlow) en torno a cuBLAS, cuDNN, NVLink/NVSwitch, priorizando la implementación CUDA. Incluso clústeres heterogéneos "anti-NVIDIA" como AWS Trainium + Cerebras WSE, al migrar la caché KV, aún necesitan el software NVIDIA NIXL y AWS EFA.
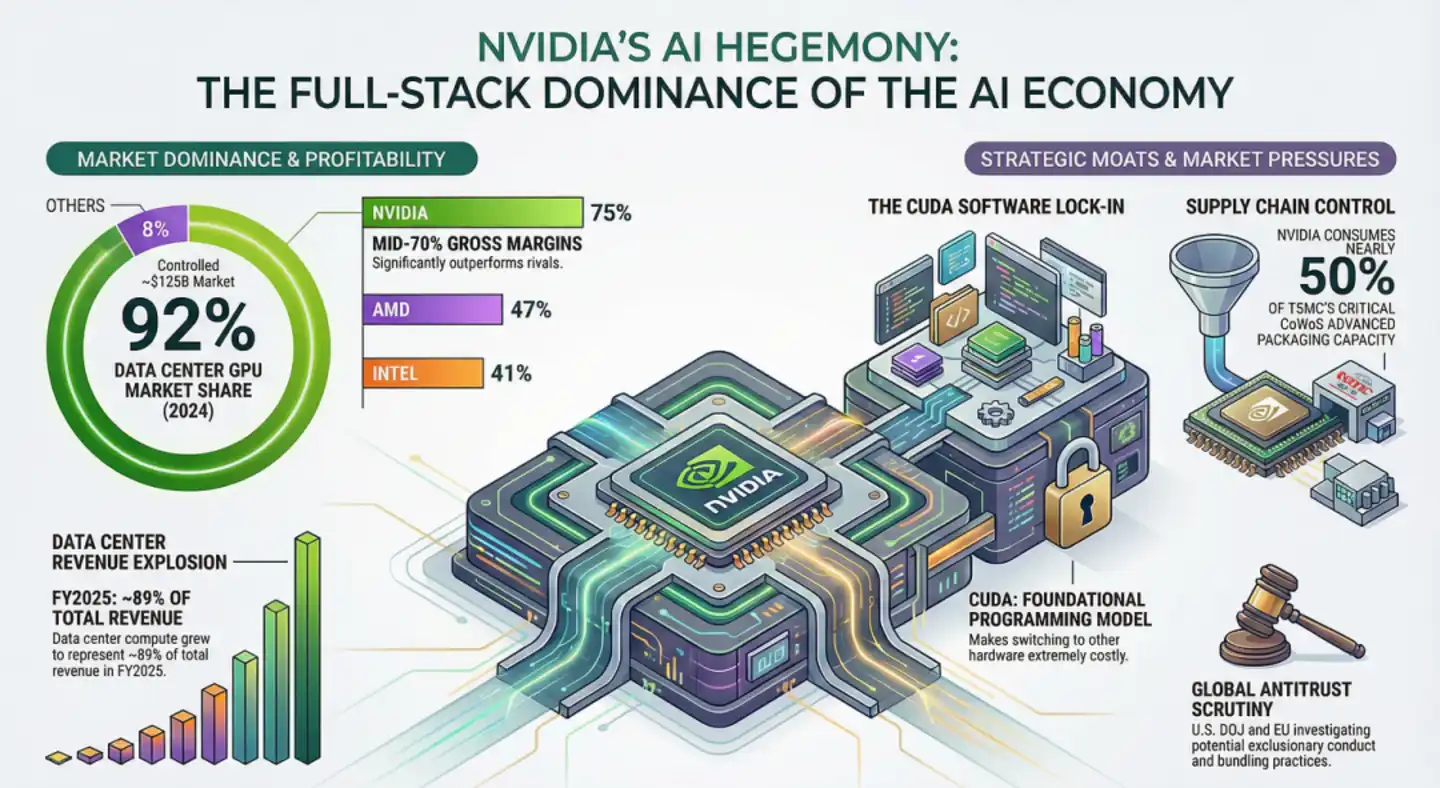
Esto demuestra que ya no es un detalle técnico puntual, es un bloqueo del ecosistema: antes de que falle la portabilidad del modelo, el que los desarrolladores "piensen en el lenguaje de las características del hardware de NVIDIA" se ha convertido en una inercia. Y es precisamente esta inercia del ecosistema la que hace que NVIDIA actúe como un enorme agujero negro, absorbiendo más del 90% de los beneficios de la innovación global.
En el contexto anterior, CANN de Huawei, como su competidor más fuerte, inicialmente intentó seguir un camino relativamente independiente. Pero con la llegada de la era de los modelos grandes, este camino comenzó a mostrar problemas, como la reticencia de los desarrolladores a migrar, el miedo de las empresas a asumir riesgos y el lento crecimiento del ecosistema. Sumado a la presión del tiempo (por ejemplo, la rápida iteración de los modelos grandes), el camino completamente autónomo comenzó a dejar de ser realista.
Basándose en esto, CANN introdujo gradualmente un diseño de capa de abstracción similar a CUDA. Por ejemplo, en CANN Next intentó igualar las interfaces de cuBLAS y cuDNN, logrando una alta compatibilidad, reduciendo el costo de migración de modelos de "semanas o incluso meses" a "horas"; a nivel arquitectónico, la recientemente lanzada arquitectura heterogénea 950PR (prellenado/desacoplamiento de decodificación) también imita deliberadamente el servicio desacoplado de NVIDIA, en lugar de la ruta totalmente heterogénea del TPU de Google.
Debemos admitir que esta estrategia de "compatibilidad primero" ha sido exitosa a corto plazo: ha reducido el umbral de entrada, permitiendo que Ascend obtenga rápidamente una base de aplicaciones en el mercado interno y que empresas como DeepSeek, Tencent, ByteDance, entre otras, puedan probar la computación nacional con un umbral relativamente bajo. Por ejemplo, CANN Next ha logrado una compatibilidad con CUDA superior al 95% mediante un modelo de programación SIMT, ayudando a varias empresas a acortar drásticamente el tiempo de migración a nivel de horas y acelerando la implementación real.
Pero el desafío que surge es que una vez que se involucra la innovación de vanguardia, la capa de compatibilidad se convierte en un "techo".
Por ejemplo, cuando los desarrolladores profundizan realmente en el uso de la plataforma Ascend, descubren que, aunque las rutas comunes están allanadas, una vez que se trata de algunos operadores subyacentes poco comunes o innovadores, el soporte de CANN disminuye y la fluctuación del rendimiento es severa. Las dificultades que encontró DeepSeek V4 durante su adaptación, como al intentar introducir arquitecturas híbridas como SSM (State Space Model) o Mamba, que no son estructuras Transformer, y descubrir que la optimización subyacente de CANN aún se inclina principalmente hacia la multiplicación de matrices (GEMM), se deben en gran medida a que, al intentar algunas optimizaciones algorítmicas que van más allá de lo convencional, chocaron con el "límite" de la capa de compatibilidad de CANN.
Y el problema más profundo es que una vez que se elige la compatibilidad, significa que se acepta tácitamente que CUDA sigue siendo el estándar invisible. Puedes reemplazar el hardware, pero en la semántica del software y el paradigma de desarrollo, aún sigues las reglas definidas por el otro. Esto es tanto un atajo como una limitación.
La compatibilidad conlleva riesgos y desafíos, las oportunidades futuras aún requieren una verdadera autonomía
Como se mencionó, ante la realidad de que el ecosistema CUDA se ha convertido en un estándar de facto, la elección de Huawei del camino de "cuasi-compatibilidad" era casi inevitable, pero al mismo tiempo empujó a toda la industria de IA china a un nodo crítico de elección: ¿seguir siendo compatible con CUDA o avanzar gradualmente hacia un ecosistema verdaderamente independiente?
A corto plazo, la respuesta casi no tiene duda: hay que ser compatible, es una cuestión de eficiencia y realidad. Pero a largo plazo, este camino oculta riesgos que no pueden ignorarse.
Como es bien sabido, cuando un sistema (como CANN) se diseña para ser compatible con otro (como CUDA), inevitablemente hereda sus limitaciones.
El hecho es que actualmente la mayoría de los algoritmos de código abierto globales se desarrollan en torno a la arquitectura NVIDIA. Si, para aprovechar estos activos existentes, se busca obstinadamente una compatibilidad 1:1, entonces caeremos en la "trampa del imitador" en el diseño de hardware, y se manifestará así: si la arquitectura de hardware de NVIDIA enfrenta en algún momento futuro una transición de paradigma, por ejemplo, pasando de Transformer a una nueva arquitectura que no requiera multiplicación de matrices a gran escala, sino que dependa más de lógica asíncrona, entonces la pila de computación nacional, que siempre ha estado en un "estado de sombra", podría enfrentar una abrupta discontinuidad tecnológica. Este callejón sin salida de la "compatibilidad error por error"无疑 (sin duda) mantiene nuestra innovación subyacente siempre bajo la sombra de los demás.
Y el riesgo más profundo radica en el "desfase temporal". Según datos estadísticos de Bernstein y Epoch AI, aunque la cuota de Huawei ha aumentado drásticamente en China, en la cantidad total de computación de IA global, la proporción de chips nacionales es solo del 5%, todavía relativamente limitada. Y es precisamente esta brecha de escala absoluta la que causa una grave "fricción en la eficiencia de I+D".
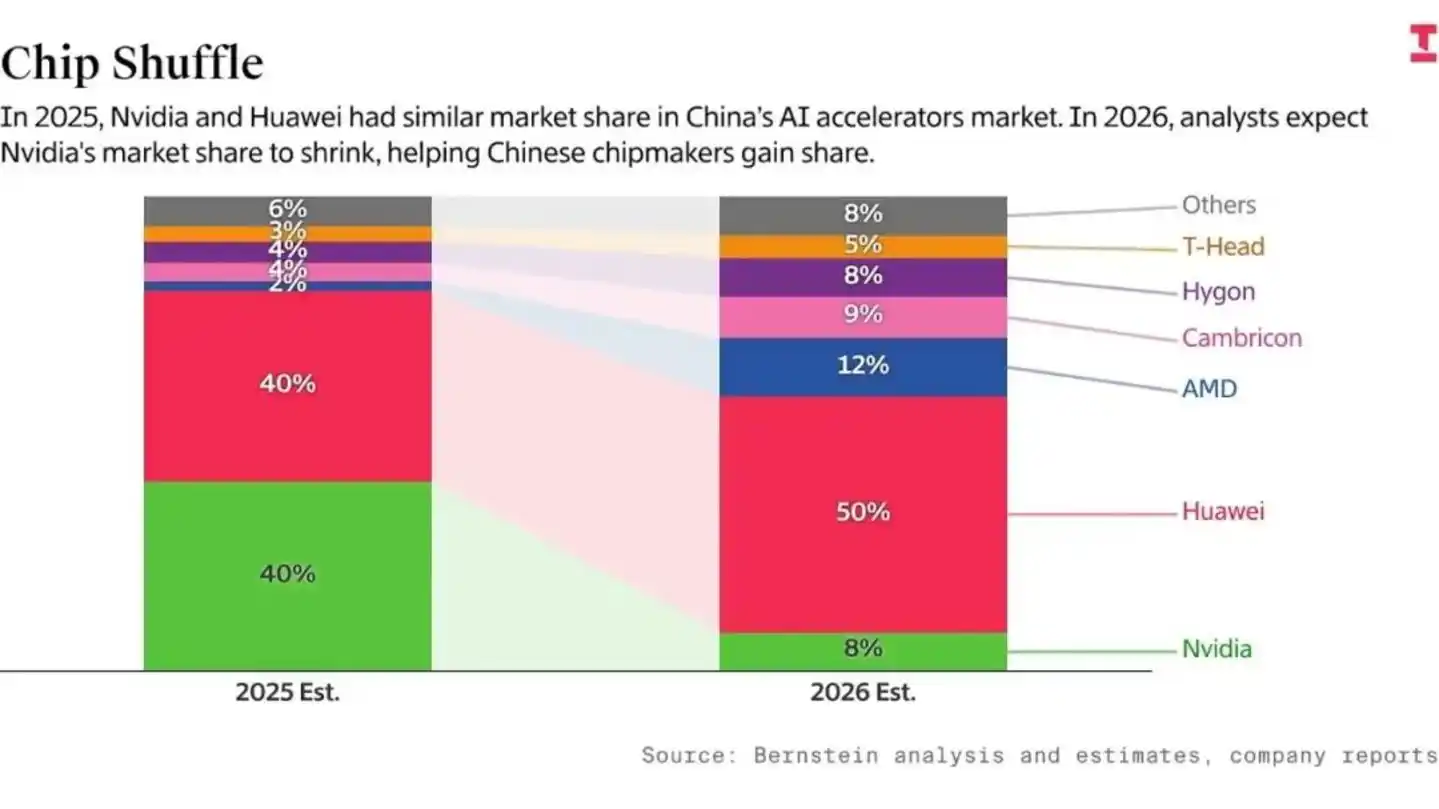
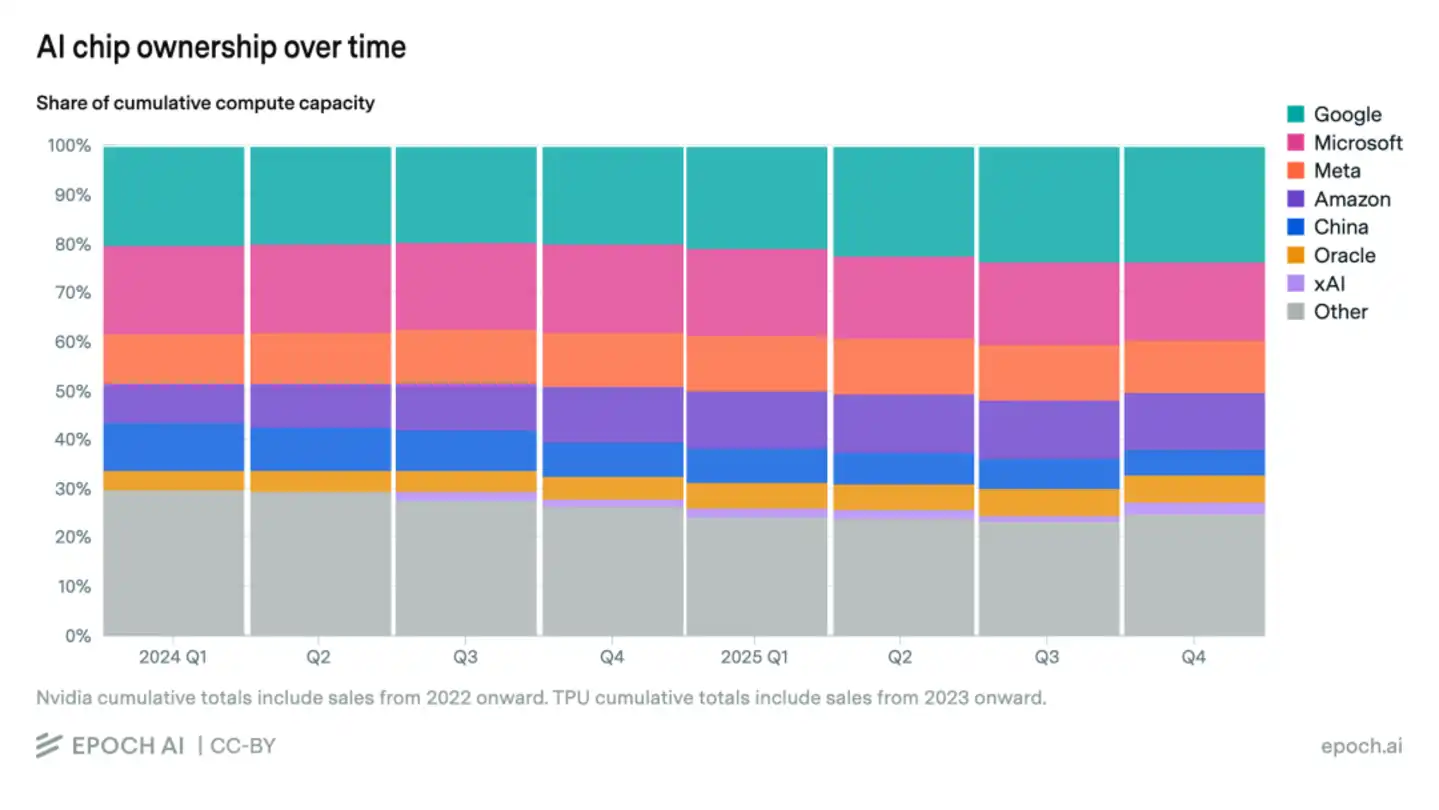
Se manifiesta concretamente en que los gigantes estadounidenses de IA pueden utilizar el potente ancho de banda de comunicaciones de Blackwell para ejecutar las Leyes de Escalado (Scaling Laws) de 10T parámetros en 18 meses, mientras que el talento de primer nivel de China tiene que consumir más del 50% de su capacidad de investigación en problemas como "cómo resolver la atenuación de la señal en chips anticuados" y "adaptar compiladores inmaduros".
Es necesario aclarar que este desfase temporal, en la era de la IA que cambia rápidamente, se amplifica infinitamente. Mientras nuestro talento aún está ocupado "tapando agujeros", el oponente puede haber completado el interés compuesto exponencial de la capacidad del modelo, haciendo que un año de ventaja del modelo del oponente se convierta en una brecha de más de un año con nosotros, tras la superposición del crecimiento compuesto exponencial de la capacidad del modelo, la rueda de datos y la alineación de seguridad.
Por supuesto, los desafíos a menudo conllevan oportunidades. Si DeepSeek V4 se lanza con éxito, demostrará la viabilidad de la "pila completa nacional", acelerará la maduración del ecosistema CANN y atraerá a más desarrolladores a seguirlo. Sumado al sentimiento global de "el mundo está harto de NVIDIA desde hace tiempo", el apoyo de la industria a CANN podría superar las expectativas. Y si los futuros chips como Huawei Ascend alcanzan el 80%-90% del rendimiento de inferencia de H100,叠加 (superponiendo) el dividendo de compatibilidad de CANN Next, es posible que se forme una masa crítica en la cadena de suministro de IA china en 1-2 años.
Pero es necesario reconocer con claridad que la compatibilidad solo puede resolver el problema de "sobrevivir"; la verdadera autonomía es lo que determinará "hasta dónde llegar". Y los próximos 3-5 años serán un período crítico. Si podemos, manteniendo la compatibilidad, establecer gradualmente modelos de programación independientes, sistemas de operadores y arquitecturas de sistemas, el ecosistema de IA chino aún tendrá la oportunidad de lograr un salto desde seguir hasta definir las reglas. De lo contrario, la IA china podría quedar atrapada en la vía del "tren de la copia burda".
Para finalizar: El lanzamiento retrasado de DeepSeek V4, aparentemente un "retraso" casual, en realidad revela una realidad más profunda: la competencia en IA ya no es solo una disputa entre modelos, sino una competencia integral del ecosistema subyacente y las capacidades del sistema. Ser compatible con CUDA es sin duda el camino más corto hacia la realidad, pero si nos detenemos ahí, también podría fijar el techo futuro.
Por lo tanto, el verdadero desafío no reside en si podemos reemplazar un conjunto de tecnología, sino en si podemos liberarnos de la dependencia de los paradigmas existentes y construir nuestro propio sistema de reglas. Y los próximos 3-5 años determinarán si la IA china se convierte en un polo importante del ecosistema global o se mantiene a largo plazo en una posición de "seguimiento de alto nivel". Por supuesto, al buscar la autonomía, también debemos estar alerta ante el impacto potencial que un ecosistema cerrado podría tener en la atracción de desarrolladores globales, para garantizar la apertura del ecosistema y la competitividad internacional a largo plazo.






