Authors: Li Hailun, Su Yang
On January 6th, Beijing time, NVIDIA CEO Jensen Huang, clad in his signature leather jacket, once again took the main stage at CES 2026.
At CES 2025, NVIDIA showcased the mass-produced Blackwell chip and a full-stack physical AI technology suite. During the event, Huang emphasized that an "era of Physical AI" was dawning. He painted a future full of imagination: autonomous vehicles with reasoning capabilities, robots that can understand and think, and AI Agents capable of handling long-context tasks involving millions of tokens.
A year has passed in a flash, and the AI industry has undergone significant evolution and change. Reviewing these changes at the launch event, Huang specifically highlighted open-source models.
He stated that open-source reasoning models like DeepSeek R1 have made the entire industry realize: when true openness and global collaboration kick in, the diffusion speed of AI becomes extremely rapid. Although open-source models still lag behind the most advanced models by about six months in overall capability, they close the gap every six months, and their downloads and usage have already seen explosive growth.

Compared to 2025's focus more on vision and possibilities, this time NVIDIA began systematically addressing the question of "how to achieve it":围绕推理型 AI (focusing on reasoning AI), it is bolstering the compute, networking, and storage infrastructure required for long-term operation, significantly reducing inference costs, and embedding these capabilities directly into real-world scenarios like autonomous driving and robotics.
Huang's CES keynote this year unfolded along three main lines:
● At the system and infrastructure level, NVIDIA redesigned the compute, networking, and storage architecture around long-term inference needs. With the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the Inference Context Memory Storage platform at the core, these updates directly target bottlenecks like high inference costs, difficulty in sustaining context, and scalability limitations, solving the problems of letting AI 'think a bit longer', 'afford to compute', and 'run persistently'.
● At the model level, NVIDIA placed Reasoning / Agentic AI at the core. Through models and tools like Alpamayo, Nemotron, and Cosmos Reason, it is pushing AI from "generating content" towards "continuous thinking", and from "one-time response models" to "agents that can work long-term".
● At the application and deployment level, these capabilities are being directly integrated into Physical AI scenarios like autonomous driving and robotics. Whether it's the Alpamayo-powered autonomous driving system or the GR00T and Jetson robotics ecosystem, they are driving scaled deployment through partnerships with cloud providers and enterprise platforms.

01 From Roadmap to Mass Production: Rubin's Full Performance Data Revealed for the First Time
At this CES, NVIDIA fully disclosed the technical details of the Rubin architecture for the first time.
In his speech, Huang started with the concept of Test-time Scaling. This concept can be understood as: making AI smarter isn't just about making it "study harder" during training anymore, but rather letting it "think a bit longer when encountering a problem".
In the past, improvements in AI capability relied mainly on throwing more compute power at the training stage, making models larger and larger; now, the new change is that even if the model stops growing, simply giving it a bit more time and compute power to think during each use can significantly improve the results.
How to make "AI thinking a bit longer" economically feasible? The Rubin architecture's next-generation AI computing platform is here to solve this problem.
Huang introduced it as a complete next-generation AI computing system, achieving a revolutionary drop in inference costs through the co-design of the Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, and Spectrum-6.

The NVIDIA Rubin GPU is the core chip responsible for AI compute in the Rubin architecture, aiming to significantly reduce the unit cost of inference and training.
Simply put, the Rubin GPU's core mission is to "make AI cheaper and smarter to use".
The core capability of the Rubin GPU lies in: the same GPU can handle more work. It can process more inference tasks at once, remember longer context, and communicate faster with other GPUs. This means many scenarios that previously required "stacking multiple cards" can now be accomplished with fewer GPUs.
The result is that inference is not only faster, but also significantly cheaper.
Huang recapped the hardware specs of the Rubin architecture's NVL72 for the audience: it contains 220 trillion transistors, with a bandwidth of 260 TB/s, and is the industry's first platform supporting rack-scale confidential computing.

Overall, compared to Blackwell, the Rubin GPU achieves a generational leap in key metrics: NVFP4 inference performance increases to 50 PFLOPS (5x), training performance to 35 PFLOPS (3.5x), HBM4 memory bandwidth to 22 TB/s (2.8x), and single GPU NVLink interconnect bandwidth doubles to 3.6 TB/s.
These improvements work together to enable a single GPU to handle more inference tasks and longer context, fundamentally reducing the reliance on the number of GPUs.

The Vera CPU is a core component designed specifically for data movement and Agentic processing, featuring 88 NVIDIA-designed Olympus cores, equipped with 1.5 TB of system memory (3x that of the previous Grace CPU), and achieving coherent memory access between CPU and GPU through 1.8 TB/s NVLink-C2C technology.
Unlike traditional general-purpose CPUs, Vera focuses on data scheduling and multi-step reasoning logic processing in AI inference scenarios, essentially acting as the system coordinator that enables "AI thinking a bit longer" to run efficiently.
NVLink 6, with its 3.6 TB/s bandwidth and in-network computing capability, allows the 72 GPUs in the Rubin architecture to work together like a single super GPU, which is key infrastructure for reducing inference costs.
This way, the data and intermediate results needed by AI during inference can quickly circulate between GPUs, without repeatedly waiting, copying, or recalculating.


In the Rubin architecture, NVLink-6 handles internal collaborative computing between GPUs, BlueField-4 handles context and data scheduling, and ConnectX-9 undertakes the system's high-speed external network connectivity. It ensures the Rubin system can communicate efficiently with other racks, data centers, and cloud platforms, a prerequisite for the smooth operation of large-scale training and inference tasks.
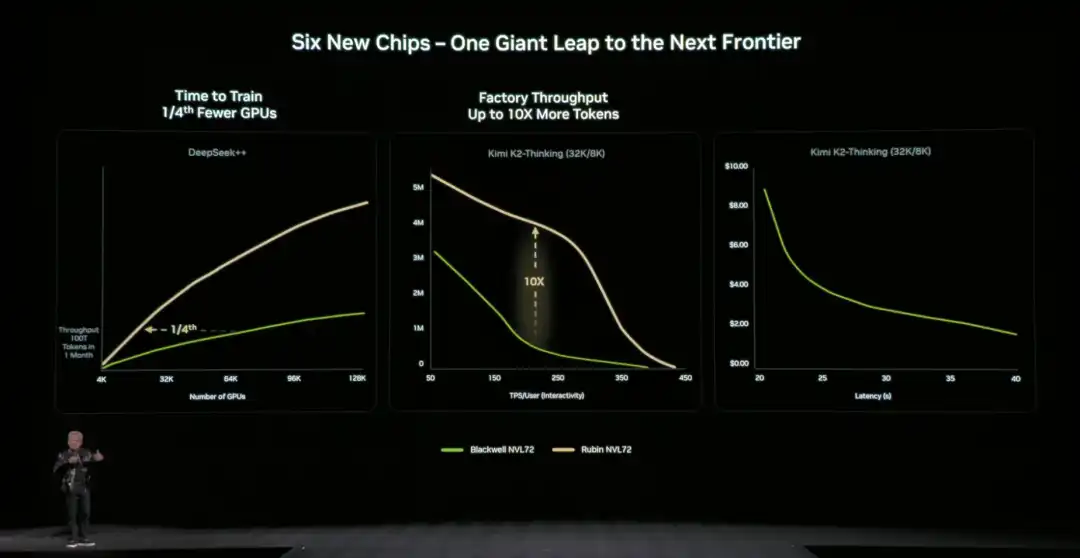
Compared to the previous generation architecture, NVIDIA also provided specific,直观的数据 (intuitive data): compared to the NVIDIA Blackwell platform, it can reduce token costs in the inference phase by up to 10 times, and reduce the number of GPUs required for training Mixture of Experts (MoE) models to 1/4 of the original.
NVIDIA officially stated that Microsoft has already committed to deploying hundreds of thousands of Vera Rubin chips in its next-generation Fairwater AI super factory, and cloud service providers like CoreWeave will offer Rubin instances in the second half of 2026. This infrastructure for "letting AI think a bit longer" is moving from technical demonstration to scaled commercial use.

02 How is the "Storage Bottleneck" Solved?
Letting AI "think a bit longer" also faces a key technical challenge: where should the context data be stored?
When AI handles complex tasks requiring multi-turn dialogue or multi-step reasoning, it generates a large amount of context data (KV Cache). Traditional architectures either cram it into expensive and capacity-limited GPU memory or put it in ordinary storage (which is too slow to access). If this "storage bottleneck" isn't solved, even the most powerful GPU will be hampered.
To address this issue, NVIDIA fully disclosed the BlueField-4 powered Inference Context Memory Storage Platform for the first time at this CES. The core goal is to create a "third layer" between GPU memory and traditional storage. It's fast enough, has ample capacity, and can support AI's long-term operation.
From a technical implementation perspective, this platform isn't the result of a single component working alone, but rather a set of co-designed elements:
- BlueField-4 is responsible for accelerating the management and access of context data at the hardware level, reducing data movement and system overhead;
- Spectrum-X Ethernet provides high-performance networking, supporting high-speed data sharing based on RDMA;
- Software components like DOCA, NIXL, and Dynamo are responsible for optimizing scheduling, reducing latency, and improving overall throughput at the system level.
We can understand this platform's approach as extending the context data, which originally could only reside in GPU memory, to an independent, high-speed, shareable "memory layer". This一方面 (on one hand) relieves pressure on the GPU, and另一方面 (on the other hand) allows for rapid sharing of this context information between multiple nodes and multiple AI agents.
In terms of actual效果 (effects), the data provided by NVIDIA官方 (officially) is: in specific scenarios, this method can increase the number of tokens processed per second by up to 5 times, and achieve同等水平的 (equivalent levels of) energy efficiency optimization.
Huang emphasized多次 (repeatedly) during the presentation that AI is evolving from "one-time dialogue chatbots" to true intelligent collaborators: they need to understand the real world, reason continuously, call tools to complete tasks, and retain both short-term and long-term memory. This is the core characteristic of Agentic AI. The Inference Context Memory Storage Platform is designed precisely for this long-running,反复思考的 (repeatedly thinking) form of AI. By expanding context capacity and speeding up cross-node sharing, it makes multi-turn conversations and multi-agent collaboration more stable, no longer "slowing down the longer it runs".

03 The New Generation DGX SuperPOD: Enabling 576 GPUs to Work Together
NVIDIA announced the new generation DGX SuperPOD (Super Pod) based on the Rubin architecture at this CES, expanding Rubin from a single rack to a complete data center solution.
What is a DGX SuperPOD?
If the Rubin NVL72 is a "super rack" containing 72 GPUs, then the DGX SuperPOD connects multiple such racks together to form a larger-scale AI computing cluster. This released version consists of 8 Vera Rubin NVL72 racks, equivalent to 576 GPUs working together.
When AI task scales continue to expand, the 576 GPUs of a single SuperPOD might not be enough. For example, training ultra-large-scale models, simultaneously serving thousands of Agentic AI agents, or processing complex tasks requiring millions of tokens of context. This requires multiple SuperPODs working together, and the DGX SuperPOD is the standardized solution for this scenario.
For enterprises and cloud service providers, the DGX SuperPOD provides an "out-of-the-box" large-scale AI infrastructure solution. There's no need to figure out how to connect hundreds of GPUs, configure networks, manage storage, etc., themselves.
The five core components of the new generation DGX SuperPOD:
○ 8 Vera Rubin NVL72 Racks - The core providing computing power, 72 GPUs per rack, 576 GPUs total;
○ NVLink 6 Expansion Network - Allows the 576 GPUs across these 8 racks to work together like one超大 (super large) GPU;
○ Spectrum-X Ethernet Expansion Network - Connects different SuperPODs, and to storage and external networks;
○ Inference Context Memory Storage Platform - Provides shared context data storage for long-running inference tasks;
○ NVIDIA Mission Control Software - Manages scheduling, monitoring, and optimization of the entire system.
With this upgrade, the foundation of the SuperPOD is the DGX Vera Rubin NVL72 rack-scale system at its core. Each NVL72 is itself a complete AI supercomputer, internally connecting 72 Rubin GPUs via NVLink 6, capable of handling large-scale inference and training tasks within a single rack. The new DGX SuperPOD consists of multiple NVL72 units, forming a system-level cluster capable of long-term operation.
When the compute scale expands from "single rack" to "multi-rack", new bottlenecks emerge: how to stably and efficiently传输海量数据 (transfer massive amounts of data) between racks.围绕这一问题 (Around this issue), NVIDIA simultaneously announced the new generation Ethernet switch based on the Spectrum-6 chip at this CES, and introduced "Co-Packaged Optics" (CPO) technology for the first time.
Simply put, this involves packaging the originally pluggable optical modules directly next to the switch chip, reducing the signal transmission distance from meters to millimeters, thereby significantly reducing power consumption and latency, and also improving the overall stability of the system.
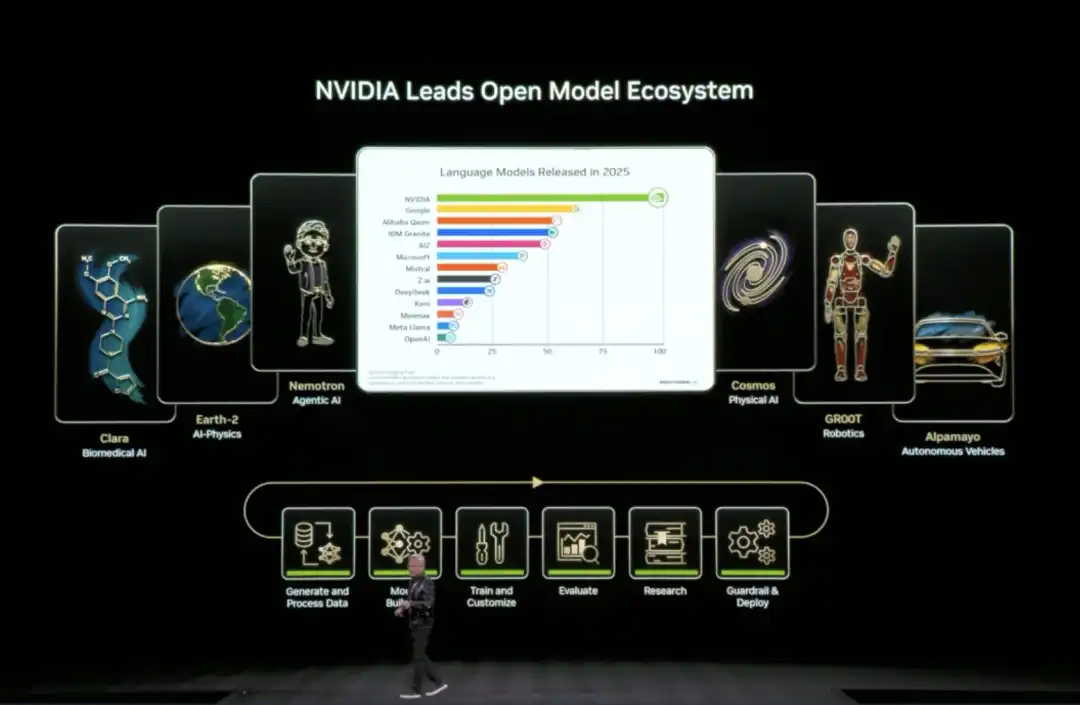
04 NVIDIA's Open Source AI "Full Stack": Everything from Data to Code
At this CES, Huang announced the expansion of its open-source model ecosystem (Open Model Universe), adding and updating a series of models, datasets, code libraries, and tools. This ecosystem covers six areas: Biomedical AI (Clara), AI Physics Simulation (Earth-2), Agentic AI (Nemotron), Physical AI (Cosmos), Robotics (GR00T), and Autonomous Driving (Alpamayo).
Training an AI model requires not just compute power, but also high-quality datasets, pre-trained models, training code, evaluation tools, and a whole set of infrastructure. For most companies and research institutions, building these from scratch is too time-consuming.
Specifically, NVIDIA has open-sourced six layers of content: compute platforms (DGX, HGX, etc.), training datasets for various domains, pre-trained foundation models, inference and training code libraries, complete training process scripts, and end-to-end solution templates.
The Nemotron series was a key focus of this update, covering four application directions.
In the reasoning direction, it includes small-scale reasoning models like Nemotron 3 Nano, Nemotron 2 Nano VL, as well as reinforcement learning training tools like NeMo RL and NeMo Gym. In the RAG (Retrieval-Augmented Generation) direction, it provides Nemotron Embed VL (vector embedding model), Nemotron Rerank VL (re-ranking model), relevant datasets, and the NeMo Retriever Library. In the safety direction, there is the Nemotron Content Safety model and its配套数据集 (matching dataset), and the NeMo Guardrails library.
In the speech direction, it includes Nemotron ASR for automatic speech recognition, the Granary Dataset for speech, and the NeMo Library for speech processing. This means if a company wants to build an AI customer service system with RAG, it doesn't need to train its own embedding and re-ranking models; it can directly use the code NVIDIA has already trained and open-sourced.
05 Physical AI Domain Moves Towards Commercial Deployment
The Physical AI domain also saw model updates—Cosmos for understanding and generating videos of the physical world, the general-purpose robotics foundation model Isaac GR00T, and the vision-language-action model for autonomous driving, Alpamayo.

Huang claimed at CES that the "ChatGPT moment" for Physical AI is approaching, but there are many challenges: the physical world is too complex and variable, collecting real data is slow and expensive, and there's never enough.
What's the solution? Synthetic data is one path. Hence, NVIDIA introduced Cosmos.
This is an open-source foundational model for the physical AI world, already pre-trained on massive amounts of video, real driving and robotics data, and 3D simulation. It can understand how the world works and connect language, images, 3D, and actions.
Huang stated that Cosmos can achieve several physical AI skills, such as generating content, performing reasoning, and predicting trajectories (even if only given a single image). It can generate realistic videos based on 3D scenes, generate physically plausible motion based on driving data, and even generate panoramic videos from simulators, multi-camera footage, or text descriptions. It can even还原 (recreate) rare scenarios.
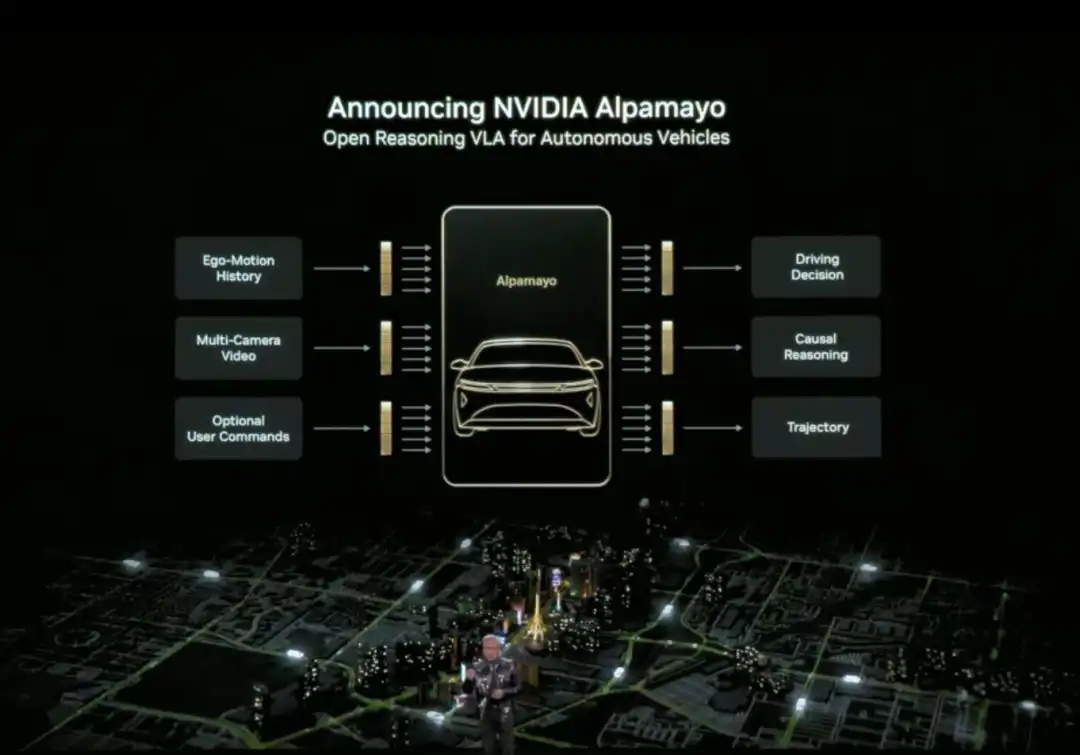
Huang also officially released Alpamayo. Alpamayo is an open-source toolchain for the autonomous driving domain, and the first open-source vision-language-action (VLA) reasoning model. Unlike previous open-sourcing of only code, NVIDIA this time open-sourced the complete development resources from data to deployment.
Alpamayo's biggest breakthrough is that it is a "reasoning" autonomous driving model. Traditional autonomous driving systems follow a "perception-planning-control" pipeline architecture—see a red light and brake, see a pedestrian and slow down, following preset rules. Alpamayo introduces "reasoning" capability, understanding causal relationships in complex scenes, predicting the intentions of other vehicles and pedestrians, and even handling decisions requiring multi-step thinking.
For example, at an intersection, it doesn't just recognize "there's a car ahead", but can reason "that car might be turning left, so I should wait for it to go first". This capability upgrades autonomous driving from "driving by rules" to "thinking like a human".
Huang announced that the NVIDIA DRIVE system has officially entered the mass production phase, with the first application being the new Mercedes-Benz CLA, planned to hit US roads in 2026. This vehicle will be equipped with an L2++ level autonomous driving system, adopting a hybrid architecture of "end-to-end AI model + traditional pipeline".
The robotics field also saw substantial progress.
Huang stated that leading global robotics companies, including Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics, and XRlabs, are developing products based on the NVIDIA Isaac platform and the GR00T foundation model, covering various fields from industrial robots and surgical robots to humanoid robots and consumer robots.

During the launch event, Huang stood in front of a stage filled with robots of different forms and用途 (purposes), displayed on a tiered platform: from humanoid robots, bipedal and wheeled service robots, to industrial robotic arms, engineering machinery, drones, and surgical assist devices, presenting a "robotics ecosystem landscape".
From Physical AI applications to the Rubin AI computing platform, to the Inference Context Memory Storage platform and the open-source AI "full stack".
These actions showcased by NVIDIA at CES constitute NVIDIA's narrative for推理时代 AI 基础设施 (AI infrastructure for the reasoning era). As Huang repeatedly emphasized, when Physical AI needs to think continuously, run persistently, and truly enter the real world, the problem is no longer just about whether there's enough compute power, but about who can actually build the entire system.
At CES 2026, NVIDIA has provided an answer.
Preguntas relacionadas
QWhat are the three main topics of Jensen Huang's CES 2026 keynote?


AThe three main topics are: 1) Reconstructing computing, networking, and storage architecture around long-term inference needs with the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the inference context memory storage platform. 2) Placing reasoning/agentic AI at the core through models and tools like Alpamayo, Nemotron, and Cosmos Reason. 3) Directly applying these capabilities to physical AI scenarios like autonomous driving and robotics.
QWhat is the key innovation of the Rubin GPU architecture and its primary goal?
AThe key innovation of the Rubin GPU architecture is its ability to handle more inference tasks and longer context within a single GPU, facilitated by a significant performance leap over Blackwell. Its primary goal is to 'make AI cheaper and smarter to use' by dramatically reducing the cost of inference and the number of GPUs required for many tasks.
QWhat problem does the Inference Context Memory Storage Platform solve, and what are its core components?
AIt solves the 'storage bottleneck' problem, where context data (KV Cache) from multi-step AI reasoning tasks traditionally had to be stored in expensive, limited GPU memory or slow conventional storage. Its core components are the BlueField-4 DPU (for hardware-accelerated data management), Spectrum-X Ethernet (for high-performance networking), and software components like DOCA, NIXL, and Dynamo for system optimization.
QWhat major advancement did NVIDIA announce for the autonomous driving sector?
ANVIDIA announced the official entry of its DRIVE system into mass production, with the first application being the new Mercedes-Benz CLA, planned for US roads in 2026. They also open-sourced Alpamayo, the first visual-language-action (VLA) reasoning model for autonomous driving, which introduces causal reasoning and multi-step decision-making capabilities.
QWhat is the significance of the new DGX SuperPOD based on the Rubin architecture?
AThe new DGX SuperPOD scales the Rubin architecture from a single rack (NVL72 with 72 GPUs) to a data-center-scale solution. Composed of 8 NVL72 racks for a total of 576 GPUs, it provides an 'out-of-the-box' massive AI computing cluster for training ultra-large models or serving thousands of Agentic AI agents, managed by the NVIDIA Mission Control software.
Lecturas Relacionadas




Trading
Artículos destacados
Qué es $S$
Entendiendo SPERO: Una Visión General Completa Introducción a SPERO A medida que el panorama de la innovación sigue evolucionando, la aparición de tecnologías web3 y proyectos de criptomonedas juega un papel fundamental en la configuración del futuro digital. Un proyecto que ha llamado la atención en este campo dinámico es SPERO, denotado como SPERO,$$s$. Este artículo tiene como objetivo recopilar y presentar información detallada sobre SPERO, para ayudar a entusiastas e inversores a comprender sus fundamentos, objetivos e innovaciones dentro de los dominios web3 y cripto. ¿Qué es SPERO,$$s$? SPERO,$$s$ es un proyecto único dentro del espacio cripto que busca aprovechar los principios de descentralización y tecnología blockchain para crear un ecosistema que promueva la participación, la utilidad y la inclusión financiera. El proyecto está diseñado para facilitar interacciones entre pares de nuevas maneras, proporcionando a los usuarios soluciones y servicios financieros innovadores. En su esencia, SPERO,$$s$ tiene como objetivo empoderar a los individuos al proporcionar herramientas y plataformas que mejoren la experiencia del usuario en el espacio de las criptomonedas. Esto incluye habilitar métodos de transacción más flexibles, fomentar iniciativas impulsadas por la comunidad y crear caminos para oportunidades financieras a través de aplicaciones descentralizadas (dApps). La visión subyacente de SPERO,$$s$ gira en torno a la inclusividad, buscando cerrar brechas dentro de las finanzas tradicionales mientras aprovecha los beneficios de la tecnología blockchain. ¿Quién es el Creador de SPERO,$$s$? La identidad del creador de SPERO,$$s$ sigue siendo algo oscura, ya que hay recursos públicos limitados que proporcionan información de fondo detallada sobre su(s) fundador(es). Esta falta de transparencia puede derivarse del compromiso del proyecto con la descentralización, una ética que muchos proyectos web3 comparten, priorizando las contribuciones colectivas sobre el reconocimiento individual. Al centrar las discusiones en torno a la comunidad y sus objetivos colectivos, SPERO,$$s$ encarna la esencia del empoderamiento sin señalar a individuos específicos. Como tal, entender la ética y la misión de SPERO es más importante que identificar a un creador singular. ¿Quiénes son los Inversores de SPERO,$$s$? SPERO,$$s$ cuenta con el apoyo de una diversa gama de inversores que van desde capitalistas de riesgo hasta inversores ángeles dedicados a fomentar la innovación en el sector cripto. El enfoque de estos inversores generalmente se alinea con la misión de SPERO, priorizando proyectos que prometen avances tecnológicos sociales, inclusividad financiera y gobernanza descentralizada. Estas fundaciones de inversores suelen estar interesadas en proyectos que no solo ofrecen productos innovadores, sino que también contribuyen positivamente a la comunidad blockchain y sus ecosistemas. El respaldo de estos inversores refuerza a SPERO,$$s$ como un contendiente notable en el rápidamente evolutivo dominio de los proyectos cripto. ¿Cómo Funciona SPERO,$$s$? SPERO,$$s$ emplea un marco multifacético que lo distingue de los proyectos de criptomonedas convencionales. Aquí hay algunas de las características clave que subrayan su singularidad e innovación: Gobernanza Descentralizada: SPERO,$$s$ integra modelos de gobernanza descentralizada, empoderando a los usuarios para participar activamente en los procesos de toma de decisiones sobre el futuro del proyecto. Este enfoque fomenta un sentido de propiedad y responsabilidad entre los miembros de la comunidad. Utilidad del Token: SPERO,$$s$ utiliza su propio token de criptomoneda, diseñado para servir a diversas funciones dentro del ecosistema. Estos tokens permiten transacciones, recompensas y la facilitación de servicios ofrecidos en la plataforma, mejorando la participación y utilidad general. Arquitectura en Capas: La arquitectura técnica de SPERO,$$s$ soporta la modularidad y escalabilidad, permitiendo la integración fluida de características y aplicaciones adicionales a medida que el proyecto evoluciona. Esta adaptabilidad es fundamental para mantener la relevancia en el siempre cambiante paisaje cripto. Participación de la Comunidad: El proyecto enfatiza iniciativas impulsadas por la comunidad, empleando mecanismos que incentivan la colaboración y la retroalimentación. Al nutrir una comunidad sólida, SPERO,$$s$ puede abordar mejor las necesidades de los usuarios y adaptarse a las tendencias del mercado. Enfoque en la Inclusión: Al ofrecer tarifas de transacción bajas y interfaces amigables para el usuario, SPERO,$$s$ busca atraer a una base de usuarios diversa, incluyendo a individuos que anteriormente pueden no haber participado en el espacio cripto. Este compromiso con la inclusión se alinea con su misión general de empoderamiento a través de la accesibilidad. Cronología de SPERO,$$s$ Entender la historia de un proyecto proporciona información crucial sobre su trayectoria de desarrollo y hitos. A continuación, se presenta una cronología sugerida que mapea eventos significativos en la evolución de SPERO,$$s$: Fase de Conceptualización e Ideación: Las ideas iniciales que forman la base de SPERO,$$s$ fueron concebidas, alineándose estrechamente con los principios de descentralización y enfoque comunitario dentro de la industria blockchain. Lanzamiento del Whitepaper del Proyecto: Tras la fase conceptual, se publicó un whitepaper completo que detalla la visión, objetivos e infraestructura tecnológica de SPERO,$$s$ para generar interés y retroalimentación de la comunidad. Construcción de Comunidad y Primeras Interacciones: Se realizaron esfuerzos de divulgación activa para construir una comunidad de primeros adoptantes e inversores potenciales, facilitando discusiones en torno a los objetivos del proyecto y obteniendo apoyo. Evento de Generación de Tokens: SPERO,$$s$ llevó a cabo un evento de generación de tokens (TGE) para distribuir sus tokens nativos a los primeros seguidores y establecer liquidez inicial dentro del ecosistema. Lanzamiento de la dApp Inicial: La primera aplicación descentralizada (dApp) asociada con SPERO,$$s$ se puso en marcha, permitiendo a los usuarios interactuar con las funcionalidades centrales de la plataforma. Desarrollo Continuo y Alianzas: Actualizaciones y mejoras continuas en las ofertas del proyecto, incluyendo alianzas estratégicas con otros actores en el espacio blockchain, han moldeado a SPERO,$$s$ en un jugador competitivo y en evolución en el mercado cripto. Conclusión SPERO,$$s$ se erige como un testimonio del potencial de web3 y las criptomonedas para revolucionar los sistemas financieros y empoderar a los individuos. Con un compromiso con la gobernanza descentralizada, la participación comunitaria y funcionalidades diseñadas de manera innovadora, allana el camino hacia un paisaje financiero más inclusivo. Como con cualquier inversión en el rápidamente evolutivo espacio cripto, se anima a los potenciales inversores y usuarios a investigar a fondo y participar de manera reflexiva con los desarrollos en curso dentro de SPERO,$$s$. El proyecto muestra el espíritu innovador de la industria cripto, invitando a una exploración más profunda de sus innumerables posibilidades. Aunque el viaje de SPERO,$$s$ aún se está desarrollando, sus principios fundamentales pueden, de hecho, influir en el futuro de cómo interactuamos con la tecnología, las finanzas y entre nosotros en ecosistemas digitales interconectados.
74 Vistas totalesPublicado en 2024.12.17Actualizado en 2024.12.17


Qué es AGENT S
Agent S: El Futuro de la Interacción Autónoma en Web3 Introducción En el paisaje en constante evolución de Web3 y las criptomonedas, las innovaciones están redefiniendo continuamente cómo los individuos interactúan con las plataformas digitales. Uno de estos proyectos pioneros, Agent S, promete revolucionar la interacción humano-computadora a través de su marco agente abierto. Al allanar el camino para interacciones autónomas, Agent S tiene como objetivo simplificar tareas complejas, ofreciendo aplicaciones transformadoras en inteligencia artificial (IA). Esta exploración detallada se adentrará en las complejidades del proyecto, sus características únicas y las implicaciones para el dominio de las criptomonedas. ¿Qué es Agent S? Agent S se presenta como un marco agente abierto revolucionario, diseñado específicamente para abordar tres desafíos fundamentales en la automatización de tareas informáticas: Adquisición de Conocimiento Específico del Dominio: El marco aprende de manera inteligente a partir de diversas fuentes de conocimiento externas y experiencias internas. Este enfoque dual le permite construir un rico repositorio de conocimiento específico del dominio, mejorando su rendimiento en la ejecución de tareas. Planificación a Largo Plazo de Tareas: Agent S emplea planificación jerárquica aumentada por la experiencia, un enfoque estratégico que facilita la descomposición y ejecución eficiente de tareas intrincadas. Esta característica mejora significativamente su capacidad para gestionar múltiples subtareas de manera eficiente y efectiva. Manejo de Interfaces Dinámicas y No Uniformes: El proyecto introduce la Interfaz Agente-Computadora (ACI), una solución innovadora que mejora la interacción entre agentes y usuarios. Utilizando Modelos de Lenguaje Multimodal Grandes (MLLMs), Agent S puede navegar y manipular diversas interfaces gráficas de usuario sin problemas. A través de estas características pioneras, Agent S proporciona un marco robusto que aborda las complejidades involucradas en la automatización de la interacción humana con las máquinas, preparando el terreno para innumerables aplicaciones en IA y más allá. ¿Quién es el Creador de Agent S? Aunque el concepto de Agent S es fundamentalmente innovador, la información específica sobre su creador sigue siendo elusiva. El creador es actualmente desconocido, lo que resalta ya sea la etapa incipiente del proyecto o la elección estratégica de mantener a los miembros fundadores en el anonimato. Independientemente de la anonimidad, el enfoque sigue siendo las capacidades y el potencial del marco. ¿Quiénes son los Inversores de Agent S? Dado que Agent S es relativamente nuevo en el ecosistema criptográfico, la información detallada sobre sus inversores y patrocinadores financieros no está documentada explícitamente. La falta de información disponible públicamente sobre las bases de inversión u organizaciones que apoyan el proyecto plantea preguntas sobre su estructura de financiamiento y hoja de ruta de desarrollo. Comprender el respaldo es crucial para evaluar la sostenibilidad del proyecto y su posible impacto en el mercado. ¿Cómo Funciona Agent S? En el núcleo de Agent S se encuentra tecnología de vanguardia que le permite funcionar de manera efectiva en diversos entornos. Su modelo operativo se basa en varias características clave: Interacción Humano-Computadora: El marco ofrece planificación avanzada de IA, esforzándose por hacer que las interacciones con las computadoras sean más intuitivas. Al imitar el comportamiento humano en la ejecución de tareas, promete elevar las experiencias de los usuarios. Memoria Narrativa: Empleada para aprovechar experiencias de alto nivel, Agent S utiliza memoria narrativa para hacer un seguimiento de las historias de tareas, mejorando así sus procesos de toma de decisiones. Memoria Episódica: Esta característica proporciona a los usuarios orientación paso a paso, permitiendo que el marco ofrezca apoyo contextual a medida que se desarrollan las tareas. Soporte para OpenACI: Con la capacidad de funcionar localmente, Agent S permite a los usuarios mantener el control sobre sus interacciones y flujos de trabajo, alineándose con la ética descentralizada de Web3. Fácil Integración con APIs Externas: Su versatilidad y compatibilidad con diversas plataformas de IA aseguran que Agent S pueda integrarse sin problemas en ecosistemas tecnológicos existentes, convirtiéndolo en una opción atractiva para desarrolladores y organizaciones. Estas funcionalidades contribuyen colectivamente a la posición única de Agent S dentro del espacio cripto, ya que automatiza tareas complejas y de múltiples pasos con una intervención humana mínima. A medida que el proyecto evoluciona, sus aplicaciones potenciales en Web3 podrían redefinir cómo se desarrollan las interacciones digitales. Cronología de Agent S El desarrollo y los hitos de Agent S pueden encapsularse en una cronología que destaca sus eventos significativos: 27 de septiembre de 2024: Se lanzó el concepto de Agent S en un documento de investigación integral titulado “Un Marco Agente Abierto que Utiliza Computadoras como un Humano”, mostrando las bases del proyecto. 10 de octubre de 2024: El documento de investigación se hizo disponible públicamente en arXiv, ofreciendo una exploración en profundidad del marco y su evaluación de rendimiento basada en el benchmark OSWorld. 12 de octubre de 2024: Se publicó una presentación en video, proporcionando una visión visual de las capacidades y características de Agent S, involucrando aún más a posibles usuarios e inversores. Estos hitos en la cronología no solo ilustran el progreso de Agent S, sino que también indican su compromiso con la transparencia y el compromiso comunitario. Puntos Clave Sobre Agent S A medida que el marco Agent S continúa evolucionando, varios atributos clave destacan, subrayando su naturaleza innovadora y potencial: Marco Innovador: Diseñado para proporcionar un uso intuitivo de las computadoras similar a la interacción humana, Agent S aporta un enfoque novedoso a la automatización de tareas. Interacción Autónoma: La capacidad de interactuar de manera autónoma con las computadoras a través de GUI significa un avance hacia soluciones informáticas más inteligentes y eficientes. Automatización de Tareas Complejas: Con su metodología robusta, puede automatizar tareas complejas y de múltiples pasos, haciendo que los procesos sean más rápidos y menos propensos a errores. Mejora Continua: Los mecanismos de aprendizaje permiten a Agent S mejorar a partir de experiencias pasadas, mejorando continuamente su rendimiento y eficacia. Versatilidad: Su adaptabilidad en diferentes entornos operativos como OSWorld y WindowsAgentArena asegura que pueda servir a una amplia gama de aplicaciones. A medida que Agent S se posiciona en el paisaje de Web3 y criptomonedas, su potencial para mejorar las capacidades de interacción y automatizar procesos significa un avance significativo en las tecnologías de IA. A través de su marco innovador, Agent S ejemplifica el futuro de las interacciones digitales, prometiendo una experiencia más fluida y eficiente para los usuarios en diversas industrias. Conclusión Agent S representa un audaz avance en la unión de la IA y Web3, con la capacidad de redefinir cómo interactuamos con la tecnología. Aunque aún se encuentra en sus primeras etapas, las posibilidades para su aplicación son vastas y atractivas. A través de su marco integral que aborda desafíos críticos, Agent S tiene como objetivo llevar las interacciones autónomas al primer plano de la experiencia digital. A medida que nos adentramos más en los reinos de las criptomonedas y la descentralización, proyectos como Agent S sin duda desempeñarán un papel crucial en la configuración del futuro de la tecnología y la colaboración humano-computadora.
221 Vistas totalesPublicado en 2025.01.14Actualizado en 2025.01.14
Cómo comprar S
¡Bienvenido a HTX.com! Hemos hecho que comprar Sonic (S) sea simple y conveniente. Sigue nuestra guía paso a paso para iniciar tu viaje de criptos.Paso 1: crea tu cuenta HTXUtiliza tu correo electrónico o número de teléfono para registrarte y obtener una cuenta gratuita en HTX. Experimenta un proceso de registro sin complicaciones y desbloquea todas las funciones.Obtener mi cuentaPaso 2: ve a Comprar cripto y elige tu método de pagoTarjeta de crédito/débito: usa tu Visa o Mastercard para comprar Sonic (S) al instante.Saldo: utiliza fondos del saldo de tu cuenta HTX para tradear sin problemas.Terceros: hemos agregado métodos de pago populares como Google Pay y Apple Pay para mejorar la comodidad.P2P: tradear directamente con otros usuarios en HTX.Over-the-Counter (OTC): ofrecemos servicios personalizados y tipos de cambio competitivos para los traders.Paso 3: guarda tu Sonic (S)Después de comprar tu Sonic (S), guárdalo en tu cuenta HTX. Alternativamente, puedes enviarlo a otro lugar mediante transferencia blockchain o utilizarlo para tradear otras criptomonedas.Paso 4: tradear Sonic (S)Tradear fácilmente con Sonic (S) en HTX's mercado spot. Simplemente accede a tu cuenta, selecciona tu par de trading, ejecuta tus trades y monitorea en tiempo real. Ofrecemos una experiencia fácil de usar tanto para principiantes como para traders experimentados.
261 Vistas totalesPublicado en 2025.01.15Actualizado en 2025.03.21



