Just now, Anthropic officially released the new model Claude Sonnet 5, calling it "the most Agentic Sonnet model to date." It can formulate plans, use tools like browsers and terminals, and operate autonomously at a level that, just months ago, required larger and more expensive models.
Sonnet 5 shows significant performance improvements over Sonnet 4.6 in reasoning, tool use, programming, and knowledge work, coming closer to Opus 4.8 while being more affordable.
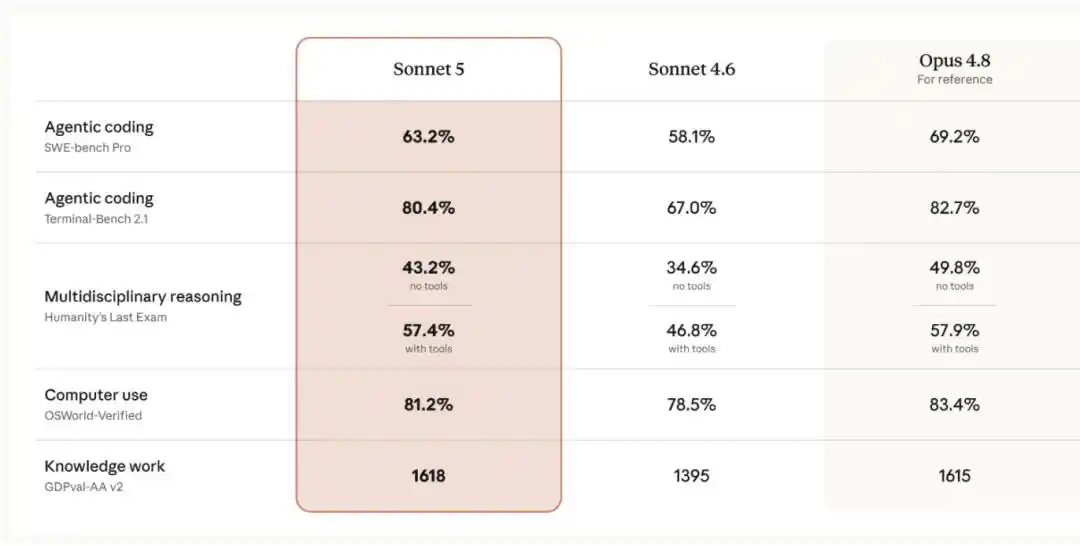
According to the official announcement, for developers, the AI Agent era truly began with Sonnet-level models: Claude Sonnet 3.5, 3.6, and 3.7 were among the first models to show impressive capabilities in programming and tool use. However, in recent times, the most notable advancements in Agentic capabilities have primarily appeared in Opus-level models.
Claude Sonnet 5 significantly narrows this gap: its performance is now close to Opus 4.8, but at a lower price. Compared to its predecessor Sonnet 4.6, it shows substantial improvements across key dimensions of Agentic performance like reasoning, tool use, programming, and knowledge work. A detailed comparison is shown below:
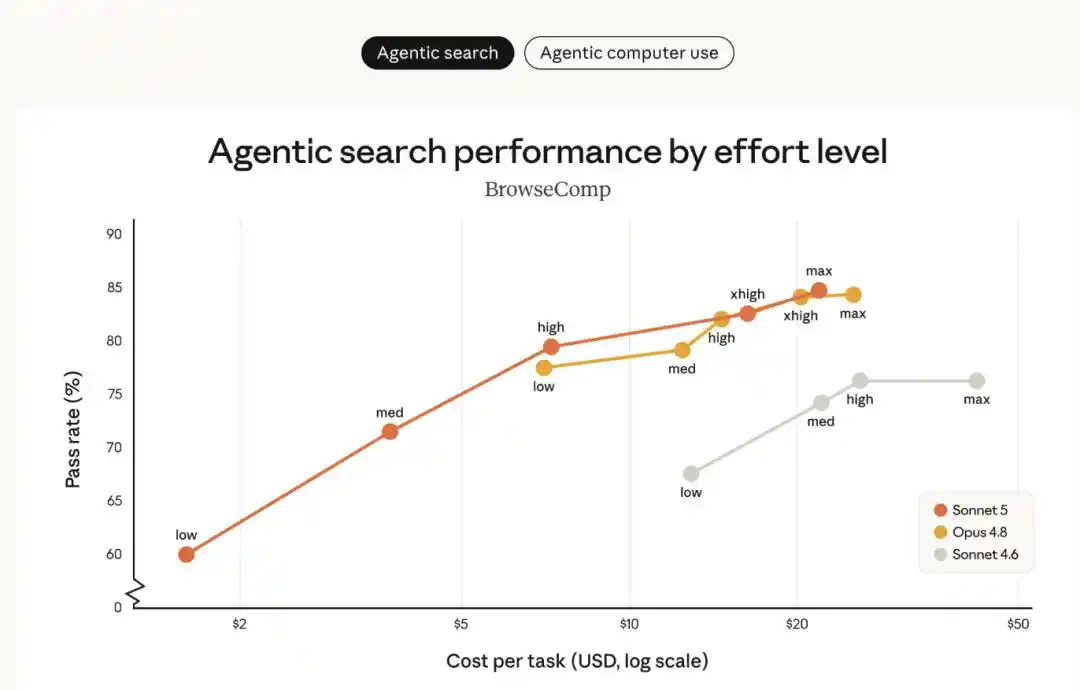
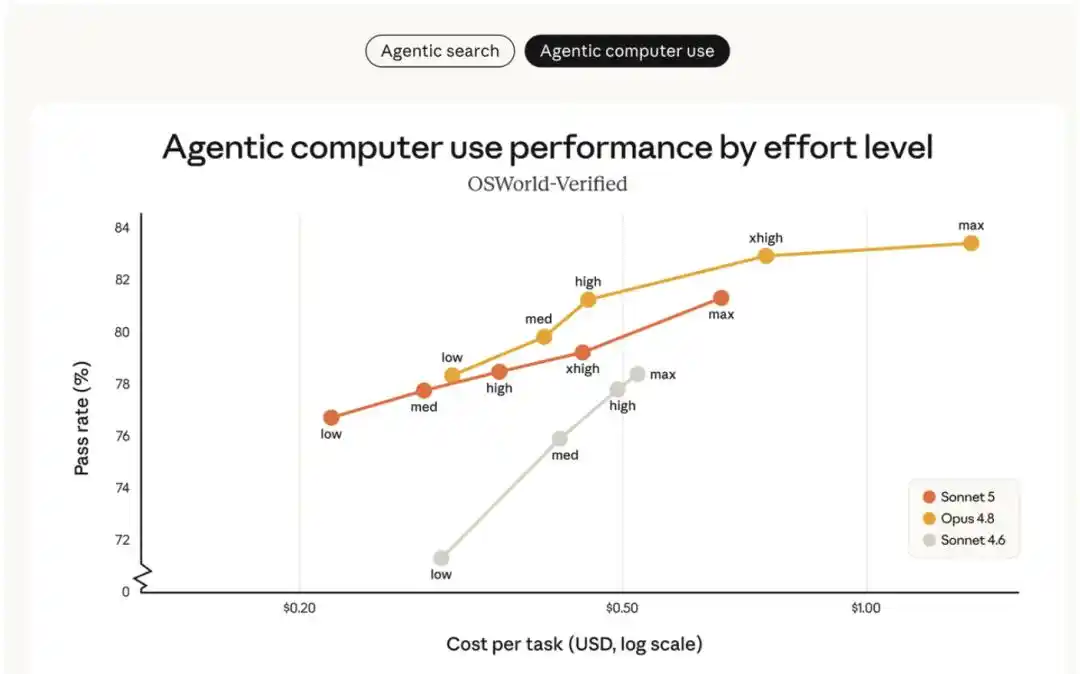
The chart below compares Sonnet 5, Sonnet 4.6, and Opus 4.8 on the Agentic search benchmark BrowseComp and the computer use benchmark OSWorld-Verified, at different "effort levels":
- Sonnet 5 (orange line) shows a clear performance improvement over Sonnet 4.6 (gray line) and offers a broader range of cost-performance options than Opus 4.8 (yellow line).
- At medium effort levels, Sonnet 5 significantly improves cost efficiency; at higher effort levels, its performance can match Opus 4.8 on certain tasks.
- Between Sonnet 5 and Opus 4.8, users can flexibly adjust the effort level based on specific tasks to find the optimal balance between cost and performance for their needs.
The cost-performance curve at different effort levels is shown above. The previous best Sonnet model (Sonnet 4.6) was far from matching Opus 4.8. Sonnet 5 provides a wider range of cost-performance options than Sonnet 4.6 and can reach the capability level of Opus 4.8 in some scenarios. The Sonnet 5 pricing shown in the chart is input $3 / million tokens, output $15 / million tokens. With the introductory pricing valid until August 31st (input $2 / million tokens, output $10 / million tokens), the actual cost of Sonnet 5 is even lower than shown. Opus 4.8 pricing is input $5 / million tokens, output $25 / million tokens.
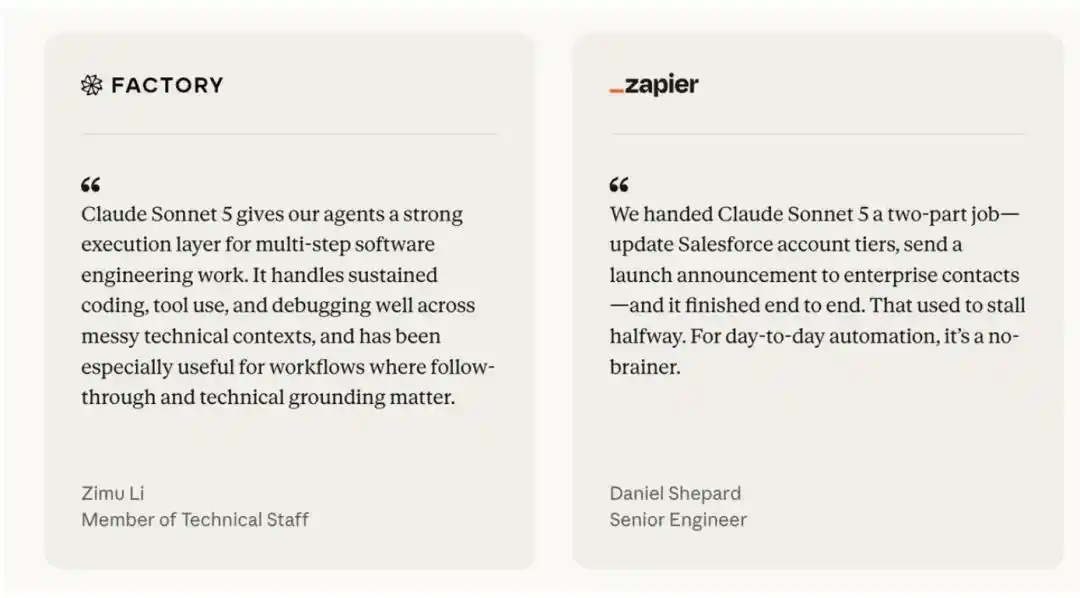
Feedback from Anthropic's early access partners has been consistent: Sonnet 5 is more capable as an autonomous agent (more agentic) than its predecessor. Testers describe it as capable of completing complex tasks — tasks where previous Sonnet models would get stuck; it proactively checks its own outputs without explicit prompting; and it accomplishes all this Agentic work at a highly attractive price:
Safety Evaluation
Anthropic's pre-deployment safety evaluations found that Sonnet 5 shows overall improvement compared to Sonnet 4.6. In terms of autonomous agent safety, the model performs better at rejecting malicious requests and resisting hijacking attempts in prompt injection attacks. The model's hallucination rate and sycophancy rate are both lower than Sonnet 4.6. In the automated behavioral audit (testing a wide range of misbehaviors, such as assisting abuse and deception), Sonnet 5 scored lower (i.e., was safer).
However, compared to the more capable Opus 4.8 and Claude Mythos Preview, it did show a slightly higher rate of misbehavior in this audit.
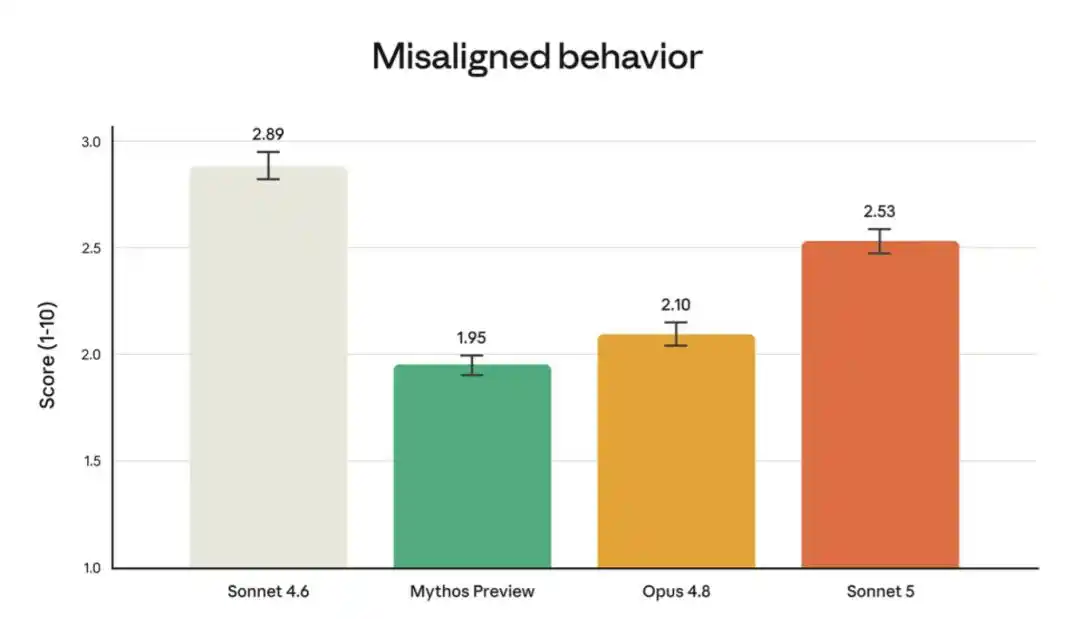
The chart above shows the misbehavior rate in the automated behavioral audit, which tests a large number of undesirable behaviors across various scenarios and contexts (see Section 6.4 of the Sonnet 5 System Card for the complete list and results per behavior). Sonnet 5's overall misbehavior rate is lower than Sonnet 4.6, but higher than Mythos Preview and Opus 4.8.
Anthropic states that they did not specifically train Sonnet 5 for cybersecurity tasks. It can perform some routine, harmless web tasks, but in evaluations of potentially dangerous cyber skills (like developing software exploit code), its performance is significantly weaker than models like Opus 4.8 and Mythos 5.
The chart below shows scores from one such evaluation, testing the model's ability to develop an exploit for a Firefox browser vulnerability. Sonnet 5 consistently failed to develop a fully functional exploit, but its partial success rate was slightly higher than Sonnet 4.6. The latter's improvement likely stems from general intelligence gains, not specific training.
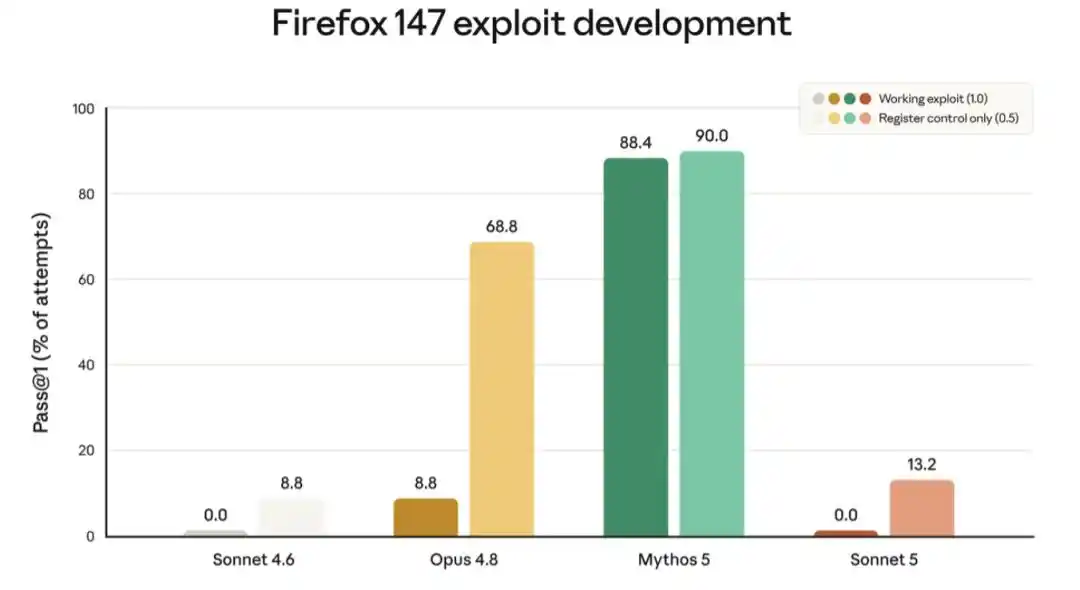
The chart above shows scores for models successfully developing an exploit for a software vulnerability in Firefox 147 (this evaluation was developed in collaboration with Mozilla; all vulnerabilities were patched in Firefox 148). For each model, the left bar indicates how often the model (without safety guardrails) developed a functional exploit, and the right bar indicates the frequency of partial success. Both Sonnet models failed to develop a functional exploit (score 0.0% each); Sonnet 5's partial success rate is slightly higher than Sonnet 4.6. Both Sonnet models' cyber capabilities are significantly weaker than Opus 4.8 and Mythos 5.
As Sonnet 5 is slightly more capable at these tasks than its predecessor, Anthropic has enabled cybersecurity guardrails by default. These guardrails — capable of detecting and blocking dangerous cyber use in real-time — are the same as those in Claude Opus 4.7 and 4.8 (because Anthropic judged Sonnet 5's overall cybersecurity risk to be low, its guardrails are less strict than those enabled for Fable 5 — which block a wider range of cybersecurity tasks).
Anthropic's complete assessment report for Sonnet 5 across multiple safety and capability evaluations can be found in the Claude Sonnet 5 System Card.
Pricing
Starting today, Claude Sonnet 5 is generally available across all channels. To celebrate the launch, Anthropic is offering a limited-time introductory price:
- From now until August 31, 2026: Input $2 / million tokens, Output $10 / million tokens
- Standard pricing after that: Input $3 / million tokens, Output $15 / million tokens
Simultaneously, they announced a comprehensive increase in rate limits for Chat, Cowork, Claude Code, and the Claude platform to accommodate the higher token consumption from higher "effort level" modes.
Important Notes
Cybersecurity Verification
Sonnet 5 has been included in Anthropic's "Cybersecurity Verification Program." The program is now available for use on the following platforms:
- Claude Native Platform
- Claude Platform on AWS
- Claude in Microsoft Foundry (hosted on Azure and by Anthropic)
Claude on Google Vertex will also support it soon.
Organizations already enrolled in the program automatically receive equivalent access for Sonnet 5, no re-application needed. If your cybersecurity work requires fewer safety guardrail restrictions, Anthropic recommends using Claude Opus 4.8.
Tokenizer Update & Pricing Explanation
Sonnet 5 is an upgrade to Sonnet 4.6 but uses a new tokenizer to optimize text processing performance (similar to the tokenizer change introduced with Claude Opus 4.7).
The consequence is: The same input text now maps to more tokens, with the increase being approximately 1.0x to 1.35x depending on the content type.
Accordingly, the introductory price has been set so that the overall cost of switching to Sonnet 5 remains roughly the same for users.
Rate Limit Adjustment Explanation
As early as April 26, 2026, Anthropic had already increased rate limits for Sonnet and Haiku models across all usage tiers and simplified the native Claude platform plans into three tiers: Start, Build, Scale.
With this update, Anthropic has further increased rate limits for Chat, Cowork, Claude Code, and the Claude platform to accommodate the higher token consumption from higher "effort level" modes.
You can view your current tier and specific limits in the Claude Console or consult the documentation for more details.
Benchmark Score Correction Explanation (Supplemental)
- Humanity’s Last Exam: Anthropic updated the scoring model for this benchmark and, based on that, revised Sonnet 4.6's score to 34.6% (without tools) and 46.8% (with tools). Therefore, this score differs from the data reported in the Sonnet 4.6 launch blog. This is noted for clarity.
- OSWorld‐Verified: Anthropic optimized the execution of this benchmark to better reflect the model's performance in real-world scenarios and revised Sonnet 4.6's score to 78.5%. This is also the reason this score differs from the data in the Sonnet 4.6 launch blog.
Developer Hands-on Feedback
As soon as Claude Sonnet 5 was released, people have already started testing it.
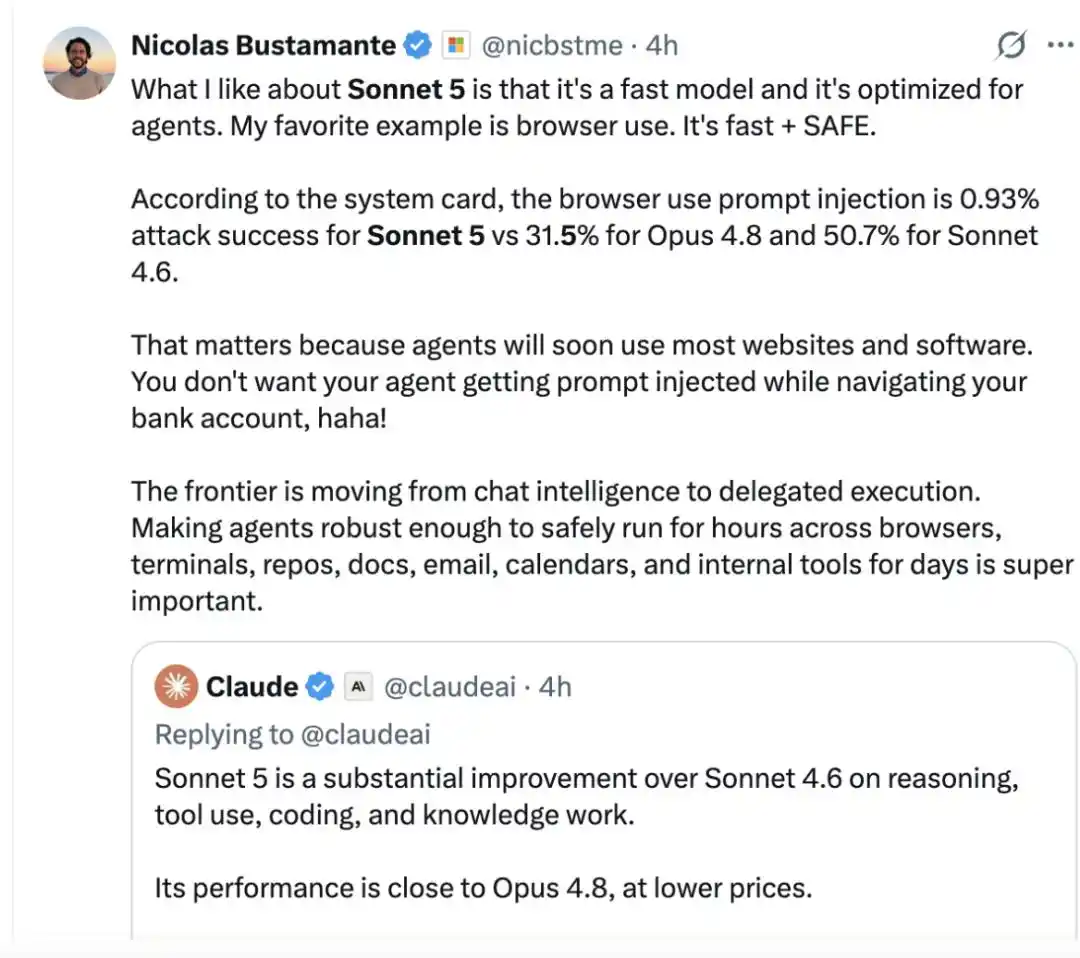
User Nicolas Bustamante said that one thing he likes about Sonnet 5 is that it's fast and optimized for Agents. "My favorite example is browser usage: fast and safe."
According to system card results, the success rate of prompt injection attacks in browser usage scenarios is only 0.93% for Sonnet 5, while it's 31.5% for Opus 4.8 and 50.7% for Sonnet 4.6.
However, some users commented, "Too expensive."
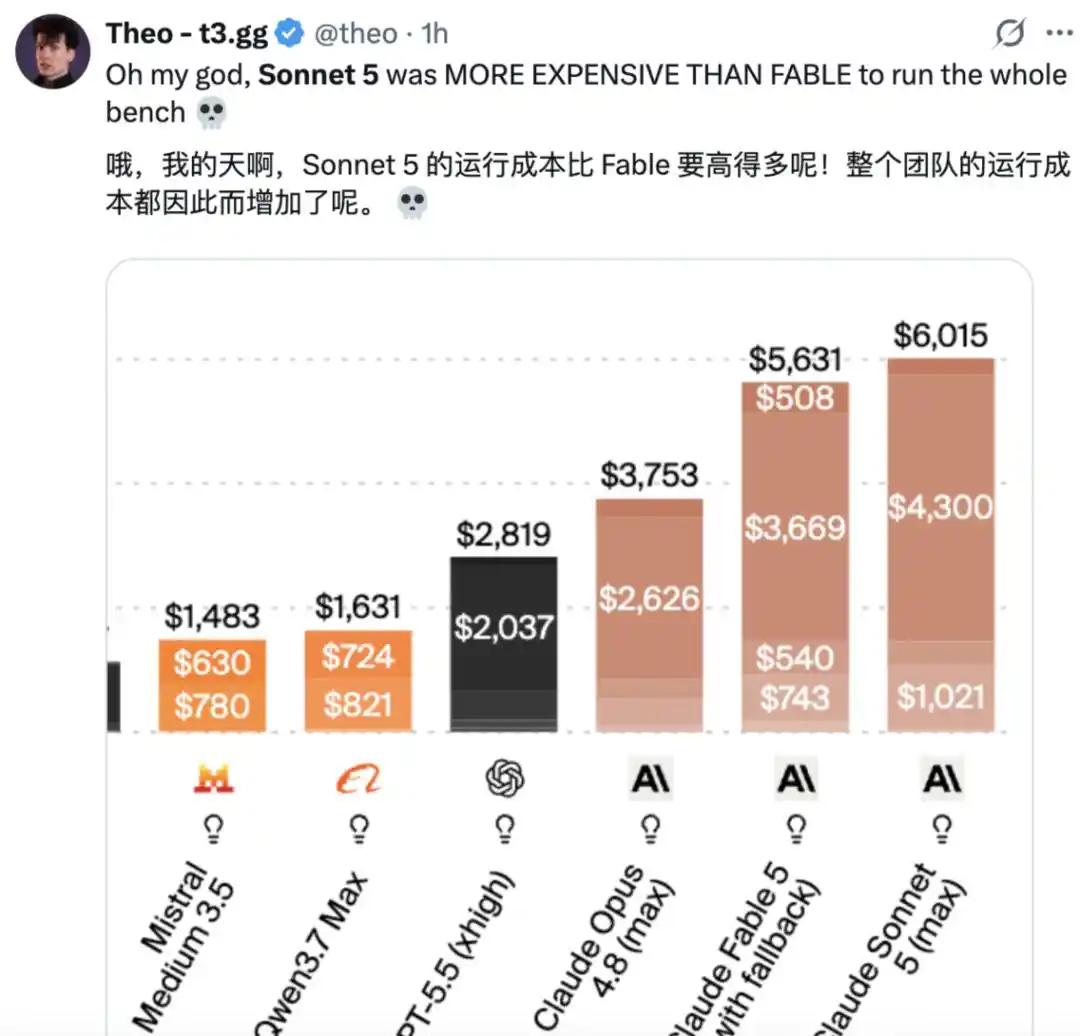
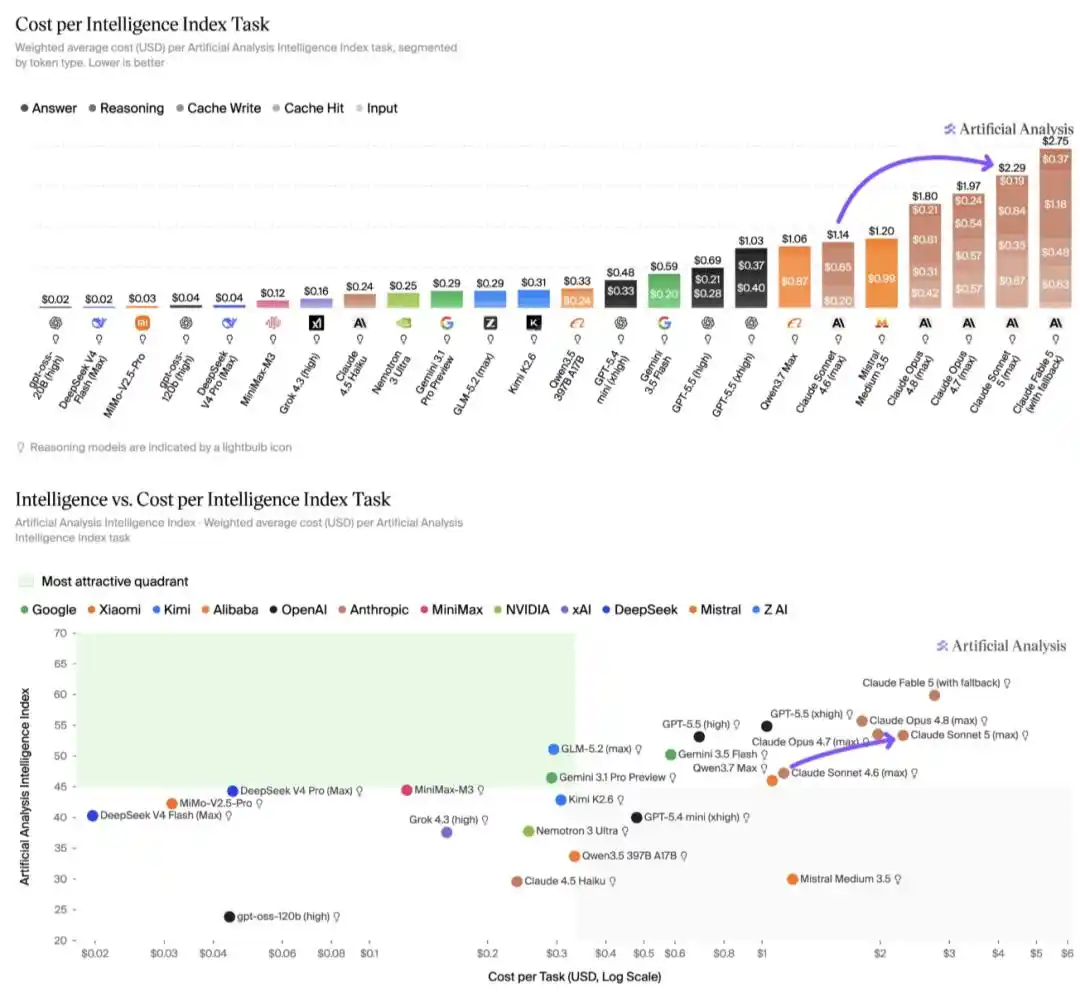
According to an analysis by Artificial Analysis, on the Intelligence Index, the run cost for Claude Sonnet 5 is $2.29 per task, an increase of about 2x compared to Sonnet 4.6, and also about 15% higher than Claude Opus 4.8. This cost increase is entirely driven by higher token usage, making Claude Sonnet 5 one of the most expensive models to run, second only to Claude Fable 5.
What about you? How do you feel about the new model? Feel free to leave comments and discuss below!
Reference Links:
https://x.com/claudeai/status/2072017450611142835
https://www.anthropic.com/news/claude-sonnet-5
https://x.com/ArtificialAnlys/status/2072062595482456431
This article is from the WeChat public account "Almost Human" (ID: almosthuman2014), author: following AI





