Is your impression of text-to-image still stuck on Nano Banana?
But kid, times have changed again.

@johnAGI168 https://x.com/johnAGI168/status/2044781168151724067

@0115hippo https://x.com/0115hippo/status/2044722124611539160
In early April, three anonymous image models, codenamed maskingtape-alpha, packingtape-alpha, and gaffertape-alpha, appeared on the LM Arena evaluation platform. They disappeared a few hours later.
OpenAI has not officially announced this model yet, but based on the metadata returned by the API and user-side testing records, it has already gained a widely accepted name: GPT Image 2.

Screenshots Can No Longer Be Used as Evidence
Over the past few years, one of the most obvious weaknesses of AI image generation models has been text within images. In the DALL-E 3 era, if you asked it to write "Hello" in an image, it might output "Hellp" or even "Hl10", with letters tilting drunkenly. GPT Image 1 improved a lot, handling simple English labels. By GPT Image 1.5, its accuracy in rendering English text was close to 95%, but it still had significant flaws with non-Latin scripts like Chinese, Japanese, and Korean.
But the leaked sample images from GPT Image 2 have changed this impression.
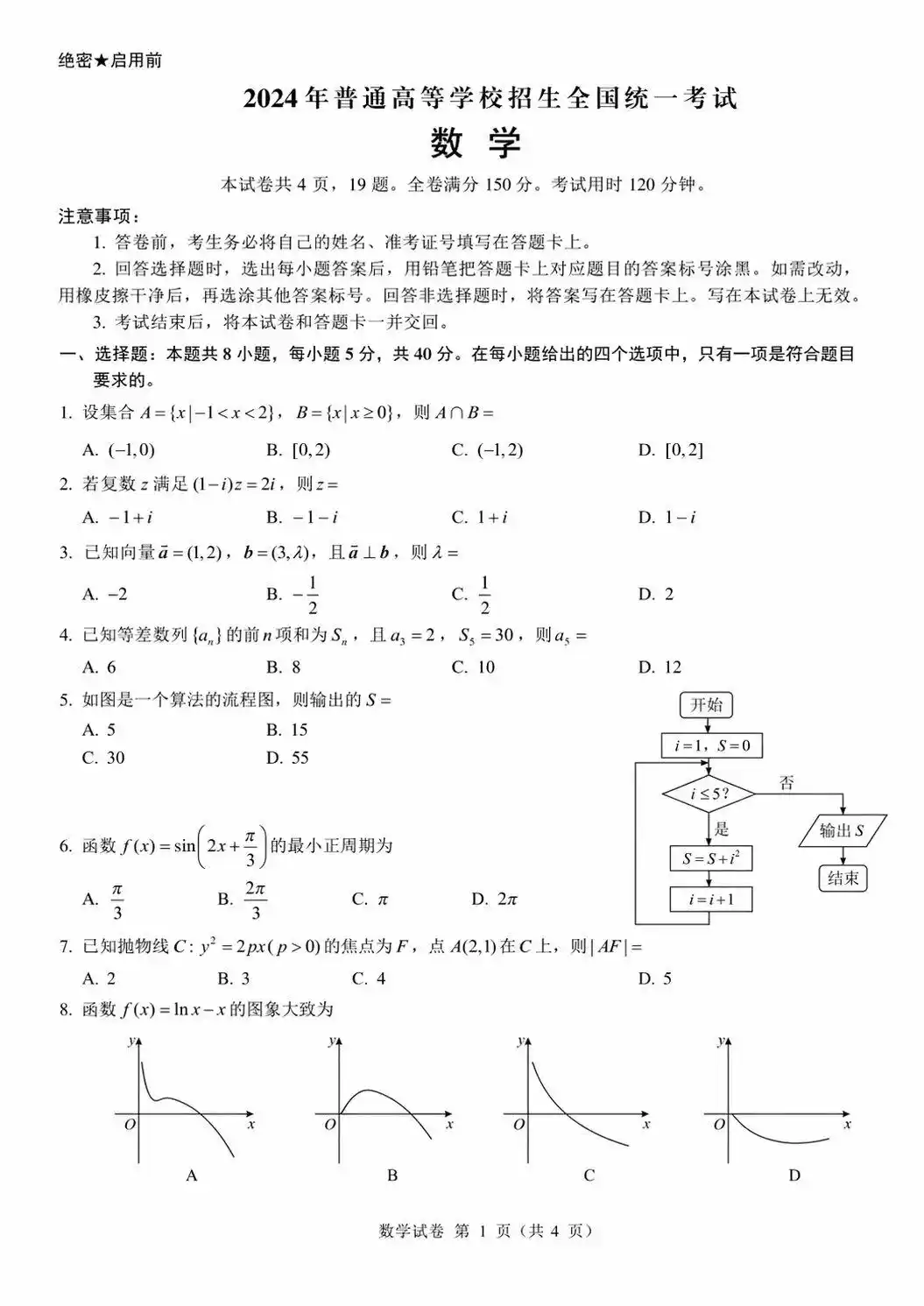

@MrLarus https://x.com/MrLarus/status/2044824800909054181
@akokoi1 https://x.com/akokoi1/status/2044789531615056175
The text in the images is exactly what it should be. Chinese characters are clear, with accurate glyphs and complete strokes. Someone tested generating an ID card-style image, where the name, address, and ID number were all rendered correctly, with neat formatting, looking at first glance like a photo of a real document.

This is good news. The improvement in text rendering means generating infographics, posters, product packaging, and complex charts becomes more reliable.
But there's always another side to the coin. A model that can generate photo-realistic ID-style images and precisely render UI screenshots naturally makes "screenshots can be used as evidence" increasingly questionable.
By comparison, this is also a core difference between the GPT Image series and other models. Midjourney still has no progress in text rendering, and the Stable Diffusion series also has this old problem. According to the leaked Arena test results, GPT Image 2 surpassed Midjourney in four dimensions: text rendering, instruction following, photorealism, and world knowledge. Midjourney's advantages are mainly retained in artistic style and aesthetic control.

Does It Really Know What the World Looks Like?
A tester asked the model to generate a hypothetical GPT-8 product pricing page. The resulting image had a layout that was indeed in the style of the OpenAI website, with button placement and font choices resembling those from a real interface, and the hierarchical logic of the price table was correct.
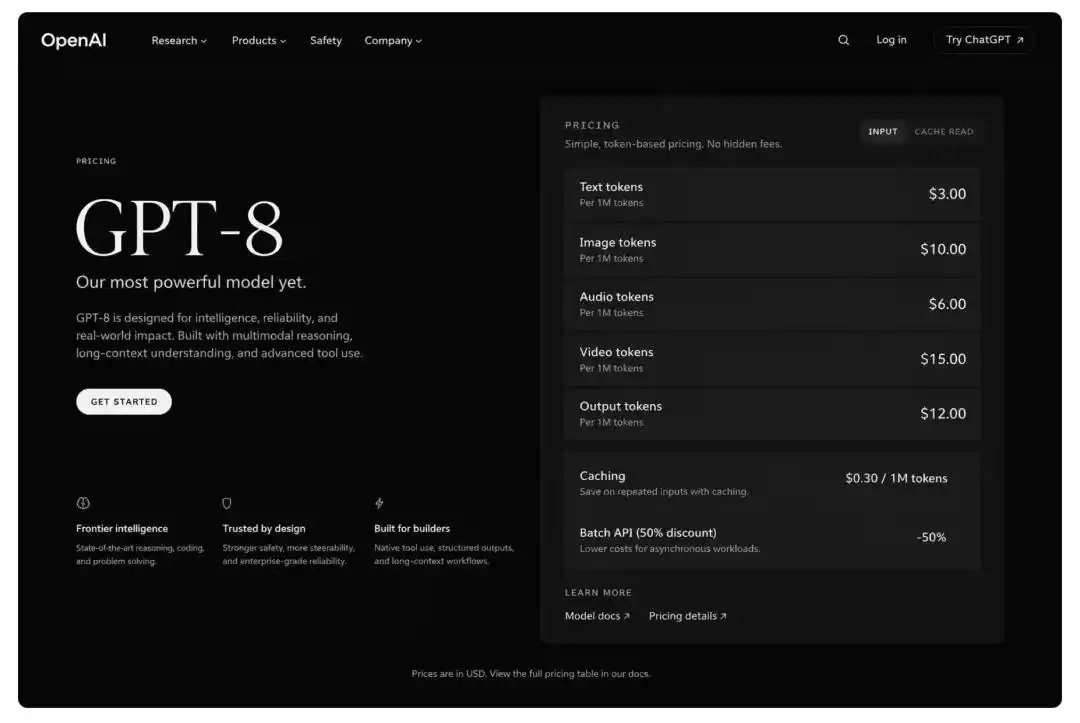
GPT Image 2 can generate images extremely similar to real software interfaces, including browser windows, mobile app interfaces, and data visualization charts, with a level of fidelity unmatched by the previous generation.
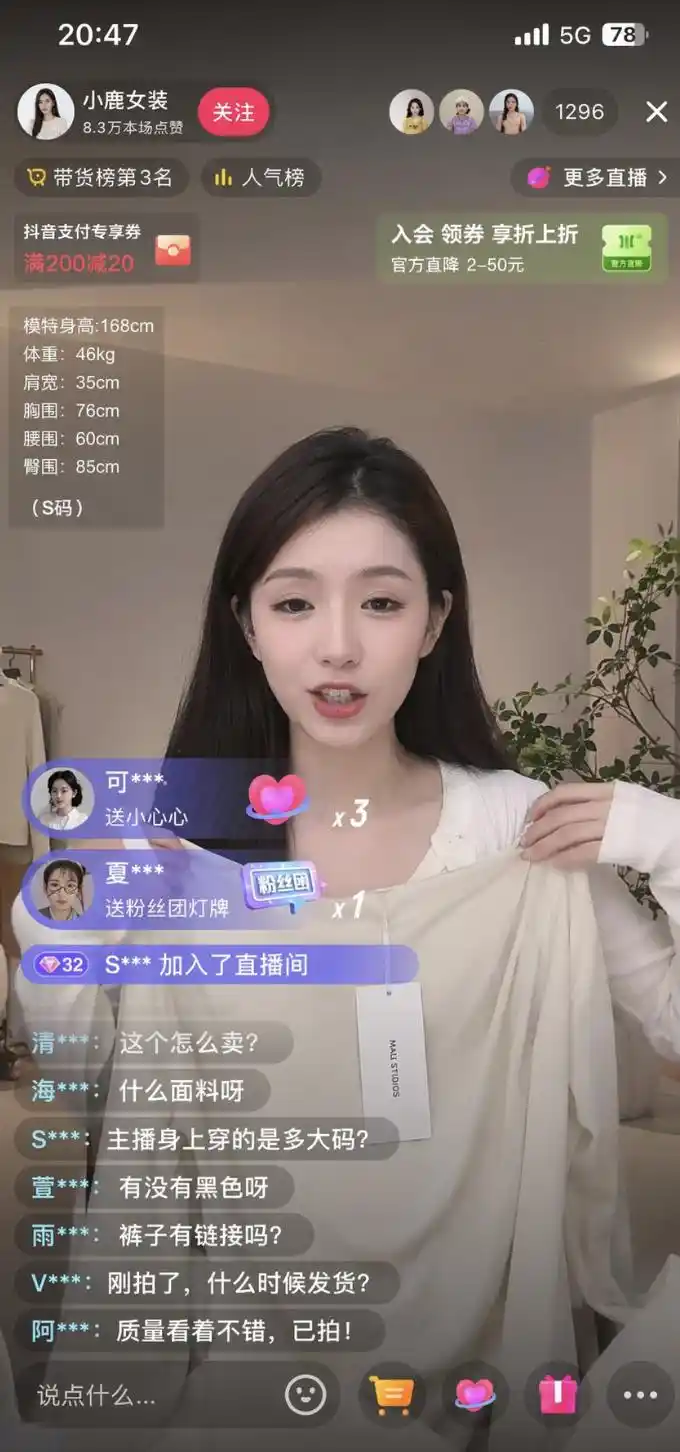
@johnAGI168 https://x.com/johnAGI168/status/2044781168151724067
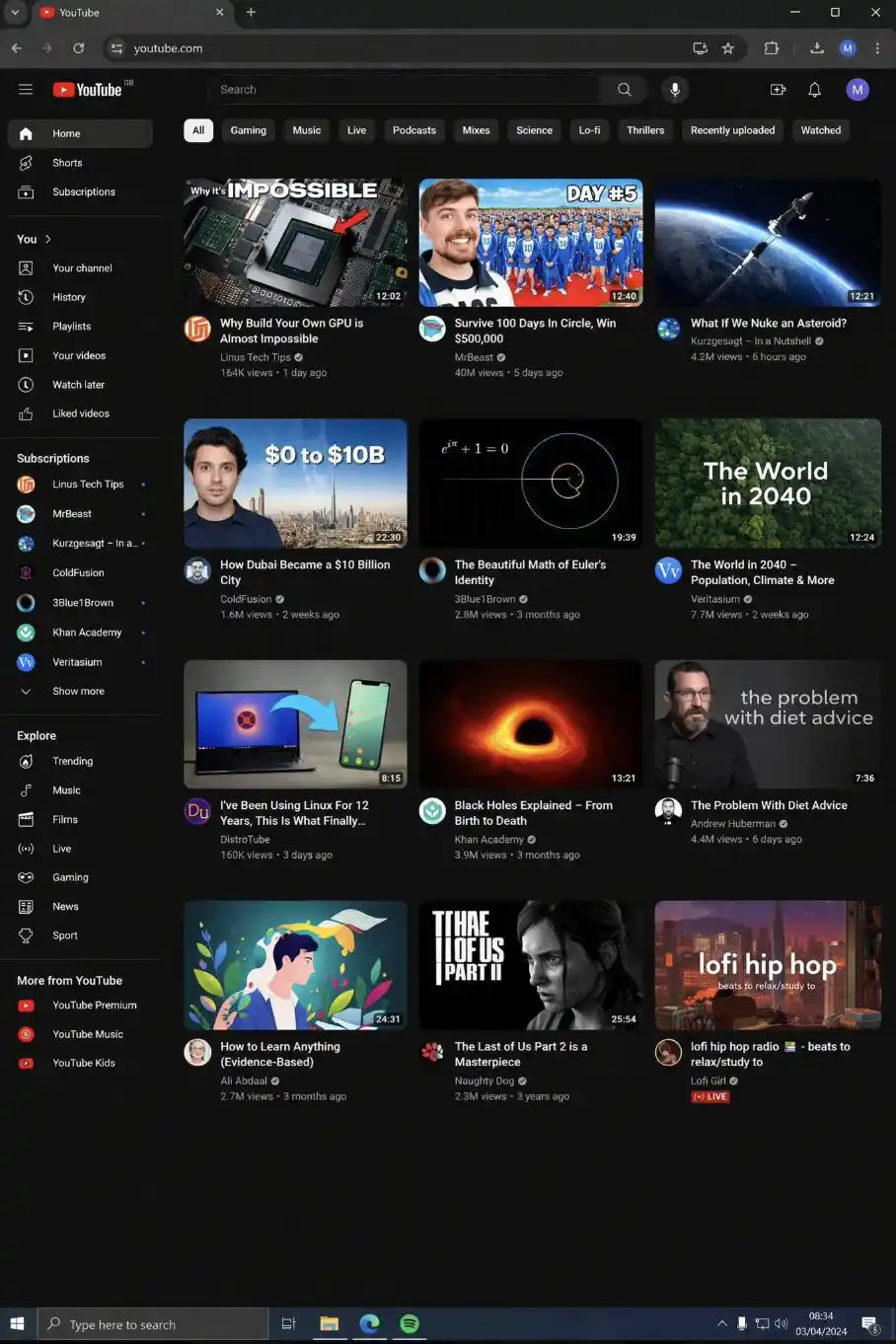
@levelsio https://x.com/levelsio/status/2040333489476681758
This will lead to some very interesting practical uses. When designers are creating product prototypes, they don't need to open Figma first and draw a bunch of wireframes; they can directly describe the desired interface in text, and the output is a reference image that can be used for team discussions. When creating investor decks, they can show a "product screenshot" without waiting for an engineer to write code. When writing documentation, example interface images for illustration can be generated directly, without having to think about where to find screenshots for a blank page.
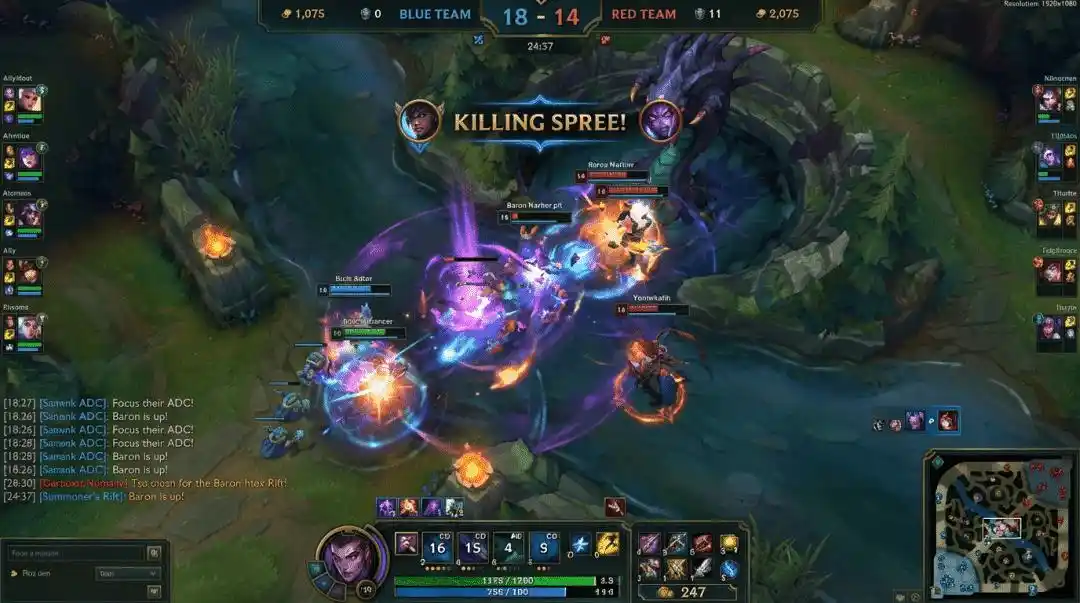

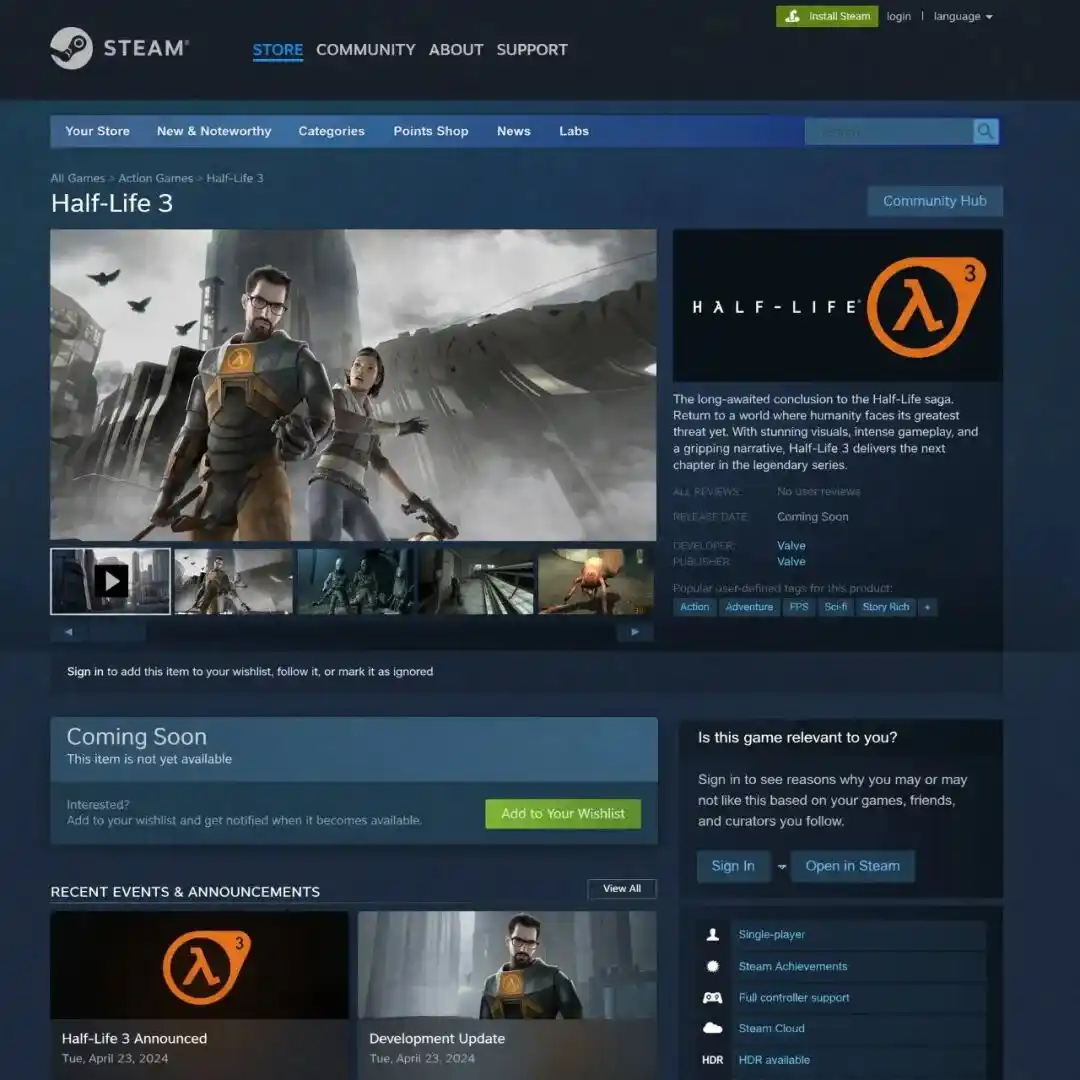
@marmaduke091 https://x.com/marmaduke091/status/2040338311873515597
Image Generation Is No Longer Just "Image Generation"
OpenAI has already announced that DALL-E 2 and DALL-E 3 will officially cease service on May 12, 2026. Azure OpenAI's DALL-E 3 was retired early in February.
DALL-E was the first place many people encountered AI image generation, from those blurry early works to today, in just a few short years.
Meanwhile, Google, which had just established its industry position with Nano Banana Pro in early 2026, might feel the pressure. Early test reports indicate that GPT Image 2 simultaneously surpasses Nano Banana Pro in three dimensions: realism, text rendering, and world knowledge. This kind of triple win is not common.
For creators, the feeling is complex. Illustrators, graphic designers, and photographers are not facing this topic for the first time. Since the release of GPT Image 1, the number of freelance graphic design positions has decreased by about 18%. AI has indeed replaced the decision to "hire someone to do this" in certain scenarios, but it is also creating new ways of working, allowing one person to do more.
The evolution speed of image generation models no longer leaves much time for adaptation. It was only a few months from GPT Image 1's launch to version 1.5. And from 1.5 to 2, it's only been about half a year. Each generation solves the core shortcomings of the previous one while opening up new possibilities.
GPT Image 2 is currently still in the A/B testing phase, with some ChatGPT users randomly gaining access. The official release window is widely predicted to be around May, coinciding with the retirement of DALL-E. If you want to experience it early, you can currently try your luck on the LM Arena evaluation platform.

Test Address: https://arena.ai
Based on community feedback and the known strengths of this model, the following prompt templates can maximize your chances of success:
UI/Screenshot Prompt: A photorealistic screenshot of a mobile banking app, clearly showing transaction history with dates, amounts, and merchant names legible. iPhone 16 screen, natural hand holding the phone, coffee shop background.
Product Label Prompt: A photographic product photo of a craft beer bottle, with clear label details showing the brewery name "Oakridge Brewing Co.", alcohol content 6.8%, a mountain logo, and an ingredient list. Studio lighting, white background.
Signage Prompt: A street scene photo of a Tokyo alley at night, showing multiple neon signs in both Japanese and English, including a ramen shop sign reading "Ichiban Ramen — Est. 1987", a karaoke bar sign, and various glowing advertisements. Wet, reflective pavement with light reflections.
Interface/World Knowledge Prompt: A photorealistic YouTube video screenshot showing a video titled "How to Assemble a Computer in 2026" with 2.3 million views, featuring realistic comments, sidebar video recommendations, and channel info. Desktop browser view.
Widescreen Trigger Prompt: A cinematic widescreen photo of an IKEA store exterior at dusk, showing the glowing IKEA sign, a parking lot with realistic cars, and shoppers entering and leaving. Golden hour lighting, 16:9 format.
Unattributed image sources and references: https://miraflow.ai/blog/how-to-use-duct-tape-ai-model-arena-gpt-image-2-guide
This article is from the WeChat public account "APPSO", author: Discovering Tomorrow's Products






