Компания Brera Holdings, чьи акции котируются на Nasdaq, объявила о ребрендинге в Solmate после привлечения $300 млн в рамках частного размещения акций (PIPE). Новая стратегия предполагает переход от владения спортивными активами к управлению казначейством цифровых активов с фокусом на экосистему Solana.
Сделка была поддержана базирующейся в ОАЭ Pulsar Group, ARK Invest, RockawayX и Solana Foundation. Ранее Brera владела футбольными клубами в Италии и Европе, но теперь сосредоточится на управлении цифровыми активами и развитии инфраструктуры на базе Solana, включая стейкинг SOL и валидаторскую деятельность.
Компанию возглавит Марко Сантори, партнер Pantera Capital и бывший главный юридический директор Kraken. В совет директоров войдут экономист Артур Лаффер и генеральный директор RockawayX Виктор Фишер, а также два представителя Solana Foundation.
Solmate планирует разместить серверы в Абу-Даби для работы валидатора Solana и рассчитывает на двойной листинг на бирже ОАЭ наряду с присутствием на Nasdaq. Генеральный директор Марко Сантори заявил:
«Наши акционеры глубоко и долгосрочно уверены в экосистеме Solana и будут требовать, чтобы мы накапливали SOL как на бычьем, так и на медвежьем рынке».
Согласно данным, подписанное соглашение о намерениях с Solana Foundation предоставляет компании дисконтный доступ к SOL. Растущий институциональный интерес к Solana подтверждается статистикой: 16 организаций владеют 15,83 млн SOL (2,75% от общего предложения), из которых 9,35 млн находятся в стейкинге с доходностью 7,7%.
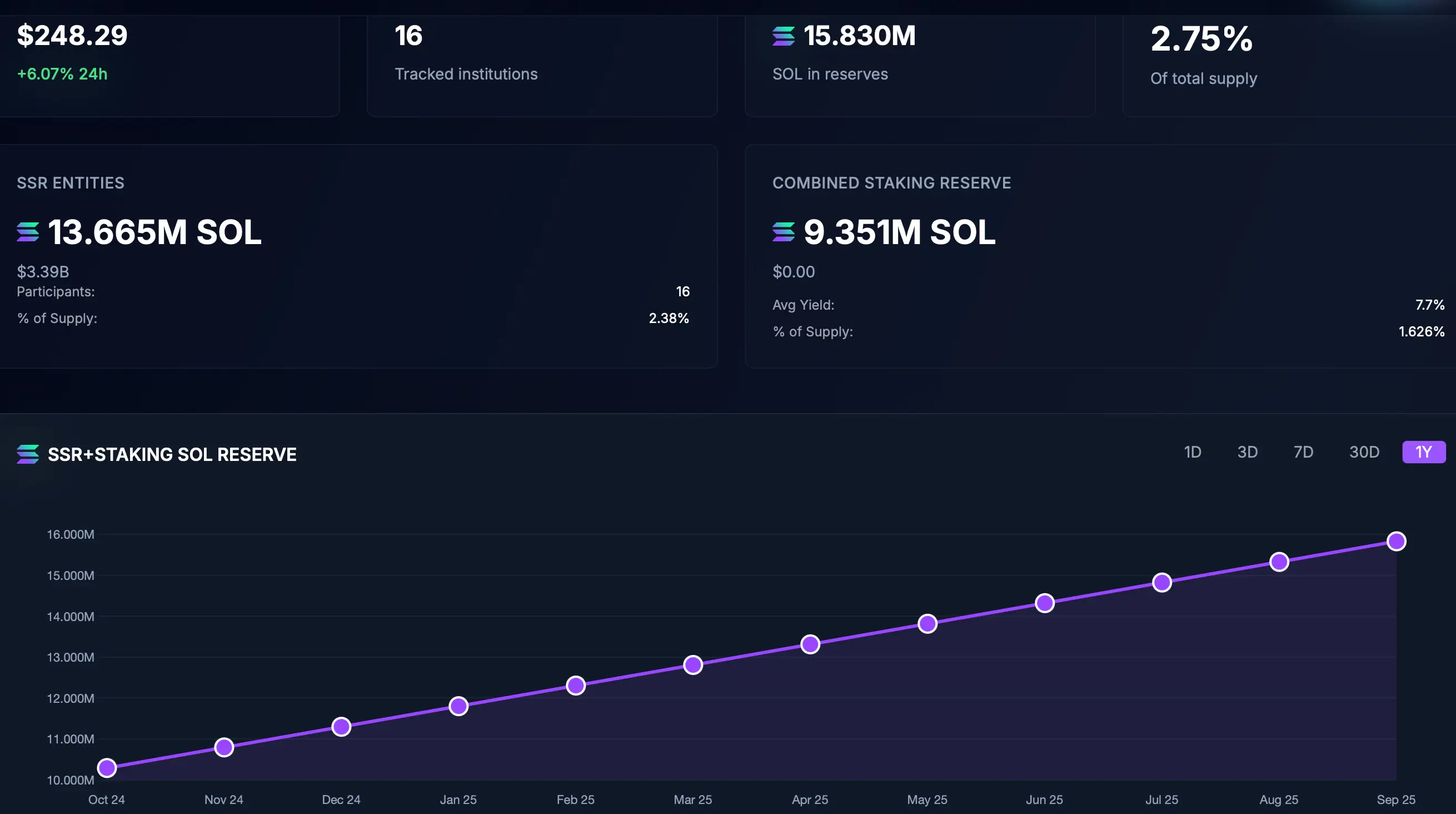
Источник: Strategicsolanareserve.org
Лидером среди институциональных держателей является Forward Industries с 6,82 млн SOL на $1,63 млрд. Волна корпоративного накопления продолжается — недавно Galaxy Digital сообщила о приобретении 6,5 млн SOL на $1,55 млрд за пять дней.
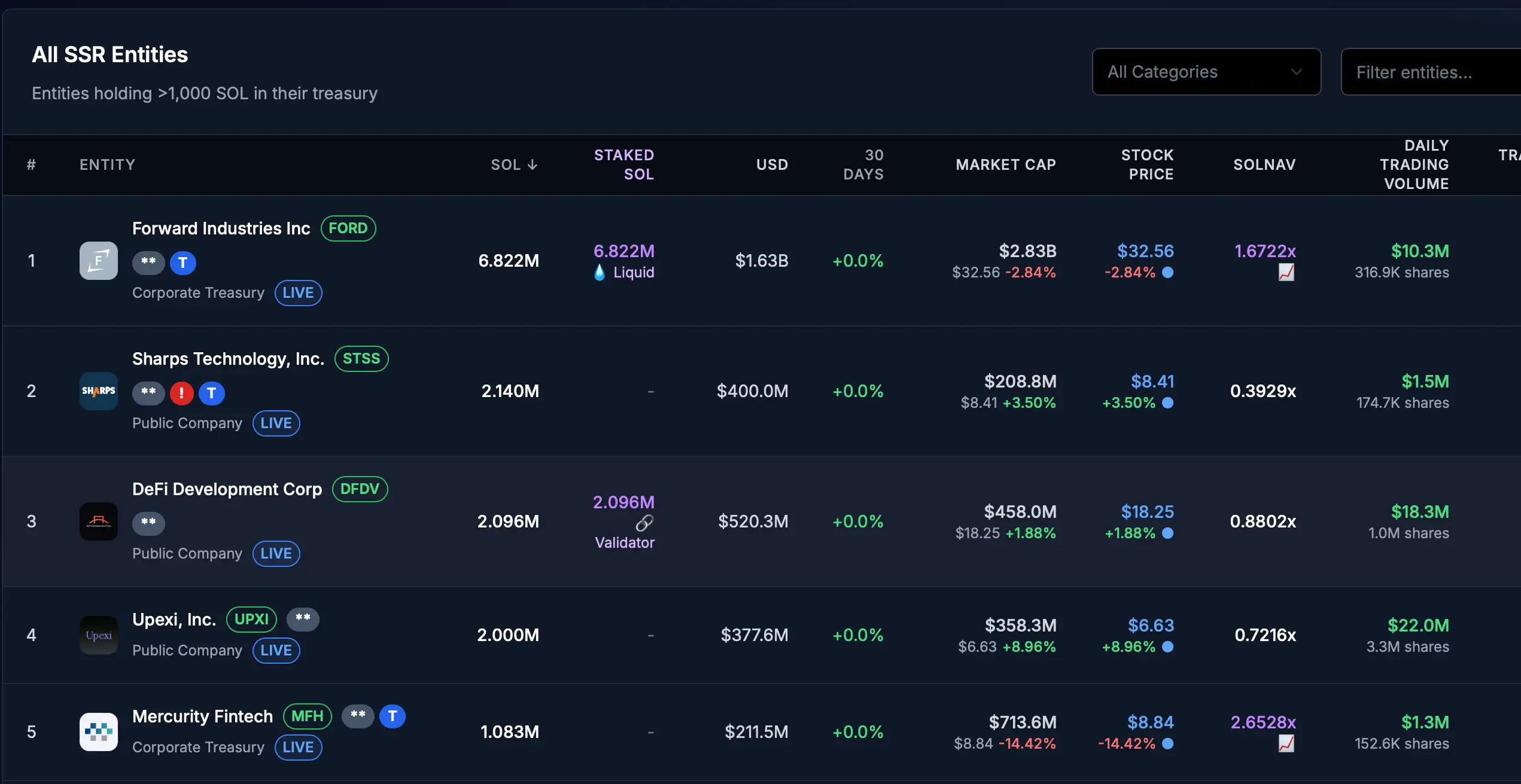
Источник: Strategicsolanareserve.org
Токен SOL торгуется на уровне $249, показывая рост на 38,7% за последние 30 дней, но оставаясь ниже исторического максимума в $293,31 января 2025 года.





