编者按:Anthropic 发布 Claude Opus 4.8,六项核心基准拿下五项第一,价格维持不变;Claude Code 加入动态工作流,下一代 Mythos 级模型也已进入市场预期。
相比单纯的性能提升,这次发布更值得关注的是,Anthropic 开始将「可信」塑造成前沿模型的核心卖点。
在代码诚实度测试中,Opus 4.8 对自身错误的漏报率大幅下降;在 Claude Code 中,它可以调度多个子 Agent,并在结果交付前引入对抗式自检。这些变化共同指向一个现实问题:当 AI 从聊天窗口进入真实工作流,用户最担心的往往不是模型无法完成任务,而是它在出错时依然给出一份看似完整、流畅且自洽的答案。
因此,Opus 4.8 的意义不止于一次模型升级,也释放出一个清晰的行业信号:前沿模型的竞争正在从单纯追逐 benchmark,转向对可靠性、可验证性和错误暴露能力的争夺。对于企业和专业用户来说,下一阶段 AI 的核心门槛,将越来越取决于模型是否值得被委托。
这也是 Agent 真正走向可用的前提。模型需要完成更多任务,也需要让人敢于把更重要、更复杂的任务交给它。
以下为原文:
Anthropic 今天发布了 Claude Opus 4.8。在发布卡列出的六项基准测试中,它拿下了其中五项第一。
我最关注的关键变化是:在 Anthropic 的代码总结诚实度测试中,Opus 4.7 有 19.7% 的情况下没有标出自己的错误;而 Opus 4.8 这一比例降到了 3.7%。同样的任务,它对自身工作的错误识别能力提升了大约五倍。Anthropic 在公告中将其概括为「4 倍」。不管怎么算,这都是决定你能否把真实工作交给这个模型、然后放心离开的关键,也比发布卡上的任何一个基准分数都更重要。

实际发布了什么
先说简版,再进入具体数字:
可靠性真正提升了。 除了上面提到的代码诚实度数据之外,Opus 4.8 也是首个在两项尽职测试中拿到「字面意义上的零」的 Claude 模型:它将「错误汇报有缺陷结果」的频率从 0.25 降到了 0.00,将「懒惰调查」的发生率从 25% 降到了 0%。过度自信的错误回答下降了约 11 倍。它偏袒自身工作的倾向,也就是 4.7 中可测量到的一种偏差,已经消失。
Claude Code 中加入了动态工作流,目前是研究预览版。 Claude 现在会自己编写编排脚本,在一次会话中并行调度数十到数百个子 Agent,并运行独立的对抗性 Agent,在结果呈现给你之前尝试反驳这些结果。这是 Opus 4.6 中提出的「Agent 团队」思路,如今变成了自动化能力。
它在自己的发布卡上领先,但并非全面领先。 六项中赢了五项。GPT-5.5 在终端操作任务上仍然领先。而且在系统卡里,还藏着一些 Anthropic 没放到展示幻灯片上的诚实退步,下文会展开。
价格没有变化。 仍然是每百万输入 token 5 美元、每百万输出 token 25 美元,与 4.7 相同。不过快速模式现在比之前便宜三倍,尽管它仍然属于溢价档,价格为 10 美元 / 50 美元。
Mythos 要来了。 Anthropic 明确表示,受限访问、能力极强的 Mythos 级模型将在未来几周到来。Opus 4.8 是通往它的公开入口。
官方发布卡:基准测试图景
下面是官方发布卡,用我们的配色呈现。
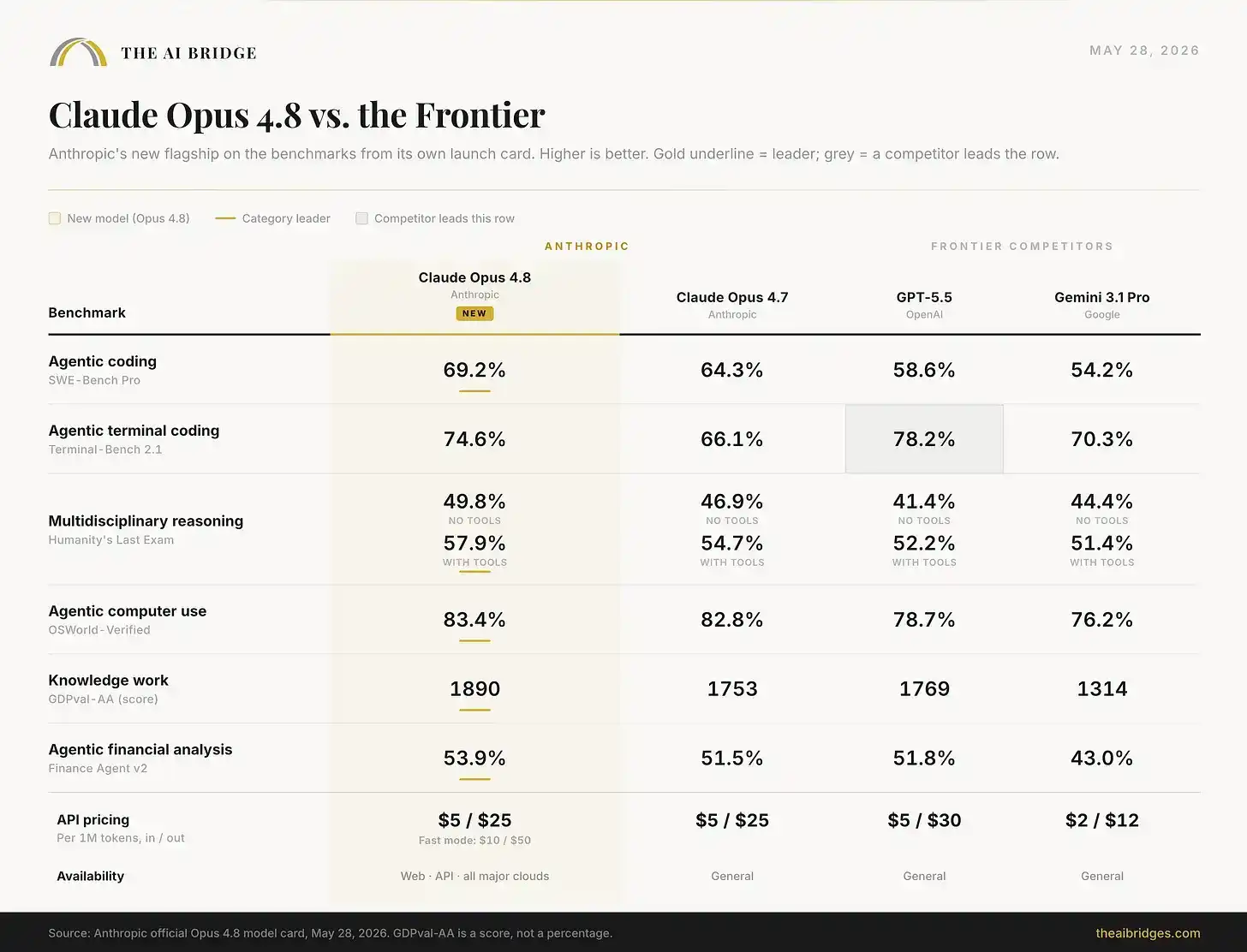
其中有一项打破了横扫局面,而且这项很重要。在 Terminal-Bench 2.1 上,也就是测试模型能否通过终端完成长程 Agent 任务的基准中,GPT-5.5 仍以 78.2% 领先 Opus 4.8 的 74.6%。Anthropic 把这个失利放在了自己的发布卡上,而不是选择隐藏。我们在 GPT-5.5 发布时提到的「Agent 与工匠」分野还没有完全弥合:GPT-5.5 仍是更强的纯终端操作者,而 Opus 4.8 在大多数专业用户真正关心的工作上更像一个更强的工程师,比如真实世界编码、专家推理、计算机使用和知识工作。
发布卡之外
发布卡只展示了六项基准。244 页的系统卡报告了 40 多项测试,其中最有意思的结果并不在幻灯片上。以下几项值得注意:
数学能力提升了 27 个百分点。 在 USAMO 2026 上,也就是今年 3 月举行的美国数学奥林匹克竞赛中,Opus 4.8 拿到了 96.7%,而 4.7 是 69.3%。由于这场比赛发生在 Opus 4.8 的训练截止时间之后,因此不存在数据污染问题。这是整张卡中最大的一次代际跃升。
长上下文场景下优势拉开。 在一项百万 token 图推理测试中,Opus 4.8 得分 68.1,而 4.7 为 40.3,GPT-5.5 为 45.4。上下文越长、任务越难,它的领先幅度越明显。
多 Agent 才是它真正登顶的地方。 单个 Opus 4.8 Agent 在网页研究任务上落后于 Gemini,分别为 84.3 和 85.9。但如果让一个编排器调度一组子 Agent,它的得分可以达到 88.5%,成为已报告结果中的最高分;一个五 Agent 团队还能用五分之一的时间,达到单个 Agent 最佳成绩。这正是动态工作流功能在基准测试中的体现。
token 效率出现质变。 在最难的编码测试中,Opus 4.8 在最低努力设置下,就能达到 Opus 4.7 在最高努力设置下的表现。也就是说,你可以用更少的 token 成本拿到过去的峰值表现。
它跨过了此前没有模型跨过的门槛。 在 Harvey 的 Legal Agent Benchmark 上,只有当任务中的每一项评分标准全部通过,任务才算成功。Opus 4.8 是第一个在这种「全通过」标准上排名第一的模型。它通过了 89% 的单项标准,但完整任务通过率只有 9.6%,这也说明真实法律工作的要求有多严苛。
也有诚实呈现的退步。 有三件事确实比 4.7 更差,Anthropic 在系统卡中也承认了。GPQA Diamond,也就是专家科学测试,从 94.2 滑落到 93.6。计算机使用场景下的拒答能力和抵抗提示注入的能力都有所退步,因此 4.8 在 Agent 场景中更容易被操纵。另外,在一项为期一年的模拟商业测试中,它最终剩下的现金只有 4.7 的三分之一。这些都没有出现在发布卡上,也正因如此,才更值得被指出来。
与开源权重模型相比,它处在什么位置
发布卡只把 Opus 4.8 与其他闭源前沿模型进行比较。如果把视野扩展到现在许多团队正在测试的廉价开源权重模型,图景几乎就是 2026 年 AI 产业的缩影:Opus 4.8 在能力上领先,但与免费、可自托管模型之间的差距已经只剩几个百分点,而价格差距却极其巨大。
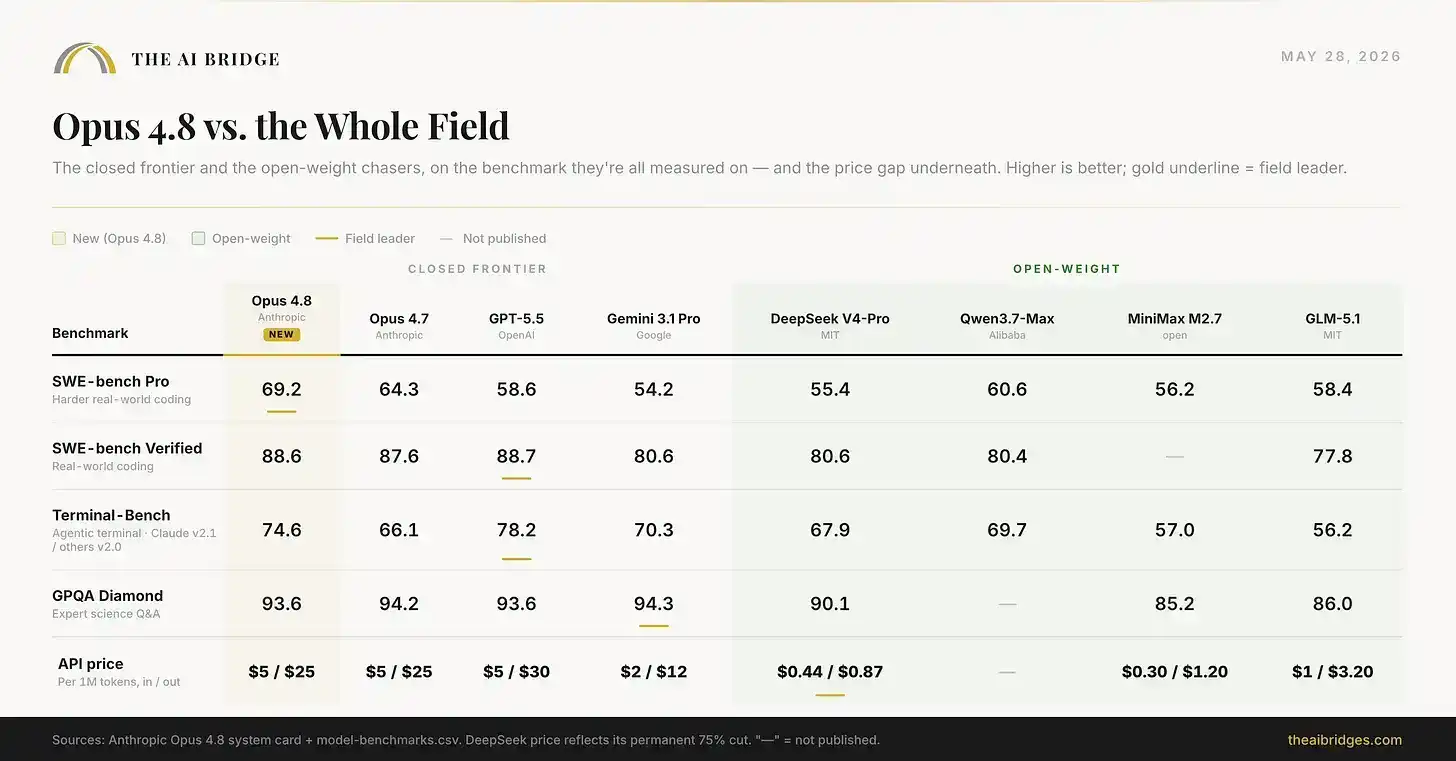
上图包含了八个模型的完整比较。DeepSeek 的价格反映了其永久性 75% 降价;Qwen Max 的价格尚未公布。
Opus 4.8 在编码基准上直接获胜。但 Qwen3.7-Max 这个你可以自行运行的开源模型,得分达到 60.6,只落后约 9 分。DeepSeek V4-Pro 得分 55.4,而其输出价格大约只有 Opus 的三十分之一。对于最高风险的工程任务来说,每百万输出 token 25 美元的差距是值得付的。对于大量日常工作来说,这个差距越来越不值得。而这正是每个严肃团队现在都在计算的账。
这对你意味着什么
如果你正在使用 Opus 4.7,那么这就是一次免费升级。价格不变,数据更好,对自身输出的判断也明显更可靠。切换过去就可以了。
更有意思的问题是:现在你愿意把哪些工作交给它?每个读者心里都有一条线,区分「我可以让 AI 做的任务」和「我必须亲自做的任务,因为我还不能信任交接」。4.8 的可靠性提升,意味着你可以把这条线往前推一步。模型更擅长标出自己的不确定性,这降低了「无声错误交接」的成本,也扩大了值得委托给模型的任务范围。这就是诚实度数据在实际使用中的含义,它比任何单项分数都更重要。
这也和我们上周写过的内容相呼应。Anthropic 自己的 AI Fluency 研究发现,当模型产出看起来很 polished、很完整时,人们会显著更不容易注意到缺失的上下文。答案看起来已经完成了,于是我们就停止检查。Opus 4.8 是从模型侧去攻击这个失败模式:它更擅长告诉你,一个看起来干净完整的答案哪里可能还有软肋。它不能替代你的判断力,但它能给你的判断力提供抓手。
如果你使用 Claude Code,本周可以拿一个真正的大任务试试动态工作流,比如一次迁移,或者对大量文件进行全面检查,同时留意 token 计量器。这个能力是真实的,对抗式自检也是让输出更可信的关键。但成本也是真实的。这是为那些单个 Agent 难以完成的大任务准备的工具,不应成为你的日常默认选项。
接下来:Mythos,几周内到来
这次发布中最具前瞻性的表述,其实并不关于 4.8。Anthropic 表示 Mythos 级模型将在未来几周到来,并把 Opus 4.8 定位为通往它的公开一步。
你需要理解这意味着什么。Mythos 是 Anthropic 内部一直在进行基准测试的受限前沿模型,它在几乎所有指标上都超过已发布的 Opus 4.8:在 SWE-bench Verified 上达到 93.9%;在网络安全测试中,它能针对当前浏览器中大多数目标生成可运行漏洞利用,而 Opus 4.8 的成功率不到 10%。它此前大约只开放给 52 家经过审核的机构,价格是标准 Opus 的五倍,被当作基础设施,而不是普通产品。
因此,当一个更强大的 Mythos 级模型在未来几周落地时,应该用「两类市场」的框架来理解它:一类是商品化层,也就是 Opus 4.8,广泛开放、价格不变、越来越受到免费开源模型追赶;另一类是受控前沿层,也就是 Mythos,昂贵、访问受限。这两者并不是割裂的产品,而是在同一条连续能力线上的不同层级。4.8 中的可靠性工作,正是你在真正目标是「让模型在更少监督下运行」之前必须先构建的东西。而这个目标现在距离我们不是几个季度,而是几周。
背景:这条线是怎么走到这里的
如果你已经跟丢了过去四个月的节奏,可以这样理解:Opus 4.6 在 2 月带来了 Agent 团队,Sonnet 4.6 带来了价格坍缩,Opus 4.7 在 4 月带来了推理跃升,而 Mythos 则是旁边隐约可见的受限天花板。Opus 4.8 把其中两条线索接了起来:它接续了 4.6 的编排叙事,同时也是通向 Mythos 的入口。
这种发布节奏本身,就是隐藏在所有表面变化之下的关键事实。旗舰模型在几个月内从 4.5、4.6、4.7 走到 4.8,而你今天为团队标准化采用的模型,到秋天可能已经不是你实际运行的那个模型。这也是为什么,比起投资某个具体模型的使用技巧,更应该投资那些能跨模型迁移的能力,比如清晰委托和严格验证。
基准测试横扫会获得截图传播。但真正发生变化的地方更小,也更重要:这是第一个 Claude 版本,其核心卖点不再只是「它更聪明」,而是「你可以把更多事情托付给它」。在 Agent 真正变得有用之前,整个行业都必须朝这个方向走;而这部分能力,也最难被放进一张图表里。
你现在的界线在哪里?哪些工作你愿意交给模型,哪些仍然必须自己做?又需要发生什么,才会让你愿意把这条线再往前推一步?





