Mô hình lớn (AI) ngày càng trở nên đồ sộ, quan điểm chủ đạo cho rằng tham số mô hình càng nhiều thì càng tiệm cận cách thức tư duy của con người. Tuy nhiên, một bài báo được công bố trên Nature Communications vào ngày 1/4 bởi nhóm nghiên cứu Đại học Chiết Giang lại đưa ra một quan điểm khác (Liên kết bài gốc: https://www.nature.com/articles/s41467-026-71267-5). Họ phát hiện ra rằng khi quy mô mô hình (chủ yếu là SimCLR, CLIP, DINOv2) tăng lên, khả năng nhận diện các sự vật cụ thể thực sự được cải thiện, nhưng khả năng hiểu các khái niệm trừu tượng không những không tăng mà thậm chí còn giảm xuống. Khi tham số tăng từ 22.06 triệu lên 304.37 triệu, độ chính xác cho nhiệm vụ khái niệm cụ thể tăng từ 74.94% lên 85.87%, trong khi đó, độ chính xác cho nhiệm vụ khái niệm trừu tượng giảm từ 54.37% xuống 52.82%.
Sự khác biệt trong cách tư duy giữa con người và mô hình
Khi não người xử lý khái niệm, nó sẽ hình thành trước một hệ thống quan hệ phân loại. Thiên nga và cú mèo trông không giống nhau, nhưng con người vẫn xếp chúng vào loài chim. Tiếp theo, chim và ngựa có thể tiếp tục được xếp vào lớp động vật. Khi con người nhìn thấy một thứ mới, họ thường nghĩ xem nó giống với thứ đã từng thấy trước đây, và nó thuộc loại nào. Con người liên tục học các khái niệm mới, sau đó tổ chức kinh nghiệm lại, và sử dụng hệ thống quan hệ này để nhận diện sự vật mới, thích ứng với tình huống mới.
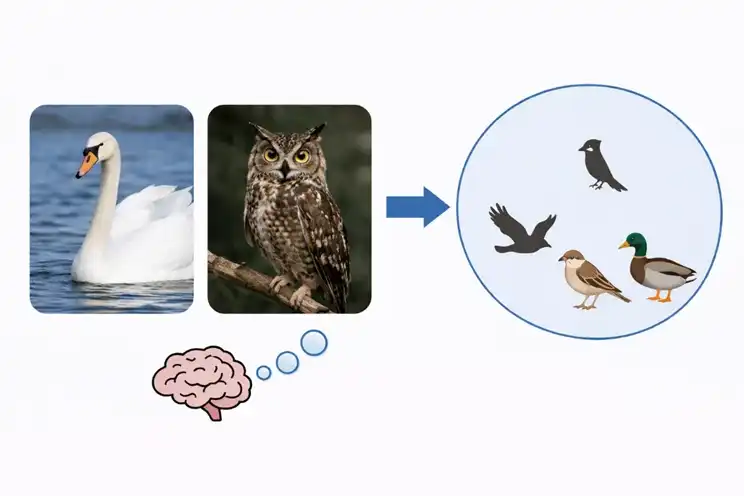
Mô hình AI cũng phân loại, nhưng cách thức hình thành khác nhau. Nó chủ yếu dựa vào các mẫu hình lặp đi lặp lại trong dữ liệu quy mô lớn. Đối tượng cụ thể xuất hiện càng nhiều, mô hình càng dễ dàng nhận ra nó. Đến bước phân loại thành các loại lớn hơn, mô hình tỏ ra khá vất vả. Nó cần nắm bắt các điểm chung giữa nhiều đối tượng, sau đó quy những điểm chung này vào cùng một loại. Các mô hình hiện có vẫn còn điểm yếu rõ ràng ở đây. Khi tham số tiếp tục tăng, nhiệm vụ khái niệm cụ thể sẽ được cải thiện, trong khi nhiệm vụ khái niệm trừu tượng đôi khi còn giảm xuống.

Điểm chung giữa não người và mô hình AI, là cả hai bên đều hình thành một hệ thống quan hệ phân loại bên trong. Nhưng trọng tâm của hai bên khác nhau, vùng thị giác bậc cao của não người sẽ tự nhiên phân chia các loại lớn như sinh vật và phi sinh vật. Trong khi mô hình AI có thể phân biệt các đối tượng cụ thể, nhưng rất khó để ổn định hình thành các phân loại lớn như vậy. Sự khác biệt này dẫn đến việc não người dễ dàng áp dụng kinh nghiệm cũ vào đối tượng mới hơn, vì vậy khi đối mặt với những thứ chưa từng thấy, chúng ta có thể phân loại nhanh chóng. Còn mô hình AI thì phụ thuộc nhiều hơn vào kiến thức hiện có, nên khi gặp đối tượng mới, nó dễ dừng lại ở các đặc trưng bề mặt. Phương pháp được đề xuất trong bài báo xoay quanh đặc điểm này, sử dụng tín hiệu não để ràng buộc cấu trúc bên trong của mô hình, khiến nó tiệm cận hơn với cách phân loại của não người.
Giải pháp của nhóm Chiết Giang
Giải pháp mà nhóm nghiên cứu đưa ra cũng rất độc đáo, không phải là tiếp tục chất đống tham số, mà là sử dụng một lượng nhỏ tín hiệu não để giám sát. Tín hiệu não ở đây, đến từ bản ghi hoạt động não của người khi xem hình ảnh. Bài báo gốc viết rằng: chuyển transfer cấu trúc khái niệm của con người (human conceptual structures) sang các mạng neural sâu (DNNs). Ý nghĩa chính là dạy cho mô hình cách não người phân loại, quy nạp, và đặt các khái niệm gần nhau như thế nào một cách tối đa.
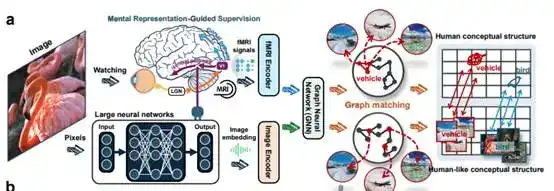
Nhóm nghiên cứu đã sử dụng 150 danh mục huấn luyện đã biết và 50 danh mục kiểm tra chưa từng thấy để thực nghiệm. Kết quả cho thấy, khi quá trình huấn luyện này tiến triển, khoảng cách giữa mô hình và biểu trưng não (brain representation) thu hẹp liên tục. Sự thay đổi này xuất hiện đồng thời ở cả hai loại danh mục, điều này chứng tỏ mô hình học được không phải là từng mẫu đơn lẻ, mà thực sự bắt đầu học một cách thức tổ chức khái niệm gần giống với não người hơn.
Sau quá trình huấn luyện này, khả năng học tập của mô hình khi có ít mẫu trở nên mạnh mẽ hơn, và thể hiện cũng tốt hơn khi đối mặt với tình huống mới. Trong một nhiệm vụ chỉ đưa ra cực ít ví dụ, nhưng yêu cầu mô hình phân biệt các khái niệm trừu tượng như sinh vật và phi sinh vật, mô hình đã cải thiện trung bình 20.5%, và thậm chí vượt qua các mô hình đối chứng có lượng tham số lớn hơn nhiều. Nhóm nghiên cứu còn tiến hành thêm 31 nhóm kiểm tra chuyên biệt, và vài loại mô hình đều cho thấy mức cải thiện gần một phần mười.
Vài năm trở lại đây, con đường quen thuộc của ngành mô hình là quy mô mô hình ngày càng lớn. Nhóm Chiết Giang đã chọn một hướng đi khác, đi từ 'lớn hơn là tốt hơn' (bigger is better) sang 'có cấu trúc là thông minh hơn' (structured is smarter). Mở rộng quy mô thực sự hữu ích, nhưng chủ yếu cải thiện biểu hiện trong các nhiệm vụ quen thuộc. Khả năng hiểu trừu tượng và chuyển giao (transfer) kiểu con người cũng cực kỳ quan trọng đối với AI, điều này đòi hỏi trong tương lai cần làm cho cấu trúc tư duy của AI tiệm cận hơn với não người. Giá trị của hướng đi này, nằm ở chỗ nó kéo sự chú ý của ngành trở lại với chính bản thân cấu trúc nhận thức, thay vì chỉ mở rộng quy mô đơn thuần.
Neosoul và tương lai
Điều này mở ra một khả năng lớn hơn, sự tiến hóa của AI, chưa chắc chỉ xảy ra ở giai đoạn huấn luyện mô hình. Huấn luyện mô hình có thể quyết định AI tổ chức khái niệm như thế nào, hình thành cấu trúc phán đoán chất lượng cao hơn ra sao. Sau khi bước vào thế giới thực, một tầng tiến hóa khác của AI mới thực sự bắt đầu: Phán đoán của AI agent được ghi nhận như thế nào, được kiểm chứng ra sao, làm thế nào để không ngừng trưởng thành và tiến hóa trong cuộc cạnh tranh lẫn nhau chân thực, giống như con người tự học và tự tiến hóa. Đây cũng chính là điều mà Neosoul hiện đang thực hiện. Neosoul không chỉ để AI agent đưa ra câu trả lời, mà là đặt AI agent vào một hệ thống liên tục dự đoán, liên tục xác minh, liên tục quyết toán, liên tục sàng lọc, để nó không ngừng tối ưu hóa bản thân trong dự đoán và kết quả, để các cấu trúc tốt hơn được giữ lại, và các cấu trúc kém hơn bị đào thải. Điều mà nhóm Chiết Giang và Neosoul cùng hướng tới, thực chất là cùng một mục tiêu: khiến AI không chỉ biết làm bài tập, mà còn phải có đầy đủ năng lực tư duy, không ngừng tiến hóa.





