Tác giả: qinbafrank
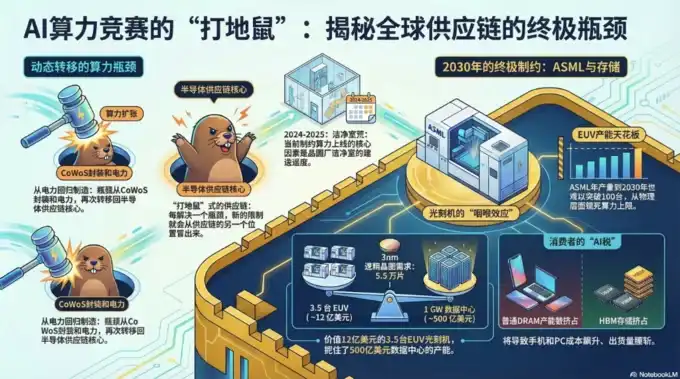
Trong bài viết "Cuộc chiến chi tiêu vốn này có ý nghĩa gì?" tháng 2, đã đề cập rằng các mắt xích quan trọng trong chuỗi cung ứng điện toán vẫn có thể nắm bắt giá trị lớn nhất: chip, đóng gói và kiểm tra, lưu trữ, mô-đun quang, v.v., những hạng mục mà công suất khó mở rộng nhanh, những hạng mục có hào rào cạnh tranh cực cao, sẽ hưởng lợi từ khoản chi tiêu vốn khổng lồ;
Không gian tối ưu hóa hiệu suất vẫn rất lớn: các kỹ thuật như cô đặc, lượng tử hóa, MoE, chip chuyên dụng, làm mát bằng chất lỏng, phản ứng tổng hợp hạt nhân (dài hạn) ở phía suy luận có thể giảm mức tiêu thụ năng lượng và chi phí cho mỗi đơn vị điện toán xuống 10–100 lần. Cần tìm kiếm cơ hội ở các khâu này.
Gần đây, nhiều ngân hàng đầu tư lớn như Morgan Stanley, J.P. Morgan, Bank of America, Goldman Sachs, UBS, Citi, Bernstein, HSBC đã công bố các báo cáo cập nhật liên quan đến AI/chất bán dẫn/điện năng/lưu trữ. Nút cổ chai của phần cứng AI đã lan rộng từ chiều "cung cấp GPU" duy nhất sang tình trạng căng thẳng tập thể của năm chiều: điện lực, chip, lưu trữ, thiết bị, vật liệu,
Quy mô nhu cầu AI đã vượt ra ngoài tất cả các khoảng dự đoán trong quy hoạch điện lực truyền thống, công suất thiết bị bán dẫn, mô hình giá lưu trữ, giả định lắp đặt robot.
Nghiên cứu chủ đề toàn cầu của Morgan Stanley chỉ ra rằng, lượng token mô hình ngôn ngữ lớn tiêu thụ hàng tuần trên toàn cầu đã tăng từ 6,4 nghìn tỷ lên 22,7 nghìn tỷ trong vòng 3 tháng, mức tăng đạt 2,5 lần, thiếu hụt điện năng cho trung tâm dữ liệu Mỹ giai đoạn 2025-28 là 55 GW; báo cáo nợ dự án điện toán hiệu suất cao trung tâm dữ liệu của J.P. Morgan lần đầu tiên bao phủ trực tiếp đưa ra con số thiếu hụt "122 GW cần huy động vốn trong 5 năm tới", quy hoạch điện lực 5 năm của Mỹ tăng vọt từ 101 GW lên 230 GW, 44% dự án mới có thời gian chờ kết nối lưới điện hơn 4 năm; trong báo cáo mục tiêu giá mới nhất của Bank of America cho Alphabet, chi tiêu vốn năm 2026 được điều chỉnh tăng trực tiếp lên 1815 tỷ USD, tăng gấp đôi so với cùng kỳ, dòng tiền tự do giảm 62%. Ba nhóm dữ liệu này không phải là kết quả từ một khuôn khổ chung, mà là những bức tranh độc lập từ ba tổ chức độc lập trên các con đường nghiên cứu khác nhau.
Sự tiến triển của nút cổ chai trong chuỗi cung ứng chất bán dẫn (đặc biệt là lĩnh vực điện toán AI), chính là tiến triển theo trình tự rõ ràng từ "tính toán (GPU) → lưu trữ (HBM, v.v.) → kết nối quang → điện lực/làm mát bằng chất lỏng". Đây là sự đồng thuận của ngành trong giai đoạn 2025-2026, khi các cụm huấn luyện/suy luận AI mở rộng từ tủ đơn (vài chục GPU) sang quy mô siêu lớn (hàng nghìn đến hàng chục nghìn GPU), mỗi khi giải quyết được nút cổ chai của một khâu, hạn chế vật lý/chuỗi cung ứng tiếp theo sẽ lập tức lộ ra, hình thành nên ràng buộc bổ sung kiểu "Leontief" (thiếu một mắt xích thì không thể xuất xưởng).
Cần hiểu tại sao lại xuất hiện sự tiến triển này, hiện trạng hiện tại và nguyên nhân vật lý/kỹ thuật đằng sau:
1. Nút cổ chai giai đoạn 1: Tính toán GPU (chi phối giai đoạn 2022-2024) Hạn chế cốt lõi:
Công suất wafer của chính GPU cao cấp (như NVIDIA Hopper H100 → Blackwell B200 → Rubin) + đóng gói tiên tiến.
Tại sao lại là nút cổ chai: Mô hình AI lớn cần tính toán song song khổng lồ, công suất quy trình logic TSMC 4nm/3nm/2nm + CoWoS (đóng gói 2.5D/3D) từng là điểm thắt lớn nhất. Ngay cả khi wafer phía trước đủ, khả năng đóng gói xếp chồng chip logic + HBM ở phía sau không theo kịp, thì toàn bộ GPU cũng không thể xuất xưởng.
Tình hình giảm bớt: TSMC mở rộng mạnh CoWoS (công suất tăng gấp đôi 2024-2025), NVIDIA Blackwell đã xuất xưởng quy mô lớn. Nhưng đây chỉ là mở khóa khâu "tính toán", vấn đề mới lập tức lộ ra ngay sau đó.
2. Nút cổ chai giai đoạn 2: Bộ nhớ (HBM - bộ nhớ băng thông cao, trở nên khan hiếm nhất giai đoạn 2024-2025)
Hạn chế cốt lõi: Công suất HBM3/HBM3e/HBM4.
Tại sao trở thành nút cổ chai kế tiếp: Sức mạnh tính toán của GPU tăng lên, nhưng tham số mô hình tăng theo cấp số nhân (hàng nghìn tỷ thậm chí hàng chục nghìn tỷ tham số), việc vận chuyển dữ liệu (băng thông bộ nhớ) trở thành "bức tường bộ nhớ". HBM có thể truyền vài TB dữ liệu mỗi giây, nhanh hơn bộ nhớ DDR thông thường trên 20 lần. Vì HBM nằm sát chip logic, dữ liệu không cần truyền đi xa, do đó tiết kiệm năng lượng.
Một GPU B200 cần 192GB+ HBM3e, tổng lượng HBM trong tủ đơn (NVL72) đã đạt 30-40TB, và nhu cầu băng thông vượt xa DRAM truyền thống.
Hiện trạng chuỗi cung ứng: Chỉ có SK Hynix, Samsung, Micron ba nhà sản xuất có thể sản xuất HBM quy mô, quy trình phức tạp (TSV + xếp chồng), năm 2025 đã bán hết sạch, năm 2026 vẫn cung không đủ cầu, giá tăng 246% so với cùng kỳ. Ngay cả khi chip GPU đã sẵn sàng, không có HBM thì không thể lắp ráp giao hàng, dẫn đến việc triển khai toàn bộ cụm AI bị trì hoãn.
Kết quả: Bộ nhớ từ "hàng hóa" trở thành mắt xích chiến lược then chốt, tỷ trọng bộ nhớ trong chi tiêu vốn có thể lên tới 30%.
3. Nút cổ chai giai đoạn 3: Kết nối quang (đang chuyển đổi giai đoạn 2025-2026)
Hạn chế cốt lõi: Giới hạn vật lý của cáp đồng (NVLink/NVSwitch) về băng thông, khoảng cách, công suất tiêu thụ, trọng lượng.
Tại sao nhất thiết phải chuyển sang quang: Trong tủ đơn (72 GPU) vẫn có thể dùng cáp đồng, nhưng khi mở rộng sang nhiều tủ, thậm chí kết nối hàng nghìn GPU, cáp đồng suy hao nghiêm trọng (băng thông 1.8TB/s, khoảng cách hiệu quả <1 mét), trọng lượng khổng lồ (tủ NVL72 có hơn 5.000 sợi cáp đồng, tổng trọng lượng 1,36 tấn), tiêu thụ điện cao (việc thay thế cáp đồng bằng mô-đun quang cắm rút sẽ tiêu thụ thêm 20.000 watt). Tính toàn vẹn tín hiệu, độ trễ, tản nhiệt đều không thể hỗ trợ cụm lớn hơn.
Giải pháp: Chuyển sang kết nối quang (CPO - quang học đóng gói chung + công nghệ silicon photonics). Đặt động cơ quang trực tiếp cạnh GPU/ASIC, sử dụng sợi quang để mở rộng quy mô (Scale-Out), mật độ băng thông cao hơn, công suất tiêu thụ mỗi bit thấp hơn, khoảng cách xa hơn.
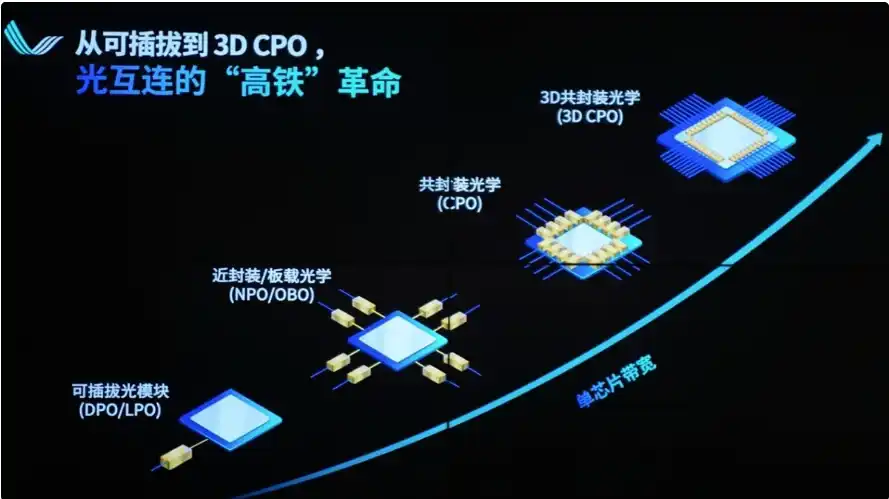
NVIDIA tại GTC 2026 đặt cược mạnh mẽ, đã đầu tư vào các công ty quang học, nhu cầu mô-đun quang 800G/1.6T bùng nổ. Lumentum, Broadcom, Coherent, Ayar Labs, v.v. trở thành những người thắng mới.
Tiến độ hiện tại: Cáp đồng đã đến giới hạn, kết nối quang đang từ "tùy chọn" trở thành "bắt buộc", đang phá vỡ trần hiệu suất của trung tâm dữ liệu AI.
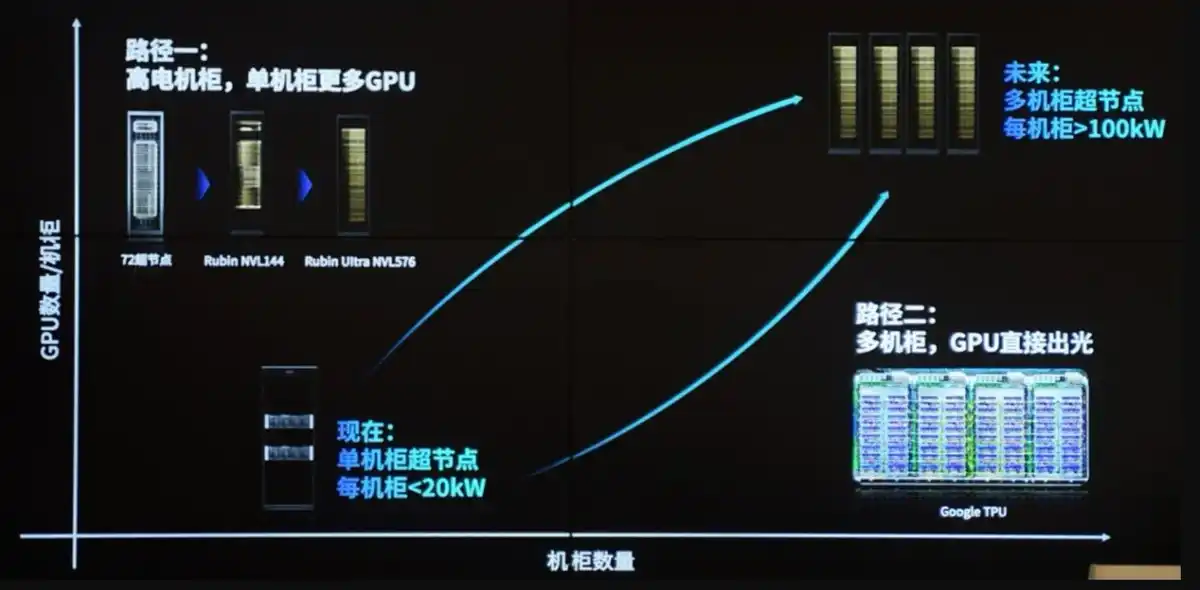
4. Nút cổ chai giai đoạn 4 (mới nhất hiện nay): Điện lực + làm mát bằng chất lỏng (từ 2026 trở thành ràng buộc vật lý cuối cùng) Hạn chế cốt lõi: Bức tường công suất tiêu thụ + bức tường tản nhiệt + kết nối lưới điện.
Tại sao là nút cổ chai tối hậu: Mỗi GPU từ 300W → 700-1200W, mỗi tủ từ 10-20kW (thời đại CPU) tăng vọt lên 120-200kW+ hoặc cao hơn. Giới hạn vật lý của làm mát bằng không khí truyền thống chỉ 20-50kW, tiếng ồn, lưu lượng gió, tiêu thụ năng lượng đều không thể chấp nhận được.
Phía điện lực: Trung tâm dữ liệu cần cấp điện cấp GW, thời gian chờ kết nối lưới điện có thể lên đến vài năm, thời gian giao hàng thiết bị như máy biến áp, máy biến áp trạng thái rắn kéo dài đến 100 tuần. CEO Microsoft từng thẳng thắn nói "có GPU nhưng không có điện để cắm".
Phía làm mát bằng chất lỏng: Bắt buộc phải chuyển sang làm mát trực tiếp lên chip (Direct-to-Chip) hoặc làm mát bằng ngâm (Immersion Cooling), kết hợp công nghệ vi lưu, tấm làm mát. TSMC đã trình diễn làm mát bằng chất lỏng nền silicon trên nền tảng CoWoS, hỗ trợ TDP > 2,6 kW. Các nhà sản xuất làm mát/quản lý nhiệt như Vertiv (VRT) trở thành lõi mới của cơ sở hạ tầng.
Phản ứng dây chuyền: Yêu cầu PUE (hiệu suất sử dụng năng lượng) < 1.2, thu hồi nhiệt thải, kết nối lưới điện hạt nhân/năng lượng mới đều trở thành chủ đề mới. Ngay cả khi tất cả các khâu trước đó đều được giải quyết, không có điện và làm mát, tủ cũng không thể lắp đặt vận hành.
Logic bản chất của sự chuyển dịch nút cổ chai trong chuỗi cung ứng điện toán AI Điện toán AI không phải là vấn đề "điểm đơn", mà là hàm sản xuất cấp hệ thống kiểu Leontief — GPU, HBM, kết nối, điện lực, làm mát phải được kết hợp theo điểm yếu thấp nhất. Các hyperscaler (Google, Microsoft, Meta, v.v.) mỗi khi giải quyết được một khâu, lập tức đẩy vốn và đổi mới sang khâu tiếp theo.
Hiện tại (năm 2026) đang ở giai đoạn chuyển đổi "kết nối quang triển khai nhanh + điện lực/làm mát bằng chất lỏng thương mại hóa quy mô lớn", tương lai có thể còn xuất hiện nút cổ chai mới (như laser, vật liệu sợi quang hoặc máy biến áp lưới điện), nhưng chuỗi "tính toán → lưu trữ → quang → điện/làm mát" này đã trở thành con đường được ngành công nhận.
Điều này cũng giải thích tại sao logic đầu tư chuyển từ NVIDIA/TSMC sang ba ông lớn HBM (SK Hynix, v.v.), các nhà sản xuất quang học (Lumentum, Coherent), cơ sở hạ tầng làm mát bằng chất lỏng/điện lực (Vertiv, các công ty nguồn điện liên quan).
Mỗi lần nút cổ chai chuyển dịch, đều đang định hình lại sự phân bổ giá trị của toàn bộ chuỗi cung ứng chất bán dẫn + trung tâm dữ liệu.






