Vào thời kỳ điện tín tính phí theo chữ, mực và giấy chính là tiền bạc. Người ta quen thuộc với việc cô đọng ngôn từ đến mức tối đa, "về ngay" có giá trị hơn một bức thư dài, "bình an" là lời dặn dò ý nghĩa nhất.
Về sau, điện thoại kéo vào từng gia đình, nhưng cước điện thoại đường dài tính theo từng giây từng phút. Những cuộc gọi đường dài của bố mẹ luôn ngắn gọn súc tích, nói xong việc chính là vội vã cúp máy, một khi câu chuyện vừa mới kéo dài thêm chút, nỗi lo về cước phí sẽ ngay lập tức chặn đứng những lời hỏi thăm vừa mới chớm.
Rồi sau đó, băng thông rộng về đến các hộ gia đình, lên mạng tính phí theo giờ, người ta nhìn chằm chằm vào bộ đếm thời gian trên màn hình, mở trang web ra rồi lập tức tắt, chỉ dám tải video xuống, phát trực tuyến (streaming) thời đó là một động từ xa xỉ. Đằng sau cuối mỗi thanh tiến trình tải xuống, đều ẩn chứa khát khao "kết nối với thế giới" và nỗi e ngại "số dư không đủ" của con người.
Đơn vị tính phí thay đổi hết lần này đến lần khác, nhưng bản năng tiết kiệm thì vĩnh cửu không đổi.
Ngày nay, Token đã trở thành đồng tiền của thời đại AI. Tuy nhiên, hầu hết mọi người vẫn chưa học được cách chi tiêu tinh tường trong thời đại này, bởi vì chúng ta vẫn chưa học được cách tính toán được mất trong những thuật toán vô hình.
Khi ChatGPT mới ra mắt vào năm 2022, hầu như không ai quan tâm Token là gì. Đó là thời đại "cơm chung" của AI, mỗi tháng chỉ cần bỏ ra 20 đô la, muốn trò chuyện bao nhiêu tùy thích.
Nhưng kể từ khi AI Agent trở nên nổi tiếng gần đây, chi phí Token đã trở thành vấn đề mà bất kỳ ai sử dụng AI Agent đều phải quan tâm.
Khác với những cuộc đối thoại hỏi đáp đơn giản, đằng sau một luồng tác vụ là hàng trăm, hàng ngàn lần gọi API. Sự suy nghĩ độc lập của Agent là có cái giá của nó, mỗi lần tự sửa chữa, mỗi lần gọi công cụ, đều tương ứng với những con số nhảy múa trên hóa đơn. Rồi bạn sẽ phát hiện số tiền bạn nạp vào đột nhiên không đủ dùng, và bạn còn không biết Agent đã thực sự làm những gì.
Trong cuộc sống thực, mọi người đều biết cách tiết kiệm tiền. Đi chợ mua rau, chúng ta biết nhặt sạch những lá héo úa dính bùn trước khi đem lên cân; bắt taxi ra sân bay, tài xế già dặn biết tránh đường cao tốc giờ cao điểm buổi sáng.
Logic tiết kiệm trong thế giới số thực ra cũng giống vậy, chỉ có điều đơn vị tính phí từ "cân" và "cây số" được thay thế bằng Token.
Trước đây, tiết kiệm là do sự khan hiếm; còn trong thời đại AI, tiết kiệm là để đạt được sự chính xác.
Chúng tôi hy vọng thông qua bài viết này, có thể giúp bạn hệ thống hóa một phương pháp luận tiết kiệm trong thời đại AI, giúp bạn sử dụng mỗi đồng tiền một cách hiệu quả nhất.
Cân đo trước, hãy nhặt bỏ lá héo úa
Trong thời đại AI, giá trị của thông tin không còn được quyết định bởi độ rộng, mà bởi độ tinh khiết.
Logic tính phí của AI là tính theo số chữ nó đọc. Dù bạn cung cấp cho nó là kiến thức sâu sắc, hay những định dạng vô nghĩa vô vị, chỉ cần nó đọc, bạn phải trả tiền.
Vì vậy, tư duy đầu tiên để tiết kiệm Token, là khắc sâu "tỷ lệ tín hiệu trên nhiễu" (signal-to-noise ratio) vào tiềm thức.
Mỗi chữ, mỗi bức ảnh, mỗi dòng mã bạn cung cấp cho AI, đều phải trả tiền. Vì vậy trước khi giao bất cứ thứ gì cho AI, hãy nhớ tự hỏi bản thân: trong này có bao nhiêu phần là AI thực sự cần? Có bao nhiêu là những lá rau héo úa dính bùn?
Chẳng hạn như "Xin chào, làm ơn giúp tôi..." những lời mở đầu dài dòng, phần giới thiệu bối cảnh lặp lại, những chú thích mã chưa xóa sạch, đều là những lá héo úa dính bùn.
Ngoài ra, sự lãng phí phổ biến nhất, là ném trực tiếp file PDF hoặc ảnh chụp màn hình trang web cho AI. Làm vậy đúng là bạn tự tiện lợi cho mình, nhưng "tiện lợi" trong thời đại AI thường đồng nghĩa với "đắt đỏ".
Một file PDF với định dạng đầy đủ, ngoài nội dung chính, còn bao gồm tiêu đề trang, chân trang, chú thích biểu đồ, watermark ẩn, và một lượng lớn mã định dạng dùng để dàn trang. Những thứ này không giúp ích gì cho việc AI hiểu vấn đề của bạn, nhưng tất cả chúng đều được tính phí.
Lần sau hãy nhớ chuyển PDF thành văn bản Markdown sạch sẽ trước khi cung cấp cho AI. Khi bạn biến file PDF 10MB thành văn bản sạch 10KB, bạn không chỉ tiết kiệm được 99% tiền, mà còn khiến bộ não của AI chạy nhanh hơn trước rất nhiều.
Hình ảnh là một con quái vật ăn Token khác.
Trong logic của mô hình thị giác, AI không quan tâm bức ảnh của bạn chụp có đẹp không, nó chỉ quan tâm bạn chiếm dụng bao nhiêu diện tích pixel.
Lấy logic tính toán chính thức của Claude làm ví dụ: Lượng Token tiêu thụ của ảnh = Số pixel chiều rộng × Số pixel chiều cao ÷ 750.
Một bức ảnh 1000×1000 pixel, tiêu thụ khoảng 1334 Token, tính theo giá của Claude Sonnet 4.6, mỗi bức ảnh khoảng 0.004 đô la;
Nhưng nếu nén cùng một bức ảnh đó xuống 200×200 pixel, chỉ tiêu thụ 54 Token, chi phí giảm xuống còn 0.00016 đô la, chênh lệch tới 25 lần.
Nhiều người ném trực tiếp ảnh chụp độ phân giải cao từ điện thoại, ảnh chụp màn hình 4K cho AI, mà không biết rằng lượng Token những bức ảnh này tiêu thụ có thể đủ để AI đọc xong phần lớn một cuốn tiểu thuyết trung篇. Nếu nhiệm vụ chỉ là nhận dạng chữ trong ảnh hoặc đưa ra đánh giá thị giác đơn giản, chẳng hạn như để AI nhận dạng số tiền trên hóa đơn, đọc chữ trong hướng dẫn sử dụng, hoặc phán đoán xem trong ảnh có đèn tín hiệu giao thông hay không, thì độ phân giải 4K là sự lãng phí thuần túy, nén ảnh xuống độ phân giải khả dụng tối thiểu là đủ.
Nhưng lý do dễ lãng phí Token nhất ở đầu vào, thực ra không phải là định dạng file, mà là cách nói chuyện kém hiệu quả.
Nhiều người coi AI như một người hàng xóm thực thụ, quen dùng những lời lẽ vụn vặt mang tính xã hội để giao tiếp, đầu tiên ném ra một câu "giúp tôi viết một trang web", đợi AI nhả ra một bán thành phẩm, rồi bổ sung chi tiết, rồi kéo co qua lại. Kiểu đối thoại vắt kiệt từng chút một (挤牙膏式) này, sẽ khiến AI liên tục tạo ra nội dung, mỗi lần sửa đổi đều cộng dồn lượng Token tiêu thụ.
Các kỹ sư của Tencent Cloud phát hiện trong thực tế, với cùng một yêu cầu, cuộc đối thoại nhiều vòng kiểu vắt kiệt từng chút một, lượng Token tiêu thụ cuối cùng thường gấp 3 đến 5 lần so với việc nói rõ ràng một lần.
Đạo lý tiết kiệm thực sự, là từ bỏ kiểu thăm dò xã hội kém hiệu quả này, nói rõ yêu cầu, điều kiện biên, ví dụ tham khảo một lần. Đừng tốn sức giải thích "đừng làm gì", bởi vì câu phủ định thường tốn nhiều chi phí thấu hiểu hơn câu khẳng định; hãy trực tiếp nói với nó "phải làm thế nào", và đưa ra một ví dụ chính xác rõ ràng.
Đồng thời, nếu bạn biết mục tiêu ở đâu, hãy nói rõ với AI, đừng để AI đóng vai thám tử.
Khi bạn ra lệnh cho AI "tìm mã liên quan đến người dùng", nó phải quét, phân tích và phỏng đoán quy mô lớn trong nền; còn khi bạn trực tiếp nói với nó "hãy xem file src/services/user.ts này, thì sự chênh lệch về Token tiêu thụ là rất lớn. Trong thế giới số, thông tin ngang bằng chính là sự tiết kiệm lớn nhất.
Đừng trả tiền cho sự "lịch sự" của AI
Có một quy tắc ngầm trong tính phí mô hình lớn mà nhiều người không nhận ra: Token đầu ra thường đắt hơn Token đầu vào từ 3 đến 5 lần.
Nghĩa là, những lời AI nói ra, đắt hơn nhiều so với những lời bạn nói với nó. Lấy giá của Claude Sonnet 4.6 làm ví dụ, đầu vào mỗi triệu Token chỉ 3 đô la, còn đầu ra thì đột ngột nhảy vọt lên 15 đô la, chênh lệch tới 5 lần.
Những lời mở đầu lịch sự kiểu "Vâng, tôi đã hoàn toàn hiểu yêu cầu của bạn, bây giờ bắt đầu giải đáp cho bạn......", những lời kết thúc xã giao kiểu "hy vọng nội dung trên có ích cho bạn", trong giao tiếp giữa người thật là những lời xã giao lịch sự, nhưng trên hóa đơn API, những lời hỏi thăm vô bổ không có giá trị thông tin thêm này cũng phải trả bằng tiền của chính bạn.
Biện pháp hiệu quả nhất để giải quyết lãng phí ở đầu ra, là đặt ra quy tắc cho AI. Dùng lệnh hệ thống để nói rõ với nó: đừng xã giao, đừng giải thích, đừng kể lại yêu cầu, trả lời trực tiếp.
Những quy tắc này chỉ cần thiết lập một lần, và có hiệu lực trong mỗi cuộc đối thoại, là phương tiện quản lý tài chính thực sự "đầu tư một lần, hưởng lợi vĩnh viễn". Nhưng khi thiết lập quy tắc, nhiều người lại rơi vào một sai lầm khác: dùng ngôn ngữ tự nhiên dài dòng để chất đống lệnh.
Dữ liệu thực tế từ các kỹ sư cho thấy, hiệu năng của lệnh không nằm ở số chữ, mà ở mật độ. Nén một đoạn từ gợi ý hệ thống 500 chữ xuống còn 180 chữ, bằng cách xóa bỏ những từ ngữ lịch sự vô nghĩa, hợp nhất các lệnh trùng lặp, và tái cấu trúc đoạn văn thành danh sách các mục ngắn gọn, chất lượng đầu ra của AI hầu như không dao động, nhưng lượng Token tiêu thụ cho mỗi lần gọi có thể giảm mạnh 64%.
Một biện pháp kiểm soát chủ động hơn nữa, đó là giới hạn độ dài đầu ra. Nhiều người không bao giờ thiết lập giới hạn đầu ra, để AI tự do phát huy, sự buông lỏng quyền biểu đạt này, thường dẫn đến tình trạng mất kiểm soát chi phí cực độ. Có lẽ bạn chỉ cần một câu ngắn gọn vừa đủ, nhưng AI lại để thể hiện một thứ "thành ý trí tuệ" nào đó, đã không nói không ràng mà tạo cho bạn một bài luận nhỏ 800 chữ.
Nếu bạn theo đuổi dữ liệu thuần túy, nên bắt buộc AI trả về định dạng có cấu trúc, thay vì mô tả đoạn văn dài dòng. Trong trường hợp chứa cùng một lượng thông tin, lượng Token tiêu thụ của định dạng JSON thấp hơn nhiều so với đoạn văn mang tính văn học. Điều này là do dữ liệu có cấu trúc loại bỏ tất cả các từ kết nối dư thừa, từ ngữ khí và sửa đổi giải thích, chỉ giữ lại phần lõi logic có nồng độ cao. Trong thời đại AI, bạn nên nhận thức rõ ràng, thứ đáng để bạn trả tiền là giá trị của kết quả, chứ không phải đoạn giải thích bản thân vô nghĩa của AI.
Ngoài ra, "suy nghĩ quá mức" (overthinking) của AI cũng đang ăn mòn số dư tài khoản của bạn một cách điên cuồng.
Một số mô hình cao cấp có chế độ "suy nghĩ mở rộng" (extended thinking), sẽ tiến hành suy luận nội bộ với quy mô lớn trước khi trả lời. Quá trình suy luận này cũng được tính phí, và là tính theo giá đầu ra, rất đắt.
Chế độ này về bản chất được thiết kế cho "các nhiệm vụ phức tạp cần hỗ trợ logic sâu". Nhưng hầu hết mọi người khi hỏi những câu hỏi đơn giản cũng chọn chế độ này. Đối với những nhiệm vụ không cần suy luận sâu, hãy nói rõ với AI "không cần giải thích ý tưởng, trả lời trực tiếp", hoặc tự tắt chế độ suy nghĩ mở rộng, cũng có thể giúp bạn tiết kiệm kha khá tiền.
Đừng để AI lật lại sổ cũ
Mô hình lớn không có trí nhớ thực sự, nó chỉ đang điên cuồng lật lại sổ cũ.
Đây là một cơ chế cơ bản mà nhiều người không biết. Mỗi lần bạn gửi một tin nhắn mới trong một cửa sổ hội thoại, AI không phải bắt đầu hiểu từ câu nói này của bạn, mà là đọc lại tất cả nội dung các bạn đã trò chuyện trước đó, bao gồm mỗi vòng đối thoại, mỗi đoạn mã, mỗi tài liệu trích dẫn, tất cả đều đọc lại một lần nữa, rồi mới trả lời bạn.
Trong hóa đơn Token, việc "ôn cố nhi tri tân" này tuyệt đối không miễn phí. Khi số vòng đối thoại cộng dồn, dù bạn chỉ hỏi thêm một từ đơn giản, chi phí đọc lại toàn bộ sổ cũ đằng sau của AI cũng sẽ tăng lên theo cấp số nhân. Cơ chế này quyết định, lịch sử hội thoại càng nặng nề, mỗi câu hỏi của bạn càng đắt đỏ.
Có người đã theo dõi 496 cuộc đối thoại thực chứa trên 20 tin nhắn, phát hiện tin nhắn thứ nhất trung bình đọc 14,000 Token, chi phí mỗi tin nhắn khoảng 3.6 cent; đến tin nhắn thứ 50, trung bình đọc 79,000 Token, chi phí mỗi tin nhắn khoảng 4.5 cent, đắt hơn tới 80%. Và ngữ cảnh ngày càng dài, đến tin nhắn thứ 50, ngữ cảnh mà AI phải xử lý lại đã gấp 5.6 lần so với tin nhắn đầu tiên.
Giải quyết vấn đề này, thói quen đơn giản nhất là: một nhiệm vụ, một hộp thoại.
Khi một chủ đề trò chuyện kết thúc, hãy quyết đoán mở cuộc đối thoại mới, đừng coi AI như một cửa sổ trò chuyện không bao giờ tắt. Thói quen này nghe có vẻ đơn giản, nhưng nhiều người không làm được, luôn cảm thấy "phòng khi còn dùng đến nội dung trước đó". Trên thực tế, những "phòng khi" mà bạn lo lắng phần lớn sẽ không xuất hiện, và vì cái "phòng khi" này, bạn đã trả thêm gấp mấy lần tiền cho mỗi tin nhắn mới.
Khi cuộc đối thoại thực sự cần tiếp tục, nhưng ngữ cảnh đã trở nên rất dài, chúng ta có thể sử dụng chức năng nén của một số công cụ. Claude Code có lệnh /compact, có thể cô đọng lịch sử hội thoại dài dòng thành một bản tóm tắt ngắn gọn, giúp bạn thực hiện một cuộc "dọn dẹp số" (digital decluttering).
Lại có một logic tiết kiệm gọi là Prompt Caching (bộ nhớ đệm gợi ý). Nếu bạn liên tục sử dụng cùng một đoạn từ gợi ý hệ thống, hoặc mỗi lần đối thoại đều phải trích dẫn cùng một tài liệu tham khảo, AI sẽ lưu vào bộ nhớ đệm phần nội dung này, lần gọi tiếp theo sẽ chỉ thu một khoản phí đọc bộ nhớ đệm rất ít, chứ không phải mỗi lần đều tính phí toàn bộ.
Bảng giá chính thức của Anthropic cho thấy, giá Token khi trúng bộ nhớ đệm là 1/10 giá bình thường. Prompt Caching của OpenAI cũng có thể giảm chi phí đầu ra khoảng 50%. Một bài báo được công bố trên arXiv vào tháng 1 năm 2026, đã thử nghiệm nhiều nhiệm vụ dài trên nhiều nền tảng AI, phát hiện bộ nhớ đệm gợi ý có thể giảm chi phí API từ 45% đến 80%.
Nghĩa là, cùng một nội dung, lần đầu cung cấp cho AI phải trả giá đầy đủ, sau đó mỗi lần gọi chỉ phải trả 1/10. Đối với những người dùng hàng ngày phải lặp lại sử dụng cùng một bộ tài liệu quy phạm hoặc từ gợi ý hệ thống, tính năng này có thể tiết kiệm được rất nhiều Token.
Nhưng Prompt Caching có một điều kiện tiên quyết, nội dung và thứ tự từ gợi ý hệ thống và tài liệu tham khảo của bạn phải nhất quán, và phải đặt ở phía trước nhất của cuộc đối thoại. Một khi nội dung có bất kỳ thay đổi nào, bộ nhớ đệm sẽ mất hiệu lực, và tính phí lại toàn bộ. Vì vậy, nếu bạn có một bộ quy chuẩn công việc cố định, hãy viết cố định nó, đừng tùy tiện sửa đổi.
Kỹ thuật cuối cùng về quản lý ngữ cảnh, là tải theo nhu cầu. Nhiều người thích nhét tất cả các quy chuẩn, tài liệu, những điểm cần lưu ý vào từ gợi ý hệ thống, lý do vẫn là "phòng khi".
Nhưng cái giá phải trả của việc này là, bạn rõ ràng chỉ đang làm một nhiệm vụ rất đơn giản, nhưng lại buộc phải tải vài nghìn chữ quy tắc, lãng phí một đống Token vô ích. Tài liệu chính thức của Claude Code khuyến nghị giữ CLAUDE.md trong vòng 200 dòng, tách các quy tắc chuyên môn của các tình huống khác nhau thành các file kỹ năng độc lập, dùng đến tình huống nào mới tải quy tắc của tình huống đó. Duy trì ngữ cảnh hoàn toàn tinh khiết, chính là sự tôn trọng cao nhất đối với sức mạnh tính toán.
Đừng mua xe hơi hạng sang để đi chợ
Các mô hình AI khác nhau có mức giá chênh lệch rất lớn.
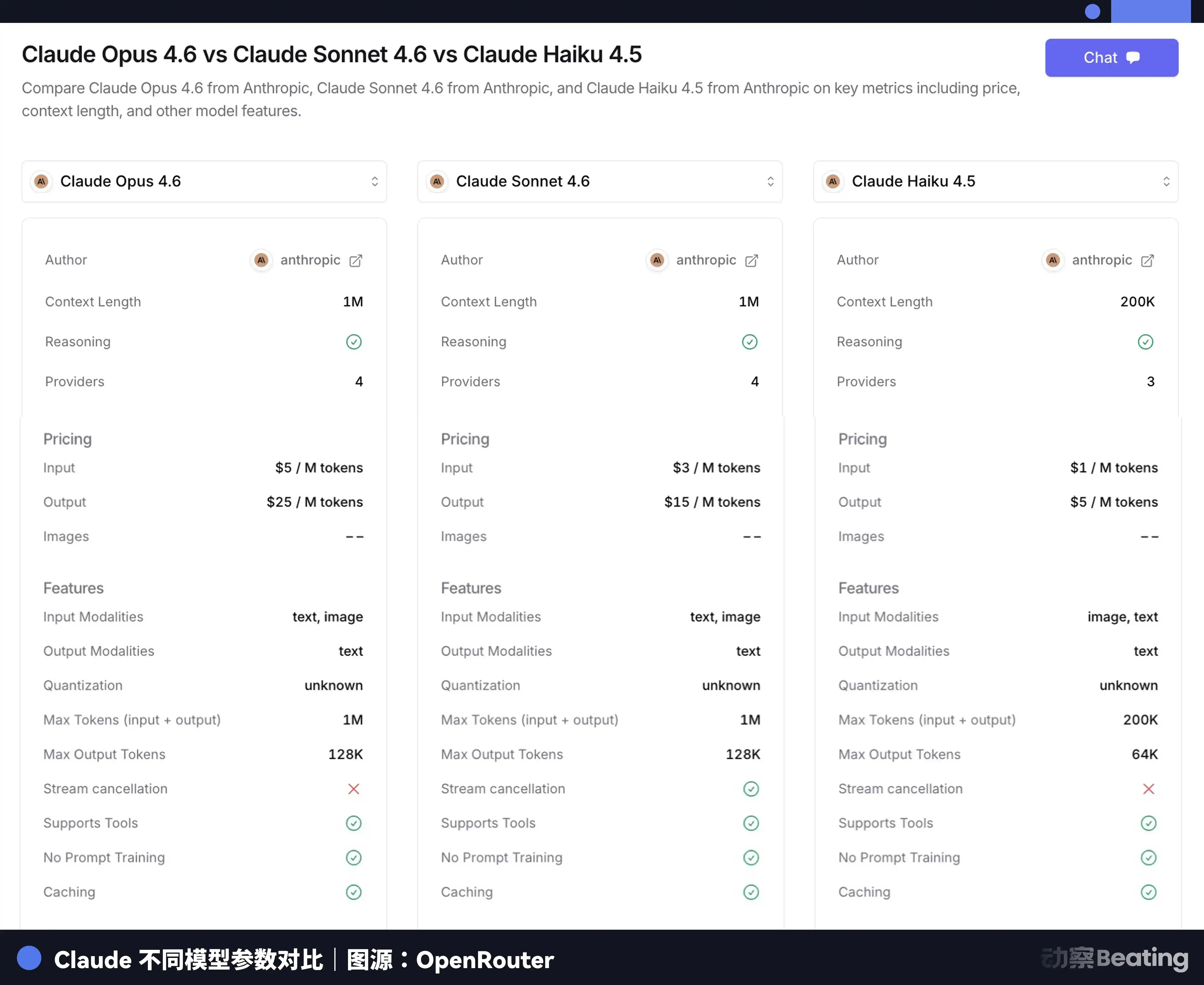
Claude Opus 4.6 mỗi triệu Token đầu vào mất 5 đô la, đầu ra 25 đô la, Claude Haiku 3.5 chỉ cần 0.8 đô la đầu vào, 4 đô la đầu ra, chênh lệch gần 6 lần. Để mô hình đỉnh cao nhất làm những công việc tạp vụ như thu thập tài liệu, định dạng bố cục, không chỉ chậm, mà còn rất đắt.
Cách dùng thông minh là mang tư duy "phân công giai cấp" phổ biến trong xã hội loài người chúng ta vào xã hội AI, nhiệm vụ với độ khó khác nhau, giao cho mô hình với mức giá khác nhau.
Giống như thuê người làm việc trong thế giới thực, bạn sẽ không chuyên đi thuê một chuyên gia với mức lương hàng triệu đô la để đến công trường khiêng vác. AI cũng vậy. Tài liệu chính thức của Claude Code cũng khuyến nghị rõ ràng: Sonnet xử lý hầu hết các nhiệm vụ lập trình, Opus dành cho các quyết định kiến trúc phức tạp và suy luận nhiều bước, các nhiệm vụ con đơn giản chỉ định dùng Haiku.
Phương án thực thi cụ thể hơn là xây dựng "quy trình làm việc hai giai đoạn". Ở giai đoạn đầu, sử dụng mô hình cơ bản miễn phí hoặc giá rẻ để làm những công việc bẩn mệt nhọc trước, chẳng hạn như thu thập tài liệu, dọn dẹp định dạng, tạo bản thảo đầu, phân loại và tổng hợp đơn giản. Bước vào giai đoạn hai, mới đưa phần tinh hoa tinh khiết cao độ đã được chắt lọc cho mô hình đỉnh cao, để tiến hành quyết định cốt lõi và chỉnh sửa sâu.
Lấy ví dụ, nếu bạn muốn phân tích một báo cáo ngành 100 trang, có thể dùng Gemini Flash trích xuất dữ liệu then chốt và kết luận trong báo cáo, sắp xếp thành một bản tóm tắt 10 trang, sau đó đưa bản tóm tắt này cho Claude Opus để phân tích sâu và phán đoán. Quy trình làm việc hai giai đoạn này, có thể đảm bảo chất lượng đồng thời nén chi phí xuống mức lớn.
Tiến xa hơn so với xử lý phân đoạn đơn thuần, là sự phân công sâu dựa trên việc giải cấu trúc nhiệm vụ. Một nhiệm vụ kỹ thuật phức tạp, hoàn toàn có thể được tách thành một số nhiệm vụ con độc lập với nhau, và phối hợp mô hình phù hợp nhất.
Chẳng hạn một nhiệm vụ cần viết mã, có thể để mô hình giá rẻ viết khung và mã mẫu trước, sau đó chỉ giao phần logic cốt lõi cho mô hình đắt tiền để thực hiện. Mỗi nhiệm vụ con có ngữ cảnh sạch sẽ, tập trung, kết quả chính xác hơn, chi phí cũng thấp hơn.
Vốn dĩ bạn không cần tiêu Token
Tất cả những thảo luận phía trên, về bản chất đều đang giải quyết vấn đề chiến thuật "làm thế nào để tiết kiệm tiền", nhưng một vấn đề logic cơ bản hơn bị nhiều người bỏ qua: hành động này, rốt cuộc có cần tiêu Token không?
Tiết kiệm triệt để nhất không phải là tối ưu hóa thuật toán, mà là sự đoạn tuyệt trong quyết định. Chúng ta quen với việc tìm kiếm câu trả lời vạn năng từ AI, nhưng lại quên mất trong nhiều tình huống, gọi mô hình lớn đắt tiền không khác gì dùng súng cao xạ bắn muỗi.
Chẳng hạn để AI tự động xử lý email, nó sẽ coi mỗi email là một nhiệm vụ độc lập để hiểu, phân loại, trả lời, lượng Token tiêu thụ khổng lồ. Nhưng nếu bạn dành 30 giây lướt qua hộp thư đến, lọc thủ công những email rõ ràng không cần AI xử lý, rồi giao phần còn lại cho AI, chi phí lập tức giảm xuống còn một phần nhỏ so với ban đầu. Khả năng phán đoán của con người ở đây không phải là trở ngại, mà là bộ lọc tốt nhất.
Người thời điện tín biết, mỗi chữ phát đi thêm phải trả thêm bao nhiêu tiền, vì vậy họ sẽ cân nhắc, đây là một loại cảm nhận trực giác về tài nguyên. Thời đại AI cũng vậy, khi bạn thực sự biết mỗi câu nói thêm của AI phải trả thêm bao nhiêu tiền, bạn tự nhiên sẽ cân nhắc việc này có đáng để AI làm không, nhiệm vụ này cần mô hình đỉnh cao hay mô hình giá rẻ, ngữ cảnh này còn có ích không.
Sự cân nhắc này, là khả năng tiết kiệm nhất. Thời đại sức mạnh tính toán ngày càng đắt, cách dùng thông minh nhất, không phải là để AI thay thế con người, mà là để AI và con người làm những việc mỗi bên giỏi. Khi tính nhạy cảm với Token này nội tâm hóa thành một phản xạ có điều kiện, bạn mới thực sự từ kẻ phụ thuộc vào sức mạnh tính toán, trở lại làm chủ sức mạnh tính toán.






