Tại một nhà máy gia công quần áo ở Ấn Độ, công nhân đang phân loại vải như thường lệ, nhưng lần này khác biệt là trên đầu họ đeo thêm một camera, dùng để quay video góc nhìn thứ nhất khi họ làm việc.
Những video này, sau khi được xử lý, sẽ trở thành tài sản dữ liệu, được bán cho các công ty trí tuệ thể hóa (embodied AI) cần lượng dữ liệu lớn để huấn luyện robot.
Những hoạt động kinh doanh tương tự từ đầu năm nay đang hình thành một chuỗi ngành công nghiệp mới, và sự trỗi dậy của chuỗi này bắt nguồn từ điểm nghẽn lớn nhất mà ngành trí tuệ thể hóa hiện đang gặp phải: dữ liệu.
"Năm nay nhu cầu tăng lên rõ rệt." Một chuyên gia trong ngành thu thập dữ liệu robot chia sẻ với 42 Megahertz, rằng các công ty robot ở Âu Mỹ mà nhóm anh phục vụ đang mua sắm lượng lớn dữ liệu công việc của con người. Hiện tại, nhóm đã có gần một trăm người thu thập tham gia sản xuất dữ liệu huấn luyện robot, mỗi tháng có thể ổn định sản xuất hàng nghìn giờ video dữ liệu góc nhìn thứ nhất của con người.
Người thu thập cần hoàn thành nhiệm vụ theo quy trình tiêu chuẩn, như phân loại quần áo, sắp xếp nhà bếp, cầm nắm đồ vật... Trong quá trình đó, họ đeo camera trên đầu, một số nhiệm vụ còn cần găng tay dữ liệu để ghi lại các cử động tay chi tiết hơn.
"Trước đây, ngành này thảo luận về mô hình, về phần cứng, giờ ngày càng nhiều người bắt đầu hỏi: dữ liệu có thể cung cấp ổn định không?"
Mọi người bắt đầu nhận thức rõ ràng rằng, khả năng của mô hình mãi không thể đột phá, quy mô dữ liệu không đủ chính là vấn đề lớn nhất.
Và trong bối cảnh khoảng trống dữ liệu khổng lồ của mô hình thể hóa, hoạt động kinh doanh mới - thu thập dữ liệu, cũng bắt đầu hình thành nhanh chóng.
Tại sao robot bắt đầu thiếu dữ liệu?
Nếu quay ngược thời gian ba năm trước, robot giống ngành tự động hóa truyền thống hơn.
Đa số robot được cố định trong nhà máy, quy trình làm việc có cấu trúc cao: hàn, vận chuyển, phun sơn, lắp ráp. Chúng không cần hiểu môi trường phức tạp, cũng không cần học khả năng tổng quát hóa, chỉ cần lặp lại động tác trên quỹ đạo đã định.
Nhưng hiện nay, nhiều công ty muốn làm không còn là robot công nghiệp truyền thống. Từ Tesla, Figure đến PI, ngành công nghiệp đang thử nghiệm để robot được huấn luyện như mô hình lớn (large model), và có khả năng tổng quát.
Vì vậy, con đường mà mô hình thể hóa đi cũng ngày càng giống với mô hình ngôn ngữ lớn (LLM), chỉ có điều con đường của mô hình thể hóa còn gian nan hơn LLM, đặc biệt là trong lĩnh vực dữ liệu.
Đối với LLM, bản thân Internet là một mỏ vàng dữ liệu tự nhiên, hàng chục năm tích lũy các trang web, sách, luận văn, kho mã nguồn... tạo thành kho ngữ liệu huấn luyện khổng lồ. Các công ty mô hình thường chỉ cần giải quyết vấn đề lọc và làm sạch dữ liệu, ít khi phải tạo dữ liệu từ con số không.
Nhưng mô hình thể hóa thì khác, nó đối mặt với thế giới vật lý - một vùng hoang mạc dữ liệu. Dữ liệu động tác của robot không tự sinh ra, ngay cả khi Internet có nhiều video con người làm việc, nhưng đối với robot, quy mô dữ liệu như vậy vẫn không đủ, và chất lượng tổng thể cũng không đủ cao.
Nếu nói LLM sinh ra trong thư viện, thì robot giống như sinh ra trong một vùng hoang mạc.
Vì vậy, khi AI đã bước vào giai đoạn cạnh tranh về sức mạnh tính toán và tối ưu hóa suy luận, ngành trí tuệ thể hóa vẫn bị kẹt ở vấn đề cơ bản nhất: dữ liệu đến từ đâu.
Đây cũng là lý do tại sao, ngay cả khi kiến trúc mô hình ngày càng phức tạp, robot vẫn còn rất xa mới thực sự bước vào gia đình và các tình huống phức tạp.
Bởi vì mô hình thiếu kinh nghiệm thực tế đủ nhiều.
Trước đây, người sáng lập Figure - Brett Adcock từng đưa ra một quan điểm rất thẳng thắn: "Nếu búng tay, lượng dữ liệu khổng lồ thực sự cần thiết có thể nhét vào mô hình Helix, chúng tôi sẽ lập tức giải quyết được robot tổng quát."
Nhưng vấn đề là, dữ liệu đến từ đâu?
Một giờ dữ liệu được sản xuất như thế nào?
Tháng 2 năm nay, một kết quả nghiên cứu khiến ngành công nghiệp trở nên phấn khích.
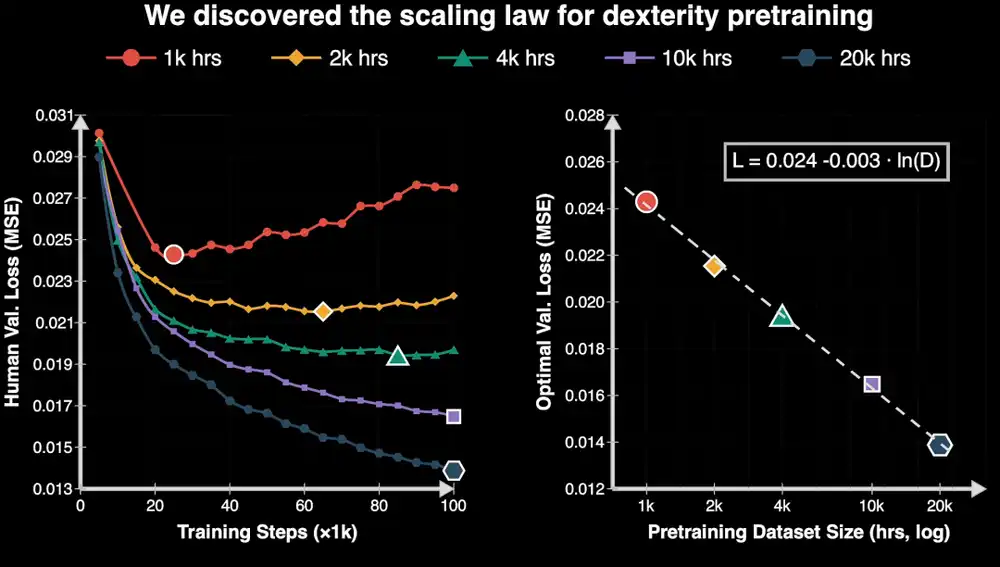
Đội ngũ Nvidia công bố EgoScale, thông qua việc tiền huấn luyện mô hình với hơn 20.000 giờ video góc nhìn thứ nhất của con người có chú thích động tác, sau đó tinh chỉnh với một lượng nhỏ dữ liệu robot, có thể khiến bàn tay khéo léo Sharpa Wave 22 bậc tự do hoàn thành các nhiệm vụ như vặn nắp chai, gấp quần áo.

Quan trọng hơn, nghiên cứu phát hiện rằng, cùng với sự tăng lên của quy mô dữ liệu con người, biểu hiện của mô hình sẽ ổn định tăng lên, sự tăng lên này có thể dự đoán được.
Nghiên cứu này rất quan trọng với ngành thể hóa, bởi vì một đường dữ liệu có thể mở rộng (Scaling) nghĩa là sự tăng trưởng năng lực của robot có cơ hội giống như mô hình lớn, bước vào một vòng lặp tích cực "nhiều dữ liệu hơn, mang lại năng lực mạnh hơn".
Trong thời gian dài trước đây, ngành thể hóa luôn có một sự lo lắng, dù đầu tư nhiều vốn hơn, sự nâng cao năng lực mô hình vẫn rất khó dự đoán. Bởi vì dữ liệu thế giới thực quá ít, chi phí quá cao, rất ít người dám đầu tư khổng lồ vào lĩnh vực dữ liệu.
Nhưng EgoScale ở một mức độ nào đó đã chứng minh một điều, ít nhất là đối với dữ liệu góc nhìn thứ nhất của con người (Ego Data), quy mô thực sự có thể mang lại lợi ích ổn định cho thao tác của bàn tay khéo léo.
Đồng thời, ngày càng nhiều công ty robot bắt đầu đi theo con đường lượng lớn dữ liệu con người + lượng nhỏ dữ liệu bản thân robot.
Video góc nhìn thứ nhất của con người, chịu trách nhiệm cho mô hình biết con người hoàn thành nhiệm vụ như thế nào, dữ liệu robot thì chịu trách nhiệm để mô hình học cơ thể của mình nên làm gì.
Vì vậy, giá trị chính của Ego Data là như một loại tri thức tiên nghiệm dễ mở rộng hơn, để robot hiểu thế giới vật lý trước, sau đó hoàn thành việc thích ứng thông qua một lượng nhỏ dữ liệu thiết bị thực.
Do đó, chuỗi ngành công nghiệp mới xoay quanh Ego Data cũng bắt đầu tăng tốc rõ ràng trong năm nay.
Con người đeo một camera trên đầu hoặc trước ngực, sau đó thực hiện nhiệm vụ cụ thể, như phân loại quần áo, sắp xếp nhà bếp, phân loại bưu kiện... camera sẽ ghi lại video góc nhìn thứ nhất khi con người làm việc.
Ở một mức độ nào đó, bản thân con người chính là robot tổng quát trưởng thành nhất thế giới. Khi vào nhà bếp, con người tự nhiên phán đoán đặt gì trước, gì sau, khi không gian không đủ, sẽ dùng tay kia. Khi chạm vào đồ dễ vỡ, sẽ vô thức điều chỉnh lực.
Đằng sau những động tác tưởng như bản năng này, thực chất ẩn chứa lượng lớn logic hiểu không gian, lập kế hoạch nhiệm vụ và tương tác vật thể.
Mà trước đây, robot hầu như chưa từng nhận được những kinh nghiệm này một cách có hệ thống.

Nhưng Ego Data không phải là quay video tùy tiện, và quay đủ quy mô video cũng không phải là khó khăn lớn nhất, mấu chốt là làm thế nào biến những kinh nghiệm này thành một sản phẩm dữ liệu có thể thực sự được mô hình sử dụng.
Một người trong ngành bắt đầu tăng tốc bố trí dữ liệu Ego trong năm nay cho biết với 42 Megahertz, việc thu thập dữ liệu thực sự thường bắt đầu từ một tài liệu đặc tả nhiệm vụ (specification) do khách hàng gửi đến.
Loại tài liệu này, sẽ không đơn giản viết một câu "thu thập dữ liệu sắp xếp nhà bếp", mà thường có quy định rõ ràng:
Loại nhiệm vụ là gì, hai tay có phải hoàn toàn vào khung hình không, camera cần đặt ở đầu hay ngực, động tác có cho phép gián đoạn không, môi trường cần bao nhiêu loại biến đổi, có cần mẫu thất bại không, định dạng giao hàng cuối cùng có cần tương thích với khung huấn luyện không.
Ví dụ, cùng là sắp xếp nhà bếp, khách hàng có thể yêu cầu: hoàn thành liên tục nhiều bước như mở cửa tủ, tìm hộp chứa, dọn không gian, lấy đặt đồ vật, đóng cửa..., giữa chừng không được bỏ khung hình, cũng không được xuất hiện che khuất nghiêm trọng.
Ở một mức độ nào đó, điều này giống như sản xuất một loại hàng công nghiệp, toàn bộ quá trình tại hiện trường thu thập cũng "công nghiệp hóa" hơn nhiều so với tưởng tượng.
Trong một số trung tâm thu thập số liệu, người thu thập sẽ lần lượt vào khu vực nhà bếp, phòng để đồ, kệ hàng được bố trí sẵn, lặp lại thực hiện nhiệm vụ theo SOP thống nhất.
Có người chịu trách nhiệm phân loại quần áo, có người lặp lại luyện tập cầm nắm đồ vật kích thước khác nhau, cũng có người chuyên thu thập dữ liệu sắp xếp nhà bếp và vận chuyển.
Cùng một động tác, thường cần được hoàn thành lặp lại bởi người có chiều cao khác nhau, tay thuận khác nhau, thói quen thao tác khác nhau, cố gắng khám phá hết các tình huống có thể xuất hiện trong thế giới vật lý, bởi vì cuối cùng robot đối mặt là thế giới thực phức tạp, không phải một đáp án tiêu chuẩn duy nhất.
Cũng là đặt cốc vào tủ, có người dọn không gian trước, có người đổi tay, có người quen mở cửa tủ trước, những khác biệt tinh tế này chính là một phần tạo nên khả năng tổng quát hóa của robot.
Vì vậy, đối với nhiều mô hình thể hóa, điều chúng cần học là logic "con người thường hoàn thành việc này như thế nào".
Loại dữ liệu này so với dữ liệu thiết bị thực, dễ đạt được sản xuất hàng loạt hơn, trước nhu cầu khổng lồ của ngành, chỉ cần quy mô theo kịp, chi phí nhân lực thấp, thì có cơ sở lợi nhuận, và cũng tương đối dễ tạo ra dòng tiền.
Nhưng nếu dữ liệu không đáp ứng yêu cầu của khách hàng thì cần làm lại, thời lượng dữ liệu thực sự được khách hàng nghiệm thu, ít hơn nhiều so với thời lượng quay gốc, thời lượng hiệu quả có thể trực tiếp vào quy trình huấn luyện quan trọng hơn.
Từ đây, ngành công nghiệp dần xuất hiện sự phân tầng ngày càng rõ ràng. Bởi vì dữ liệu khác nhau, giá trị khác biệt rất lớn, từ góc độ tổng hợp như chi phí, giá trị..., đại thể có thể hình thành một "kim tự tháp dữ liệu".
Giá trị khác biệt lớn giữa các loại dữ liệu khác nhau
Trong "kim tự tháp dữ liệu", tầng dưới cùng là dữ liệu Internet, gần như không có chi phí thu thập, đồng thời cũng có quy mô không nhỏ.
Robot có thể học từ đó vật thể trông như thế nào, bố cục đại thể của nhà bếp. Nhưng vấn đề cũng rất rõ ràng, nó chỉ có thể giúp robot "biết", rất khó giúp robot "làm". Chỗ thực sự khó khăn của thế giới thực, là động tác, lực ma sát, trọng lượng, biến đổi chất liệu, hạn chế không gian, rủi ro va chạm, những điều này không thể chỉ học qua video thông thường.
Lên trên một tầng nữa là dữ liệu con người cấp cao hơn, trong đó Ego Data là phần quan trọng nhất, nó có thể từ góc nhìn thứ nhất cho mô hình biết con người thao tác như thế nào, phần dữ liệu video này có thể sử dụng quy mô lớn cho tiền huấn luyện, giống như trong EgoScale đã làm.
Nhưng robot cuối cùng vẫn cần giải quyết vấn đề cơ thể mình nên làm như thế nào. Cũng là vặn nắp chai, tay người hoàn thành dễ dàng, robot có thể thất bại lặp đi lặp lại.
Do đó, dữ liệu cảm nhận do găng tay dữ liệu mang lại ngày càng quan trọng, Ego Data thông thường chỉ có thể cho mô hình biết con người nhìn thấy gì, hoàn thành nhiệm vụ gì. Nhưng robot cuối cùng còn cần biết khi nào nên tăng lực, khi nào cần thả lỏng.
Những động tác tinh tế này, rất khó chỉ suy luận qua video, vì vậy ngày càng nhiều công ty bắt đầu thử nghiệm căn chỉnh dữ liệu hình ảnh với bắt chuyển động tay, ước tính tư thế, quỹ đạo khớp.
Video chịu trách nhiệm cung cấp hiểu không gian, găng tay chịu trách nhiệm cung cấp chi tiết động tác, còn dữ liệu thiết bị thực từ điều khiển từ xa thì giúp robot hiểu cơ thể mình nên thực hiện như thế nào.

Tuy nhiên, hiện tại ngành công nghiệp vẫn tồn tại một vấn đề rất thực tế, tiêu chuẩn găng tay vẫn rất không thống nhất. Tần số lấy mẫu, định nghĩa khớp, độ chính xác và cách biểu đạt động tác của thiết bị khác nhau rất lớn, làm thế nào để ánh xạ ổn định động tác con người lên cơ thể robot khác nhau, vẫn là một điểm nghẽn không nhỏ.
Vì vậy, nếu không đeo găng tay dữ liệu, chỉ dùng camera đội đầu quay, lúc này giá của Ego Data không quá cao, nhưng một khi thêm găng tay dữ liệu, giá sẽ nhanh chóng tăng lên.
Tiếp tục lên trên kim tự tháp là dữ liệu mô phỏng, thông qua môi trường song sinh kỹ thuật số, robot có thể huấn luyện tốc độ cao trong thế giới ảo, trải qua hàng triệu lần lặp lại cầm nắm, định hướng và tránh vật cản. Lượng dữ liệu mất một tháng mới hoàn thành trong thực tế, trong môi trường mô phỏng có thể chỉ cần vài ngày.
Tuy nhiên, mô phỏng rốt cuộc không phải là thế giới thực, dù lượng lớn và chi phí thấp, nhưng các yếu tố ngẫu nhiên như lực ma sát, biến đổi chất liệu, phản quang... trong thực tế rất khó được sao chép hoàn toàn, đây cũng là "Khoảng cách Mô phỏng - Thực tế (Sim-to-Real Gap)" thường được nhắc đến trong ngành, robot học rất tốt trong mô phỏng, nhưng một khi bước vào môi trường thực, năng lực thường bị giảm sút nhiều.
Còn tầng đỉnh của kim tự tháp, là dữ liệu thiết bị thực chất lượng cao nhất, cũng đắt và khan hiếm nhất, chủ yếu dựa vào cách thức như người vận hành điều khiển từ xa..., điều khiển robot hoàn thành nhiệm vụ cụ thể, robot sẽ đồng bộ ghi lại hình ảnh, động tác, tín hiệu điều khiển và trạng thái cảm biến.
Khác với dữ liệu con người, nó tự nhiên nằm trong không gian động tác của robot, mô hình không cần tốn sức hiểu động tác con người ánh xạ lên cơ thể robot như thế nào. Ngoài ra, dữ liệu thiết bị thực cũng bao gồm dữ liệu công việc tự chủ mà nó tạo ra khi ứng dụng, nhưng robot hiện tại phổ biến chưa ứng dụng quy mô lớn, dữ liệu tạo ra cũng khan hiếm tương tự.
Hơn nữa, vấn đề then chốt của dữ liệu thiết bị thực là hiệu suất sản xuất rất thấp, muốn nâng cao quy mô dữ liệu thì cần tăng thêm nhiều robot và người vận hành, đồng thời chi phí hao mòn địa điểm và thiết bị cao, đều sẽ nhanh chóng đẩy giá lên.
Tình hình giá cả do nhiều người trong ngành đưa ra đại khái là, Ego Data đơn giản nhất thường chỉ cần vài chục tệ một giờ, còn dữ liệu bản thân robot liên quan đến điều khiển từ xa, giá thường tăng lên hàng trăm thậm chí hàng nghìn tệ một giờ.
Trong quá trình huấn luyện mô hình robot của các nhà sản xuất khác nhau, các tầng của kim tự tháp dữ liệu phát huy tác dụng cũng khác nhau, do đó toàn ngành cũng xuất hiện các công ty dữ liệu thượng nguồn có trọng điểm khác nhau như mô phỏng, dữ liệu góc nhìn thứ nhất của con người...
Ai đang giao dịch những dữ liệu này?
Khi một ngành công nghiệp quy mô khổng lồ trỗi dậy, người đầu tiên có lợi nhuận thường là "người bán nước" thượng nguồn.
Ngành trí tuệ thể hóa cũng như vậy, trong một hai năm qua, trên phạm vi toàn cầu đã xuất hiện rất nhiều công ty khởi nghiệp robot, nhân tài các ngành đều tập trung vào lĩnh vực này.
Gần như mỗi ngày đều có công ty mới tuyên bố hoàn thành gọi vốn, các công ty định giá trăm tỷ trong nước ngày càng nhiều, một số công ty thậm chí đã đi trên con đường IPO, chuyển ánh mắt ra nước ngoài, Figure sau khi hoàn thành vòng gọi vốn C năm ngoái, định giá đã đạt 39 tỷ USD, đứng đầu trong các công ty robot hình người.
Mọi người đều muốn làm robot hình người tổng quát, và đều cần lượng dữ liệu khổng lồ, đồng thời do vốn không ngừng đổ vào, toàn bộ đường đua vẫn trong tình trạng không thiếu tiền.
Vì vậy, đằng sau những công ty có nhu cầu dữ liệu mạnh mẽ, lại có đủ vốn nghiên cứu phát triển này, "người bán nước" thượng nguồn của ngành robot ngày càng nhiều, do đó dần hình thành chuỗi sản xuất dữ liệu của ngành công nghiệp robot.
Hơn nữa, cùng với sự phát triển của ngành, xoay quanh dữ liệu cần thiết cho huấn luyện robot, những công ty thượng nguồn này cũng bắt đầu hình thành sự phân tầng rõ ràng, từ cấu trúc ngành hiện tại, đại khái có thể chia thành năm loại người chơi.
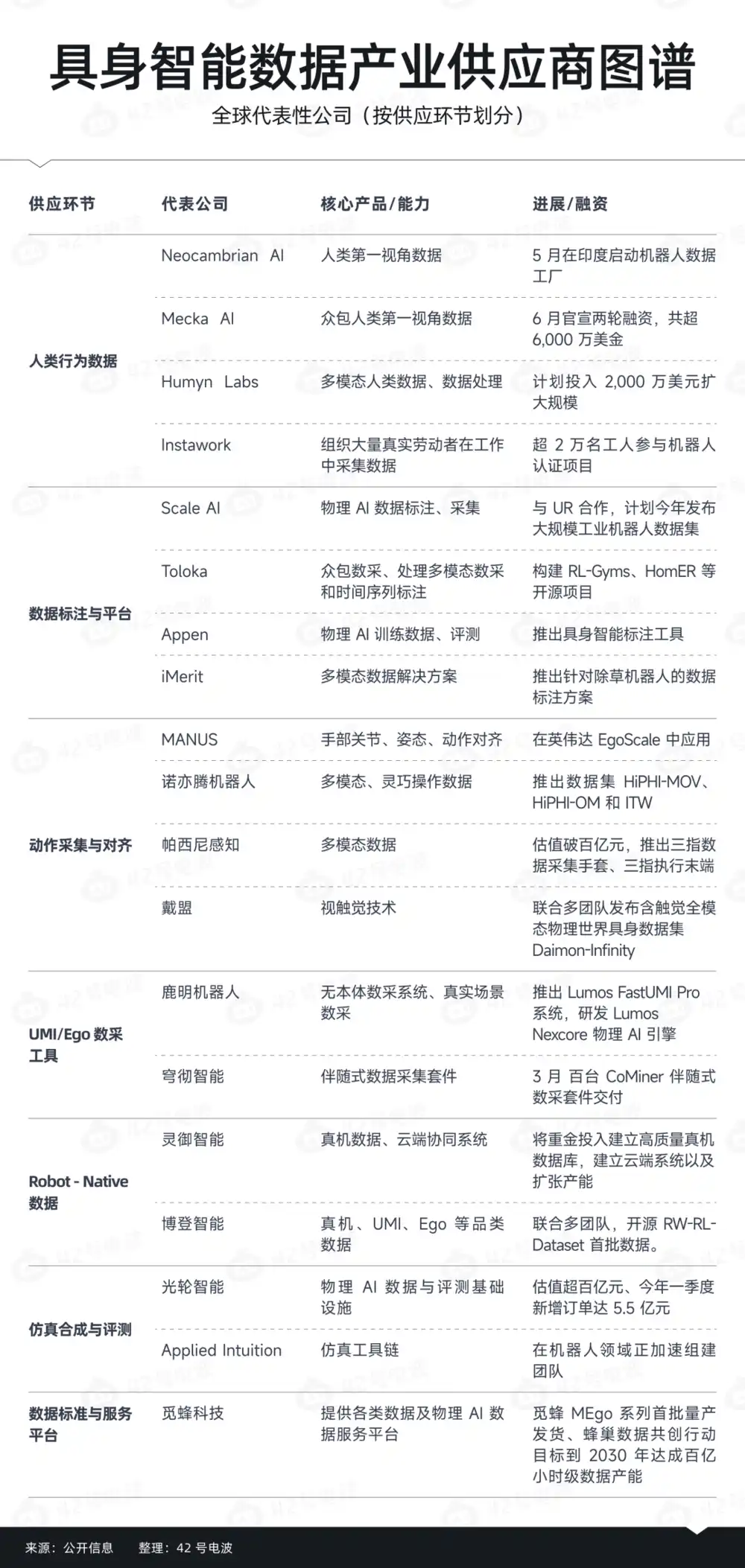
Loại thứ nhất là nhà máy dữ liệu chi phí thấp, trọng điểm thu thập là Ego Data, ở Ấn Độ, Thái Lan..., đã có ngày càng nhiều nhóm bắt đầu tổ chức lao động chi phí thấp, xây dựng mạng lưới thu thập dữ liệu.
Ví dụ, gần đây có một công ty khởi nghiệp tên Neocambrian AI, đã khởi động một dự án nhà máy dữ liệu robot tại Ấn Độ, thu thập dữ liệu động tác con người cho mô hình thể hóa, đặc biệt là Ego Data, người sáng lập của nó cũng đặc biệt nhấn mạnh Ấn Độ có lực lượng lao động khổng lồ, cũng là một lợi thế lớn cho việc phát triển bộ dữ liệu AI vật lý của họ.
Người thu thập dữ liệu đeo thiết bị camera đầu, găng tay bắt chuyển động, hoàn thành công việc theo quy trình nhiệm vụ, sau đó nhóm hậu cần tiến hành làm sạch, chú thích, nghiệm thu, cuối cùng giao hàng cho công ty robot.
Xét về mô hình kinh doanh, chúng rất giống với công ty chú thích dữ liệu phục vụ mô hình lớn những năm trước, chỉ là trước đây chú thích văn bản, hình ảnh và giọng nói, giờ bắt đầu sản xuất kinh nghiệm thế giới vật lý.
Một người trong ngành cũng nói với chúng tôi, trong năm qua, cảm thấy rõ ràng nhu cầu khách hàng nước ngoài đang tăng lên. Đặc biệt là các công ty robot Âu Mỹ, "họ đối với quy cách dữ liệu sẽ rõ ràng hơn, biết mình cần gì."
Bởi vì dữ liệu robot không đơn giản là "quay video", nhiều khách hàng thực sự cần là một bộ dữ liệu có thể trực tiếp vào đường ống huấn luyện, bao gồm chuỗi thời gian, hình ảnh đa góc nhìn, quỹ đạo động tác, trạng thái cảm biến, tư thế tay, metadata môi trường, và định dạng huấn luyện thích ứng cuối cùng.
Trong quá trình này, ngày càng nhiều công ty cũng phát hiện, chỉ dựa vào nhân lực chi phí thấp, thực sự rất khó hình thành rào cản lâu dài. Trong tương lai, những nhà máy dữ liệu chi phí thấp này, rào cản cạnh tranh lớn nhất vẫn là xem dữ liệu giao hàng có thể dễ dàng được sử dụng trực tiếp hơn không.
Và vấn đề cũng rất thực tế, loại hình kinh doanh này tự nhiên dễ hàng hóa hóa, một nhóm làm được, nhóm khác về lý thuyết cũng có thể làm, giá dần minh bạch, không gian lợi nhuận thường bị nén.
Vì vậy, khả năng giao hàng chi phí thấp, là ưu thế lớn nhất của họ, nhưng cũng có thể trở thành trần nhà.
Loại thứ hai là tầng thu thập và căn chỉnh động tác, so với chỉ thu video đơn thuần, loại người chơi này cố gắng giải quyết vấn đề "động tác được máy thực sự hiểu như thế nào", trọng điểm của họ không chỉ là lượng dữ liệu, biểu đạt động tác quan trọng hơn.
Ví dụ, găng tay dữ liệu, bắt chuyển động, theo dõi tay, chuyển hướng động tác, giao diện thu thập thao tác.
Bởi vì phần thực sự khó khăn của robot, nhiều lúc không phải là có nhìn hiểu không, mà là làm thế nào để động. Cũng là cầm một cái cốc, bàn tay khéo léo của robot khác nhau có bậc tự do khác nhau, cấu trúc đốt ngón tay khác nhau, khả năng điều khiển lực khác nhau.
Điều này sẽ tạo ra một vấn đề then chốt, động tác con người, làm thế nào để ánh xạ ổn định lên cơ thể robot khác nhau?
Vì vậy, ngày càng nhiều công ty bắt đầu quan tâm hơn đến chuyển hướng động tác, trong quá trình này, video chịu trách nhiệm cho robot biết con người đã làm gì, tầng động tác, thì trả lời thêm robot tự mình nên làm như thế nào.
Giá trị thực sự của tầng này, thường không phải là phần cứng bản thân, hoàn thành "dịch động tác" ổn định hơn là cốt lõi.
Loại thứ ba là tầng dữ liệu Robot-Native, thường là nhà cung cấp dịch vụ điều khiển từ xa bên thứ ba và dữ liệu thiết bị thực, đặc điểm cốt lõi nhất của loại người chơi này là gần với bản thân robot hơn, thậm chí nhiều lúc, bản thân cần liên kết sâu với công ty robot.
Bởi vì so với các phân khúc thu số liệu khác, dữ liệu thiết bị thực phụ thuộc cao vào lượng lớn robot cụ thể, và phần cứng robot của các công ty khác nhau không giống nhau, bậc tự do, không gian động tác, giao diện điều khiển có sự khác biệt lớn, cùng là một nhiệm vụ cầm nắm, đổi một robot khác có thể cần thu lại.
Trong quá trình đó, họ sẽ cung cấp, người điều khiển từ xa, địa điểm và khả năng thu thập thiết bị thực, giúp công ty robot tích lũy nhanh dữ liệu huấn luyện, đặc biệt là trong giai đoạn xác minh sớm của mô hình, khi công ty robot tự mình chưa có đủ đội ngũ và địa điểm, nhà cung cấp dịch vụ bên ngoài thường có thể khởi động nhanh hơn.
Loại thứ tư là công ty dữ liệu tổng hợp mô phỏng, họ không chỉ bán dữ liệu, trọng điểm là thử xây dựng một loại năng lực dữ liệu hoàn chỉnh hơn.
Trong khi sản xuất dữ liệu, cũng giúp khách hàng trả lời tại sao robot nhiệm vụ thất bại, và đợt dữ liệu tiếp theo nên thu như thế nào, đây là con đường mới nhiều công ty đang đi hiện nay.
Logic rất đơn giản, robot huấn luyện một ngày, có thể chỉ đủ tích lũy vài giờ quỹ đạo hiệu quả. Nhưng trong thế giới mô phỏng, cùng thời gian đó robot có thể thất bại hàng triệu lần, cầm nắm thất bại, lập kế hoạch đường đi sai, va chạm, ngã, đều có thể được lặp lại vô hạn.
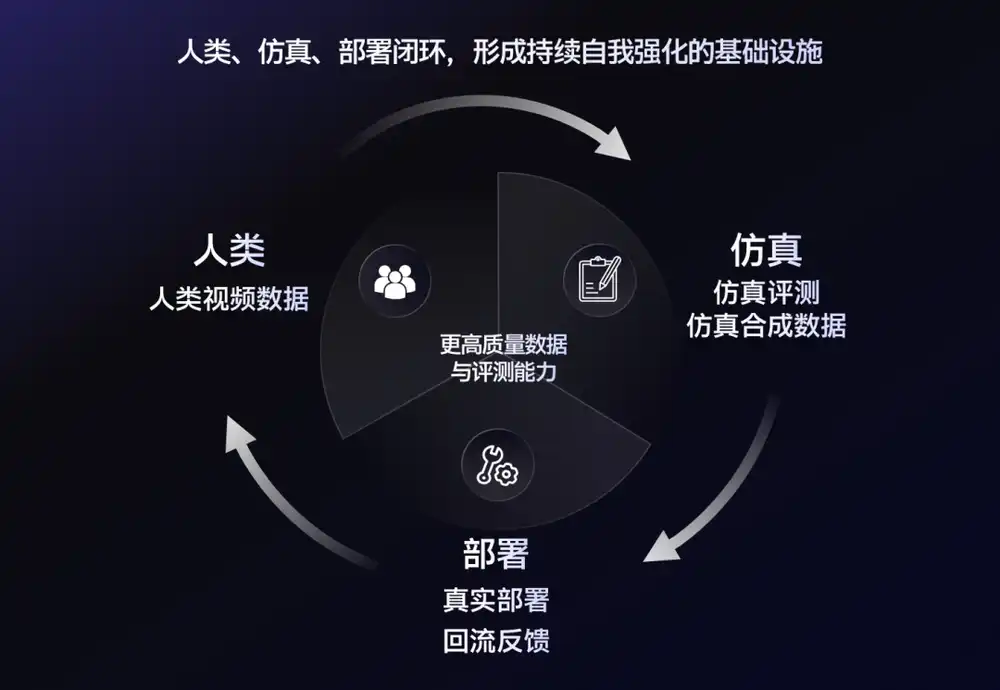
Vì vậy, ngành công nghiệp cũng bắt đầu dần hình thành một cách kết hợp mới, dữ liệu thực tế chịu trách nhiệm neo đậu hiện thực, dữ liệu tổng hợp mô phỏng chịu trách nhiệm mở rộng quy mô nhiệm vụ.
Nvidia trong lộ trình GR00T cũng nhiều lần nhấn mạnh, mô hình cơ bản robot không chỉ cần dữ liệu trình diễn con người, cũng cần lượng lớn dữ liệu tổng hợp. Nhà phát triển có thể thông qua thu thập thế giới thực để có được tri thức tiên nghiệm trước, sau đó nhờ mô phỏng mở rộng quy mô nhiệm vụ.
Mô hình trong mô phỏng thất bại càng nhiều, càng biết thiếu dữ liệu gì, và ai có thể sản xuất nhanh nhất những dữ liệu này, ai càng có cơ hội chiếm ưu thế.
Loại người chơi thứ năm thiên về tầng tiêu chuẩn và nền tảng dữ liệu, trong khi mở rộng quy mô dữ liệu, khám phá làm thế nào để bản thân việc cung cấp dữ liệu trở nên tiêu chuẩn hơn, dễ lưu thông hơn.
Bởi vì công ty robot ngày càng nhiều, dữ liệu cũng trở nên phân mảnh cao, cách thức thu thập khác nhau, biểu đạt động tác khác nhau, tiêu chuẩn định dạng khác nhau, cùng một bộ dữ liệu, nhiều lúc thậm chí khó trực tiếp tái sử dụng.
Trong bối cảnh này, các nỗ lực xung quanh tiêu chuẩn hóa dữ liệu thể hóa, thu thập phối hợp trong năm nay cũng bắt đầu tăng lên rõ ràng.
Đối với ngành robot hiện tại, thiếu dữ liệu chỉ là một trong các vấn đề, dữ liệu có thể tiếp tục ổn định sản sinh không, dễ vào quy trình huấn luyện hơn, cũng rất quan trọng.
Tuy nhiên, bất kể là người chơi dữ liệu con người, dữ liệu thiết bị thực hay mô phỏng..., cuối cùng đều phải trả lời một câu hỏi như vậy: công ty robot có giao những năng lực cốt lõi này cho nhà cung cấp bên ngoài không?
Bởi vì đối với hầu hết công ty thể hóa ngày nay, dữ liệu không chỉ là chi phí, mà còn là rào cản.
Công ty robot, rốt cuộc nên mua dữ liệu hay tự thu?
Bước vào năm nay, vị trí của dữ liệu trong ngành robot vô cùng quan trọng, mọi người đều biết robot thiếu dữ liệu.
So với trước đây, lựa chọn cung cấp dữ liệu trên thị trường ngày nay bắt đầu ngày càng nhiều, các loại dữ liệu khác nhau đều có nhà cung cấp để chọn, đối với công ty robot, việc mua dữ liệu bắt đầu ngày càng dễ dàng.
Nhưng tình hình thực tế lại có chút khác, một mặt là ngày càng nhiều công ty robot bắt đầu mua sắm dữ liệu, mặt khác là các công ty hàng đầu lại cố gắng xây dựng đội ngũ dữ liệu của riêng mình.
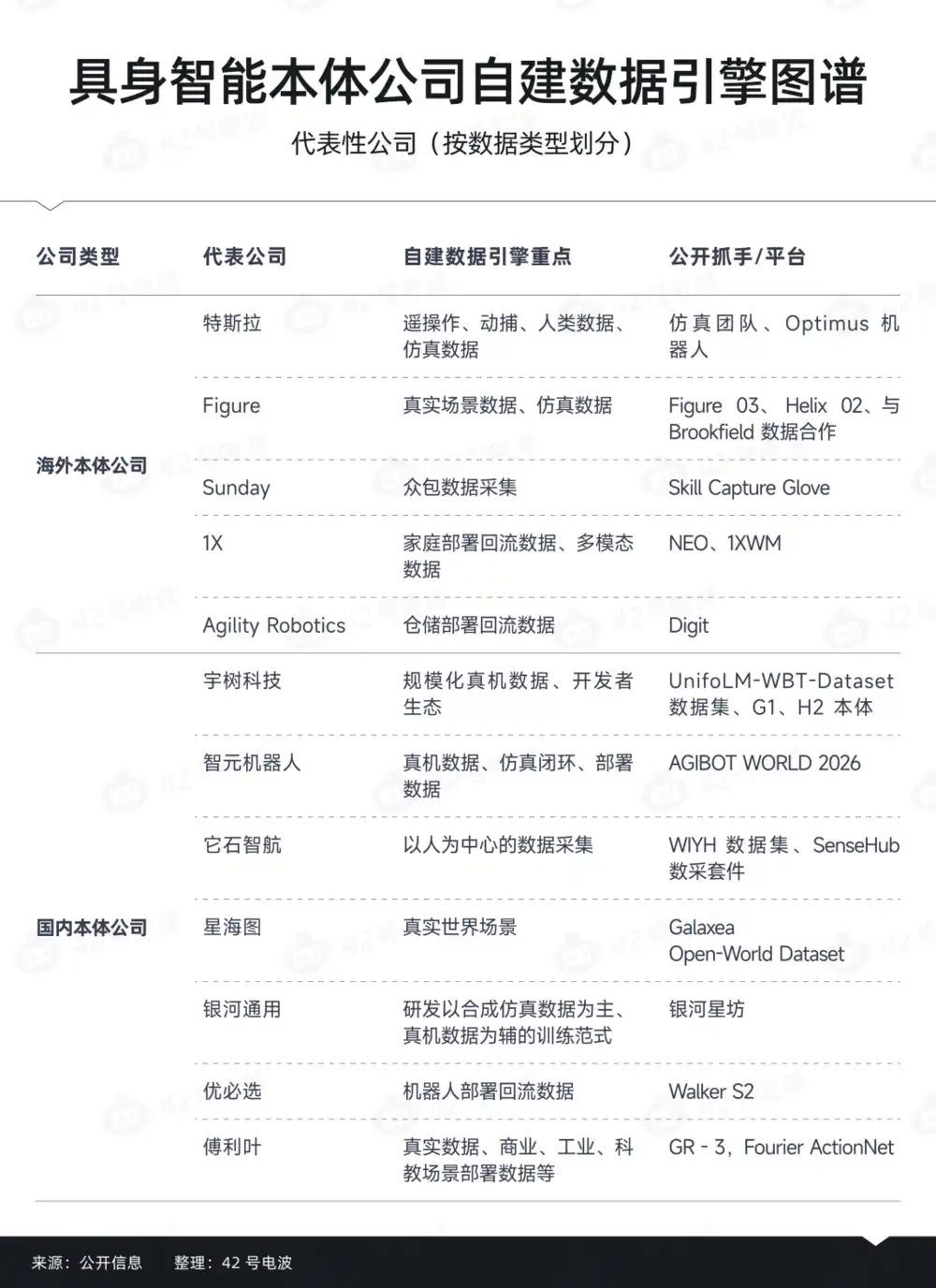
Nếu tách ra phía dưới, sẽ phát hiện dữ liệu khác nhau, quyết định cách thức tổ chức hoàn toàn khác nhau.
Ở một mức độ nào đó, công ty robot thực sự hình thành là logic "mua sắm phân tầng".
Trong đó, tầng thứ nhất là dữ liệu tổng quát cơ bản, đây là tầng dễ bị thuê ngoài nhất.
Ví dụ, sắp xếp nhà bếp, dọn dẹp bàn, cầm nắm cơ bản, phân loại, vận chuyển... những hành vi này, loại dữ liệu này có một đặc điểm chung, bất kể robot trông như thế nào, cuối cùng đều cần hiểu con người hoàn thành nhiệm vụ như thế nào.
Ví dụ, một robot vào nhà bếp sau, khi nào thì dọn một tay trước, khi nào thì sắp xếp vật lớn trước, rồi sắp xếp vật nhỏ, khi đồ vật quá nhiều, không gian làm thế nào lập kế hoạch lại?
Những năng lực này về bản chất thuộc về nhận thức thế giới vật lý tổng quát, không phải là năng lực độc chiếm của một robot nào đó.
Loại dữ liệu Ego tương tự như vậy nếu tự thu từ đầu, cần dựng đội ngũ, chi phí quản lý tương đối cao.
Trong khi đó, đội ngũ bên ngoài có thể mở rộng quy mô thu thập nhanh ở các khu vực như Đông Nam Á, Ấn Độ..., một tháng có thể ổn định sản xuất hàng nghìn giờ.
Đối với công ty robot, nhiều lúc mua trước, so với tự xây đội ngũ thì hợp lý hơn. Bởi vì ở giai đoạn này mục tiêu không phải là để robot làm việc ổn định, mà là hiểu thế giới trước.
Vì vậy, loại dữ liệu này thuê ngoài là hợp lý, thậm chí là lựa chọn hiệu quả hơn.
Tầng thứ hai là dữ liệu thích ứng thể hóa, công ty robot sẽ có xu hướng tự thu hơn.
Sau khi tiền huấn luyện thông qua lượng lớn dữ liệu cơ bản, lúc này huấn luyện bắt đầu liên quan đến liên kết cốt lõi thực sự robot triển khai, căn chỉnh nhiệm vụ.
Vì vậy, logic bắt đầu xuất hiện thay đổi, bởi vì bản thân robot của mỗi công ty có sự khác biệt lớn, bậc tự do khác nhau, bàn tay khéo léo khác nhau, năng lực các khía cạnh như khớp cũng khác nhau. Logic động tác mà robot cuối cùng cần học, cũng sẽ có sự khác biệt lớn.
Càng gần tầng thực hiện động tác, dữ liệu càng khó tổng quát. Vì vậy, nhiều công ty dù mua lượng lớn Ego Data, nhưng vẫn xây dựng đội ngũ thu số liệu nội bộ, tiến hành thu thập dữ liệu thiết bị thực. Bởi vì tầng này, đã bắt đầu tiếp cận sức cạnh tranh thực sự của mô hình.
Tầng thứ ba là dữ liệu triển khai và dữ liệu thất bại, đây là tầng khá then chốt, thường sinh ra sau khi triển khai thực tế.
Sau khi robot được triển khai vào môi trường ứng dụng thực tế, môi trường làm việc thực sự của nó thường gặp phải các tình huống ngẫu nhiên đa dạng, những dữ liệu triển khai sinh ra trong các tình huống thực tế này, bất kể là thành công hay thất bại, đều cực kỳ có giá trị, và trong việc thu thập dữ liệu tiền trạm rất ít gặp, khó được thiết kế trước, chỉ có thể tích lũy từng chút một trong môi trường thực tế.
Hơn nữa, nhiều công ty cũng khó triển khai robot của mình với số lượng lớn vào tình huống thực tế, vì vậy dữ liệu triển khai thực tế thì không cần bàn đến.
Trong quá trình triển khai, robot trong môi trường biến đổi không ngừng tích lũy, ngay cả dữ liệu thất bại, cũng giúp đội ngũ tìm ra nguyên nhân có trọng điểm, và đưa ra đối sách, từ đó tối ưu hóa mô hình, rồi thúc đ đẩy việc triển khai quy mô của robot.
Những điều này thuộc về dữ liệu cốt lõi của công ty robot hàng đầu, cũng là rào cản phân biệt họ với đối thủ cạnh tranh.
Điều này ở một mức độ nhất định cũng hạn chế trần nhà của công ty dữ liệu, chúng có thể giúp robot "nhập môn", dữ liệu thực sự quyết định trần năng lực, nhiều công ty hàng đầu cuối cùng vẫn sẽ chọn tự nắm giữ.
Vì vậy, hai con đường khác nhau phân hóa của ngành dữ liệu cũng có dấu vết để theo, một là nhà máy dữ liệu, một là động cơ dữ liệu.
Nhà máy dữ liệu là loại công ty xuất hiện nhanh nhất, số lượng nhiều nhất, cũng dễ hình thành dòng tiền nhất hiện nay trong ngành.
Trong đó, nhà máy dữ liệu chi phí thấp coi trọng hơn dữ liệu hành vi con người, dựa vào ưu thế lao động chi phí thấp, tính phí theo giờ, theo đuổi quy mô và khả năng giao hàng, dòng tiền có thể nhanh chóng chuyển dương, nhưng rào cản hạn chế, người cạnh tranh tham gia đang nhanh chóng tăng lên, đặc biệt là sau EgoScale, lượng lớn công ty khởi nghiệp bắt đầu đổ vào dữ liệu con người.
Nhà máy dữ liệu phức tạp cao hơn, trên cơ sở bao phủ dữ liệu hành vi con người, triển khai hàng loạt robot, thông qua cách thức điều khiển từ xa hoặc bản thân vận hành độc lập, thu thập lượng lớn dữ liệu thiết bị thực.
Một con đường khác, cố gắng làm động cơ dữ liệu, sắp xếp hệ thống phân loại nhiệm vụ, xây dựng cấu trúc dữ liệu, thực hiện chuyển hướng động tác, kết nối nền tảng mô phỏng, triển khai đánh giá mô hình, và dựa vào mẫu thất bại của mô hình lặp lại sản xuất ngược bộ dữ liệu.
Nói cách khác, việc họ đang làm không chỉ là bán dữ liệu, trọng điểm là để robot có khả năng tiếp tục trở nên thông minh.
Scale AI phiên bản robot, sẽ xuất hiện không?
Đặt ngành robot ngày nay, quay lại mô hình lớn năm 2022, sẽ phát hiện một cảm giác tương tự.
Ngành công nghiệp lúc đó cũng phát hiện, thứ thực sự quyết định trần năng lực của mô hình, là dữ liệu.
Do đó, xoay quanh các lĩnh vực như làm sạch dữ liệu, RLHF, đánh giá, hậu huấn luyện..., một loạt công ty mới cũng bắt đầu nhanh chóng trỗi dậy, kinh điển nhất là Scale AI.
Công ty này trong giai đoạn đầu giúp công ty lái xe tự động gắn nhãn dữ liệu, từ năm 2019, Scale AI trong giai đoạn GPT-2 đã liên kết sâu với OpenAI, nhận gắn nhãn phản hồi con người RLHF, đánh giá mô hình lớn, kiểm tra đội đỏ, tạo dữ liệu ngược trường hợp biên.
Sau khi ChatGPT bùng nổ, Meta Llama, Anthropic, Microsoft Azure... nhanh chóng kết nối, nhu cầu gắn nhãn chất lượng cao, đánh giá, dữ liệu tổng hợp của mô hình lớn tăng mạnh, doanh thu của công ty này trong 3 năm tăng hơn 4 lần.
Sau này, công ty này cũng bắt đầu dần đi vào tầng cơ sở hạ tầng sâu hơn, quản lý dữ liệu, đánh giá mô hình, quy trình làm việc AI.
Bởi vì kinh nghiệm thành công của Scale AI, nhiều người cũng mong mỏi, ngành robot, có sẽ xuất hiện một công ty tương tự không?
Từ mức độ thiếu hụt dữ liệu hiện tại, rất có thể, nhưng cũng sẽ không hoàn toàn sao chép.
Bởi vì dữ liệu cần thiết của robot phức tạp hơn nhiều so với văn bản, đối với mô hình lớn, một câu trả lời đúng sai tương đối dễ phán đoán. Nhưng trong thế giới robot, một động tác có thành công không, thường đầy mơ hồ.
Cốc cầm lên rồi, nhưng góc độ không đúng. Đồ đặt lại rồi, nhưng làm đổ vật thể khác, và nhiều lúc bản thân hoàn thành nhiệm vụ tồn tại nhiều đường đúng.
Vì vậy, ngành robot thực sự cần, không phải là một nền tảng dữ liệu đơn giản, trọng điểm là toàn bộ vòng lặp khép kín dữ liệu từ thu thập, gắn nhãn, ánh xạ động tác, mở rộng mô phỏng, đánh giá mô hình, phản hồi thất bại.
Robot thực sự thiếu không chỉ là dữ liệu, khả năng sản xuất liên tục kinh nghiệm hiệu quả càng khan hiếm hơn.
Vì vậy, ngày càng nhiều công ty bắt đầu chuyển trọng tâm cạnh tranh, từ bản thân robot, kiến trúc mô hình sang hệ thống dữ liệu.
Từ đầu năm nay, bất kể là Figure, 1X, PI, hay lộ trình GR00T do NVIDIA thúc đẩy, đều lặp đi lặp lại nhấn mạnh một hướng chung, sự tăng trưởng năng lực của robot, nâng cấp phần cứng chỉ là một phần, nhiều dữ liệu hơn và huấn luyện hiệu quả hơn bắt đầu trở thành nhân vật chính.
Ở một mức độ nào đó, trong giai đoạn ngành robot mở ra sản xuất hàng loạt và triển khai, mọi người cũng đang từ "chế tạo máy" bước vào thời kỳ mới "cho máy ăn".
Trong giai đoạn robot còn chưa đứng lên, chưa đi được, sức cạnh tranh lớn nhất của công ty thể hóa là có thể làm tốt phần cứng và điều khiển vận động không.
Nhưng khi robot có thể chạy có thể nhảy, thành tích trên nhiều cuộc thi có thể vượt qua con người, năng lực làm việc tự chủ lại trở thành mục tiêu lớn nhất của ngành, dưới sự thúc đẩy của mục tiêu này, chủ âm của ngành trở thành dữ liệu chất lượng cao quy mô lớn.
Robot muốn tiếp tục thành công trong thế giới thực phức tạp, cần thấy đủ nhiều nhiệm vụ tồn tại thực sự trong không gian vật lý, biết cốc có thể đổ, quần áo có thể vướng, không gian có thể không đủ, những kinh nghiệm này, không tự nhiên tồn tại trong Internet, nó chỉ có thể được sản xuất ra từng chút.
Vì vậy, chuỗi ngành công nghiệp dữ liệu này, cũng đằng sau cơn sốt robot hai năm nay, lặng lẽ định hình.
Ở một đầu chuỗi, là con người đeo camera trong nhà máy Ấn Độ, là robot không ngừng ngã trong mô phỏng.
Đầu kia, là các công ty robot định giá hàng chục tỷ, trăm tỷ, thậm chí nghìn tỷ, họ đang cố gắng để robot thực sự bước vào gia đình, bước vào nhà máy.
Từ nhà máy dữ liệu Ấn Độ, robot trong mô phỏng, đến các công ty robot lớn trên toàn cầu, một chuỗi sản xuất mới đã bắt đầu hình thành, chỉ là lần này, thứ được sản xuất không còn là linh kiện, mà là dữ liệu.
Bài viết này đến từ tài khoản công chúng WeChat: 42 Megahertz , tác giả: Lanbo, biên tập: James, tiêu đề gốc: 《Robot đã bắt đầu 'ăn' dữ liệu: Từ nhà máy dữ liệu Ấn Độ đến chuỗi sản xuất ngầm của robot hình người trị giá hàng tỷ USD》





