「Deep Think」đánh bại/sánh ngang đối thủ trong mọi cuộc thi!
Vừa qua, nhà nghiên cứu cấp cao Google DeepMind Conglong Li đã đăng 12 bài liên tiếp trên nền tảng X, công bố một bảng điểm chưa từng thấy.

Một AI, cùng một bộ não, tám đề thi ngôn ngữ khác nhau, tất cả đều nộp bài với điểm số cao.
Ở bất kỳ mô hình nào, thành tích như vậy thực sự hiếm thấy.
Từ huy chương vàng IMO đến phủ sóng giải khu vực
Việc Deep Think đạt điểm cao trên nhiều bảng xếp hạng lần này không phải là một sự bùng nổ đơn lẻ đột ngột, mà là một đường cong phát triển năng lực đã diễn ra gần một năm.
Đầu tiên là đứng đầu trên đấu trường suy luận khó nhất.
Tháng 7/2025, Gemini Deep Think lần đầu tiên đạt tiêu chuẩn huy chương vàng tại Olympic Toán học Quốc tế (IMO), đạt 35/42 điểm. Cùng kỳ cũng đạt thành tích cao tương tự tại chung kết thế giới ICPC.
Hai thành tích này đã được DeepMind chính thức công bố trên blog.
Google DeepMind sau đó đã đưa hai thành tích này vào blog chính thức, như một dấu mốc cho việc Deep Think vượt qua "ngưỡng thi đấu thế giới" về toán học và lập trình.
Tiếp theo, Deep Think bắt đầu chuyển từ "đột phá đơn lẻ đẳng cấp vô địch thế giới" sang "xác minh hệ thống đa ngôn ngữ, đa lĩnh vực, đa tình huống".
Tháng 2/2026, Google đã liên tiếp đăng ba blog.
Một bài giới thiệu mô hình chính Gemini 3.1 Pro, một bài giới thiệu bản nâng cấp lớn cho chế độ suy luận chuyên dụng Deep Think, và một bài từ nhóm khám phá khoa học DeepMind, trực tiếp định vị Deep Think là "công cụ khuếch đại trí tuệ con người".
Deep Think sau khi nâng cấp đã đưa ra một loạt chỉ tiêu cứng:
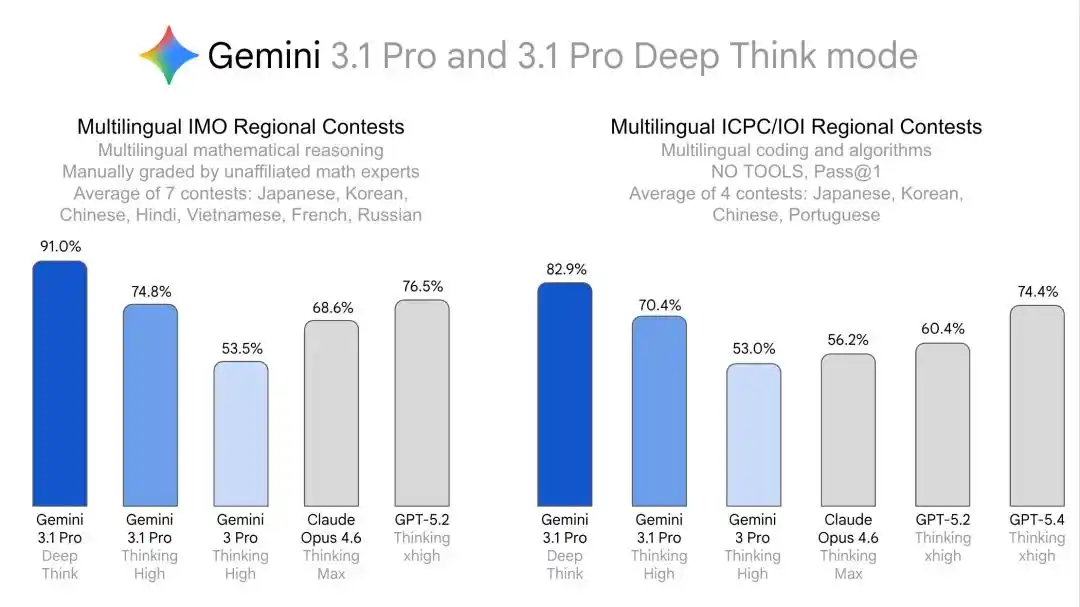
Humanity's Last Exam đạt 48.4% (không có trợ giúp công cụ), ARC-AGI-2 đạt 84.6% (được xác minh chính thức bởi Quỹ ARC Prize), điểm Elo lập trình thi đấu Codeforces là 3455, phần thi viết của Olympic Vật lý và Hóa học Quốc tế 2025 đạt trình độ huy chương vàng.
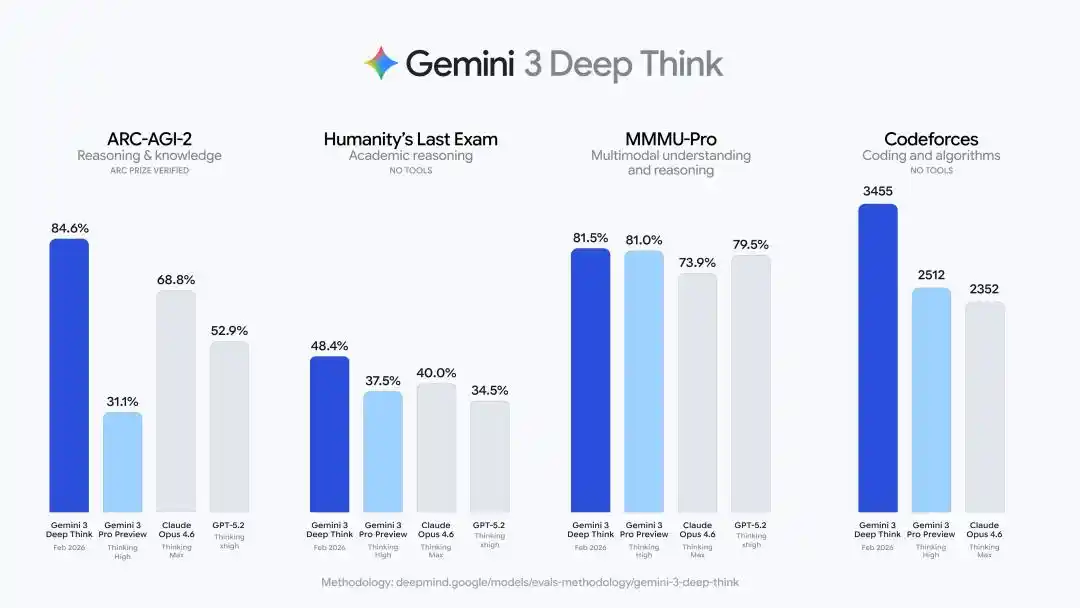
Lộ trình này rất rõ ràng: đầu tiên sử dụng các cuộc thi đẳng cấp thế giới như IMO, ICPC để chứng minh khả năng suy luận mạnh mẽ của nó, sau đó sử dụng thành tích đa ngôn ngữ, giải khu vực và Olympic đa lĩnh vực để chứng minh khả năng suy luận sâu tổng quát có thể di chuyển ổn định xuyên ngôn ngữ và lĩnh vực.
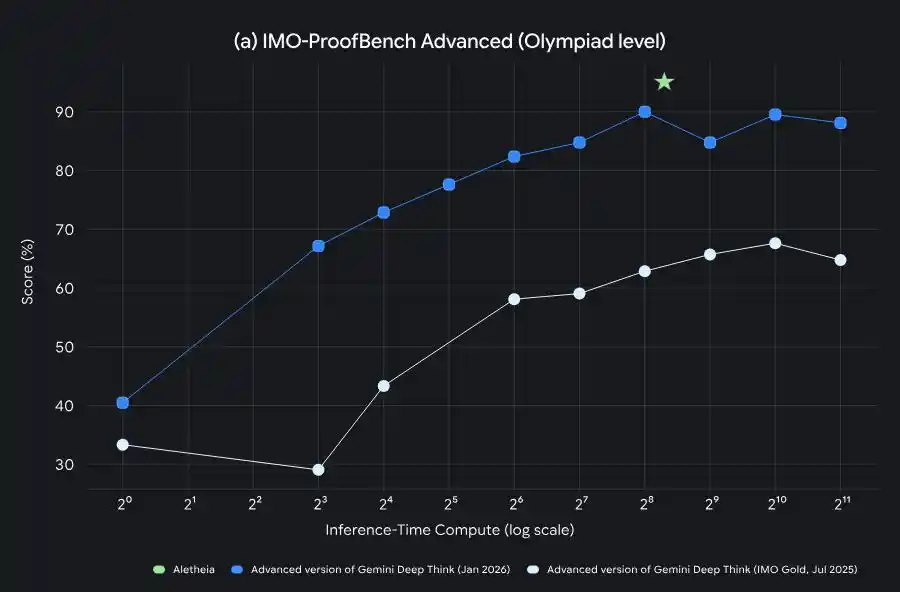
Sự phát triển năng lực của Gemini Deep Think từ huy chương vàng IMO đến tăng tốc nghiên cứu cấp Tiến sĩ
Xem xét chi tiết từng thành tích trong bảng điểm 8 ngôn ngữ
Bây giờ, hãy thực sự mở bảng điểm này ra xem.
Tiếng Nhật nổi bật nhất.
Kỳ thi chọn Olympic Toán học Nhật Bản lần thứ 35 năm 2025 (JMO Finals), điểm tuyệt đối.
Vòng sơ khảo ICPC châu Á tại Nhật Bản, điểm tuyệt đối.
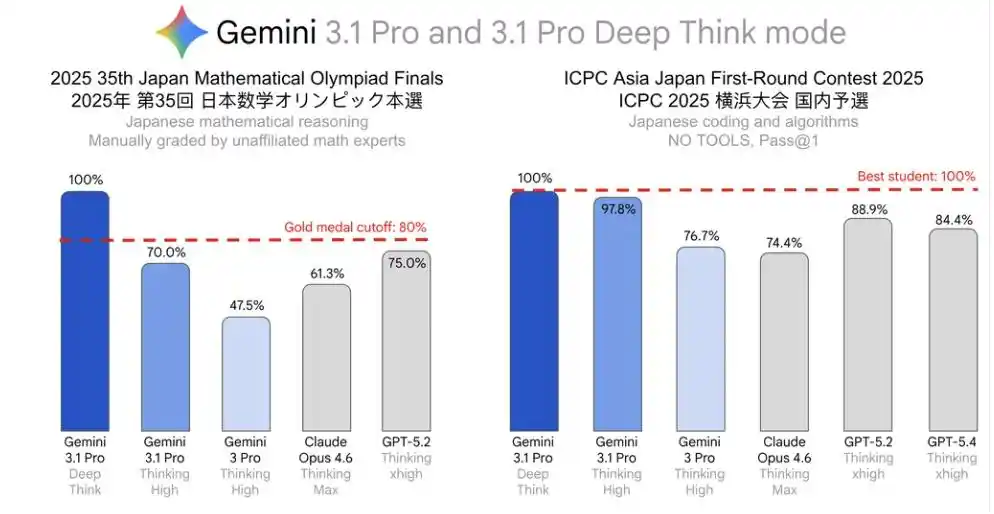
Trong đó, thành tích tại JMO Finals thậm chí còn vượt quá mức 80% tương ứng với điểm cao nhất của kỳ thi đó, đạt tiêu chuẩn "tương đương huy chương vàng" theo thông báo chính thức.
Tiếng Pháp cũng đạt điểm tuyệt đối, 100%.
Tiếng Trung thì thú vị.
Tại Olympic Toán học Trung Quốc lần thứ 41 (CMO), Deep Think đạt 86.3%, rất xuất sắc. Nhưng tại Olympic Tin học Trung Quốc (NOI) chỉ đạt 63.3%.
Khoảng cách giữa 86.3% và 63.3% đã vẽ ra ranh giới thực sự của khả năng suy luận AI.
Trong các kỳ thi toán, mô hình đối mặt với suy diễn trừu tượng, xây dựng chứng minh và diễn dịch nhiều bước, đây chính xác là dải năng lực mà Deep Think giỏi nhất.
Nhưng đến các kỳ thi tin học, vấn đề không chỉ là "nghĩ thông suốt", mà còn bao gồm việc dịch logic thành mã thực thi, kiểm soát điều kiện biên, cân nhắc các ràng buộc độ phức tạp, và tránh sai sót ở cấp độ triển khai.
Cái trước gần hơn với suy luận thuần túy, cái sau yêu cầu đồng thời đạt chuẩn "suy luận + thiết kế thuật toán + triển khai kỹ thuật".
Ở các ngôn ngữ khác như Hàn Quốc, Hindi, Việt Nam, Nga, Bồ Đào Nha trong các kết quả thi tương ứng, Deep Think cũng đều đánh bại đối thủ hoặc ít nhất là ngang bằng.
Nếu gộp tiếng Nhật, tiếng Pháp, tiếng Trung lại để xem, điểm bất thường nhất lần này thực ra không phải là một môn đơn lẻ nào đó đạt điểm tuyệt đối, mà là cùng một mô hình, cùng một hệ thống suy luận Deep Think, trên đề thi của nhiều ngôn ngữ khác nhau, đều giao nộp thành tích thuộc nhóm dẫn đầu.
Bảng điểm này có đáng tin không?
Nhưng ở đây có một thiếu sót then chốt:
Conglong Li đã không liệt kê dữ liệu so sánh cụ thể của các đối thủ cạnh tranh: tất cả thành tích đều đến từ đánh giá nội bộ của Google. Không có xác minh độc lập của bên thứ ba, không có chứng nhận chính thức từ ban tổ chức cuộc thi, phương pháp đánh giá hoàn toàn không được công khai.
Mỗi bài tập được làm một lần hay làm nhiều lần lấy kết quả tốt nhất? Sử dụng bao nhiêu năng lực tính toán khi suy luận? Có can thiệp của kỹ thuật gợi ý nhân tạo không?
Những chi tiết này ảnh hưởng trực tiếp đến hàm lượng vàng của thành tích, cũng đều không được đề cập.
Một điểm dễ bị bỏ qua khác: tất cả các kỳ thi này đều là vòng chọn khu vực của các quốc gia, không phải chung kết quốc tế.
Giữa độ khó của đề thi khu vực và chung kết quốc tế, cách nhau một cấp độ.
Nhà nghiên cứu đã nói rõ, những thành tích này "sẽ được đưa vào thẻ mô hình (model card)", tính đến thời điểm phát hành, thẻ mô hình vẫn chưa được cập nhật chính thức.
Vì vậy, hiện tại đây dường như vẫn là một bảng điểm do thí sinh tự chấm điểm, tự công bố, chưa nộp cho phòng giáo vụ đóng dấu.
Tính công bằng nghiên cứu đa ngôn ngữ, chiến trường thực sự bị bỏ qua
Tại sao Google lại dành sức lực đặc biệt để đánh giá giải khu vực bằng 8 ngôn ngữ?
Việc đánh giá năng lực suy luận AI hiện tại, hầu như hoàn toàn dựa trên tiếng Anh.
MATH, GSM8K, HumanEval, ARC-AGI...... tất cả đều là tiếng Anh.
Các nhà toán học, vật lý học, kỹ sư trên toàn thế giới, chỉ cần tiếng mẹ đẻ không phải là tiếng Anh, khi sử dụng công cụ nghiên cứu AI đều phải vượt qua một rào cản ngôn ngữ.
8 ngôn ngữ Google chọn không phải ngẫu nhiên.
Tiếng Nhật, Hàn Quốc, Trung Quốc bao phủ trọng điểm nghiên cứu Đông Á, Hindi, Việt Nam bao phủ thị trường mới nổi, tiếng Pháp, Nga, Bồ Đào Nha bao phủ châu Âu và Nam Mỹ.
Cộng lại, đây là phần lớn sản lượng nghiên cứu toàn cầu.
DeepMind trong blog chính thức đã định vị Deep Think là "công cụ khuếch đại trí tuệ con người", nói rằng nó có thể "xử lý truy xuất kiến thức và xác minh nghiêm ngặt, để các nhà khoa học tập trung vào chiều sâu khái niệm và định hướng sáng tạo".
Kết hợp với thành tích đa ngôn ngữ lần này, hàm ý của câu nói này không khó hiểu: công cụ khuếch đại này, không chỉ dành cho các nhà khoa học nói tiếng Anh.
Đáng chú ý hơn là Deep Think đã đi được bao xa trong việc ứng dụng nghiên cứu.
DeepMind đã công bố một tác nhân nghiên cứu toán học tên là Aletheia, dựa trên Deep Think, có thể tự động tạo, xác minh, sửa đổi giải pháp cho các vấn đề toán học cấp nghiên cứu.
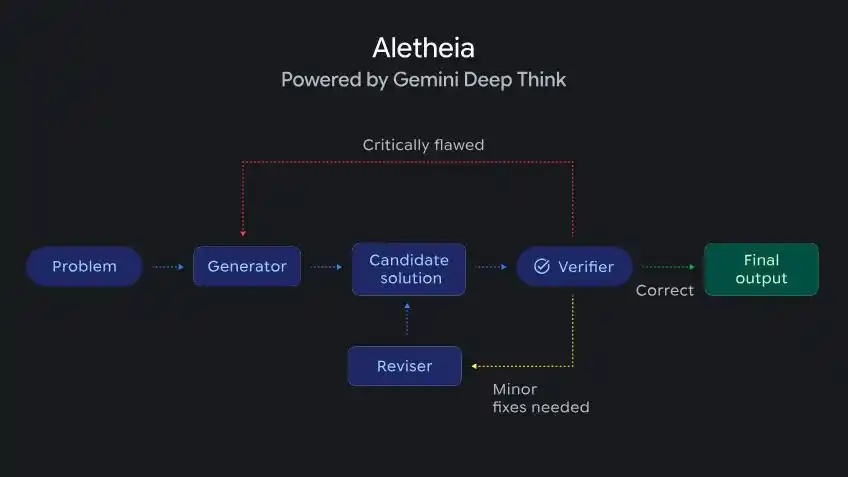
Aletheia được điều khiển bởi Deep Think, có khả năng tạo lặp, xác minh và sửa chữa đối với các vấn đề toán học cấp nghiên cứu
Aletheia đã tham gia tạo ra nhiều bài báo nghiên cứu, trong đó một bài hoàn toàn do AI tự chủ hoàn thành, tính toán hằng số cấu trúc cụ thể trong hình học số học.

Ngoài ra, trong đánh giá bán tự chủ 700 vấn đề toán học mở, nó còn tự giải quyết độc lập 4 vấn đề trước đó chưa có lời giải.
Chế độ Gemini Deep Think cũng thể hiện tiềm năng to lớn trong các lĩnh vực như khoa học máy tính, vật lý học, kinh tế học.
Trong lĩnh vực khoa học máy tính, Deep Think giúp lật đổ một giả thuyết tồn tại mười năm chưa giải quyết, trong lĩnh vực vật lý tìm ra nghiệm giải tích mới cho bức xạ hấp dẫn của dây vũ trụ, trong lĩnh vực kinh tế mở rộng một định lý lý thuyết đấu giá.
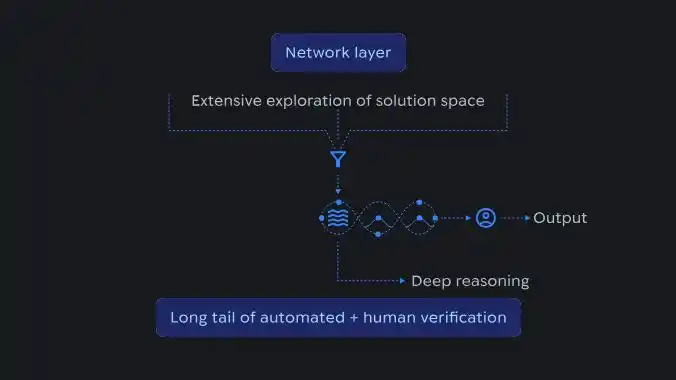
Sơ đồ quy trình suy luận AI, cho thấy việc khám phá không gian giải pháp quy mô lớn ở lớp mạng được tổng hợp thành suy luận có cấu trúc như thế nào, và được xác nhận thông qua xác minh tự động và nhân tạo.
Thông qua hợp tác với chuyên gia giải quyết 18 vấn đề nghiên cứu hóc búa, phiên bản nâng cao của Gemini Deep Think đã giúp đột phá các nút thắt cổ chai tồn tại lâu dài trong các lĩnh vực thuật toán, học máy và tối ưu hóa tổ hợp, lý thuyết thông tin và kinh tế học.
Điều này đã vượt xa phạm vi "giải bài tập thi".
Khi các đối thủ cạnh tranh vẫn còn xoay quanh bảng xếp hạng benchmark tiếng Anh, Google đã tìm thấy một chiến trường mới trong lĩnh vực "công cụ tăng tốc nghiên cứu AI".
Thứ quan trọng nhất của sự việc này thực ra không phải là điểm số, tín hiệu thực sự đằng sau nó là: rào cản ngôn ngữ của công cụ nghiên cứu AI đang được coi là một vấn đề kỹ thuật để giải quyết.
Nếu con đường này thành công, các nhà khoa học nghiên cứu bằng tiếng Nhật, Hàn Quốc, Trung Quốc, Hindi trên toàn thế giới, lần đầu tiên sẽ đứng trên cùng một vạch xuất phát với những người nói tiếng Anh bản ngữ.
Lần này, Google đã đặt bài lên bàn.
Còn đối thủ cạnh tranh nào sẽ theo bài, tin rằng chúng ta cũng sẽ sớm thấy.
Tài liệu tham khảo:
https://blog.google/intl/ja-jp/company-news/technology/gemini-31-pro-gemini-31-pro-deep-think/%20
https://deepmind.google/blog/accelerating-mathematical-and-scientific-discovery-with-gemini-deep-think/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-deep-think/
Bài viết từ tài khoản WeChat công cộng "Tân Trí Nguyên" (新智元), tác giả: Tân Trí Nguyên