By Alter
On the morning of April 24th, the long-awaited DeepSeek V4 finally made its appearance.
That same day, DeepSeek-V4-Pro immediately topped the Hugging Face open-source model leaderboard, with two "bombshell innovations" being widely praised:
First, a million-token-level ultra-long context, but with a KV cache only 10% that of V3.2, praised by Amazon engineers as a solution to the HBM shortage problem;
Second, its adaptation to domestic chips, having closely collaborated with Huawei during R&D and promptly adapted to domestic chips like Ascend and Cambricon.
Coincidentally, ranked second on the Hugging Face open-source model leaderboard was Kimi K2.6, which was released and open-sourced late on April 20th.
If this were happening across the Pacific, the "clash" of two trillion-parameter models would inevitably lead to mutual attacks over valuations and commercial territories. Domestically, however, a completely different scene unfolded: there was no drama of exposing each other's secrets, no undercurrents of PR warfare, and even a "swap" at the technical foundation.
Behind this "unusual" situation lies a divergence in AI technology paths between China and the U.S.: Silicon Valley is frantically "erecting high walls," trying to protect vested interests through closed-source models; Chinese large model vendors, however, are choosing to "tear down the walls," moving toward collaborative evolution on the soil of open source.
01 Silicon Valley Trapped in a "Game of Thrones"
Unlike the open-source approach flourishing domestically, Silicon Valley's AI leaders—OpenAI, Anthropic, and Google's Gemini—are all staunch advocates of closed-source models.
As cutting-edge technological innovations are locked away in their respective data centers, under the pressure of computing costs and market expectations, the "Silicon Valley spirit" known for openness and collaboration is gradually fading. Players inevitably find themselves in a zero-sum "game of thrones."
Over the past two years, technical "shadow wars" have evolved into public spats. The most typical tactic is mutual "spotlight stealing": quickly unveiling their own major updates at competitors' key product launch moments to curb the other's momentum has become a routine operation in Silicon Valley.
As early as May 2024, OpenAI and Google simultaneously released new AI products, one claiming GPT-4o was globally leading, the other touting the Gemini family's coverage of the entire ecosystem and path. Eventually, the CEOs of both companies couldn't sit still, publicly mocking each other on social media.
It's not just a "tangle" with Google; the rivalry between OpenAI and Anthropic has also intensified: on April 16th, just after Anthropic released its new model Claude Opus 4.7, OpenAI announced a major update to Codex over two hours later, proclaiming "Codex for (almost) everything." It was clear to everyone that the timing was no coincidence but a carefully planned "snipe" by OpenAI against Anthropic.
Beyond the "cultural fights" in the court of public opinion, "military fights" of mutual "exposure" have also become the norm in Silicon Valley.
Anthropic proudly announced on April 7th that its annualized revenue had reached $30 billion, successfully surpassing OpenAI's $25 billion.
A week later, OpenAI's Chief Revenue Officer stated bluntly in an internal letter to all employees: Anthropic's claimed $30 billion in annualized revenue was seriously inflated because it used the "gross method," fully counting the share given to cloud service providers like Amazon and Google into its total revenue, resulting in an overestimation of about $8 billion.
The practice of undermining competitors in internal letters is uncommon in the tech industry, aiming无非是告诉投资人——Anthropic's growth myth is inflated.
And once hostility breeds, it permeates every decision.
After Anthropic "fell out" with the Pentagon for refusing to delete specific security clauses from a contract, OpenAI announced within hours that it had reached a cooperation agreement with the U.S. Department of Defense.
During the 2026 Super Bowl, Anthropic heavily advertised with a commercial whose content was "Advertising is entering the AI field, but it won't enter Claude." This was essentially a direct challenge to OpenAI, which had just begun testing ad features.......
Why have former "brothers-in-arms" come to such loggerheads?
The root lies in the inherent logic of the closed-source business model: the survival foundation of closed source is building moats, and the prerequisite for building moats is blocking technology diffusion, monopolizing the most advanced productivity. Coupled with incompatible technical routes and opposing product narratives, it naturally forms a Nash equilibrium: whoever "ceases fire" first will see their brand narrative collapse, ultimately sinking deeper into the quagmire of internal consumption.
02 The "Collaborative Evolution" of the Open-Source Camp
Turning the focus back to China, the script unfolds completely differently.
Rewind to over a year ago, the emergence of DeepSeek-R1 slammed the brakes on the狂奔的大模型创业赛 (frantic large model startup race), with the finalist large model "Six Little Tigers" being the first affected. The biggest difference from Silicon Valley is that DeepSeek did not play the role of a "shark" eating all the fish in the pond, but rather acted like a catfish that activated the entire Chinese large model ecosystem, leading everyone to embrace open source.
A direct example is Moonlight (Yue Zhi An Mian - 月之暗面), whose growth trajectory highly overlaps with DeepSeek's: both are startup teams that began in 2023, both maintain extremely small teams with high talent concentration, and both are firm believers in Scaling Law.
In July 2025, Moonlight released the world's first trillion-parameter open-source model, Kimi K2, openly stating in its technical report that it adopted the MLA architecture open-sourced by DeepSeek. For large models, the biggest nightmare of processing ultra-long text is the memory wall. The disruptive nature of the MLA architecture lies in its clever achievement of a staggering over 93% compression rate for KV Cache.
With the "industry standard" contributed by DeepSeek, large model teams like Moonlight no longer needed to reinvent the wheel, quickly reducing inference costs.
The story didn't stop there.
Looking through the DeepSeek V4 technical documentation, it details the model's architecture. One important upgrade was switching the optimizer for most modules from AdamW to Muon, achieving faster convergence speed and better training stability.
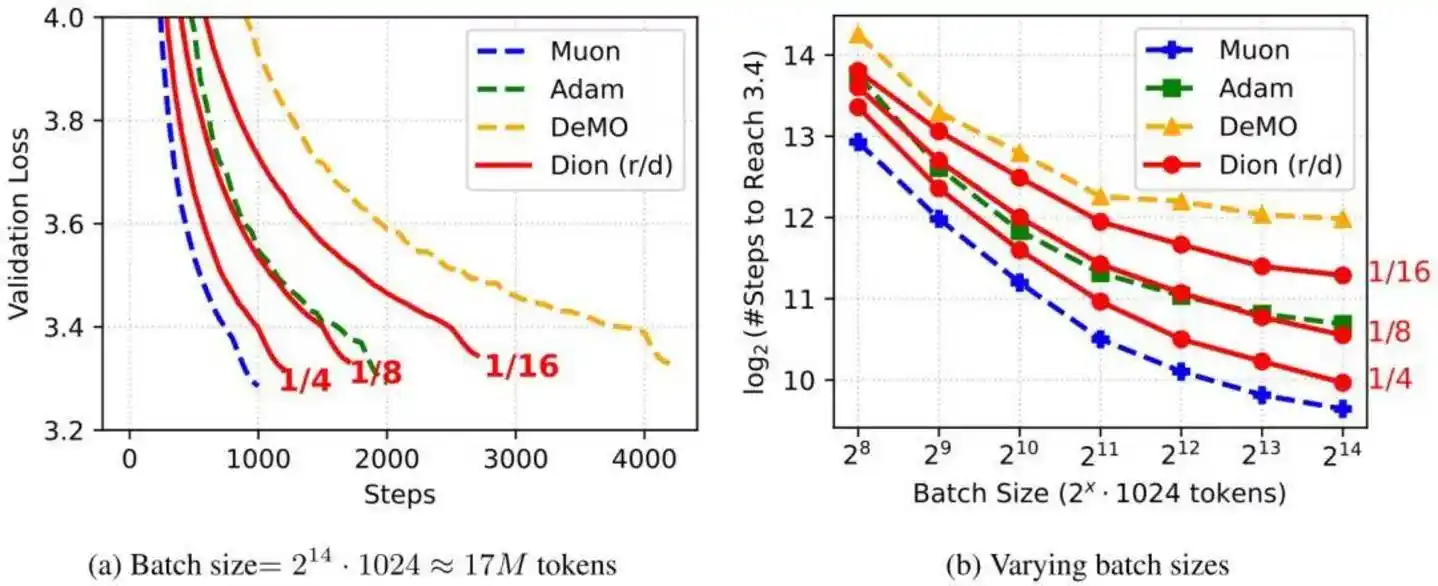
In the Kimi K2.6 technical documentation, the Muon optimizer is also mentioned, achieving a 2x efficiency improvement under the same training volume.
The Muon optimizer, mentioned by both models, was first proposed by independent researcher Keller Jordan in a blog post in late 2024. The Moonlight team, also troubled by AdamW, made key engineering improvements to Muon in early 2025, adding capabilities like Weight Decay and RMS control, and named it MuonClip.
Moonlight率先 validated the stability of the Muon optimizer on Kimi K2, achieving "zero Loss Spike" throughout pre-training. DeepSeek also adopted the validated Muon optimizer when training the V4 large model.
It's important to note that the "collaborative evolution" of open-source large models has not fallen into homogeneity but is moving towards a path of "harmony in diversity."
For example, DeepSeek-V4 focuses on core capabilities攻坚 of the base model, further solidifying the global open-source large model performance ceiling and providing the entire industry with a base foundation rivaling closed-source flagships; Kimi K2.6深耕 Agent engineering and落地, solving the pain points of long-range autonomous execution for large models, and打通关键路径 for large models to enter real production scenarios.
Throughout this process, there were no protracted商业谈判, no tense patent battles. In the open-source camp, technological innovation flows freely like water; whoever does it well, everyone uses it.
Absorbing nutrients from the open-source ecosystem, complementing each other in technical routes. China's large model vendors are demonstrating to the world another possibility beyond Silicon Valley through action.
03 The U.S. Is "Building Walls," China Is "Paving Roads"
While marveling at the collaborative evolution of open source, one must face a商业现实 squarely.
Currently, OpenAI and Anthropic's annualized revenues have both reached the tens of billions of USD, while the revenue of domestic leading large model vendors has just crossed the threshold of annualized $100 million.
OpenAI's valuation in the secondary market is about $880 billion, Anthropic's valuation has soared to around $1 trillion, while the valuations for Kimi and DeepSeek's latest funding rounds are $18 billion and $20 billion respectively.
Some exclaim that Chinese large model vendors are undervalued, while others believe: "The ability to translate technical reputation into real money is a life-and-death test facing Chinese companies." For a time, discussions about the "cost-effectiveness" of open source are rampant.
To see the endgame, one might start from the competition stages of large models:

The first stage was "competing on parameters, competing on Benchmark." By the end of April 2026, this stage is basically over, as scores on leaderboards can no longer create substantial gaps.
The second stage is "competing on training efficiency, competing on inference cost, competing on architectural innovation." This is the current segment, also an inevitable result forced by computing cost pressures.
The third stage will be "competing on Agent systems, competing on ecosystem, competing on developers." When Tokens change from free traffic to "fuel" for executing tasks, the prosperity of the ecosystem will determine survival.
What is the ecological niche of domestic open-source large models? We found two sets of直观的对比数据 (intuitive comparative data).
One is training cost.
GPT-5, released in August 2025, had a training cost exceeding $500 million; Kimi K2 Thinking around the same time cost about $4.6 million to train; DeepSeek did not公布 the training cost of the V4 series models, but the V3 model cost only $5.576 million... Domestic large model vendors used resources amounting to less than pocket change for OpenAI to train models of comparable level.
The other is call volume.
After entering 2026, data from the multi-model aggregation platform OpenRouter shows: driven by Agent products represented by OpenClaw, global Token consumption has shown exponential growth. China's "Open-Source Dream Team,"凭借 "好用又便宜"的口碑 (relying on a reputation for being "user-friendly and cheap"), has seen its volume连续多周超越美国 (surpass that of the U.S. for multiple consecutive weeks).
The reason isn't hard to explain.
China's open-source camp has already successfully run a "positive feedback flywheel": Company A open-sources underlying technology, Company B adopts and performs engineering optimizations, then feeds the optimization results and experiences back to the entire ecosystem. If the evolution of closed-source models is linear growth built on massive computing power stacking, what awaits the open-source route is the exponential diffusion brought by the collision of technological innovations.
According to J.P. Morgan's research report, China's AI inference token consumption will achieve a compound annual growth rate (CAGR) of about 330% between 2025 and 2030,激增 (soaring) from 10 trillion tokens in 2025 to 3900 trillion tokens in 2030, a growth scale of 370 times.
This means that 2026 is still in the early stages of the AI explosion, with hundreds of times more growth opportunities in the next 5 years—far from the time for a final verdict.
Precisely because of confidence in long-term opportunities, while Silicon Valley giants are desperately building walls, Chinese large model vendors are choosing to use collaborative positioning to continuously solidify the road to AGI.
04 In Conclusion
In this轰轰烈烈的AI浪潮 (grand AI wave), who will have the last laugh? The answer concerns not only the models but also the autonomous controllability of computing power. If models are compared to "atomic bombs," then domestic computing power, free from external technological blockades, is the "rocket" that sends the atomic bomb into the sky.
It is gratifying that the integration of domestic models and domestic computing power is becoming increasingly close: in the DeepSeek V4 technical documentation, Ascend NPU is listed alongside NVIDIA GPU in the hardware verification list; Moonlight's latest论文 (paper) runs large model inference's prefill and decoding on different chips, opening the door for domestic chips to participate in model inference on a large scale.
In early 2025, DeepSeek R1 secured a seat at the table for domestic large models; by 2026, China's open-source large model camp is continuously creating more定义牌桌规则的硬资本 (hard capital that defines the rules of the table) through collaboration.








