Do androids dream of electric sheep? If they do dream, will they dream of electric sheep?

Screenshot from the movie "Blade Runner"
In 1968, when Philip K. Dick, the author of the novel that inspired the sci-fi film "Blade Runner," typed out this abstract and ahead-of-its-time question at his typewriter, he probably never imagined that more than half a century later, Silicon Valley tech giants would give a serious answer.
Yes, they can not only dream of electric sheep, but they can also visualize their dreams.
Yesterday, at its developer conference in San Francisco, Anthropic announced a series of new features for its Managed Agents platform for building agents, including memory expansion, output control, multi-agent collaboration, and "Dreaming."
According to Anthropic, "memory and dreaming together form a robust, self-improving memory system for agents."

Dreaming, memory... friends less familiar with the AI field might be full of question marks. When did these human terms start to be so seamlessly applied to AI?
As early as 2024, when OpenAI launched the o1 series, describing it as "a series of AI models designed to spend more time thinking before responding," the word "thinking" was used so naturally that no one stopped to ask: a program that statistically predicts the next token—how can that be called thinking?
This was followed by reasoning, memory, reflection, imagining—one by one, activities unique to humans were brought onto the product stage.

Screenshot from the film "Paprika" which explores dreams
"Thinking" can still be explained as a metaphor, "memory" is barely an extension of technical jargon, but "dreaming" is really pushing it. Humanities haven't figured it out after millennia, but AI companies can directly say: We've not only created thinking machines, but we've also created dreaming machines.
What is dreaming? Besides dreaming, couldn't they find a single precise engineering term to describe this?
AI Dreaming Also Costs Money
As early as the Claude Code code leak incident, netizens discovered that Anthropic was preparing a feature called Auto Dreaming. At the time, everyone wondered, does AI also need sleep, like us humans, requiring sufficient rest to become more focused and smarter?
But once you understand how current AI Agents work, you'll find that so-called "dreaming" is essentially just an automated batch processing of offline logs.
AI Agents are now good at completing long, complex tasks. For example, "Help me research the latest financial reports of these five competitors and organize them into a table." In this process, the Agent needs to jump between different web pages, read multiple documents, call different tools, and may even hit walls and retry due to encountering anti-crawling mechanisms.
After this long series of complex online tasks, the Agent's backend leaves behind massive amounts of operational logs.
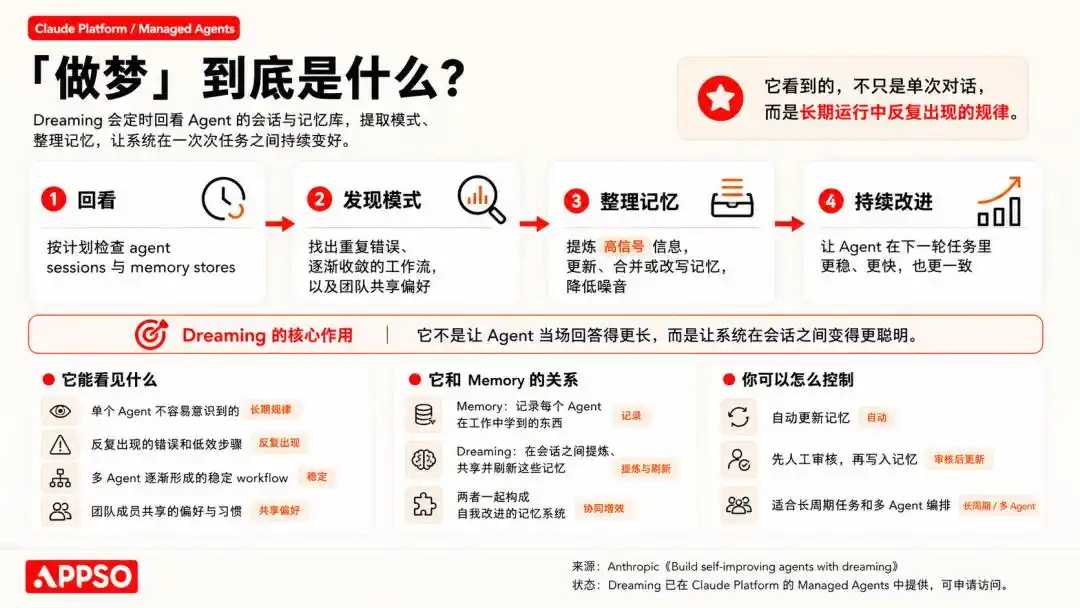
Image generated by AI
Anthropic's "dreaming" function allows the Agent to re-examine these historical records during idle time. It looks for patterns, such as discovering that "whenever I encounter this kind of pop-up, clicking the top right corner closes it," thereby optimizing the next operational path.
"Memory" is responsible for capturing learned things during work, while "dreaming" refines these memories between sessions and shares them across different Agents.
In short, this is a reinforcement learning and self-correction mechanism based on historical data.

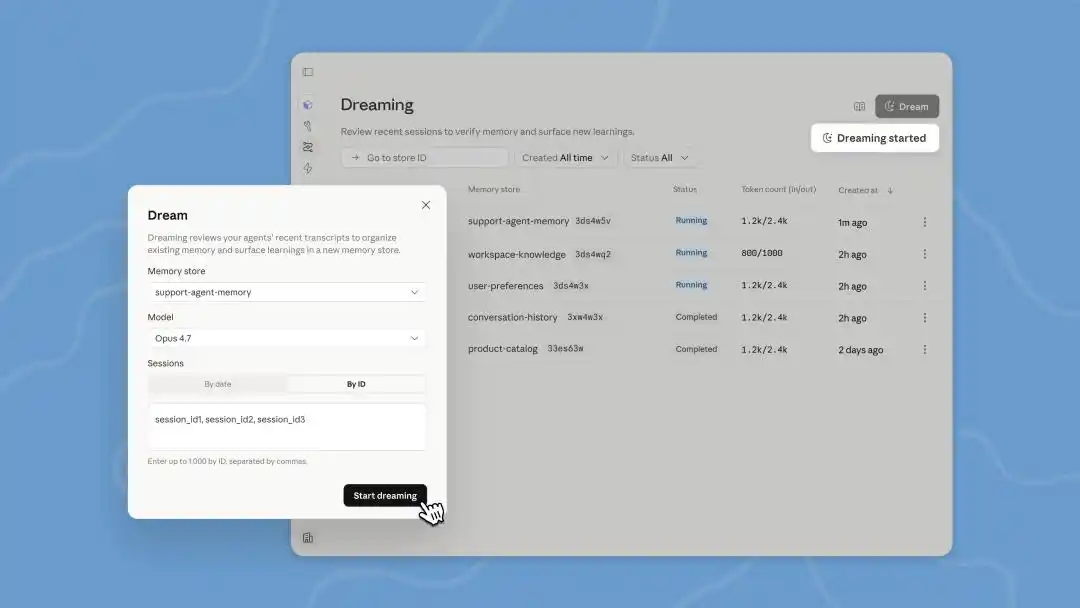
Dream Introduction: https://platform.claude.com/docs/en/managed-agents/dreams
The Dreams feature updated in Managed Agents at this developer conference is a backend processing task that we need to trigger manually. Claude can read the conversation history of up to 100 sessions at once and produce a brand new memory for us to review before deciding whether to use it.
Meanwhile, AutoDream, which has already been quietly rolled out in Claude Code, runs in the background after each conversation round with the Agent to check "whether it should dream," with a default of running once every 24 hours.
Similar dreaming functions also exist in Hermes Agent. Hermes Agent focuses on self-learning and evolution. It not only supports automatically summarizing experiences from past tasks and placing them in memory files.

One feature called Curator can also automatically organize these refined operation guides into Skills.
These Skills are scored, duplicates are merged, unused ones are automatically archived, and they even have a lifecycle with states like active, stale, and archived. We can also pin important Skills to prevent the system from automatically clearing them.
OpenClaw has also added related mechanisms in recent updates, such as cross-conversation persistent memory, scheduled task processing, isolated execution of sub-agents, and a direct Dreaming function.
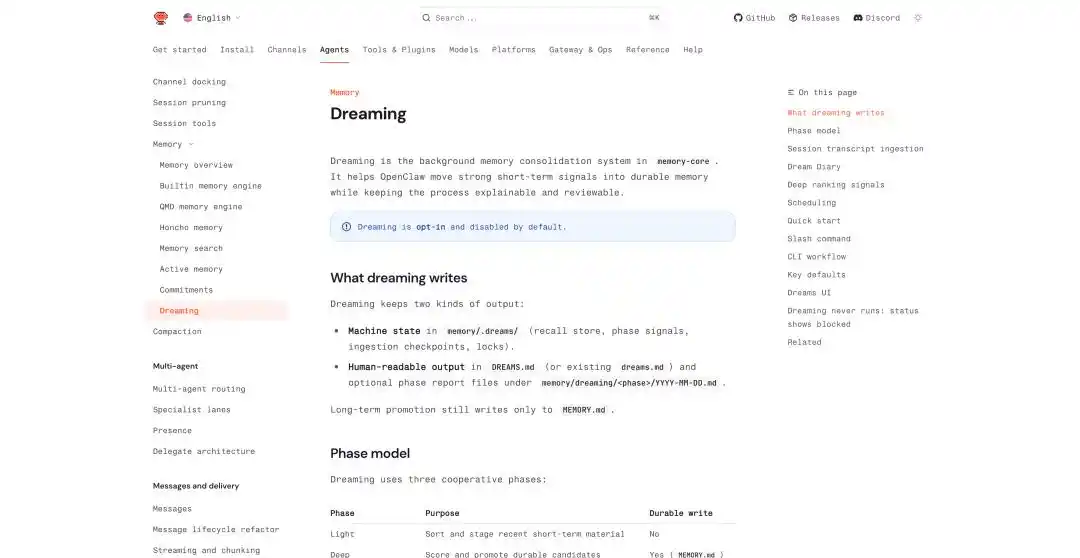
OpenClaw Dreaming: https://docs.openclaw.ai/concepts/dreaming
In OpenClaw's dreaming mechanism, it summarizes the dreaming process into three stages: light, REM, and deep. The first two are responsible for organization, reflection, and thematic summarization, while deep truly writes content into the long-term memory MEMORY.md.
The consolidation in the deep sleep stage is decided by six weighted signals on whether it needs to be written into long-term memory. These six signals include frequency, relevance, query diversity, timeliness, cross-day repetition, and conceptual richness.

Image generated by AI
Writing to long-term memory generates two files: one machine-oriented state file, placed in memory/.dreams/; the other is a human-readable record, written into DREAMS.md and reports generated by stage.
Additionally, Dreaming can run automatically on a schedule, defaulting to running a complete process (light → REM → deep) every day at 3 AM.
Besides the dreaming output, OpenClaw also maintains a document called Dream Diary. The system automatically generates a "dream diary" that narratively records the memory organization process, emphasizing explainability and reviewability rather than being a black-box writing library.
There is a classic understanding in neuroscience: Information acquired during the day first enters a more temporary storage system; during sleep, the brain replays, consolidates, and cleanses this information, retaining the important and discarding the meaningless.
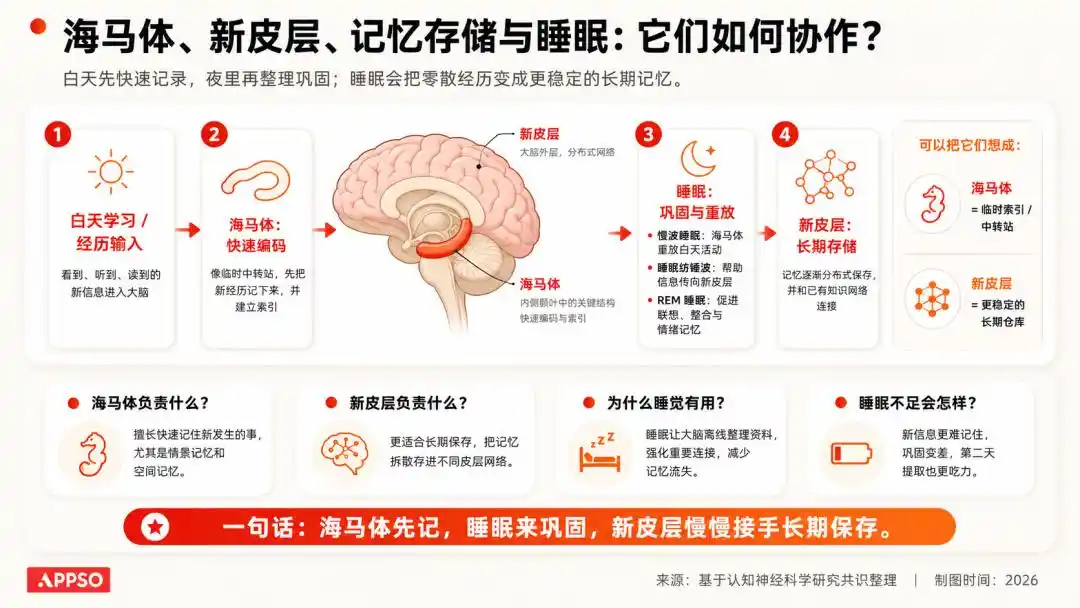
Image generated by AI
We don't remember the color of every car on yesterday's commute, but we remember how to get to the office.
These dreams sound quite similar to human dreams. If we must find differences, it's probably that Claude's dreaming still consumes our Tokens.
But neither Anthropic nor OpenClaw chose to call it "session-based optimization" or "post-task tuning"—names more inclined towards engineering.
After all, when complex names are directly replaced with "dreaming," what we perceive is no longer a software feature, but more like a "digital life with inner activities."
AI Memory is Fragmented Context
Since "dreaming" is mentioned, its prerequisite, Memory, must be discussed.
Over the past period, the hottest terms in the AI circle have shifted from prompt engineering to context engineering, skill engineering, harness engineering. But no matter how it changes, the most valuable currently is still context engineering.
System prompts, user input, short-term conversation, long-term memory, retrieved documents, outputs from tool and skill calls, current user state—these layers stacked together constitute the "context" the agent actually uses.
Enabling Agents to remember more and more useful content has been a long-standing challenge.
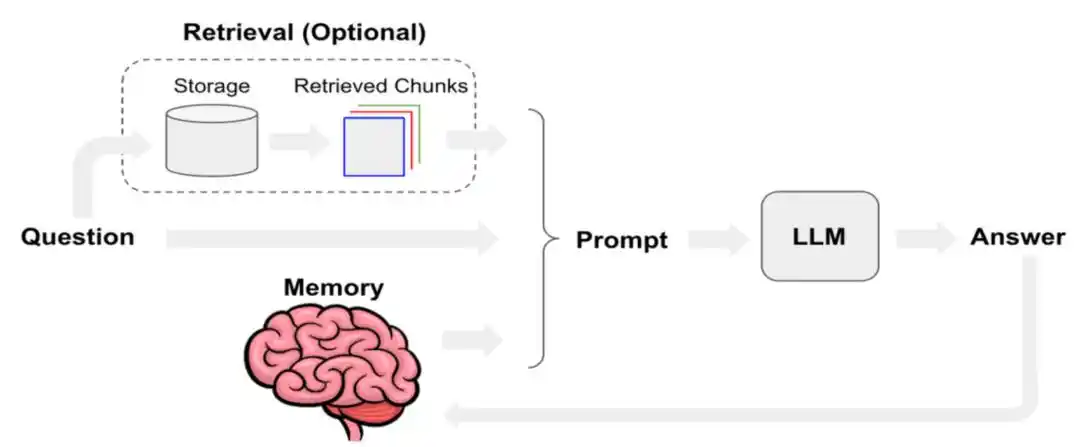
Manus published a technical blog last year specifically discussing how Manus optimizes context engineering. It mentioned defining KV-Cache hit rate as one of the most important single metrics for AI Agents in production environments. At the tool-calling level, it prioritizes "masking" over "removal"; and using the file system as the ultimate context, among other methods.
To understand so-called KV Cache (Key-Value Cache), we can imagine a large language model as an extremely obsessive-compulsive individual that can only read one word at a time.
When processing a sentence, it calculates a Key vector and a Value vector for each generated Token. To avoid recalculating from scratch every time, it stores these (K, V) key-value pairs; this is the KV Cache.
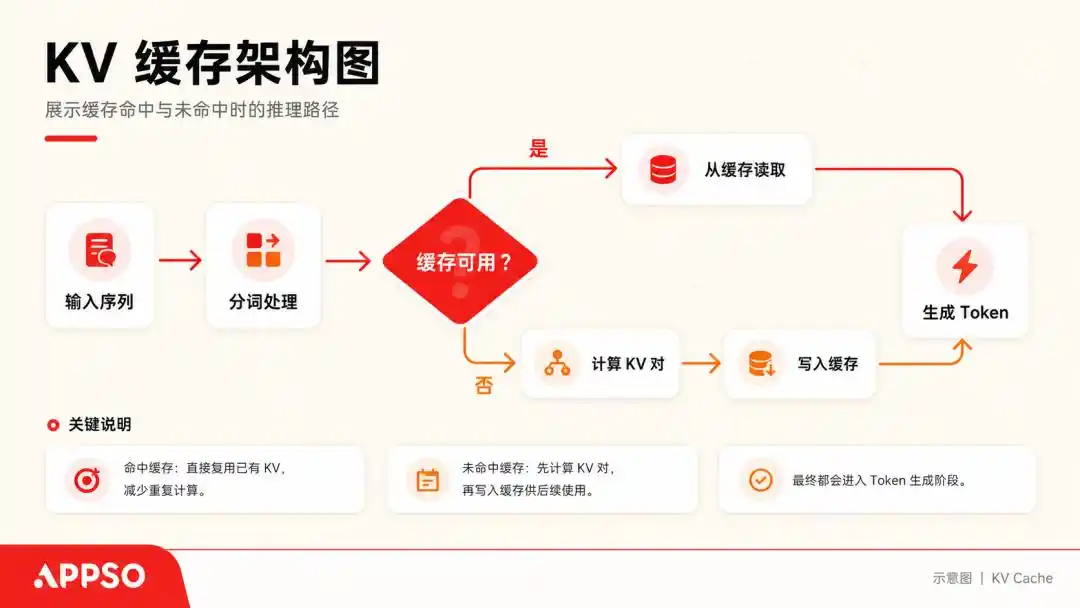
KV Cache (Key-Value Cache) is an underlying acceleration technology used by large models during text generation to "trade space for time." Caching allows the model to predict the next word without recalculating all previous words. Image generated by AI.
As long as the conversation continues, the KV Cache keeps saving. Generally, when facing large models with huge contexts like 128k, a 70B parameter model running a full 128k context can consume up to 64 GB of memory for the KV Cache alone.
This is why most models' context windows currently max out at the million-token level.
Yesterday, a new company Subquadratic, which secured $29 million in seed funding, announced the SubQ new model on X, focusing on longer context.

SubQ claims to support a context window of up to 12 million tokens, which is currently the largest among all large models.
Although there is no technical paper or model documentation yet, the introduction video mentions that SubQ's core technical direction shifts from the traditional Transformer's "dense attention" to a "sub-quadratic / linear scaling" architecture with sparse attention. The new architecture有望能 solve the problem of exploding computational costs with longer contexts.

The test results provided are quite aggressive: at 1 million tokens, speed increases by over 50x, cost reduces by over 50x; at 12 million tokens, computational requirements can be reduced by nearly 1000x compared to cutting-edge models.
On the RULER 128K long-context benchmark, Subquadratic claims SubQ achieved 95% accuracy at an $8 cost, compared to Claude Opus's 94% accuracy at ~$2600 cost, reducing cost by about 300x.
Either expand the context window, or make the model learn to dream and discard some things itself.
This is also why Agent products like Anthropic must now introduce Dreaming. With limited context windows, smarter AI cannot rely solely on stuffing in more content; it needs to be selective.
Acknowledging Machines Are Just Machines is Harder Than Imagined
Understanding the mechanisms of AI dreaming and memory, we might grasp their relationship to human activities.
But putting together all these terms that AI companies have created for machines—OpenAI's thinking, the industry's memory and hallucination, Anthropic's dreaming this time, and the virtue and wisdom in Anthropic's constitution—we can see that AI companies are far from just selling products; they are redistricting the vocabulary ownership within the concept of "human." With each term appropriated, the boundary between machine and human blurs by an inch.

Language shapes expectations, expectations shape tolerance, and tolerance determines how much we are willing to entrust to it. This is a long chain, but the starting point is those harmless words at press conferences.
A more subtle layer of influence is responsibility allocation. When a tool is described as an entity with "thinking," "memory," and "values," and it malfunctions, we naturally treat it as an independent "actor" to hold accountable—this AI needs to be "educated," "debugged," "calibrated."
But what should really be questioned is the company that deployed this program into our workflow and the product team that came up with the word "dreaming." Change the word, and the "defendant" in the dock changes.
And as we watch a machine that can "think," "remember," and now even "dream," we also begin to subconsciously believe there is something inside. Because acknowledging it's just a machine dissipates the feeling of "I'm talking to a thinking being," reverting to a cold, tool-based relationship.

Daydreaming Feature Introduction | Image generated by AI
I can already imagine: Dreaming processes past content. Next, AI companies will launch Daydreaming for rehearsing the future.
The introduction will be: Daydreaming or mind-wandering allows the Agent, in an active state, to use a small portion of idle computing power combined with ongoing projects to perform exploratory generation simultaneously, preparing for possible future tasks.
This article is from the WeChat public account "APPSO", author: APPSO who discovers tomorrow's products





