In recent years, the Mixture of Experts (MoE) model has been widely used in large cloud-based models. However, on the mobile side, Large Language Models (LLMs) are still predominantly based on dense architectures. In the past, mobile devices imposed stricter constraints on memory, computing power, and latency, and there was a lack of systematic research on on-device MoE within the sub-billion active parameter range. Now, with the increase in DRAM capacity of mobile devices, MoE also has the opportunity to be deployed on smartphones.
The MobileMoE proposed by Meta's team achieves efficient MoE inference on commercial smartphones for the first time. The results show that across 14 foundational tests, MobileMoE-S/M, with similar memory usage, achieved comparable or even higher average accuracy using only 1/2 to 1/4 of the inference compute of dense baselines. In real-world tests, MobileMoE-S showed the most significant speedup on the iPhone 16 Pro's GPU/MLX backend, with a maximum speedup of 3.8x during the input phase.

Paper Link: https://arxiv.org/abs/2605.27358
The research team also proposed a set of on-device MoE scaling laws to determine model structures more suitable for mobile deployment. MobileMoE establishes a new Pareto frontier for on-device large language models, achieving better results in the trade-off between accuracy and inference computational overhead.
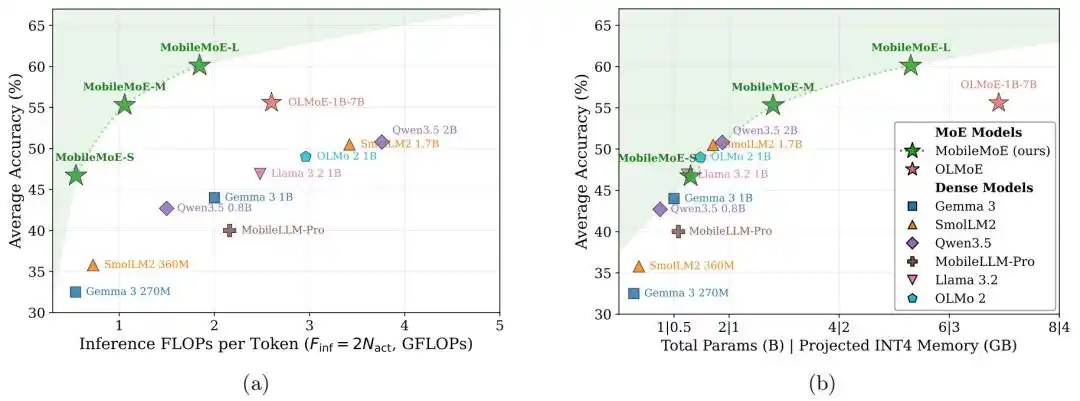
Figure | MobileMoE establishes a new Pareto frontier for on-device large language models.
How is MobileMoE Designed?
MobileMoE can be understood as follows: it is a class of MoE language models designed for on-device deployment. The overall architecture remains a decoder-only Transformer, but the original dense feed-forward layers are replaced with MoE layers. The router selects the top-scoring few experts for each token to participate in computation, while a shared expert always participates. The entire training process is divided into four steps: pretraining, intermediate training, supervised fine-tuning, and quantization-aware training.
Pretraining: The research team pretrained the model using approximately 6T tokens of open-licensed data with a context length of 2048. The data primarily consisted of web content, while also covering domains such as mathematics, code, knowledge, and science.
Intermediate Training: The research team extended the context length to 8192 and further increased the proportion of high-quality data in areas like knowledge, code, mathematics, and science, with a total scale of about 500B tokens.
Supervised Fine-Tuning (SFT): The research team fine-tuned MobileMoE-Base on open-licensed instruction-tuning data comprising over 80 million samples.
Quantization-Aware Training: The research team quantized linear layers and embeddings to INT4, activations to INT8 with dynamic quantization, while the router retained FP32 precision.

Figure | The four-stage training of MobileMoE.
Experimental Results
Ablation Study Results
The research team first compared three architectural variables: the number of experts E, expert granularity g, and the inclusion of a shared expert.

Figure | Scaling the number of experts E.
Under a fixed memory budget, when memory is above approximately 0.25GB, the loss of MoE begins to be lower than that of the corresponding dense model. Continuing to increase the number of experts E further reduces the loss, but the marginal gain significantly diminishes after E increases to 8. Experiments on expert granularity g indicate that finer-grained expert configurations are generally better, with g=8 achieving a good balance between effectiveness and training cost; when g increases from 8 to 16, the loss improvement is less than 0.01, but training time increases by about 50%. Under the same computational budget, the model loss further decreases after adding a shared expert.
Based on the ablation study results, the research team ultimately adopted the configuration with E=8, g=8, and a shared expert, i.e., 60 fine-grained routing experts, Top-4 routing, and 1 shared expert, and used this architecture for the three versions: MobileMoE-S, M, and L.
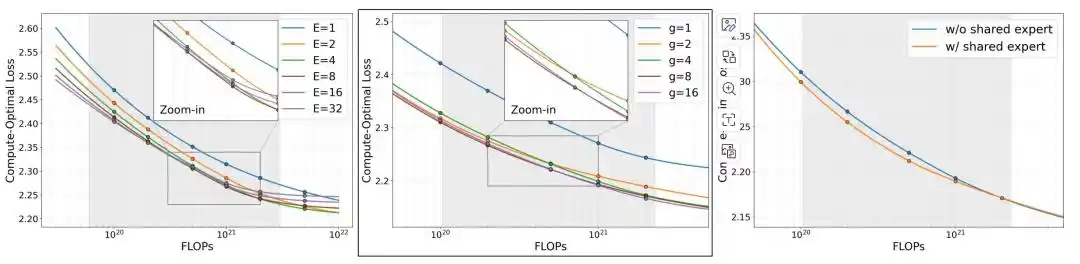
Figure | Scaling MoE models under compute-optimal conditions.
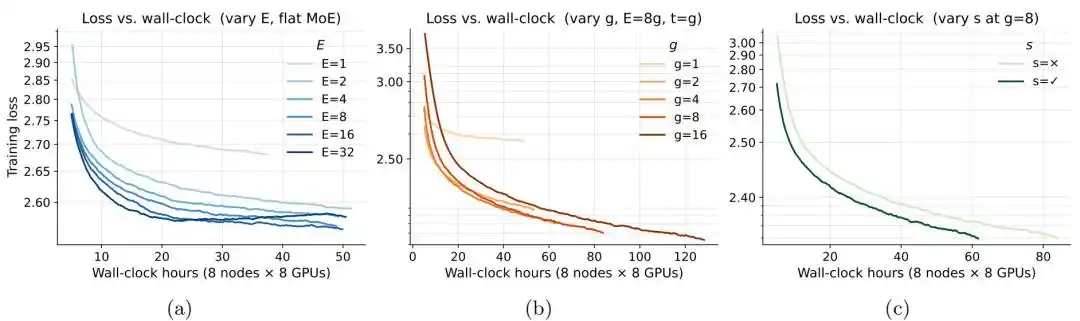
Figure | Training efficiency of the MoE architecture.
14 Foundational Evaluations: Establishing a New On-Device Pareto Frontier
The research team compared MobileMoE with models such as Gemma 3, SmolLM2, Qwen3.5, OLMo 2, and OLMoE-1B-7B under a unified setup across 14 foundational evaluations in five categories: commonsense reasoning, knowledge, science, reading, and reasoning.
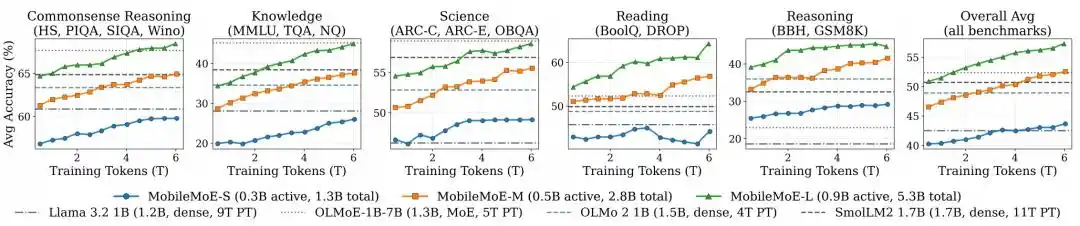
Figure | Pretraining trajectory of MobileMoE.
Comparison results for Base models show that the average score of MobileMoE-M is higher than that of Qwen3.5 2B, and the average score of MobileMoE-L is higher than that of OLMoE-1B-7B, while also requiring a smaller model size. The team also noted that the average score of the Base version of MobileMoE-L is already higher than that of the Instruct version of OLMoE-1B-7B. In terms of training scale, MobileMoE uses about 6T pretraining tokens, which is less than Llama 3.2 1B's 9T and SmolLM2 1.7B's 11T. In the overall comparison of instruction-tuned models, the average accuracy of MobileMoE-M is already close to that of OLMoE-1B-7B, but with both active and total parameters reduced by about 60%.

Figure | Comparison of MobileMoE-Base models.
Advanced Evaluations: More Prominent Advantages in Code and Math Tasks
In advanced evaluations after instruction tuning, MobileMoE performs more prominently on code and math tasks. Taking MobileMoE-L as an example, its average scores in both code and math categories are higher than those of Qwen3.5 2B and OLMoE-1B-7B. However, the research team also notes that in terms of instruction-following and knowledge reasoning capabilities, Qwen3.5 2B remains stronger.
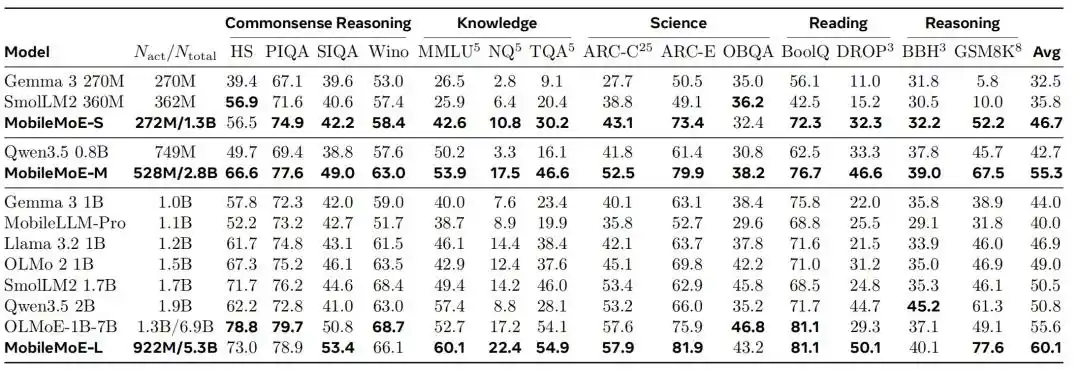
Figure | Comparison of Instruct models on advanced benchmarks.
Quantization and On-Device Deployment: Remains Competitive After INT4, Significant Speedup on Mobile
After quantization, the overall average scores of MobileMoE-S/M/L decreased compared to their respective BF16 versions, but the drops were roughly within 2 to 3 points. Even so, the performance of the INT4 version of MobileMoE-L remained higher than the BF16 version of OLMoE-1B-7B Instruct.
The research team also deployed MobileMoE on Samsung Galaxy S25 and iPhone 16 Pro for testing. The results show that under comparable INT4 weight memory conditions, MobileMoE-S, compared to MobileLLM-Pro, achieved speedups of 1.8-3.8x during the input phase and speedups of 2.2-3.4x during token-by-token generation.
In terms of memory usage, under conditions of Samsung Galaxy S25, 8K context length, and real prompts, the peak RSS of MobileMoE-S was 1.49GB, lower than MobileLLM-Pro's 1.91GB.

Figure | On-device runtime latency.
Limitations and Future Directions
Currently, in terms of higher-order instruction following, knowledge, and reasoning capabilities, the instruction-tuned MobileMoE still lags behind Qwen3.5 2B. The research team believes this gap may be related to more comprehensive post-training. In the future, to narrow this gap, training-side efforts should focus on strengthening distillation, inference-oriented post-training, and multimodal extension.
Furthermore, the research team points out that the memory footprint of MoE on mobile phones varies with input content. Compared to templated inputs, real inputs typically lead to higher memory usage. Testing solely based on templated inputs might underestimate the actual memory pressure in real deployment scenarios. In the future, to more accurately evaluate the real memory performance of on-device MoE, more real-world measurement data is needed.
At the same time, the research team has already completed systematic real-device testing on CPU and GPU backends, but the NPU path remains to be explored. Additionally, the runtime memory footprint of MoE is relatively sensitive to input content. In the future, dynamic routing, expert pruning, mixed-precision quantization, and mobile NPU deployment are all directions for further improving on-device efficiency.
For more technical details, please refer to the original paper.
This article is from the WeChat public account "Academic Headlines" (ID: SciTouTiao), Author: Xia Qiansi