Author: Luo Yihang

In January 2009, an anonymous individual invented something called a "token." You invest computing power, obtain tokens, and these tokens circulate, are priced, and traded within a consensus network. The entire crypto economy was born from this. Over a decade later, people are still debating whether this token has any value.
In March 2025, a man in a leather jacket redefined another thing called a "token." You invest computing power, produce tokens, and these tokens are instantly consumed in an AI inference (inference & reasoning) process: thinking, reasoning, writing code, making decisions. The entire AI economy is accelerating because of this. No one debates whether this token has value because you just used millions of them this morning.
Two types of tokens, the same name, the same underlying structure: computing power goes in, something valuable comes out.

In March 2026, I sat in the NVIDIA GTC venue and listened to Jensen Huang deliver a keynote speech with almost no product promotion. Yes, he unveiled Vera Rubin, a product combining CPU and GPU. But this time, he didn't talk about chip specifications or manufacturing processes; he talked about a complete economics of token production, pricing, and consumption:
Which model corresponds to which token speed; which token speed corresponds to which price range; which price range requires what level of hardware to support.
He even prepared data center computing power allocation plans for the CEOs and decision-makers holding the corporate checkbooks in the audience: 25% for the free tier, 25% for mid-tier, 25% for high-end, 25% for the high-premium tier.
Yes, this time he wasn't specifically selling a particular GPU group, like he did with Blackwell two years ago. But this time, he was selling something bigger. After two hours, I felt the sentence he most wanted to say was: Welcome to consume tokens, and only Nvidia's factory could produce.
At that moment, I realized that this man was doing something structurally identical to what that anonymous person did 17 years ago when he mined the first token.
The Same Conversion Rules
The anonymous individual using the pseudonym "Satoshi Nakamoto" wrote a nine-page white paper in 2008, designing a set of rules: invest computing power, complete a mathematical proof (Proof of Work), and receive a crypto token as a reward.
The brilliance of this rule lies in the fact that it doesn't require anyone to trust anyone else—as long as you accept these rules, you automatically become a participant in this economy. The rule is correct; after all, it brought so many deceitful people together.
And Jensen Huang, on the stage at GTC 2026, did something structurally identical.
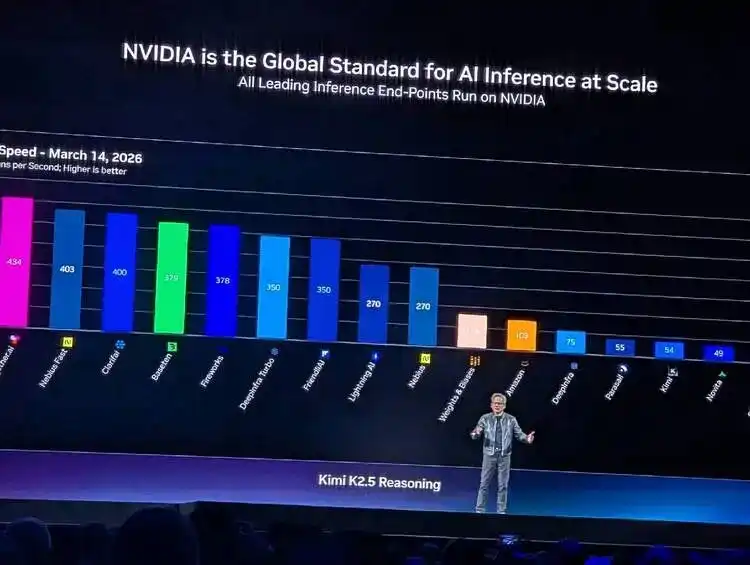
He showed a chart illustrating the relationship and tension between inference efficiency and token consumption: the Y-axis is throughput (tokens produced per megawatt of power), the X-axis is interactivity (token speed perceived per user). Then, he labeled five pricing tiers below the X-axis: Free uses Qwen 3, $0/million tokens; Medium uses Kimi K2.5, $3/million tokens; High uses GPT MoE, $6/million tokens; Premium uses GPT MoE 400K context, $45/million tokens; and Ultra, $150/million tokens.
This chart could almost serve as the cover of Jensen Huang's "token economics" white paper.
Satoshi defined "what constitutes valuable computation"—completing an SHA-256 hash collision was valuable. Jensen Huang defined "what constitutes valuable inference"—producing tokens for a specific scenario at a specific speed under given power constraints is valuable.
Neither Satoshi Nakamoto nor Jensen Huang directly produced tokens; they both defined the rules for token production and the pricing mechanism.
A sentence Huang said on stage could almost be written directly into the abstract of a token economics white paper—
Tokens are the new commodity, and like all commodities, once it reaches an inflection, once it becomes mature, it will segment into different parts.
Token is the new commodity. Commodities naturally stratify once they mature. He wasn't describing the status quo; he was predicting a market structure and then precisely laying out his hardware product line across every layer of this structure.
The production processes of the two types of tokens even have a semantic symmetry: mining is called mining, inference is called inference.
The essence of both mining and inference is turning electricity into money. Miners spend electricity costs to mine crypto tokens and then sell them. Inference models and AI Agents spend electricity costs to generate AI tokens and then sell them to developers priced per million. The middle steps are different, but the two ends are the same: on the left is the electricity meter, on the right is revenue.
Two Ways to Write Scarcity
The most important design decision Satoshi Nakamoto made was not Proof of Work, but the 21 million Bitcoin supply cap. He used code to create artificial scarcity—no matter how many mining rigs flood in, the total number of Bitcoins will never exceed 21 million. This scarcity is the value anchor of the entire crypto economy.
And Jensen Huang created natural scarcity using physical laws. He said:
"You still have to build a gigawatt data center. You still have to build a gigawatt factory, and that one gigawatt factory for 15 years amortized... is about $40 billion even when you put nothing on it. It's $40 billion. You better make for darn sure you put the best computer system on that thing so that you can have the best token cost."
A 1GW data center will never become 2GW. This isn't a code limitation; it's a law of physics.
Land, electricity, cooling—each has a physical limit. How many tokens this factory you built for $40 billion can produce over its 15-year lifecycle depends entirely on what computing architecture you put inside it.

Satoshi's scarcity can be forked. If you don't like the 21 million cap, fork a new chain, change it to 200 million, call it Ether or whatever, and issue a white paper. And people did just that, with great relish.
But the scarcity Huang creates cannot be forked. After all, you can't fork the second law of thermodynamics, you can't fork a city's power grid capacity, you can't fork the physical area of a piece of land.
But whether it's Satoshi Nakamoto or Jensen Huang, the scarcity they created led to the same result: a hardware arms race.
The history of mining is: CPU→GPU→FPGA→ASIC. Each generation of specialized hardware rendered the previous generation obsolete. And the history of AI training and inference is replaying: Hopper→Blackwell→Vera Rubin→Groq LPU. Start with general-purpose hardware, settle with specialized hardware. The Groq LPU showcased by Huang at this year's GTC, the deterministic dataflow processor released after acquiring Groq. Static compilation, compiler scheduling, no dynamic scheduling, 500MB on-chip SRAM—its architectural philosophy is the ASIC of the inference field. Do one thing, but do it to the extreme.
Interestingly, GPUs played a key role in both waves.
Around 2013, miners found that GPUs were more suitable for mining crypto tokens than CPUs, and NVIDIA graphics cards were sold out. 10 years later, researchers found that GPUs are the best tool for training and inferring AI models, and NVIDIA data center cards were sold out again. GPU, as a processor category, has successively served two generations of token economies.
The difference is, the first time NVIDIA benefited passively, and that was it. The second time, as the main battlefield of AI computing consumption shifted from pre-training to inference, NVIDIA quickly seized the opportunity to actively design the entire game, becoming the writer of the AI rules of the game.
The World's Most Profitable Shovel Seller
In the gold rush, the most profitable weren't the gold miners, but the shovel seller Levi Strauss. In the mining boom, the most profitable weren't the miners, but the mining machine seller Bitmain and Jihan Wu. In the AI pre-training and inference wave, the most profitable aren't the foundation models and Agents, but the GPU seller NVIDIA.
But honestly, the roles of Bitmain and NVIDIA in their respective industries are no longer comparable.
Bitmain only sold mining machines; NVIDIA was even a supplier to Bitmain. You bought a mining machine, what coin to mine, which mining pool to join, at what price to sell, all had nothing to do with Bitmain. It was a pure hardware supplier, earning one-time equipment profits.
NVIDIA is different. He doesn't just sell hardware; now, especially since the explosion of inference-side AI in 2025, he deeply defines what should be mined with this GPU, how to price tokens, who to sell tokens to, how data center computing power should be allocated... All of this is in Huang's presentation PPT: he divides the market into five tiers, each tier corresponding to which model, context length, interaction speed, and price... NVIDIA has standardized and formatted the future market driven by AI inference.
Around 2018, global computing power was concentrated in a few large mining pools—F2Pool, Antpool, BTC.com—they competed for computing power share, but the source of mining machines was highly concentrated in Bitmain.
Just like NVIDIA today, 60% of revenue comes from competing "hyperscalers" like AWS, Azure, GCP, Oracle, CoreWeave, while 40% comes from dispersed AI Natives, sovereign AI projects, and enterprise customers. Large "mining pools" contribute the main revenue, small "miners" provide resilience and diversification.
The structure of the two ecosystems is exactly the same. But Bitmain later encountered competitors—MicroBT, Innosilicon, Canaan—all eating into its share. Mining machines are relatively simple ASIC designs, so followers had a chance. But shaking NVIDIA seems increasingly difficult: 20 years of CUDA ecosystem, hundreds of millions of GPU install base, six generations of NVLink interconnect technology, the decoupled inference architecture after the Groq integration—NVIDIA's technical complexity and ecosystem barriers have rendered most competitive tools ineffective.
This might last for 20 years.
The Fundamental Fork of Two Tokens
What makes cryptocurrency and AI training/inference tokens fundamentally different is the motivation and psychology of their users.
The demand side for Crypto tokens is speculation. No one "needs" Bitcoin to get work done. All white papers claiming blockchain tokens can solve your problems were written by scammers. You hold crypto because you believe someone will buy it from you at a higher price in the future. Bitcoin's value comes from a self-fulfilling prophecy: if enough people believe it has value, it has value. This is the faith economy.
The demand side for AI tokens is productivity. Nestlé needs tokens to make supply chain decisions—its supply chain data refresh rate went from every 15 minutes to every 3 minutes, costs reduced by 83%; this value can be directly mapped to the P&L. 100% of NVIDIA engineers already need tokens to write code instead of hand-coding; research teams need tokens for scientific research. You don't need to believe tokens have value; you just need to use them, and the value proves itself in use.
This is the most essential difference between the two tokens. Crypto tokens are produced to be held and traded—their value lies in not being used. AI tokens are produced to be consumed immediately—their value lies in the moment they are used.
One is digital gold, more valuable the more you hoard it; the other is digital electricity, produced to be burned.
This difference determines that: the AI token economy will not become as bubble-prone as the crypto token economy. Bitcoin rises and falls sharply because the price of a speculative item is driven by sentiment. But the price of [AI] tokens is driven by usage volume and production cost. As long as AI remains useful—as long as people are still using Claude Code to write code, using ChatGPT to write reports, using Agents to run business processes—the demand for tokens won't collapse. It doesn't rely on faith; it relies on being indispensable.
In 2008, the Bitcoin white paper needed to repeatedly argue why a decentralized electronic cash system was valuable. 17 years later, people are still arguing.
In 2026, token economics did not引发 any debate; it didn't even need论证 and became consensus. When Huang stood on the GTC stage and said "tokens are the new commodity," no one questioned it. Because everyone sitting in the audience had used Claude Code or ChatGPT to consume millions of tokens this morning. They didn't need to be convinced that tokens have value—their credit card bills had already proven it.
In this sense, Huang really is a副本 of Satoshi Nakamoto, the副本 that stayed behind to monopolize mining machine production, defined the usage scenarios and norms for tokens, and holds an annual show at the San Jose SAP Center telling people how powerful the next generation of "mining machines" supporting AI training and inference will be.
Satoshi Nakamoto had a charm of cautious desire; he designed the rules, handed them over to the code, and then disappeared. This is cypherpunk romance. And Huang is more of a businessman than any scientist; he designed the rules, maintains them personally, constantly adds bricks and tiles, and solidifies his moat.
The token you used to see because you believed, now you can see without believing. It is the next one after Watt, Ampere, Bit.





