Author | ZeR0 JunDa, Zhidongxi
Editor | Moying
LAS VEGAS, January 5, 2026 (Zhidongxi) — Just now, NVIDIA founder and CEO Jensen Huang delivered his first keynote of 2026 at CES 2026. As usual wearing a leather jacket, Huang announced 8 major releases within 1.5 hours, providing an in-depth introduction to the entire new generation platform, from chips and racks to network design.
In the fields of accelerated computing and AI infrastructure, NVIDIA released the NVIDIA Vera Rubin POD AI supercomputer, NVIDIA Spectrum-X co-packaged optics for Ethernet, NVIDIA Inference Context Memory Storage Platform, and the NVIDIA DGX SuperPOD based on DGX Vera Rubin NVL72.

The NVIDIA Vera Rubin POD utilizes six major NVIDIA self-developed chips, covering CPU, GPU, Scale-up, Scale-out, storage, and processing capabilities. All parts are co-designed to meet the demands of advanced models and reduce computing costs.
Among them, the Vera CPU adopts a custom Olympus core architecture. The Rubin GPU introduces a Transformer engine, achieving up to 50 PFLOPS of NBFP4 inference performance. NVLink bandwidth per GPU is as fast as 3.6 TB/s. It supports third-generation Universal Confidential Computing (the first rack-level TEE), achieving a complete trusted execution environment across CPU and GPU domains.

These chips have already taped out. NVIDIA has validated the entire NVIDIA Vera Rubin NVL72 system, and partners have begun running their internally integrated AI models and algorithms. The entire ecosystem is preparing for the deployment of Vera Rubin.
Among other releases, the NVIDIA Spectrum-X co-packaged optics for Ethernet significantly optimize power efficiency and application uptime. The NVIDIA Inference Context Memory Storage Platform redefines the storage stack to reduce redundant computation and improve inference efficiency. The NVIDIA DGX SuperPOD based on DGX Vera Rubin NVL72 reduces the token cost of large MoE models to 1/10th.

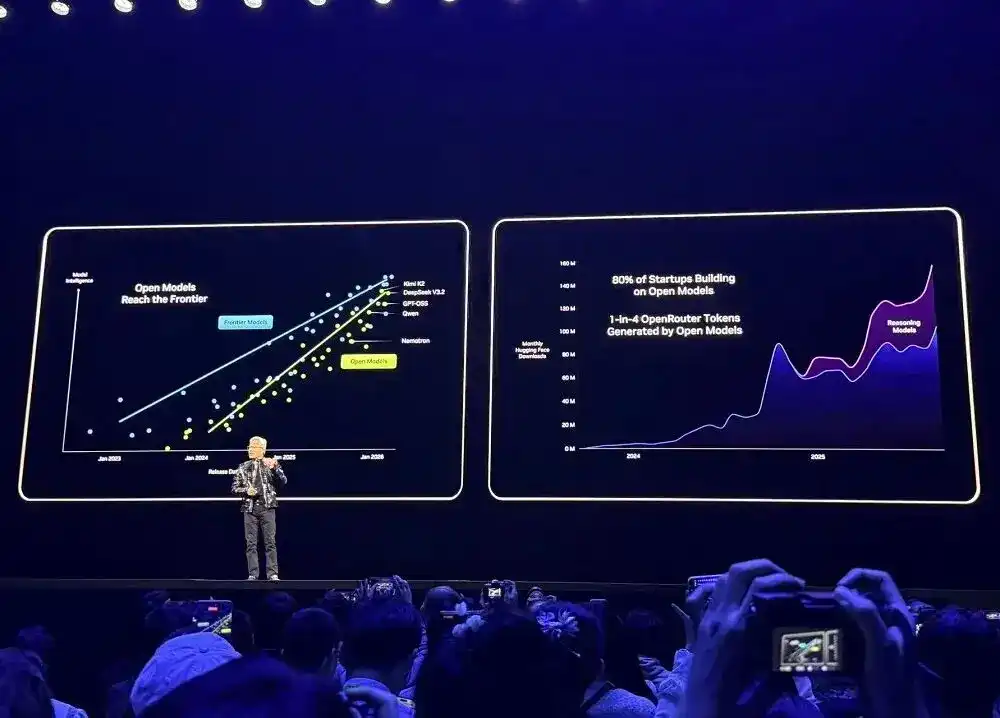
Regarding open models, NVIDIA announced an expansion of its open-source model family bucket, releasing new models, datasets, and libraries. This includes new additions to the NVIDIA Nemotron open-source model series: an Agentic RAG model, security models, and voice models. It also released new open models for all types of robots. However, Jensen Huang did not provide detailed introductions during the speech.
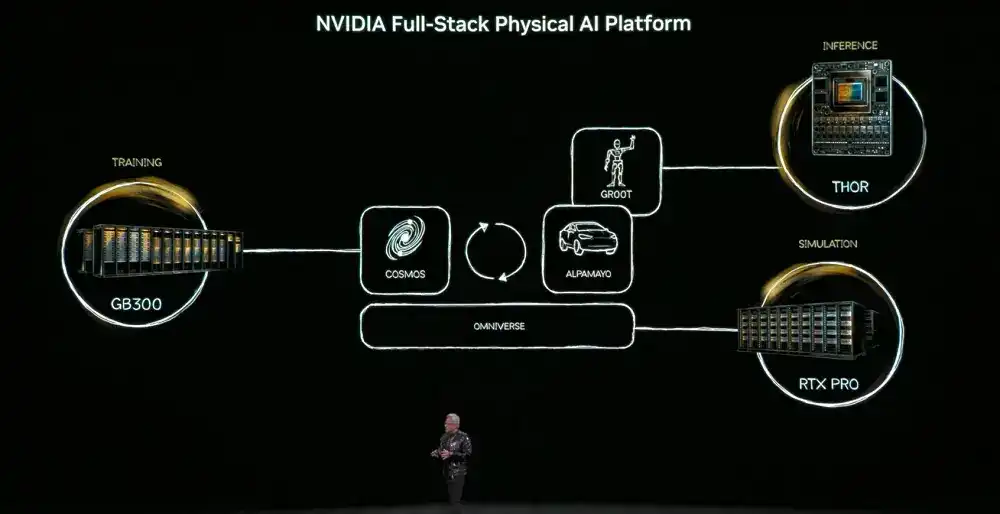
In terms of Physical AI: The ChatGPT moment for Physical AI has arrived. NVIDIA's full-stack technology enables the global ecosystem to transform industries through AI-driven robotics. NVIDIA's extensive AI tool library, including the new Alpamayo open-source model portfolio, enables the global transportation industry to quickly achieve safe L4 driving. The NVIDIA DRIVE autonomous driving platform is now in production, equipped in all new Mercedes-Benz CLA vehicles for L2++ AI-defined driving.

01. New AI Supercomputer: 6 Self-Developed Chips, Single Rack Computing Power Reaches 3.6 EFLOPS
Jensen Huang believes that every 10 to 15 years, the computer industry undergoes a comprehensive reshaping. But this time, two platform transformations are happening simultaneously: from CPU to GPU, and from "programming software" to "training software." Accelerated computing and AI are reconstructing the entire computing stack. The computing industry, worth $10 trillion over the past decade, is undergoing a modernization transformation.
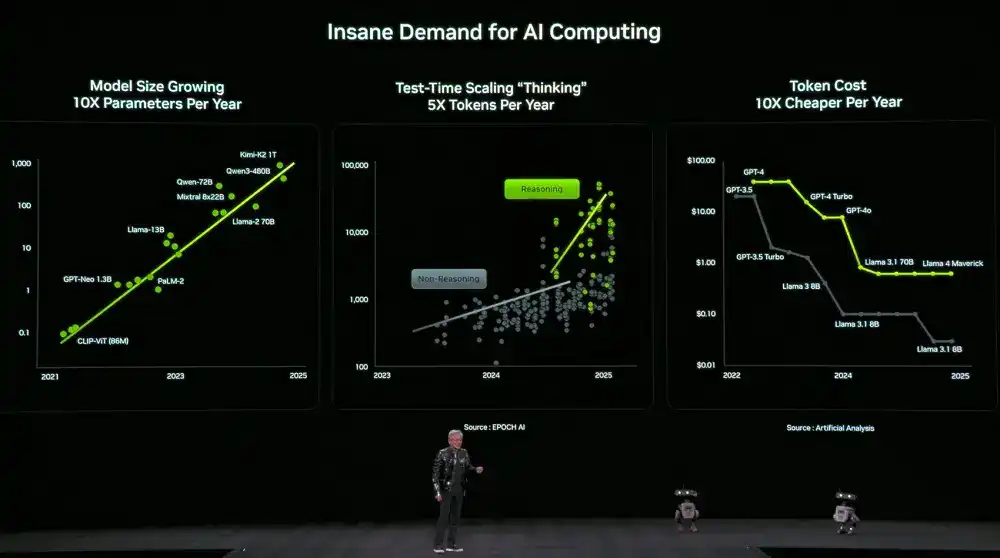
At the same time, the demand for computing power is soaring dramatically. Model size grows 10x annually, the number of tokens used for model thinking grows 5x annually, and the cost per token decreases 10x annually.
To meet this demand, NVIDIA has decided to release new computing hardware every year. Huang revealed that Vera Rubin has now fully entered production.
The new NVIDIA Vera Rubin POD AI supercomputer utilizes six self-developed chips: Vera CPU, Rubin GPU, NVLink 6 Switch, ConnectX-9 (CX9) SmartNIC, BlueField-4 DPU, and Spectrum-X 102.4T CPO.
Vera CPU: Designed for data movement and agent processing, it features 88 NVIDIA custom Olympus cores, 176-thread NVIDIA spatial multithreading, 1.8 TB/s NVLink-C2C supporting CPU:GPU unified memory, system memory up to 1.5 TB (3x that of Grace CPU), SOCAMM LPDDR5X memory bandwidth of 1.2 TB/s, and supports rack-level confidential computing, doubling data processing performance.

Rubin GPU: Introduces a Transformer engine, achieving NVFP4 inference performance up to 50 PFLOPS, 5x that of Blackwell GPU, with backward compatibility, maintaining inference precision while improving BF16/FP4 level performance; NVFP4 training performance reaches 35 PFLOPS, 3.5x that of Blackwell.
Rubin is also the first platform to support HBM4, with HBM4 bandwidth reaching 22 TB/s, 2.8x that of the previous generation, providing the required performance for demanding MoE models and AI workloads.

NVLink 6 Switch: Single lane rate increased to 400 Gbps, using SerDes technology for high-speed signal transmission; each GPU achieves 3.6 TB/s of full interconnect communication bandwidth, 2x the previous generation, total bandwidth is 28.8 TB/s, in-network computing performance reaches 14.4 TFLOPS at FP8 precision, and supports 100% liquid cooling.

NVIDIA ConnectX-9 SuperNIC: Provides 1.6 Tb/s bandwidth per GPU, optimized for large-scale AI, with fully software-defined, programmable, accelerated data paths.

NVIDIA BlueField-4: 800 Gbps DPU, used for SmartNICs and storage processors, equipped with 64-core Grace CPU, combined with ConnectX-9 SuperNIC, for offloading network and storage-related computing tasks, while enhancing network security capabilities. Computing performance is 6x the previous generation, memory bandwidth is 3x, and GPU access to data storage speed is increased to 2x.

NVIDIA Vera Rubin NVL72: Integrates all the above components into a single-rack processing system at the system level, featuring 2 trillion transistors, NVFP4 inference performance of 3.6 EFLOPS, and NVFP4 training performance of 2.5 EFLOPS.
The system's LPDDR5X memory capacity reaches 54 TB, 2.5x the previous generation; total HBM4 memory is 20.7 TB, 1.5x the previous generation; HBM4 bandwidth is 1.6 PB/s, 2.8x the previous generation; total scale-up bandwidth reaches 260 TB/s, exceeding the total bandwidth scale of the global internet.

The system is based on the third-generation MGX rack design. The compute tray features a modular, hostless, cableless, fanless design, making assembly and maintenance 18x faster than GB200. Assembly work that originally took 2 hours now takes about 5 minutes. While the original system used about 80% liquid cooling, it now uses 100% liquid cooling. The single system itself weighs 2 tons, and with coolant, it can reach 2.5 tons.

The NVLink Switch tray enables zero downtime maintenance and fault tolerance; the rack can still operate when a tray is removed or partially deployed. The second-generation RAS engine enables zero downtime health checks.
These features improve system uptime and throughput, further reducing training and inference costs, meeting data center requirements for high reliability and high maintainability.
Over 80 MGX partners are ready to support the deployment of Rubin NVL72 in hyperscale networks.
02. Three Major New Releases Drastically Improve AI Inference Efficiency: New CPO Device, New Context Storage Layer, New DGX SuperPOD
Simultaneously, NVIDIA released three important new products: NVIDIA Spectrum-X co-packaged optics for Ethernet, NVIDIA Inference Context Memory Storage Platform, and the NVIDIA DGX SuperPOD based on DGX Vera Rubin NVL72.
1. NVIDIA Spectrum-X Co-Packaged Optics for Ethernet
The NVIDIA Spectrum-X co-packaged optics for Ethernet is based on the Spectrum-X architecture, uses a 2-chip design, employs 200 Gbps SerDes, and each ASIC can provide 102.4 Tb/s bandwidth.
This switching platform includes a 512-port high-density system and a 128-port compact system, each port rate is 800 Gb/s.

The CPO (Co-Packaged Optics) switching system achieves 5x improvement in energy efficiency, 10x improvement in reliability, and 5x improvement in application uptime.
This means more tokens can be processed per day, further reducing the total cost of ownership (TCO) of data centers.
2. NVIDIA Inference Context Memory Storage Platform
The NVIDIA Inference Context Memory Storage Platform is a POD-level AI-native storage infrastructure for storing KV Cache. Based on BlueField-4 and Spectrum-X Ethernet acceleration, tightly coupled with NVIDIA Dynamo and NVLink, it achieves协同 context scheduling between memory, storage, and network.
This platform treats context as a first-class data type, achieving 5x inference performance and 5x better energy efficiency.

This is crucial for improving long-context applications like multi-turn conversations, RAG, and Agentic multi-step reasoning. These workloads highly depend on the ability to efficiently store, reuse, and share context throughout the system.
AI is evolving from chatbots to Agentic AI, which reasons, calls tools, and maintains long-term state. Context windows have expanded to millions of tokens. This context is stored in the KV Cache. Recomputing it every step wastes GPU time and creates huge latency, hence the need for storage.
But GPU memory, while fast, is scarce. Traditional network storage is too inefficient for short-term context. The AI inference bottleneck is shifting from computation to context storage. Therefore, a new memory layer between GPU and storage, optimized for inference, is needed.

This layer is no longer an afterthought patch but must be co-designed with network storage to move context data with minimal overhead.
As a new storage tier, the NVIDIA Inference Context Memory Storage Platform does not reside directly in the host system but is connected externally to the computing devices via BlueField-4. Its key advantage is the ability to scale the storage pool size more efficiently, thereby avoiding redundant computation of KV Cache.
NVIDIA is working closely with storage partners to bring the NVIDIA Inference Context Memory Storage Platform to the Rubin platform, enabling customers to deploy it as part of a fully integrated AI infrastructure.
3. NVIDIA DGX SuperPOD Built on Vera Rubin
At the system level, the NVIDIA DGX SuperPOD serves as a blueprint for large-scale AI factory deployment. It uses 8 sets of DGX Vera Rubin NVL72 systems, with NVLink 6 for scale-up networking and Spectrum-X Ethernet for scale-out networking, incorporates the NVIDIA Inference Context Memory Storage Platform, and is engineering-validated.
The entire system is managed by NVIDIA Mission Control software for ultimate efficiency. Customers can deploy it as a turnkey platform, completing training and inference tasks with fewer GPUs.
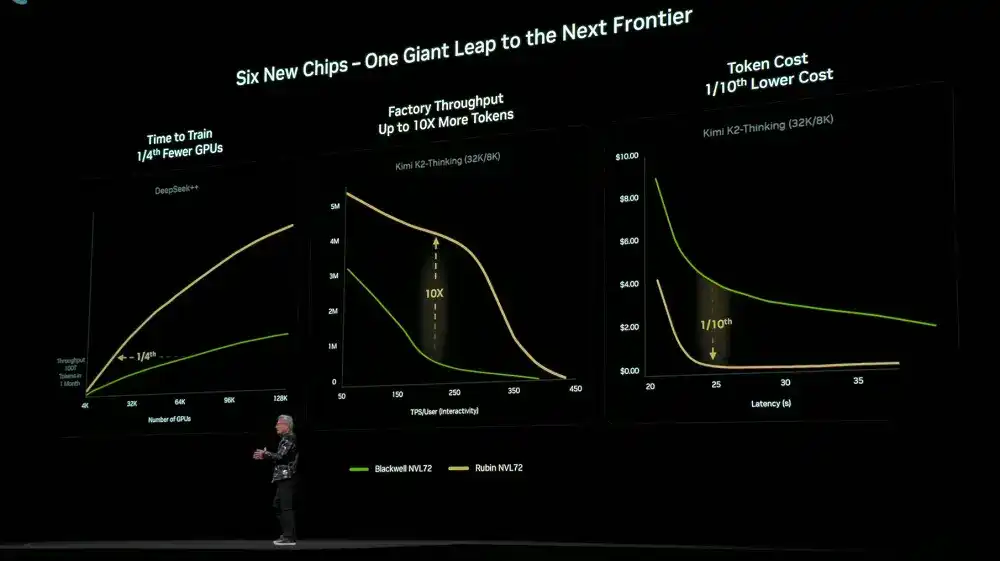
Due to极致 co-design at the 6-chip, tray, rack, Pod, data center, and software levels, the Rubin platform achieves a significant drop in training and inference costs. Compared to the previous generation Blackwell, training MoE models of the same scale requires only 1/4 the number of GPUs; at the same latency, the token cost for large MoE models is reduced to 1/10th.
The NVIDIA DGX SuperPOD using the DGX Rubin NVL8 system was also announced.
Leveraging the Vera Rubin architecture, NVIDIA is working with partners and customers to build the world's largest, most advanced, and lowest-cost AI systems, accelerating the mainstream adoption of AI.