Author: XinZhiYuan
Google I/O 2026 goes all out!
Just now, Pichai and Demis Hassabis took the stage together, unveiling all the major releases they've been accumulating for half a year in one go.

Without any suspense, the biggest star of the night, Gemini Omni, officially debuted!
As a truly "omni" model, Omni can accept any form of input and generate any content. It debuts with video output support, making it the "video version of Nano Banana".

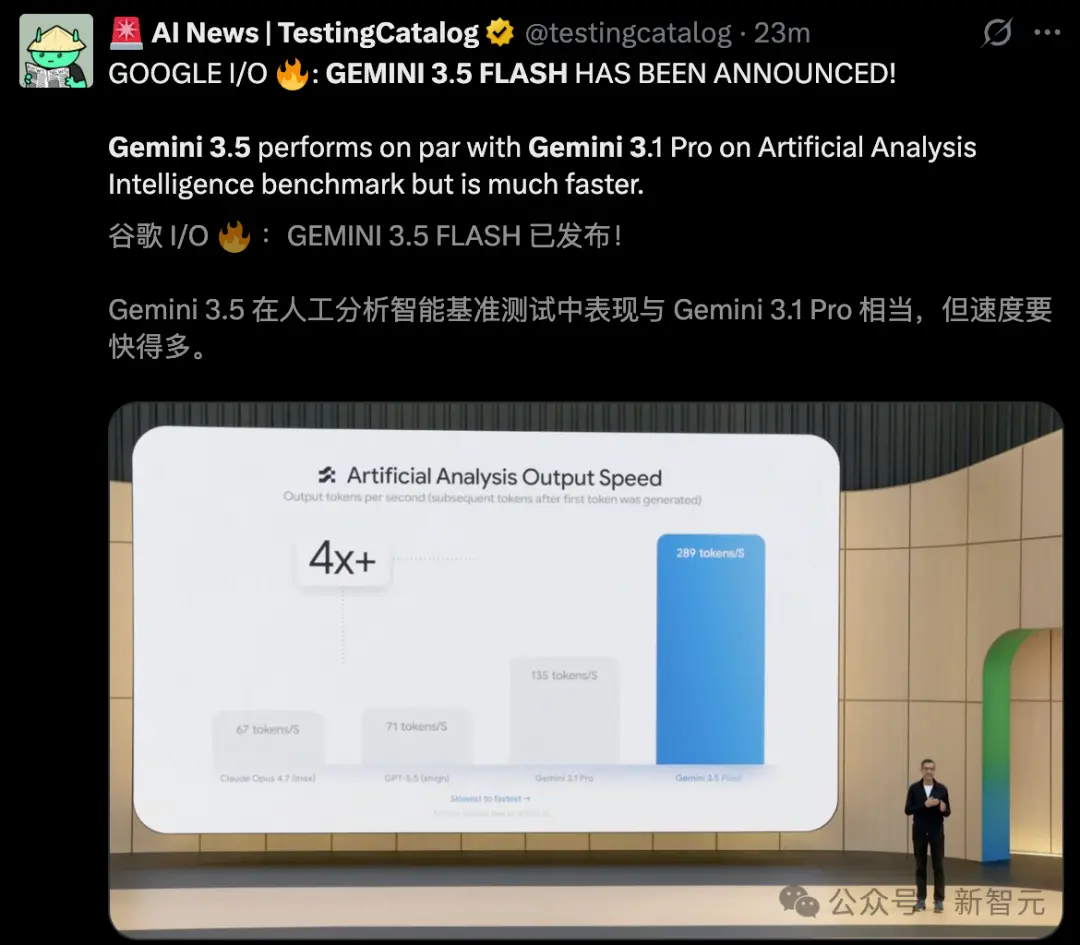
Another highlight of the night belongs to Gemini 3.5 Flash.
In almost all benchmarks, 3.5 Flash has achieved a crushing victory over its predecessor flagship, Gemini 3.1 Pro. Its output speed has also doubled, and it is over 4 times faster than GPT-5.5 and Opus 4.7. The more powerful 3.5 Pro will be released next month.
In addition, a slew of other major new products were unveiled:
-
Antigravity 2.0: A brand-new standalone desktop application, evolving from an IDE to an Agent development platform.
-
Gemini Spark: A personal AI agent, running 24/7 in the cloud.
-
Gemini App Redesign: Code-named "Neural Expressive," switching to compute-based billing.
-
AI Ultra Subscription Plan: Adds a new $100 tier; highest tier reduced from $250 to $200.
-
Google Search's Biggest Upgrade in 25 Years: Integrated with 3.5 Flash, adds intelligent search box, automatic mini-app generation, etc.
......
Without exaggeration, the density of substantive announcements at this I/O is the highest in years.
Gemini Omni Debut: The Birth of an 'Omni' AI
As hinted by the teaser video, the highly anticipated Gemini Omni has finally arrived. Hassabis personally took the stage to announce, "We are taking the next important step—Gemini Omni, a new model that can create content from any input."

This prominence says it all. What Google aims to build this time is an "omni" AI creation engine. It integrates Gemini's intelligence with the strongest generative AI, fully maximizing capabilities in world understanding, multimodality, and editing. Put simply, given any combination of images, audio, video, and text, it can generate a high-quality video. Moreover, you can edit videos through conversation.
More crucially, Omni doesn't just "look like it"; it truly understands the physical world. Hassabis stated, "Previous systems often stumbled when simulating concepts like gravity and momentum, but Omni achieves a 'step change.'" It injects Gemini's "world knowledge" and "reasoning ability" into video generation.
-
Given the prompt "Explain protein folding using clay animation," the generated video accurately depicts amino acid chains folding into α-helices and β-sheets at every step, visually presented as exquisite stop-motion animation.

-
Another example: assigning corresponding objects to the 26 letters of the English alphabet. C for Capybara, D for Disco Ball, L for Lava Lamp. Omni isn't just pasting assets; it's genuinely connecting language, images, and semantics.

It has to be said, the leap from realism to meaningfulness is enormous.

On stage, Hassabis pulled out a selfie video and began live editing. A circle drawn on a palm turned into a black hole; an evening street stroll transformed into a cyberpunk scene. Rewrite the scene with a sentence, change the world with another. Anything can become a canvas for creating new realities. For instance, conjuring fire in your palm from a selfie, or a circle drawn on paper instantly becoming a black hole—all sorts of imaginative possibilities are now achievable.



Moreover, this isn't a one-time generation. You can continue the conversation. Characters remain consistent in Gemini Omni's video output, physical logic holds, and scene memory is coherent.
-
Starting from an original performance clip. Round two: "Teleport the violinist into the environment of this picture," attaching a reference image of snowy mountains and meadows. The scene instantly switches, with actions and lighting fully adapting to the new environment.
-
Round three: "Cut the shot to behind the violinist's shoulder." The perspective rotates, but the performance actions and music remain completely continuous.

No matter how the scene changes, the main subjects in the video do not break.

What's even more thought-provoking is Omni's input flexibility. Images, text, video, audio—any references can be mixed as input to generate a coherent output. You can even create your own avatar, allowing an AI version of you to appear in any scene, speaking with your voice and doing things you haven't done.
Currently, Omni Flash is officially launched, with the API version opening in the coming weeks. The more powerful Omni Pro is also on the way. Leveraging Google's powerful integration capabilities, Omni is integrated at launch with Gemini App, Google Flow, and YouTube Shorts, and even free for YouTube Shorts users.

Flash Overtakes Pro: 3.5 Redefines 'Flagship'
Following Gemini Omni, another major highlight of this I/O is the release of the new flagship, Gemini 3.5 Flash. Google defines it as the strongest coding and agent model to date.

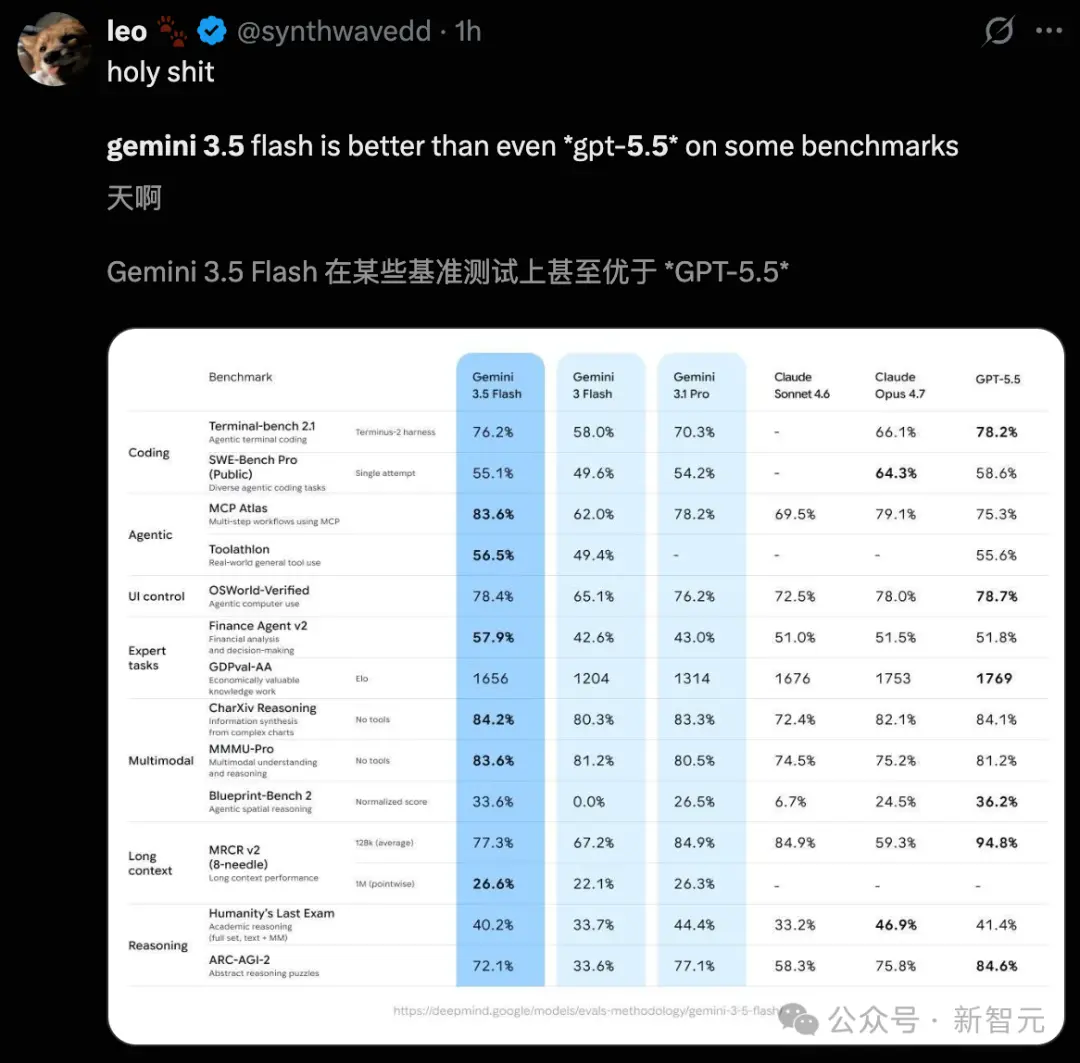
On stage, Pichai personally announced, "3.5 Flash outperforms Gemini 3.1 Pro across virtually all benchmarks!" Remember, 3.1 Pro was the flagship model Google launched just three months ago. Now, a Flash-tier model is crushing it.
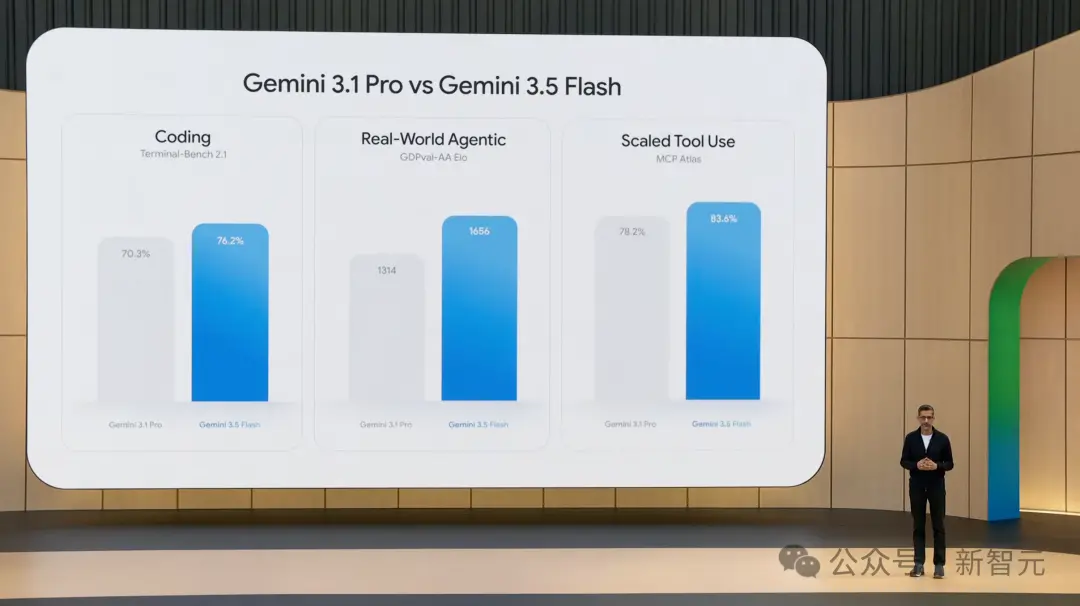
Unexpectedly, Google delivered such impressive results in such a short time:
-
Terminal-Bench 2.1 (Coding): 76.2%
-
GDPval-AA (Real-world Agent Tasks): 1656 Elo
-
MCP Atlas (Large-scale Tool Usage): 83.6%
-
CharXiv Reasoning (Multimodal Understanding): 84.2%
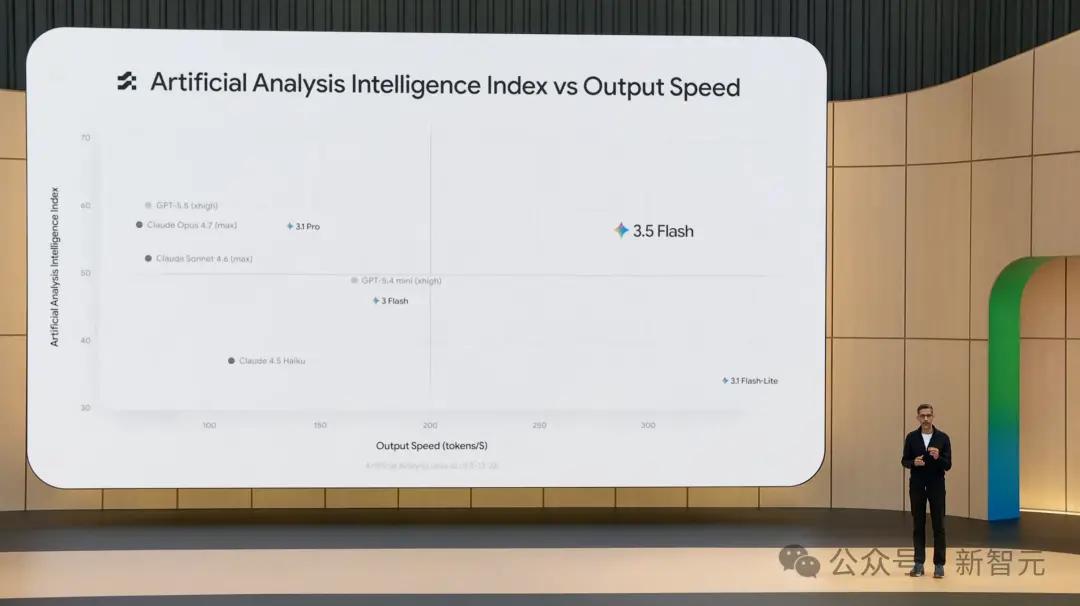
In the four major benchmarks above, compared to Gemini 3.1 Pro, 3.5 Flash represents a massive leap forward. In terms of speed, 3.5 Flash occupies its own quadrant at 289 tokens/second, over 4 times faster than other frontier models. Additionally, 3.5 Flash matches or even surpasses GPT-5.5 and Claude Opus 4.7 in some benchmarks. It must be said, 3.5 Flash is both fast and powerful, with virtually no rivals.

Numbers are abstract; let's look at real demonstrations. In an instant, 3.5 Flash can digest an abstruse academic paper and write a fully interactive, visual website. In agent tasks, via Antigravity, it can complete multi-step workflows, automatically categorizing and naming sprawling assets. Or, using two agents, it reproduced the AlphaZero paper in just six hours and coded a fully playable game.
93 Agents Build an OS in Just 12 Hours
It's evident that all these capabilities of 3.5 Flash are enabled by the new Antigravity 2.0. Today, Google's agent development platform, Antigravity, has been upgraded to version 2.0, evolving from an IDE to a standalone desktop application, fully embracing an Agent-first design.

Varun took the stage and gave a demo that left the audience breathless. He tasked Antigravity powered by 3.5 Flash with building an operating system from scratch. 93 sub-agents worked in parallel, making over 15,000 model calls, processing 2.6 billion tokens. Twelve hours later, a completely blank project transformed into a fully functional OS kernel. Scheduler, memory management, file system—every line of code was written by agents, tested by agents, and audited by agents. The API cost was under $1,000.

Then, he attempted to run DOOM on this AI-written operating system. The first attempt failed, lacking video and keyboard drivers. So he immediately entered a fix command in Antigravity 2.0, and the agents began automatically writing the driver code. After a moment, the DOOM screen appeared, and the venue erupted.
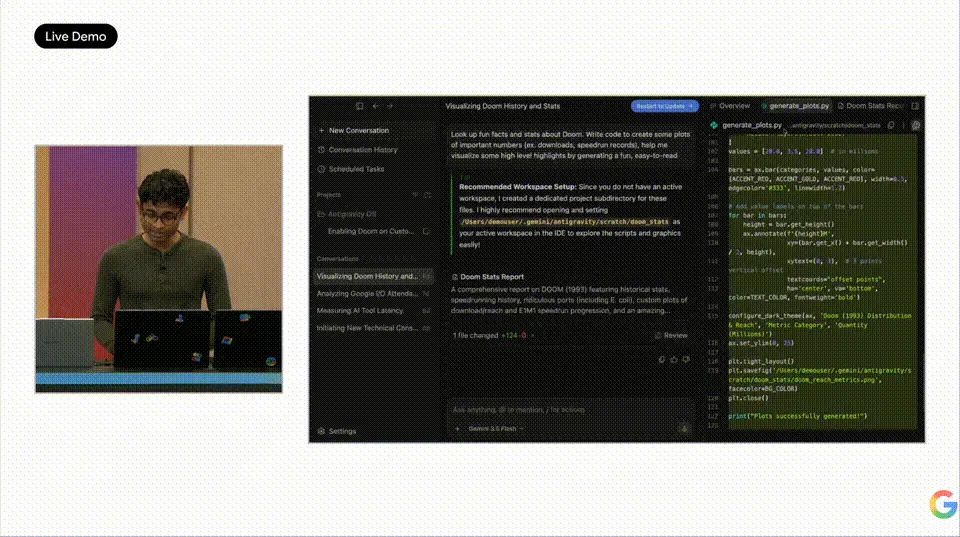
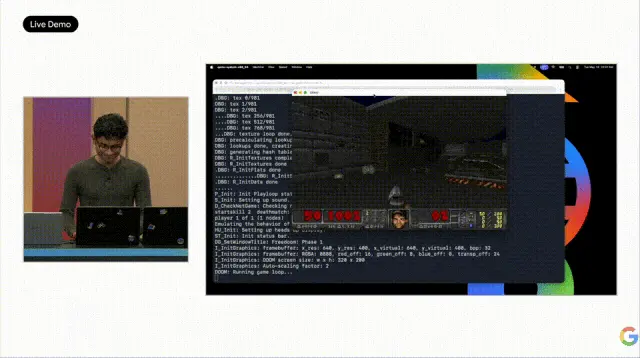
To summarize, Antigravity 2.0's core upgrades include:
-
Sub-agents can be dynamically generated; the main agent splits tasks into subtasks and assigns them out, running in parallel without interference.
-
Asynchronous task management prevents long-running operations from blocking the main thread.
-
Scheduled Tasks allow setting "timed tasks" for agents to execute automatically, like checking PR status once a day or running a health check script every hour.
-
New slash commands:
/goallets the agent run to completion;/grill-memakes the agent clarify requirements before acting;/browserexplicitly controls browser usage.
However, these are capabilities already proven internally. The token processing speed using Antigravity internally at Google was 500 billion per day in March. Now, it's roaring at 3 trillion per day. Moreover, this 12x accelerated Flash is available in Antigravity starting today.
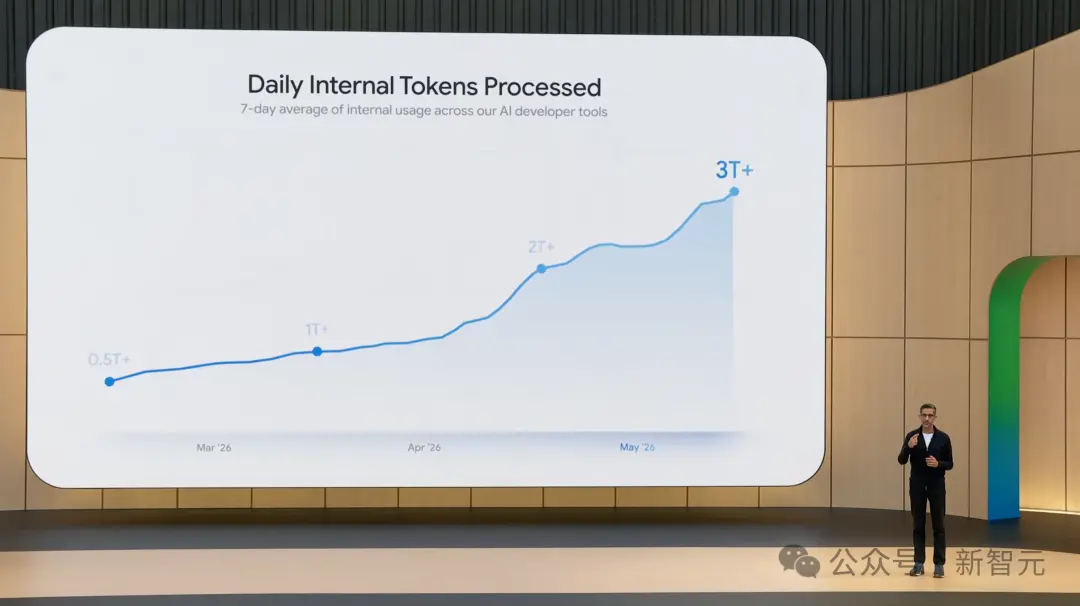
3.5 Flash is now the default model for both the Gemini App and Google Search AI Mode, available to all users worldwide. Developers can access it via Antigravity 2.0, Gemini API, and Google AI Studio. Enterprise users can onboard via Gemini Enterprise Agent Platform. Even more explosive, 3.5 Pro is currently in internal testing and will be released next month.

24/7 Personal Assistant: Google Spark Finally Arrives
The third major announcement tonight is undoubtedly Gemini Spark! Pichai's positioning for it is very clear: your personal AI agent. It doesn't stop even when you close your laptop. It runs on a dedicated virtual machine in the cloud, enabling 24/7 availability.


Gemini Spark is powered by Gemini 3.5 + the Antigravity framework, deeply integrated with Google's "Workspace suite." Product VP Josh Woodward took the stage to demonstrate two scenarios that drove the audience wild.
-
The first is a work scenario: Input an instruction, "Draft an email for the team summarizing all information from the past week about the Gemini Live launch." Spark automatically pulls information across Gmail, Docs, and chat logs, and also invokes a "ghostwriter" skill Woodward wrote himself, making the email automatically match his personal tone. The entire process is done in the background; a human only needs to review and send. Yes, Spark supports custom skills, allowing it to learn your voice, your preferences, and your work style.
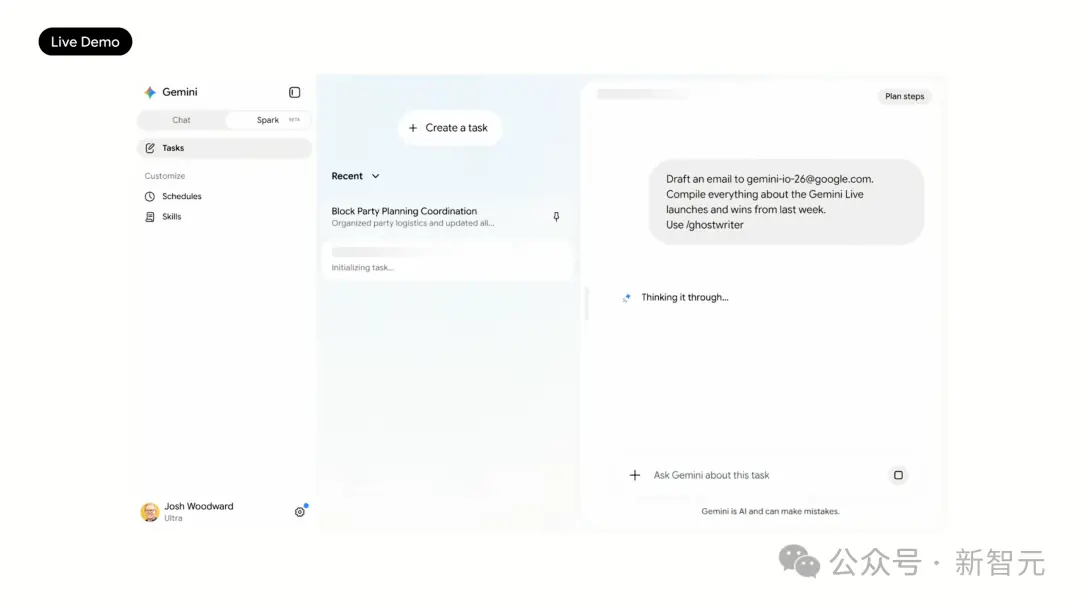
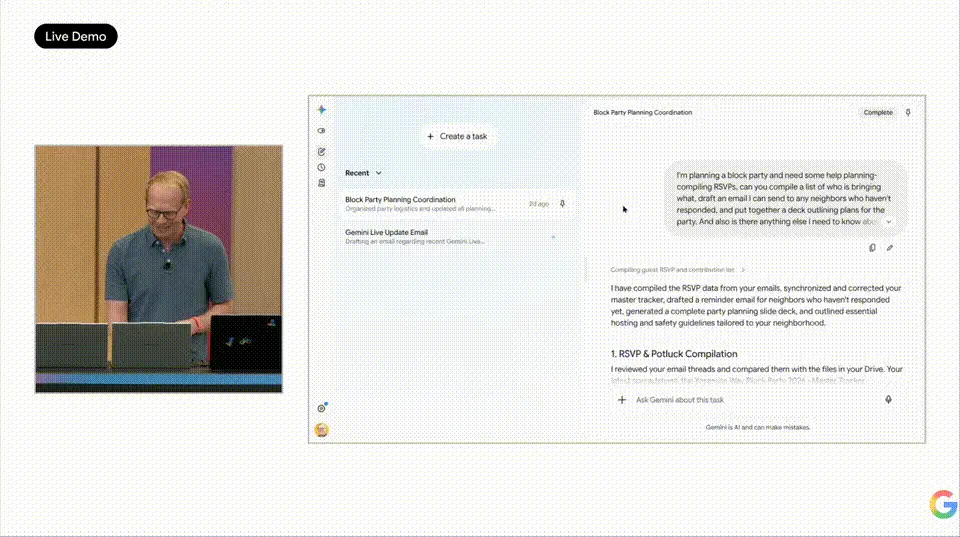
-
The second is a life scenario: Planning a neighborhood block party. Upon receiving the task, Spark executes step by step. It creates an RSVP tracking sheet in Google Sheets, directly linked to Gmail, updating automatically as people reply. For neighbors who haven't signed up, Spark automatically drafts reminder emails, creating drafts for confirmation before sending. Then, it also generates a promotional deck in Google Slides, even including information about placing an inflatable castle in the neighborhood. The entire process didn't involve opening a single app.
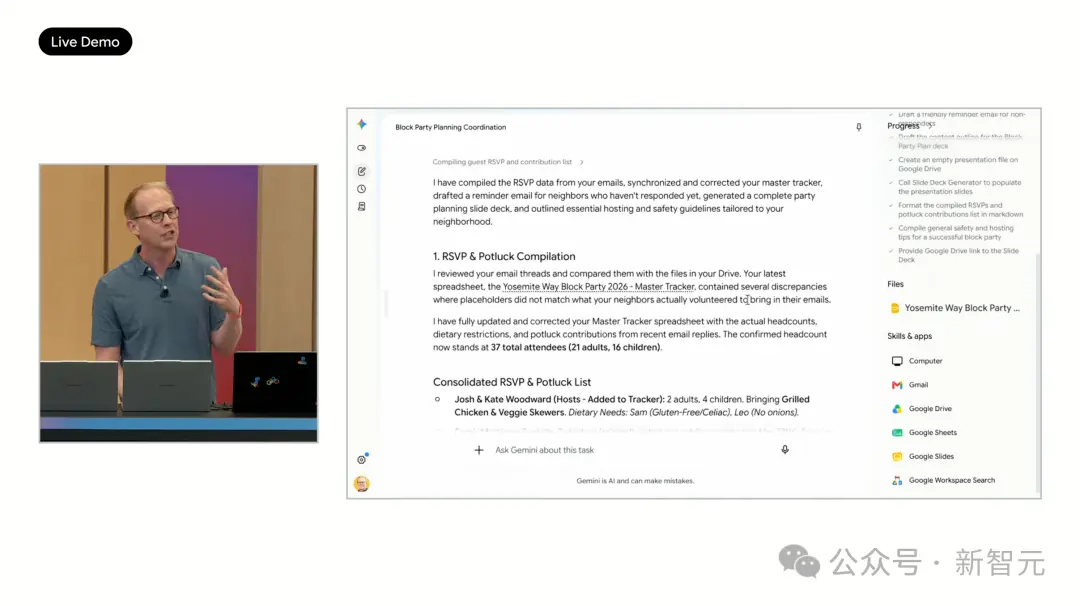
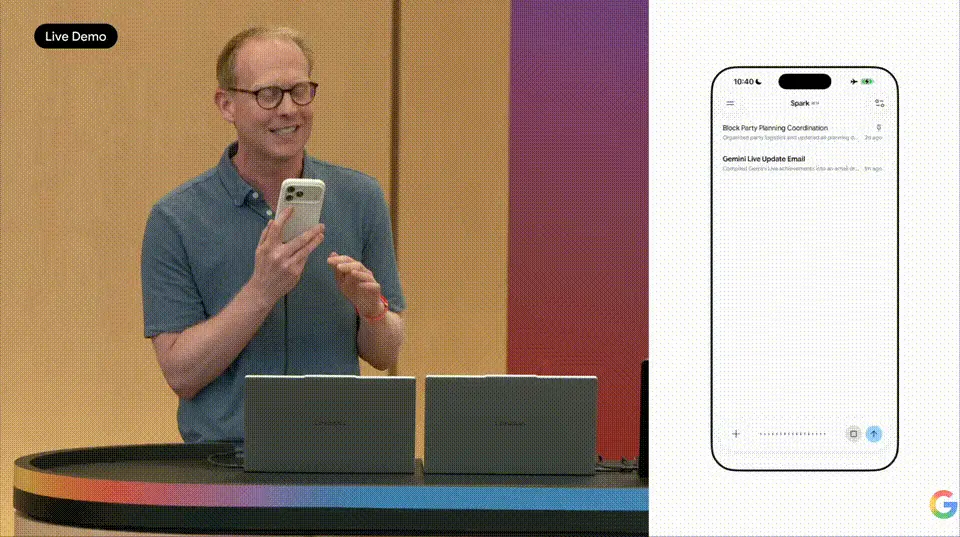
Moreover, Spark possesses powerful voice input capabilities. Live on stage, Woodward pulled out his phone and directly issued three tasks via voice: "Find all meetings with Sundar and mark them bright pink," "Write an invitation for new neighbor John to join the block party list," "Create a doc listing things to do for the kids before the school year ends, sorted by deadline."
The voice directly converted into text instructions, and Spark automatically split the continuous voice input into three independent task threads, executing them in parallel in the background.
Regarding pricing, the $100/month AI Ultra subscription provides access to the Spark Beta. The highest-tier Ultra plan has been reduced from $250 to $200. Spark will be available as a Beta next week, initially for U.S. AI Ultra subscribers.
Tonight, Google Unveils the Gateway to ASI
Looking back at this I/O, what's truly chilling isn't any single product. It's that all these capabilities arrived simultaneously.
Full multimodal understanding, full multimodal generation, and 24/7 online Agents—these three puzzle pieces were all put in place by Google in one night. Omni turns a sentence into a world without humans providing any assets; 93 agents create an operating system from scratch without humans writing a single line of code; Spark works for you 24/7 without humans opening an app.
When AI no longer needs humans to "feed it," but understands, decides, executes, and iterates on its own—the end of this road is called ASI (Artificial Superintelligence).
No one can give a definitive timeline. But tonight's Google I/O made everyone realize one thing: On the path to superintelligence, the obstacle of "technically impossible" no longer exists. What remains is merely the speed of engineering deployment. Half a year ago, we were debating whether AGI was a bubble. Half a year later, Google is already writing operating systems with agents. The acceleration in this industry has already surpassed what human intuition can perceive.
References:
-
https://youtu.be/wYSncx9zLIU
-
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/
-
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni/
-
https://antigravity.google/blog/introducing-google-antigravity-2-0
-
https://antigravity.google/blog/google-io-2026-feature-deep-dive
Edited by: Peach Moses





