Original Title: DeepSeek's 10 trillion USD grand strategy
Original Author: @bookwormengr
Original Compilation: Peggy, BlockBeats
Editor's Note: Over the past year, discussions about DeepSeek have mostly focused on model performance, open source strategy, and price wars. However, understanding DeepSeek solely from perspectives like "selling subscriptions or not," "having multimodal capabilities or not," or "being able to act as a coding agent or not" might underestimate what it truly aims to change.
This article proposes a more radical judgment: DeepSeek's goal might not be short-term monetization through the application layer, but rather to reshape the cost structure of AI training and inference through a series of foundational architectural innovations, and indirectly catalyze the formation of a new hardware ecosystem. From MoE and MLA to DSA, CSA, mHC, Engram, and further to Dual Path and TileLang, DeepSeek's technical roadmap consistently revolves around one core question: how to achieve stronger models with less high-end computing power, under constraints of HBM, advanced manufacturing processes, packaging, and the CUDA ecosystem.
The most noteworthy aspect of this article is not "whether DeepSeek can earn a few hundred million dollars through APIs or subscriptions," but whether it is binding model capabilities, memory architecture, and the domestic hardware ecosystem together. KV Cache compression reduces reliance on HBM, NAND and SSDs can accommodate long-term caching, LPDDR can be used for weight streaming and Engram storage, and TileLang attempts to weaken the CUDA moat. If these innovations continue to proliferate, the beneficiaries won't be just DeepSeek itself, but also storage, ASICs, GPUs, networking chips, and the entire AI infrastructure chain.
Of course, the judgments in the article about a "$10 trillion industrial ecosystem" and a "$1 trillion valuation" still carry a strong speculative tone. But it provides an important path to understanding DeepSeek: open source doesn't necessarily mean abandoning commercialization, and low prices aren't necessarily just about subsidizing the market. For DeepSeek, the real business might not be at the application layer, but in making more hardware viable and enabling lower-cost AI supply. In other words, what it's selling might not be the model itself, but the feasibility of the next generation of AI infrastructure.
Original Article:

Have you ever wondered how DeepSeek is actually going to make money, and potentially a lot of it?
It hasn't launched competitive coding subscription plans like GLM, MoonShot, and MiniMax; it doesn't have multimodal, audio, or video models. So far, it doesn't even have its own harness—the outer runtime framework for model invocation, tool integration, and task execution—though they have recently started hiring for related positions to build this system.
Meanwhile, DeepSeek seems to be a long-term, steadfast proponent of open source, even happily sharing its "secret sauce." Isn't this crazy? Isn't it just burning money for nothing? Are the investors ready to pour in $10 billion just throwing their money down the drain?
I personally believe the answer is quite the opposite.
Next, based on what DeepSeek has done so far, I'll offer some observations and analyze the strategy it appears to be following. DeepSeek CEO Liang Wenfeng's ambitions likely extend far beyond the current model competition. He might be aiming for a much bigger prize: DeepSeek has the opportunity to reach a $1 trillion valuation while catalyzing the formation of a new $10 trillion industry.

TechInAsia report on DeepSeek's latest funding round
Revisiting DeepSeek's "Hero's Journey"
DeepSeek has always been going against the grain. It hasn't chosen to continuously release slightly better models and hastily package them as directly monetizable applications, like coding subscriptions. On January 27, 2025, I posted a widely circulated tweet about what I saw as DeepSeek's "Hero's Journey." Now, that story has become even more interesting.
While others were still trying to build dense models, DeepSeek chose the more difficult-to-train Mixture of Experts (MoE).
They adopted a "first principles" approach, inventing the new GRPO algorithm to replace the then-mainstream but costlier-to-implement PPO reinforcement learning algorithm.
They found that Reinforcement Learning from Verified Rewards (RLVR) was a key strategy for improving model reasoning capabilities.
They also proposed a simple speculative decoding strategy through "Multi Token Prediction," while also making training signals more dense.
They perfected the "ZERO bubble" pipeline to improve the utilization efficiency of limited GPU resources.
They released an expert load balancer, making it easier for everyone to deploy MoE models. Particularly, with the "Wide Expert Parallel" strategy, models can serve with larger batches, significantly reducing inference costs.
They invented mechanisms like MLA, DSA, CSA, HCA to reduce KV Cache requirements and keep the computational demand increase with context length as close to constant as possible.
They invented Engram, trading memory for computational efficiency.
They also invented mHC, enabling stable training even as model size scales. And there are many more examples like these.
In the "Hero's Journey," the most universal narrative structure, the hero never decides at the outset where their journey will ultimately lead. They learn along the way, gradually discovering their truly great mission and accomplishing it against formidable obstacles. They face many doubters but choose to ignore them. They also face malicious actors. They have apparent flaws or weaknesses but ultimately overcome them to fulfill their mission. They face seemingly insurmountable challenges but find ways to form alliances and learn to use their limited, precious resources wisely. This is precisely what makes the audience cheer for the hero. This is also why DeepSeek has won followers, global respect, and detractors.
As I will detail next, DeepSeek has been on this path for a long time and is gradually discovering its ultimate destiny: its goal is not to sell coding subscriptions, but to propel a $10 trillion Chinese AI hardware ecosystem and achieve a $1 trillion valuation for itself. In the process, it will also create opportunities for many new entrants in the Western hardware ecosystem.

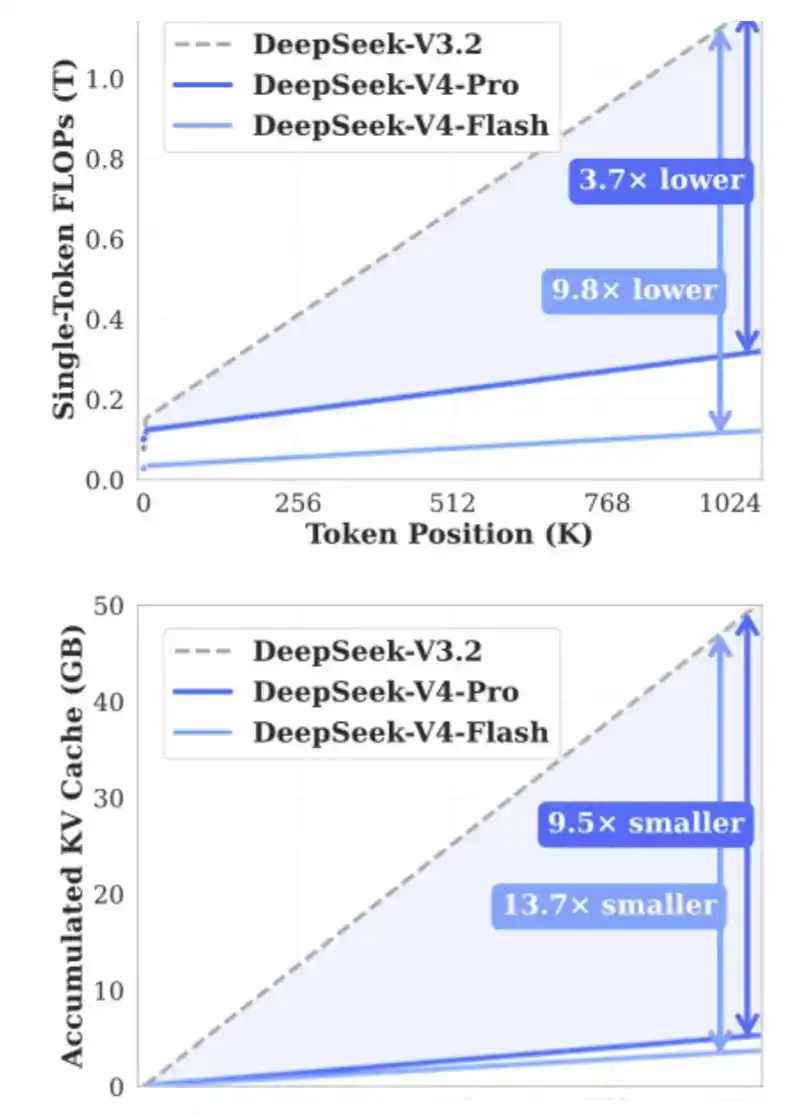
Let's start with some interesting KV Cache calculations
Take a look at this very timely recent tweet by @SemiAnalysis_:
DeepSeek has solved this problem better than anyone else!
Let's do some fun KV Cache calculations. Don't worry, even if you don't like math. We'll use the recently released KV Cache calculator to see how much KV Cache savings DeepSeek V4 Pro brings and compare it with the latest GLM and Qwen models.
Here I calculate for a 1 million context length, assuming 8-bit KV precision and 16-bit indexer precision. You can also try this calculator yourself: https://kvcache.ai/tools/kv-cache-calculator/
You can also try the calculator yourself!
At 1 million context length:
· DeepSeek V4 requires only 5.48GB HBM;
· GLM-5 requires 60GB HBM;
· Qwen3-235B-A22B requires a whopping 89GB HBM.
Note that:
· DeepSeek is a 1.6 trillion parameter model;
· GLM-5 is about 700 billion parameters and has already adopted DeepSeek's MLA and DSA, though not the latest compressed attention mechanisms;
· Qwen3-235B-A22B is about 235 billion parameters, using GQA attention mechanism.
DeepSeek has made fundamental contributions to alleviating memory pressure. If such innovations are widely adopted, they will significantly reduce the operating costs of long-horizon agents and unlock the next batch of new applications.
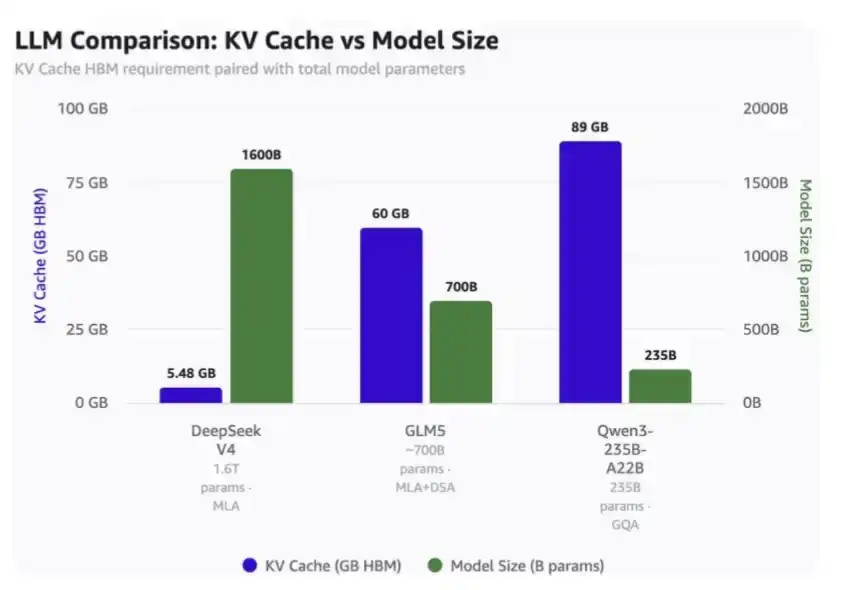
KV Cache occupancy comparison for 1 million token context and model sizes
The methodology behind the "madness"
The ability to keep the KV Cache volume so small without sacrificing model quality is precisely why DeepSeek can offer long-term caching at extremely low prices—less than 3% of Sonnet 4.6's cache hit price—and DeepSeek can keep the cache for hours.
For long-horizon tasks, a smaller KV Cache means it can be offloaded to SSD more economically and reloaded when needed. This reduces reliance on HBM. From the perspective of China's AI hardware industry, HBM is not only in tight supply but also one of the most difficult memory types to manufacture.
Furthermore, DeepSeek has developed technology to load KV Cache from SSDs faster, as described in its Dual Path paper.
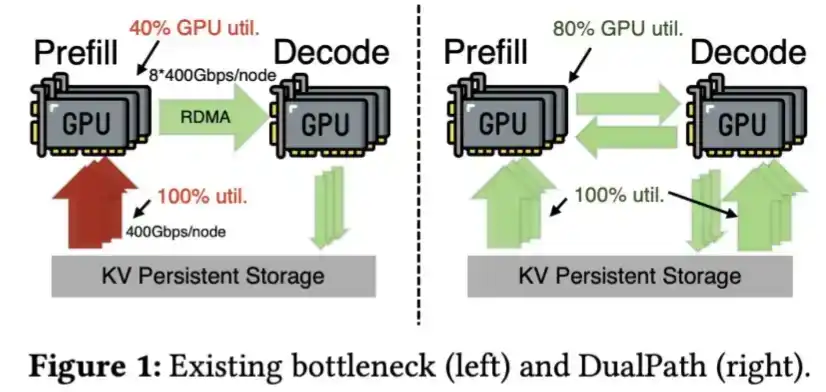
DeepSeek V4's compression of KV Cache is so significant that this step might not even be necessary.
So, who are the most direct beneficiaries of KV Cache compression?
Who supplies SSDs at scale? Don't forget, YMTC (Yangtze Memory Technologies Co.) is growing into a giant in the 3D NAND field. NAND can help DeepSeek avoid recomputing KV. In turn, DeepSeek creates a huge market for NAND and SSDs—benefiting not just YMTC but other related players.

But it's not just about NAND and SSDs.
LPDDR memory also has huge potential. It can serve as a place to store model weights and stream them into HBM on demand, alleviating pressure on HBM. The SGLang team published a great blog post introducing this. The image below shows how this scheme works.
While DeepSeek hasn't specifically designed for this scheme, its MoE architecture, large number of expert models, and 4-bit weight characteristics all make this scheme easier to implement.
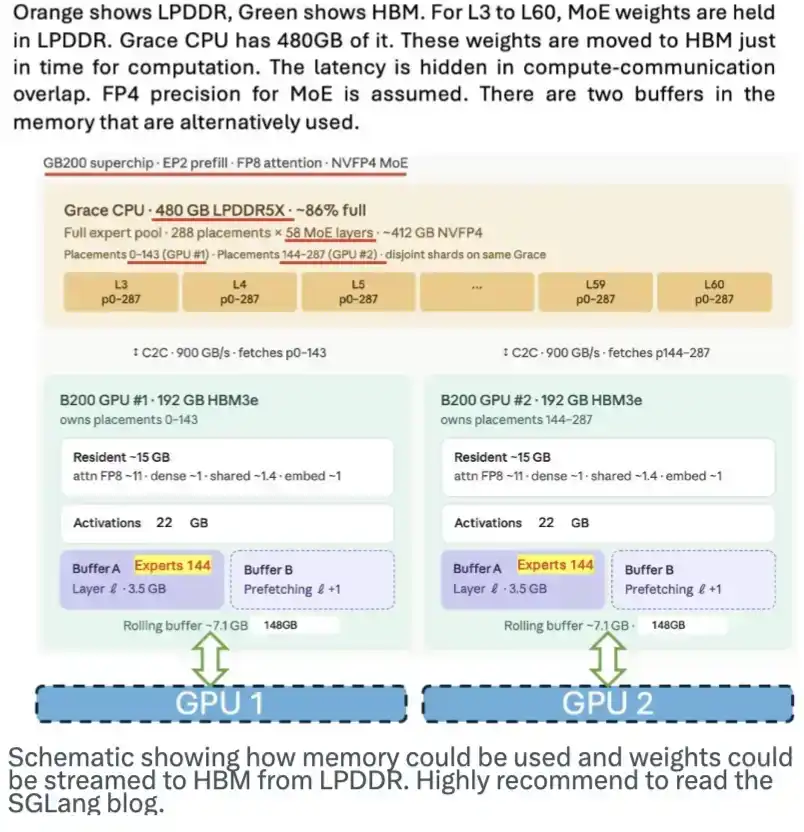
This schematic shows how memory might be used and how model weights are streamed from LPDDR to HBM. Highly recommend reading SGLang's blog post.
If this innovation is combined with extremely compact and lossless KV Cache, it will significantly reduce the demand for HBM.
So, who produces LPDDR in China? The answer is CXMT, ChangXin Memory Technologies. They are only about half a generation behind in LPDDR speed and one generation behind in density—not a huge gap.
Besides ample NAND, the Chinese AI ecosystem will also have ample LPDDR supply in the near future. Can this ease compute pressure? Answer: Yes. Keep reading.

Intelligent memory usage can also alleviate GPU/ASIC pressure
The role of using NAND to store KV Cache is easy to understand: it allows KV Cache to be retained longer, reduces pressure on HBM, avoids recomputing KV Cache, and thus alleviates the computational burden on GPUs and ASICs.
Can LPDDR play a similar role? Besides serving as a storage location to stream weights "just-in-time" into HBM on demand, can it further reduce computational pressure?
Answer: Yes.
LPDDR can be used to store a large amount of content called Engram. In DeepSeek's Engram paper, they point out that MoE can expand model capacity through conditional computation, but the Transformer itself lacks a native "knowledge lookup" mechanism. Therefore, Transformers often have to inefficiently simulate retrieval through computation.
To solve this, DeepSeek proposed the Engram module. It modernizes classic N-gram embeddings, transforming them into a hash-based O(1) lookup mechanism, creating a complementary sparsification path they call conditional memory.
This saves computation but also requires memory to host the embedding table, which itself can be very large.
Essentially, this is a classic "trade memory for compute" scheme. But the key insight is: from a per-bit read cost perspective, the "memory" side is much cheaper—one LPDDR lookup is far cheaper than having data go through multiple Transformer layers for one full forward pass. Therefore, at scale, this is a very cost-effective trade-off.
This is how DeepSeek sacrifices some memory to gain computational savings.
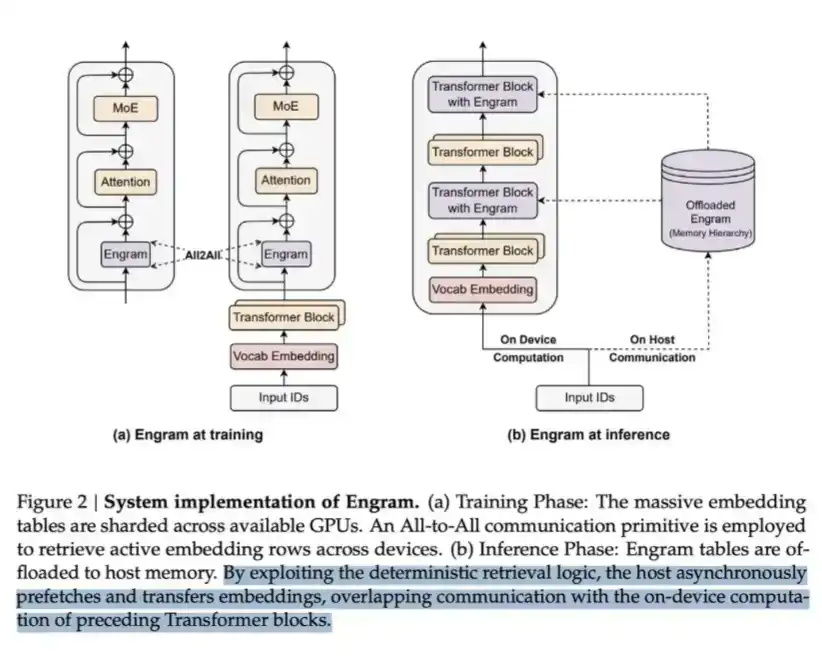
A worthwhile trade-off
Without comparable chip transistor density or EUV, Chinese GPUs and ASICs are likely to lag behind Western GPUs in raw FLOPs compute power for a long time. They also still have significant gaps in advanced packaging. Therefore, such trade-offs are very worthwhile, especially given that China can mass-produce NAND and LPDDR memory.
Reviewing DeepSeek's long-term strategy
Judging from these innovations, DeepSeek's goal doesn't seem to be making a few hundred million dollars in profit in the short term. Many of its past choices illustrate this: still no multimodal capabilities, no voice models, and video models are out of the question.
What it's really engaged in is a patient, potentially $10 trillion long-term game: catalyzing the formation of an alternative AI hardware ecosystem.
This is not only to make Chinese memory manufacturers key players in the Chinese and even global AI hardware markets but also to fundamentally reduce resource requirements, making AI model training and serving more cost-efficient. This way, many GPU, ASIC manufacturers, and networking chip vendors can become viable options.
At the same time, these innovations will also benefit the Western open-source ecosystem and the new generation of hardware manufacturers.
All the signs are already there. Let's review these innovations proposed by DeepSeek so far in detail:
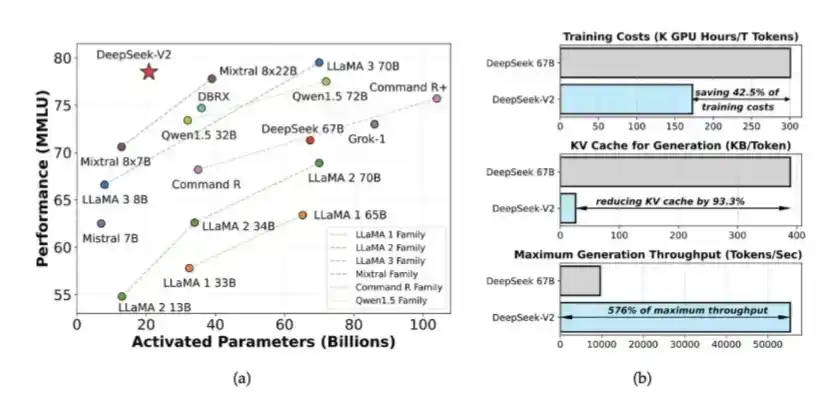
1. Mixture of Experts (MoE) and MLA introduced in DeepSeek V2
DeepSeek introduced MoE and MLA in V2. MoE reduced the computation required to train high-intelligence models by about 40-50%; MLA reduced KV Cache by 90%.
This made offloading KV Cache to SSDs quite efficient.
These ideas first appeared in the DeepSeek V2 paper released in May 2024. Later, they also laid the foundation for training DeepSeek V3. At the time, DeepSeek trained a system close to closed-source model performance using only 2048 weakened H800 GPUs.
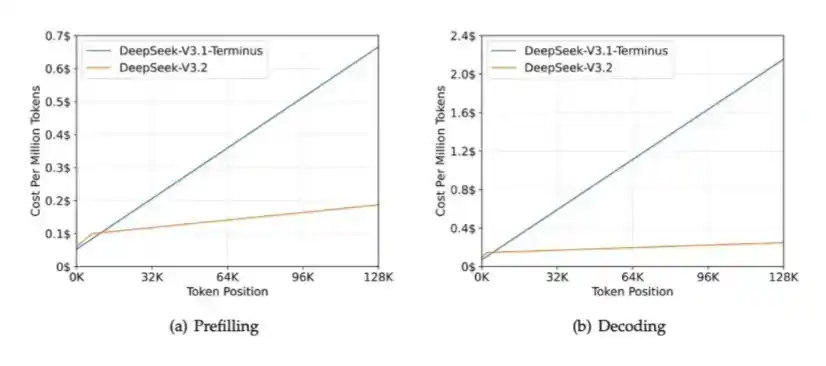
2. DSA: Introduced in DeepSeek V3.2 Exp to reduce computational overhead in long-context scenarios and alleviate HBM bandwidth pressure.
The core role of DSA is to ensure computational load doesn't continuously grow with increasing context length. Look at the chart below: as context length increases, DeepSeek-V3.2's processing time remains largely flat.
3. mHC: Proposed by DeepSeek in December 2025 in the paper "mHC: Manifold-Constrained Hyper-Connections."
mHC is a macro-architectural innovation by DeepSeek that redesigns information flow between Transformer layers.
Since ResNet, models typically used standard residual connections, i.e., x + F(x). mHC expands the residual flow into multiple parallel information channels and allows the model to perform learnable mixing between these channels. The key is that it constrains the mixing matrix to be doubly stochastic, restricting it to the Birkhoff polytope via Sinkhorn-Knopp projection. This mathematically guarantees stable signal magnitude regardless of how deep the model stacks.
This solves the catastrophic instability problem faced by earlier unconstrained Hyper-Connections. Hyper-Connections were initially proposed by ByteDance but, without constraints, signal amplification could explode 3000x at 27 billion parameters, causing training to collapse completely.
mHC's computational cost is low: it only adds about 6.7% actual training time overhead because it doesn't change the FLOPs of attention or FFN layers, only how the outputs of these layers are routed between layers.
But the performance improvement is noticeable: at 27 billion parameters, mHC improves scores by 7.2 points on BIG-Bench Hard reasoning tasks, 3.2 points on DROP, 2.8 points on GSM8K math, and 1.4 points on MMLU general knowledge—all at the same model size and nearly the same compute budget.
Essentially, mHC provides the network with a richer, more expressive inter-layer information routing topology, achieving higher intelligence per parameter with almost no extra FLOPs.
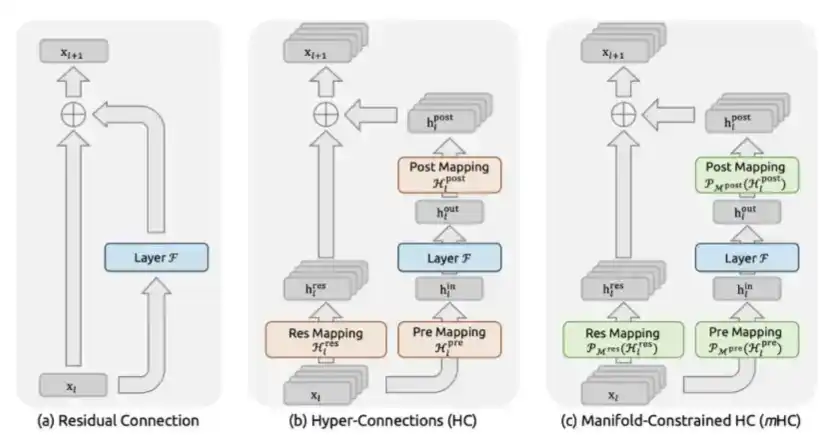
mHC is a complex architectural design, but it enables more stable training and higher intelligence per parameter.
4. CSA, HSA: Introduced by DeepSeek in V4 in April 2026.
The goal of CSA and HSA is to further reduce KV Cache requirements by another 90% by compressing KV tokens, while also significantly reducing required FLOPs, thereby alleviating pressure on both HBM and GPU/ASIC.
5. Engram: Introduced by DeepSeek in Q1 2026, essentially trading memory—LPDDR memory—for computational efficiency to some extent.
As shown in the detailed chart below, Engram provides noticeable performance improvement under the same total parameter budget.
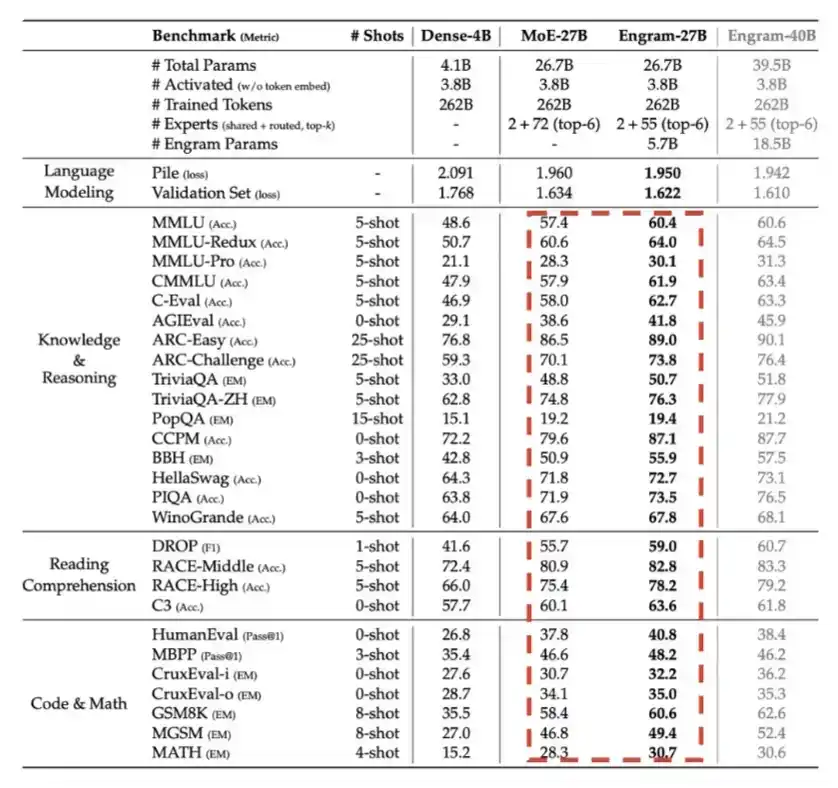
6. Engram: Introduced by DeepSeek in Q1 2026, essentially trading memory—LPDDR memory—for computational efficiency to some extent.
As shown in the detailed chart below, Engram provides noticeable performance improvement under the same total parameter budget.

This is DeepSeek's recommendation shared with hardware vendors in the V4 paper. I'm sure in private discussions, their feedback would be even more extensive.
7. Investment in TileLang also points in the same direction: DeepSeek isn't just solving its own compute bottlenecks; it's enabling the Chinese hardware ecosystem to compete with the Western one.
With TileLang, developers can write a kernel—the low-level computational code—once and have it run successfully on multiple hardware platforms, provided those platforms have corresponding TileLang backends.
I expect other Chinese AI labs will join in gradually. This will help Chinese hardware vendors indirectly counter the so-called "CUDA moat." At the same time, it will also unlock the potential of more Western hardware, like AMD.
It should be noted that several Chinese AI hardware platforms already offer CUDA compatibility or CUDA translation layers. For example, Moore Threads, MetaX, Biren, and Tianshu Zhixin are Chinese chip vendors that achieve high CUDA compatibility through translation layers. So theoretically, they might not necessarily need TileLang.

Large-scale reinforcement learning and RSI
As DeepSeek gains access to more compute sources—more hardware options—and the models themselves require less computational resources, it will be able to pursue more ambitious training projects, especially reinforcement learning post-training.
Reinforcement learning requires generating a massive number of trajectories—trillions of tokens. This quickly becomes extremely expensive. Going further, training models with 1 million context length requires generating trajectories of the same length. Only training on such ultra-long trajectories can truly support long-horizon tasks.
Additionally, with more hardware options, DeepSeek will have access to more hardware resources, which will drive automated research, or RSI. RSI refers to AI designing and executing experiments itself. This involves a lot of trial and error, and costs escalate quickly. But RSI is crucial for exploring the full model design space. Before moving towards AGI, and subsequently ASI, DeepSeek must possess RSI capabilities.
What DeepSeek does today, the entire industry will follow tomorrow
DeepSeek's innovations around MoE, MLA, DSA, etc., have already been adopted by other AI labs globally and in China.
For example, ZAI, the developer of the GLM series, uses MLA and DSA. Kimi (Moonshot) also uses MLA and openly states its architecture is based on DeepSeek's design. Conversely, DeepSeek uses the Muon optimizer, which was first used at scale by Kimi (Moonshot) in large-scale training.
It should be noted:
MoE was first proposed by Google in 2017, key author Noam Shazeer. DeepSeek's contribution lies in applying MoE at scale and inventing its own accompanying techniques.
Muon, the MomentUm Orthogonalized by Newton-Schulz optimizer, was proposed by ML researcher Keller Jordan in late 2024. The Kimi (Moonshot) team was the first to use it for large-scale training.
What about the money-making issue?
We can look at the interesting example of OpenAI.
OpenAI received warrants/options to purchase AMD and Cerebras stock at a low price, tied to its compute consumption milestones. For AMD and Cerebras, this was a very good deal. Because once OpenAI commits to using their hardware, their long-term success probability increases significantly.
Here's a passage from AMD's announcement:
"As part of the agreement, to further align strategic interests, AMD issued to OpenAI warrants to purchase up to 160 million shares of AMD common stock, vesting based on the achievement of specific milestones. The first tranche vests upon completion of the initial 1 GW deployment, with subsequent tranches vesting as purchases scale to 6 GW. Vesting is also contingent on AMD achieving certain stock price targets and OpenAI reaching technical and commercial milestones required for AMD's large-scale deployment."

I expect DeepSeek will also enter into similar agreements with multiple Chinese memory, ASIC, CPU, and networking stack vendors, collaborating deeply to make these vendors' hardware stacks capable of handling leading AI workloads.
Considering the total market capitalization of AI stocks in the West, including East Asian allies, far exceeds $10 trillion, this "gain equity returns through cooperation" approach will give DeepSeek the opportunity to help China build an equally massive industry and claim its share of the pie, ultimately achieving its own $1 trillion valuation.
This would not only earn DeepSeek far more money than traditional application subscription businesses but also fulfill its stated goal of "making AGI beneficial to everyone." Liang Wenfeng is a big fan of Jim Simons and a savvy enough capital player; he couldn't miss this.
If you look back at everything DeepSeek has done so far, this is the only explanation that makes the most sense.
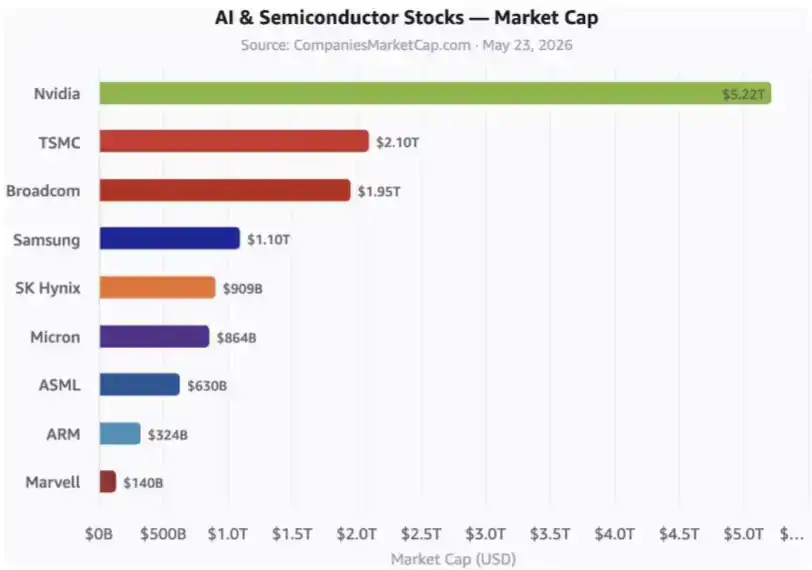
These are key AI stocks. The chart doesn't yet include hyperscalers and many other related companies.
Original Article Link







