文 | 字母AI
五一假期前一天,DeepSeek突然扔出来一份视觉多模态技术报告。
点开之前,我心里大概是有个预期的,无非就是具体能看到多远、看得多清楚。
毕竟过去一年,多模态模型基本都在往这个方向卷。OpenAI讲thinking with images,让模型在推理过程中裁剪、放大、旋转图片;Gemini、Claude也都在想办法让模型处理更高分辨率、更复杂的视觉输入。
大家的共同假设是,只要模型看得更细,视觉推理自然就会更强。
但DeepSeek这份报告看下来,你会发现,他们完全走上了另一条路。
DeepSeek没有把重点放在“让模型看到更多像素”上,他们把注意力放在了一个更底层的问题上。
就算模型已经看清楚了,但是它在推理过程中,你怎么能保证模型和你指的是同一个东西?
其实这是多模态推理里最容易被忽略的死穴。
人类看图时,可以用手指去标记对象。比如“这个人是谁谁谁”、“那个人是谁谁谁”。但模型哪知道你说的这个是哪个?
模型只能用语言说“左边那个”“上面那个”“这条线”。一旦画面复杂起来,语言指代就会漂移,推理也会跟着崩。
于是DeepSeek就说了,那就给模型一根“手指”不就完了?
它把点和边界框变成模型思考时的基本单位,让模型能够一边用这根赛博手指指着对象,一边进行推理。
01 从连续视觉到离散符号
DeepSeek在这份技术报告里,提出了一个很有意思的问题。他们认为,多模态模型真正难的地方,不是看见图像,而是在连续推理过程中稳定地指向同一个视觉对象。
就比如你跟你的朋友说“菜市场里,张老太太的那个摊位卖的菜最新鲜”。但是菜市场里老头老太太多了去了,哪个是张老太太?
但如果你直接用手指着说“就是那个”,你朋友就会马上明白。
DeepSeek将这个问题命名为“引用鸿沟”(Reference Gap)。
过去一年,几乎所有前沿多模态模型都在解决“感知鸿沟”(Perception Gap)这个问题。
假如说有一张照片放在你面前,如果照片太模糊、分辨率太低,你可能看不清楚里面的小字或者远处的细节。AI也一样,如果输入的图像质量不够、处理方式不对,它就会“看不清”,这就是感知鸿沟。
GPT、Claude、Gemini这些模型不断提高分辨率,引入高分辨率裁剪、动态分块、多尺度处理,目的就是让模型能看到更多细节。
这个方向当然有价值,但DeepSeek在报告里指出,就算模型看得再清楚,在复杂的空间推理任务上,仍然会出现逻辑崩溃。
问题出在自然语言本身。
照片里有十几只狗,你说“左边那只狗”,那模型就没办法理解你说的具体是哪只。
还有更绝的,如果你让模型数一下照片里狗的数量,那么模型在推理过程中很容易就搞不清楚自己已经数过哪些、还有哪些没数。
报告中还提到了迷宫导航这样极端的情况,纯语言根本无法准确描述不规则形状的路径和复杂的拓扑关系。
语言作为一种指代工具,在连续的视觉空间里天生就是模糊的。它擅长抽象概念和因果关系,但在空间定位和拓扑关系上,语言的表达能力存在根本性的局限。
可DeepSeek本身就是个通用的语言模型,那应该怎样解决呢?
于是就有了文章开头提到的这根“手指”。
他们提出的核心概念是“视觉基元”(Visual Primitives),具体来说就是把边界框(bounding boxes)和点(points)这两种计算机视觉里最基础的空间标记,提升为“思维的最小单位”。
以前的多模态模型虽然也能画框标注物体,但只是在最后给你看个结果,证明“我找到了”。就像考试时,你只交答案,不写解题过程。
也有一些研究让AI在思考过程中画框,但目的只是为了“看得更准”,框框只是个辅助工具。就好比你做数学题时用草稿纸,草稿纸只是帮你算得更清楚,不是解题思路的一部分。
DeepSeek要做的完全不同。
他们把这些空间标记直接嵌入到模型的推理过程中,让它们成为推理的有机组成部分。模型在思考的时候,不只是用语言描述“我看到了一只狗”,还同时输出“我看到了一只狗,它在这里:[[x1,y1,x2,y2]]”。
这个机制被DeepSeek称为“边推理边指向”(point while it reasons)。
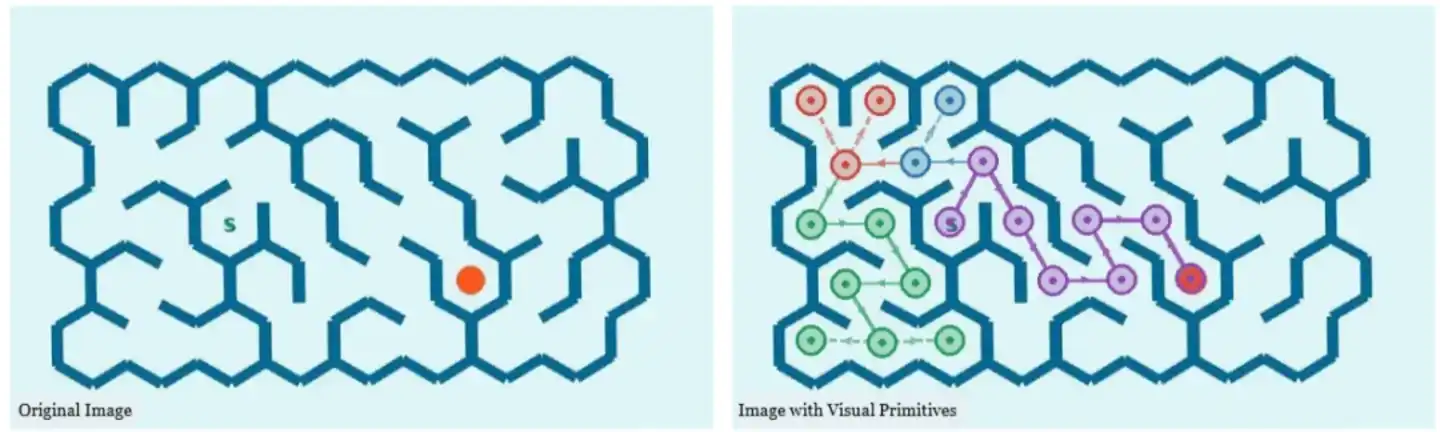
模型的每一步思考都锚定在图像的具体坐标上。
技术报告里就给了这样一个例子:模型从起点出发,一路探索、回溯、再尝试,最后输出了一串完整的坐标路径,每个坐标都对应迷宫里走过的一个点。
这样一来,模型就不会在推理过程中“迷路”。它不会搞不清楚自己在说什么、指什么。每个视觉对象都有了明确的空间锚点,推理过程变得可追踪、可验证。
这条技术路线和OpenAI的方向形成了有趣的对比。
OpenAI在o3和o4-mini的官方介绍里明确提到了“thinking with images”的概念,即模型可以把图像纳入推理链,并通过裁剪、放大、旋转等方式处理图像。这个方向的重点是让图像本身成为思维链的一部分,模型可以在推理过程中生成新的图像、修改图像、对图像进行操作。
OpenAI的路线强调的是通用能力,视觉、代码、搜索、文件、工具调用一起协作。模型拥有一个强大的“视觉工作台”,可以灵活地处理各种视觉任务。
DeepSeek的路线则更“符号化”一点。它让坐标进入思维链。模型在推理文本里显式写出边界框和点的坐标,把视觉对象变成推理时可复用的锚点。
这就导致,OpenAI的视觉推理发生在内部,用户只能看到最终答案和必要解释,中间的视觉处理过程是黑箱。DeepSeek则故意把中间视觉锚点显式化,让推理过程完全透明。
DeepSeek这样做,好处是推理过程更容易被训练、检查和打分。这也让它更容易设计格式、质量和任务级奖励。尤其在迷宫、路径追踪这类任务中,可以对路径合法性、轨迹覆盖度等给出更细的反馈。
模型不只是学会输出正确答案,更是学会了用视觉基元进行推理的方法。
02 效率才是核心
DeepSeek这份报告里有一个很容易被忽略但极其重要的细节,他们的模型在处理图像时,用的token数量远远少于其他前沿模型。
报告里有一张对比图,展示了不同模型处理一张800×800分辨率图像时消耗的token数量。
Gemini-3-Flash约1100个,Claude-Sonnet-4.6约870个,GPT-5.4约740个,Qwen3-VL约660个,DeepSeek约361个,并在KV缓存里只保留约90个条目。
这个差距不是一点点。DeepSeek用的token数量只有Gemini的3分之1,KV缓存条目更是只有10分之1左右。
这种极致的效率是怎么实现的?
DeepSeek用了一个叫“压缩稀疏注意力”(Compressed Sparse Attention, CSA)的机制。
你可以这样理解,假如说你给朋友看一张全家福,你不会说“从左数第237个像素开始有一块红色区域……”,你会直接说“左边是我妈,右边是我爸”。
DeepSeek-ViT先把图像压成更少的视觉token,CSA再把这些视觉token在KV缓存中的表示进一步压缩。
这个机制在DeepSeek-V4-Flash模型上就使用过,现在被应用到了视觉多模态之中。
具体的压缩流程是这样的。一张756×756的图像,包含571536个像素。这些像素首先经过ViT处理,以14×14的patch size切分,生成2916个patch token。然后进行3×3的空间压缩,把每9个相邻的token沿着通道维度压缩成1个,变成324个视觉token。
这324个token进入大语言模型进行预填充。最后,CSA机制会把这些视觉token在KV缓存里再压缩4倍,最终只保留81个条目。
从571536个像素到81个KV缓存条目,整个压缩比达到了7056倍。
一般AI大厂都是在用暴力方法去堆计算资源,而DeepSeek则是在信息论层面去做取舍,只留下最直观易懂的信息。
其最直接的结果,就是推理速度变快了许多。
图像token数量直接影响模型的推理延迟。在自回归生成过程中,每生成一个新token,模型都需要对之前所有token的KV缓存进行注意力计算。如果图像占用了1000个token,那么每次生成都要对这1000个token做注意力。如果只占用90个,计算量就大幅减少。
对于需要实时响应的应用场景,比如机器人视觉、自动驾驶、实时视频分析,推理速度的提升起到了决定性作用。
然后它内存占用得也少。
KV缓存是大模型推理的内存瓶颈。特别是在处理长上下文或批量推理的时候,KV缓存会占用大量显存。DeepSeek把视觉token的KV缓存压缩到90个条目,意味着可以在同样的硬件上处理更多图像,或者处理更长的多轮对话。
这对于实际部署非常重要。很多公司的多模态模型在实验室里表现很好,但一到实际部署就遇到成本问题。每张图片消耗的token越多,推理成本就越高,可支持的并发用户就越少。DeepSeek的效率优势在规模化部署时会被放大。
同时也变相提高了模型的上下文容量。
如果一张图片要占用1000个token,那么在一个128k的上下文窗口里,只能放100多张图片。如果只占用300个token,就可以放400多张。这对于需要处理多图对话、长视频分析、大量文档理解的场景至关重要。
DeepSeek的模型可以在一个对话里处理更多图像,可以对比分析几十张甚至上百张图片,可以追踪视频里的长期变化。
最关键的是训练成本。
虽然报告主要讲推理效率,但这种压缩机制在训练阶段同样有效。更少的视觉token意味着更小的计算图,更快的训练速度,更低的硬件要求。
DeepSeek一直以“用更少资源做出更好效果”著称。从R1的强化学习训练,到V4的MoE架构,再到现在的视觉多模态,这种效率优先的哲学贯穿始终。
但这里有一个关键问题。压缩会不会损失信息?
DeepSeek并没有否认压缩会带来信息损失。它的主张是,在这组空间推理和计数任务上,压缩后的表征仍然足够有效。
每一步压缩都在保留对推理最重要的信息,丢弃冗余和噪声。
其实前面提到的DeepSeek的视觉基元机制,它本身也是一种信息压缩。一个边界框用4个数字就能精确定位一个物体,一个点用2个数字就能标记一个位置。这些离散符号携带的信息密度远高于原始像素。
从实验结果看,这种压缩没有损害性能,反而在某些任务上带来了提升。
这说明对于很多视觉推理任务,瓶颈不在于看得不够清楚,而在于没有找到合适的表征方式。
这种效率优势还证明了多模态智能不一定需要更大的模型、更多的算力、更高的成本。
从DeepSeek时刻诞生至今,这家公司一直有一条暗线,“真正的智能不在于算力,而在于对问题本质的理解”。
当你真正理解了视觉推理需要什么,你就不需要那么多token。当你找到了合适的表征方式,你就不需要那么大的模型。
从这个角度看,DeepSeek的极致效率不是目的,而是副产品。真正的目的是找到视觉推理的正确范式。效率只是证明了这个范式是对的。
03 未竟之事
DeepSeek在报告的局限性部分,坦诚地列出了当前方法存在的几个问题。这些问题不是技术细节上的小瑕疵,而是指向了视觉推理的下一个阶段。
第一个问题是触发词依赖。
报告里明确说,当前的“用视觉基元思考”能力需要显式的触发词(explicit trigger words)才能激活。也就是说,模型还不能自然、自主地决定“什么时候该画框、打点”。
它意味着模型还没有真正学会判断什么时候需要使用视觉基元,什么时候用语言就够了。
理想的情况是,模型应该能根据任务的性质自主决策。但当用户问“数一数图里有几只狗”的时候,模型应该自动切换到视觉基元模式,用边界框来辅助计数。
从技术上说,这需要在模型里建立一个元认知层。这个元认知层可以评估当前任务的复杂度,判断纯语言推理是否足够,决定是否需要调用视觉基元。
DeepSeek目前还没有实现这个元认知层,但他们已经明确了方向。未来的版本可能会让模型学会自主决定推理策略,而不是依赖外部触发。
第二个问题是分辨率限制。
报告提到,受输入分辨率限制,模型在细粒度场景下的表现还不够好,输出的视觉基元有时不够精确。
这个问题和DeepSeek的效率优先策略有关。为了控制token数量,他们限制了视觉token的范围在81到384之间。对于超出这个范围的图像,会进行缩放处理。
这种设计在大部分场景下是合理的,但在一些需要极高精度的任务上就会遇到瓶颈。比如医疗影像分析需要识别微小的病灶,工业质检需要发现细微的瑕疵,这些场景对分辨率的要求很高。
DeepSeek在报告里提到,这个问题可以通过整合现有的高分辨率方法来解决。也就是说,他们的视觉基元框架和传统的高分辨率裁剪方法不是对立的,而是互补的。
我觉得DeepSeek可以出个混合方案。
具体就是对于大部分常规任务,使用压缩的视觉表征和视觉基元推理,保持高效率。对于需要细粒度分析的局部区域,动态调用高分辨率裁剪,提取更详细的视觉信息。这样既保持了整体效率,又满足了局部精度需求。
这种混合方案的关键是让模型学会判断哪些区域需要高分辨率处理。于是这就又回到了刚才元认知的问题上。
第三个问题是跨场景泛化。
报告提到,用点作为视觉基元来解决复杂拓扑推理问题仍然很难,模型的跨场景泛化能力有限。
这个问题在迷宫导航和路径追踪任务上表现得比较明显。虽然DeepSeek在自己构建的测试集上达到了66.9%和56.7%的准确率,超过了其他模型,但这个数字本身还不够。
更重要的是,这些任务都是在合成数据上训练和测试的。迷宫是用算法生成的,路径追踪的曲线也是程序化绘制的。当模型遇到真实世界里的拓扑推理问题时,比如在真实地图上规划路径,在复杂管线图里追踪连接关系,表现可能会下降。
DeepSeek的方法是通过大规模、高多样性的数据来提升泛化能力。他们爬取了97984个数据源,经过严格过滤后保留了31701个,最终得到超过4000万个样本。在迷宫和路径追踪任务上,他们也设计了多种拓扑结构、视觉风格、难度等级,试图覆盖尽可能多的变化。
然而数据多样性只是泛化能力的一部分。模型是否真正理解了拓扑推理的本质?还是说它只是记住了训练数据里的模式而已?
另外,DeepSeek的视觉基元是一套新的表征系统,需要专门的数据格式、训练流程、评估方法。这和现有的多模态生态不完全兼容。
大部分多模态数据集和评测基准都是基于传统的“图像+文本”范式设计的,没有考虑视觉基元。如果要在这些基准上评测DeepSeek的模型,要么需要关闭视觉基元功能,要么需要重新设计评测方法。
其他研究者如果想复现或改进这个工作,需要重新构建整个数据和训练流程,门槛比较高。
DeepSeek能在报告中谈及这些问题,说明他们对自己的工作有清醒的认识。
这可能比给出完美答案更有价值。因为真正推动社会进步的,往往不是答案,而是问题。






