Automated research has truly stepped out of the code sandbox and into the real physical world.
Recently, Jim Fan, lead of NVIDIA's GEAR lab, introduced a new project called ENPIRE. This marks their first implementation of automated research on robot hardware.
They placed 8 Codex Agents into a robot fleet, allocated GPU computing power and ample token budgets, and gave a simple goal: solve the task as quickly as possible, keep the robots busy but safe, and avoid wasting computing power.
After that, human intervention was largely withdrawn. The Agents autonomously drove the entire closed loop, including automatic scene resetting, literature review, idea implementation and infrastructure setup, policy training and deployment, self-verification, log analysis and code improvement, iterating continuously until high-precision dexterous tasks were reliably completed on real hardware, such as fastening cable ties, organizing pins into a box, installing GPUs, etc.
They also observed a "physical scaling law": increasing the number of parallel robots (e.g., from a few to 8) significantly sped up task resolution.
Currently, part of the lab's systems can perform self-iteration overnight without human intervention, with researchers only needing to check reports in the morning.
Jim Fan stated that the future goal is to allow team members to go on vacation with peace of mind, with even NVIDIA CEO Jensen Huang unaware that the lab is still running autonomously.
The ENPIRE project plans to be fully open-sourced, potentially enabling regular developers to set up similar autonomous robot research systems at home.

Project address: https://research.nvidia.com/labs/gear/enpire/
ENPIRE System Architecture: Four Modules Forming a Closed Loop
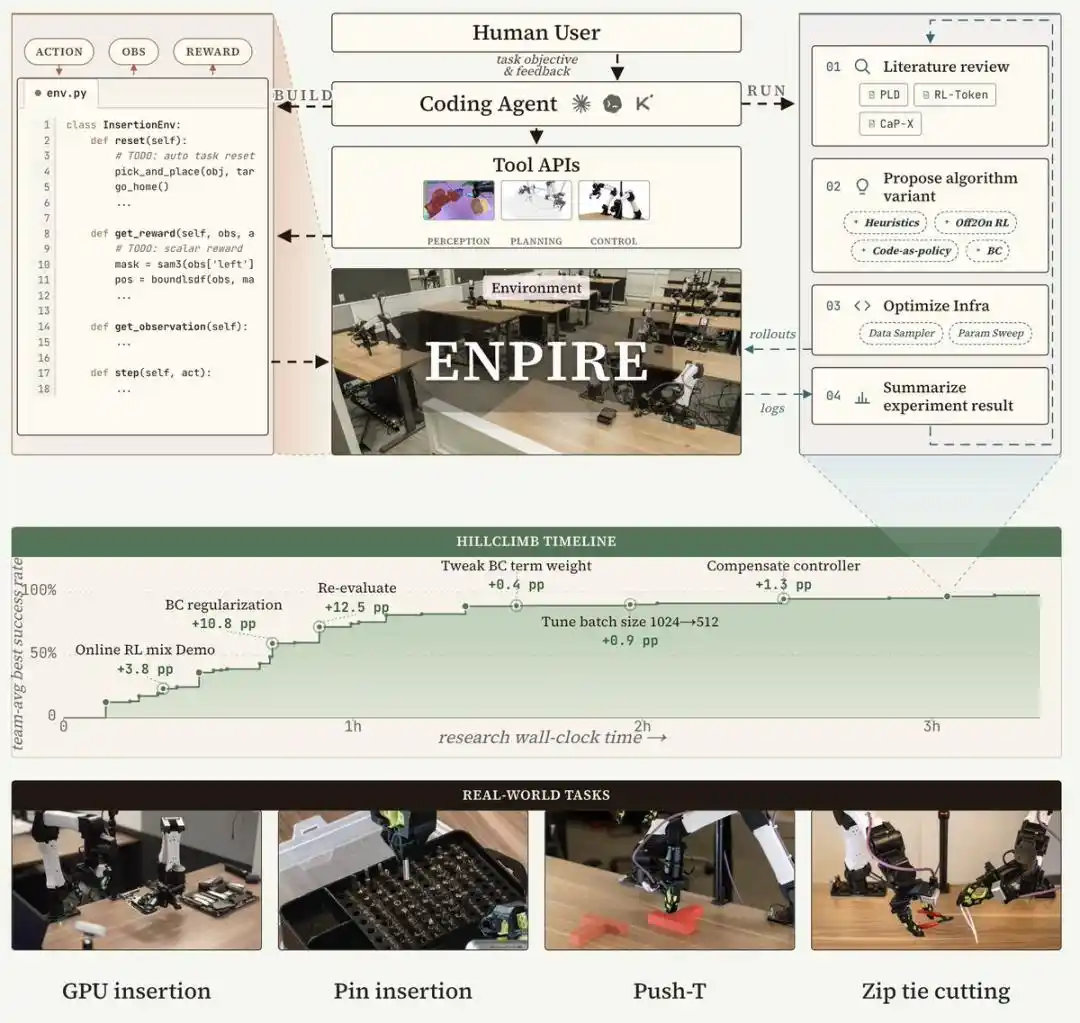
ENPIRE is a framework system designed for coding Agents, constructing a repeatable physical feedback loop through four core modules: the Environment module (EN) handles automatic resetting and verification; the Policy Improvement module (PI) initiates policy optimization; the Rollout module (R) supports policy evaluation on single or multiple robots in parallel; and the Evolution module (E) enables coding Agents to analyze logs, review literature, and improve training infrastructure and algorithm code to address failure modes.
This closed-loop system transforms real-world robot learning into an Agent-managed, controllable optimization process, thereby minimizing manual input while supporting fair ablation experiments across different training recipes and Agent variants.
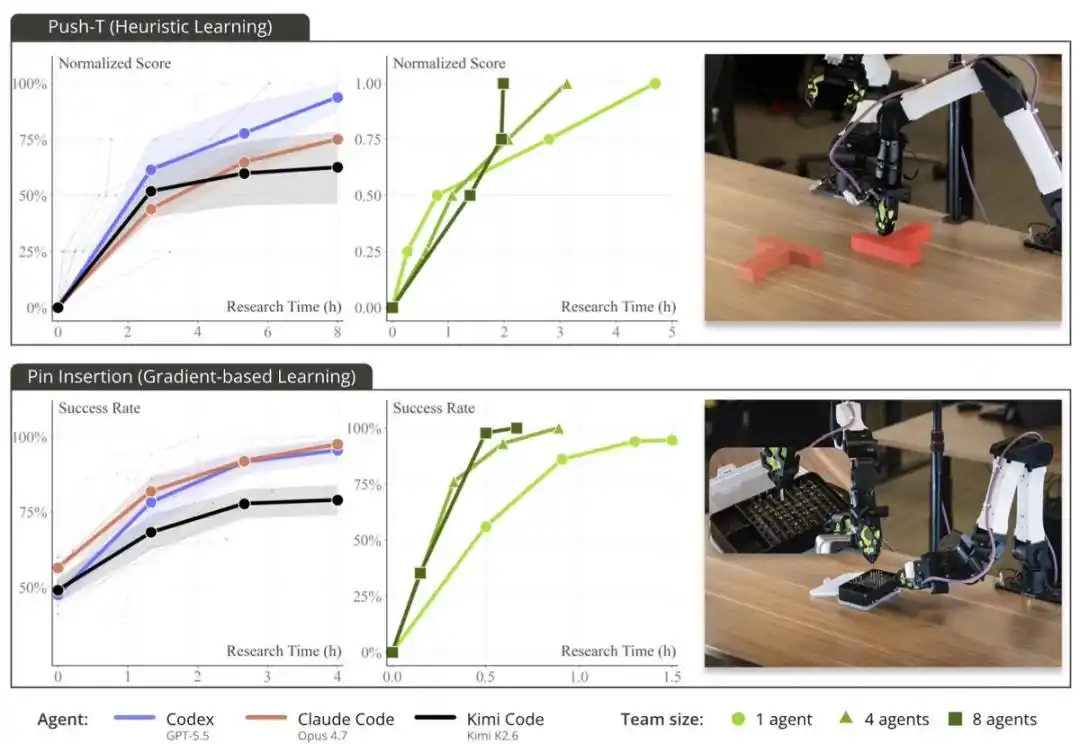
Supported by ENPIRE, cutting-edge programming Agents can autonomously develop policies and achieve a 99% success rate on challenging real-world dexterous manipulation tasks like PushT, organizing pins into a pin box, and cutting cable ties with a cutter.
Key Finding: Resetting the Environment is Often Easier Than Completing the Task Itself
One key observation is: For many robot tasks, resetting the environment is often easier than completing the task itself.
Therefore, ENPIRE's approach is to first let the Agent build an automatic resetting environment via Code-as-Policy. Often, the so-called reset is essentially a pick-and-place task, solvable by Cap-X.
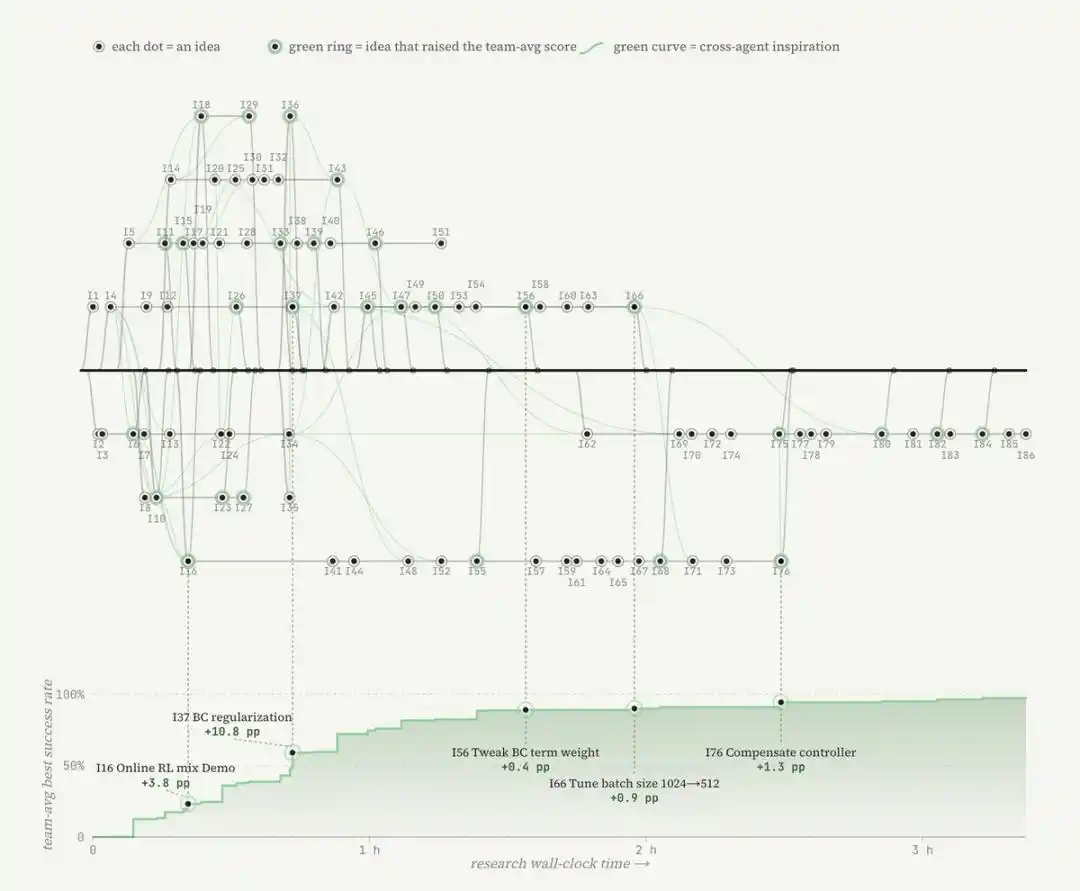
Subsequently, the agent writes a heuristic rule-based reward function. The research team then places this environment into a sandbox and initiates automated research by the Agent centered around scoring.
This also echoes Karpathy's definition of automated research: automated research here is not simply tuning a hyperparameter or modifying a small piece of code. The Agent explores different paradigms from the internet and rewrites anything that could potentially boost performance, including algorithms, training objectives, and even the data loader.
In the pin task, one Agent even wrote its own contact force safety controller, which proved more effective than merely adjusting several reinforcement learning parameters.
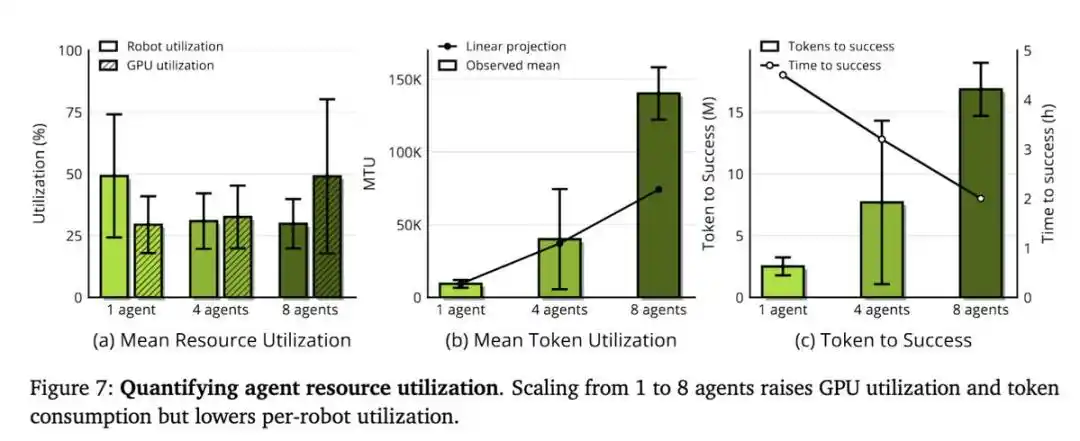
New Metrics MRU and MTU
ENPIRE's scalability depends on the size of the Agent team and computing resources, but here, the truly scarce resource is not GPUs, but robot time.
When the research team provided Agents with 8 robots instead of 1, the time needed for the pin task to achieve near-perfect performance was reduced from over 1.5 hours to about 40 minutes. These Agents coordinate via Git: sharing code, discarding suboptimal ideas, and autonomously selecting each other's best-performing runs.
This points to a larger shift: robotics research is becoming a work of environment design—building environments where coding Agents can conduct automated research; algorithmic work is shifting to a higher layer, towards constructing feedback loops that Agents can autonomously close.
And this loop compounds continuously: a skill mastered by an Agent today becomes the building block for constructing and resetting environments for more difficult tasks tomorrow. Capabilities bootstrap new capabilities.
Under this paradigm, the true hard constraint is the budget for real-world interaction.
Therefore, the research team proposed two metrics:
- Mean Robot Utilization (MRU): The proportion of time robots are actually running experiments relative to total elapsed real-world time.
- Mean Token Utilization (MTU): Measures the efficiency of Agents in converting tokens into research progress.
In their experiments, MRU consistently remained below 50%. That means the robots were idle half the time, waiting for the Agents to think. Therefore, a better harness and faster models directly translate into tangible benefits.
PushT is a long-standing robot manipulation benchmark. Typically, completing this task requires extensive human demonstration data plus hours of behavior cloning training.
However, they observed that Codex, Claude Code, and Kimi Code all "solved" this task in under 2 hours using a rule-based heuristic approach: without neural networks, without training, and without relying on any human data.
To enable more people to experiment with automated research in the physical world at home, they developed a full-stack system based on the @LeRobotHF SO-101 kit + NVIDIA Jetson Thor. This system can perform the PushT task.
Reference Links:
https://x.com/_wenlixiao/status/2066913334994358342
https://x.com/DrJimFan/status/2066921736369766762
This article is from the WeChat public account "Machine Heart" (ID: almosthuman2014), author: Yang Wen





