Editor's Note: This report, based on approximately 400,000 Claude Code sessions, explores how AI coding tools are reshaping the relationship between people and code.
The core finding of the article is: In agentic programming, humans primarily decide "what to do," while Claude primarily handles "how to do it." Users take on most of the planning decisions, while Claude assumes the bulk of the execution work. This means AI is taking over implementation steps such as writing code, modifying files, running commands, and debugging, but goal setting and outcome evaluation still rely on humans.
More importantly, the effectiveness of using Claude Code doesn't depend solely on whether the user is a programmer. The report shows that in code generation tasks, the success rates of users in non-technical professions like law, finance, management, and research have already approached those of software engineers. What truly influences the outcome is whether the user understands the problem they need to solve.
This indicates that AI programming lowers the barrier to implementation, not the barrier to judgment. In the future, those who understand the business, the context, and can clearly articulate requirements and evaluate results might be better equipped to leverage AI than those who only know how to write code. AI won't automatically replace domain knowledge; instead, it will amplify its value.
Here is the original text:
Key Findings
Building upon existing research, we propose a framework for studying interactive agentic programming. This framework is based on a privacy-preserving analysis of approximately 400,000 Claude Code sessions from October 2025 to April 2026, assessing task composition, human-AI collaboration patterns, and task success rates.
In a typical session, humans are responsible for most planning decisions, i.e., deciding "what to do"; Claude is responsible for most execution decisions, i.e., deciding "how to accomplish it." The stronger a user's expertise in a specific domain, the more work Claude completes per instruction. In coding tasks, the average success rates across major occupational groups—measured as completing what the user originally intended, with verifiable evidence like passing tests, committing code—are nearly on par with those of software engineers.
The stronger a user's domain expertise, the more likely a session is to end successfully. However, the gap between intermediate and expert users is not large. Over the seven months we observed, the proportion of sessions used for debugging has almost halved, with usage shifting towards more end-to-end agentic applications: deploying and running code, analyzing data, and writing non-code documentation.
During these seven months, the estimated value of typical tasks has increased across almost all work types. By comparing with freelance job posting information, we estimate the average increase in task value to be around 25%.
Introduction
Agentic programming is rapidly emerging. Since late 2025, the proportion of GitHub projects showing activity from coding agents has more than doubled, and Claude Code users now average 20 hours of use per week. Can people without formal programming experience successfully direct an agent to complete complex technical work? How will the rapid adoption and capability enhancement of these tools affect knowledge work more broadly? We don't yet have complete answers, but we can see early signals from Claude Code usage data.
This report, based on a privacy-preserving analysis of approximately 400,000 interactive sessions from about 235,000 users between October 2025 and April 2026, provides evidence of how Claude Code is actually being used. It builds on our previous research on autonomy metrics in Claude Code sessions and how Claude Code is changing work within Anthropic. This article proposes a framework for describing the use of interactive AI coding assistants: what work people are doing, who is doing it, and whether the work is successful. We focus on user interactions via the command-line interface (CLI), Claude.ai, or the Claude Code desktop application. By tracking how agentic programming usage changes as model capabilities improve, we can better understand the impact of these tools on both programming professionals and the broader knowledge worker labor market.
What happens in Claude Code may foreshadow the future of knowledge work: agents will gradually become embedded in non-coding tasks. We find that Claude is handling more complex and valuable tasks. At the same time, a clear division of labor persists in agentic programming: humans decide what to build, and agents decide how to build it.
We also see evidence that it is domain expertise, not programming proficiency, that truly amplifies the effectiveness of the tool. Domain experts, in particular, are more likely to succeed and more likely to recover from errors and misunderstandings. However, the gap between experts and intermediate users is not large. This suggests that being proficient enough in a domain allows one to use such tools almost as effectively as a deep expert.
These findings allow us a preliminary observation of potential shifts in the labor market. In our data, success depends on whether a person understands the problem they are trying to solve, not on whether they have received programming training. If these patterns hold across the broader economy, it implies that while agentic programming tools may be absorbing some implementation-oriented work, they are simultaneously rewarding those who genuinely understand the problems inherent in their work. Coding agents are not replacing domain expertise. On the contrary, the more understanding a worker brings to an agent, the more high-quality work the agent can accomplish.
Division of Labor
What People Use Claude Code For
To understand how people use Claude Code, we categorize each session into one of nine work modes—the single activity that best describes the session's goal. Four modes directly involve writing or maintaining code: building something new, fixing something broken, testing code, and orchestrating other agents or automation pipelines. Another category involves operating software, including deploying, configuring, running pipelines, and monitoring systems. Two more modes focus on figuring out "what to do": understanding how an existing system works, and planning changes before making modifications. The final two modes are non-code related, or where code is only an auxiliary part of the final output: analyzing data, and communicating through presentations and other text-based documents.
Approximately 56% of sessions consist of writing code (25%), fixing code (26%), or testing and orchestrating code (5%). Operating software accounts for 17%, planning or exploration accounts for 14%, and analysis or writing text accounts for 13% (see Figure 1).
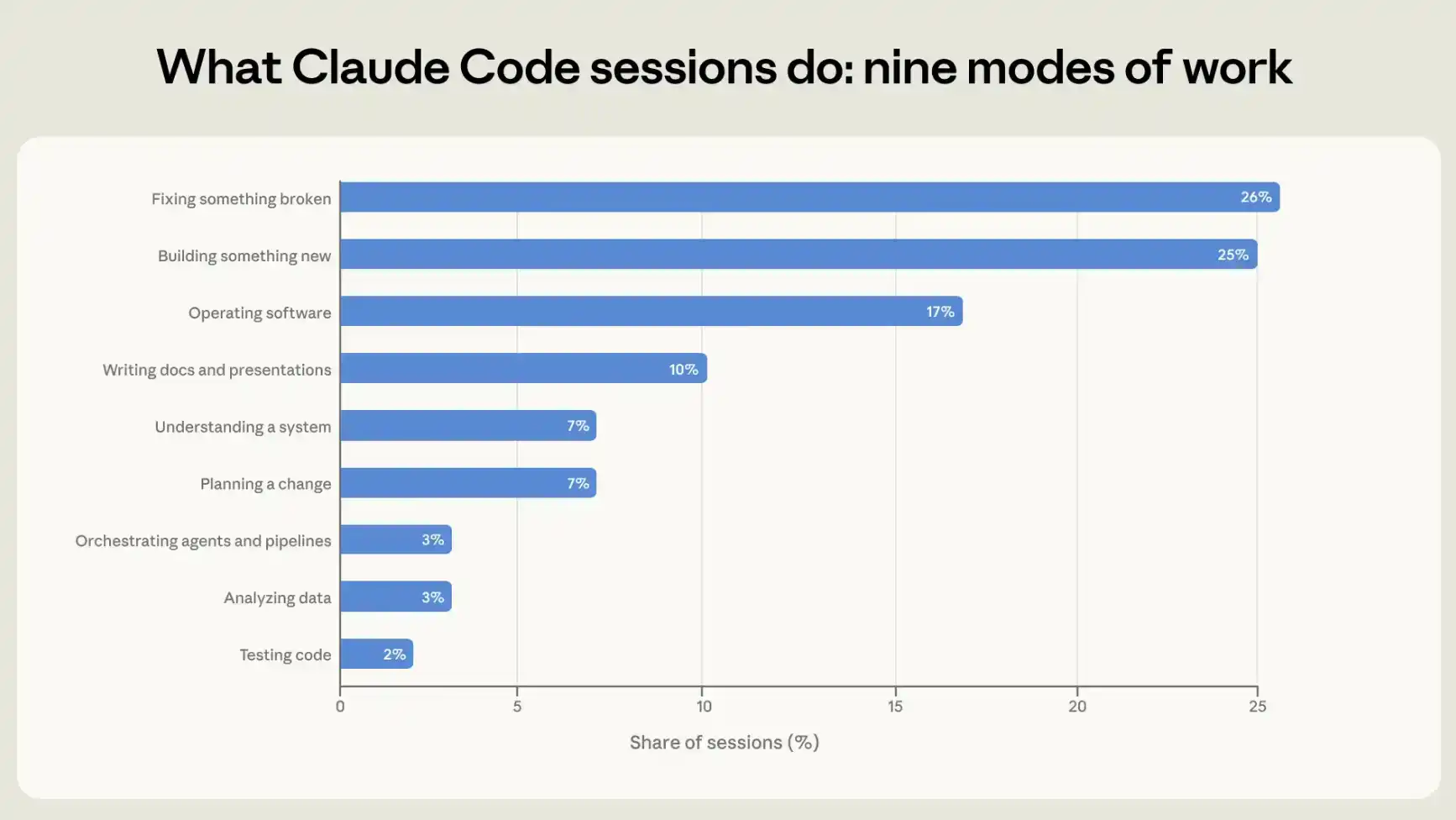
We first have the model read session transcripts to classify each session; we then cross-validate these classifications with automatically logged telemetry data for each session, including whether code lines were added or deleted. There is high consistency between the two sources. For example, over 90% of sessions classified by our classifier as creating or modifying code also show code changes in the telemetry data. See the appendix for details.
Who Makes the Decisions
How autonomous is Claude Code? Capability evaluations show the upper bound is already high and still rising. For example, in benchmarks like METR's Time Span Evaluation, frontier models can now autonomously complete software tasks that would take humans hours, overcoming obstacles along the way. But what happens in actual usage? Here, we focus on how much guidance is provided by humans versus Claude in real sessions.
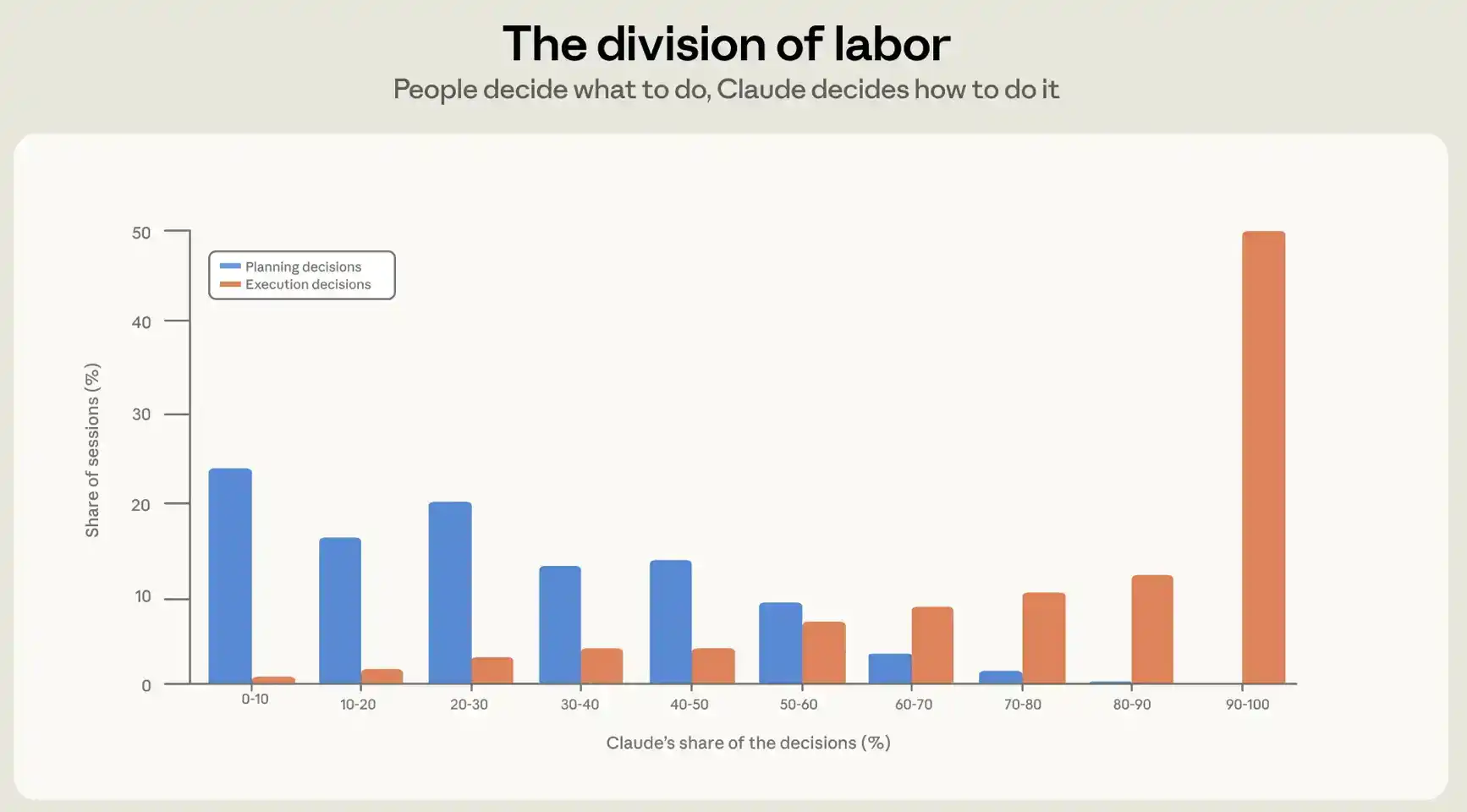
We examine this question from two angles. First, we look at how much people delegate decision-making to Claude; second, we observe how many actions they assign to Claude. To understand the division of decision-making in a session, we built a privacy-preserving decision attribution classifier based on session content. We ask the classifier to list all meaningful decisions in a session, categorizing them as planning decisions and execution decisions. Planning decisions include what to do, which approach to use, and what constitutes completion; execution decisions include which files to modify, what code to write, what language to use, and which commands to run. The classifier then attributes each decision to either Claude or the user, producing two numbers per session: the percentage of planning decisions attributed to the user, and the percentage of execution decisions attributed to the user.
On average, humans make about 70% of planning decisions but only about 20% of execution decisions (see Figure 2). In practice, agentic programming establishes a clear division of labor: humans decide what to build, agents decide how to build it.
To understand the extent of action delegation in a session, we look not at content but at session structure. A Claude Code session consists of back-and-forth interactions between Claude and the user: the user sends a prompt, Claude executes actions; then the user sends the next prompt, and so on. In a typical session, there are about four such rounds. In our historical data from October to April, each user prompt triggered Claude to perform about 10 actions on average, sometimes over 100. In each round, Claude reads files, edits code, runs commands, and outputs an average of 2,400 words.
How much work Claude completes between user check-ins depends largely on who is making the decisions. When users retain control over execution—meaning they make over 80% of execution decisions—Claude performs fewer actions per round, around 8. When Claude holds planning control—meaning it makes over 80% of planning decisions—it undertakes the highest number of actions, around 16.
Expertise Level
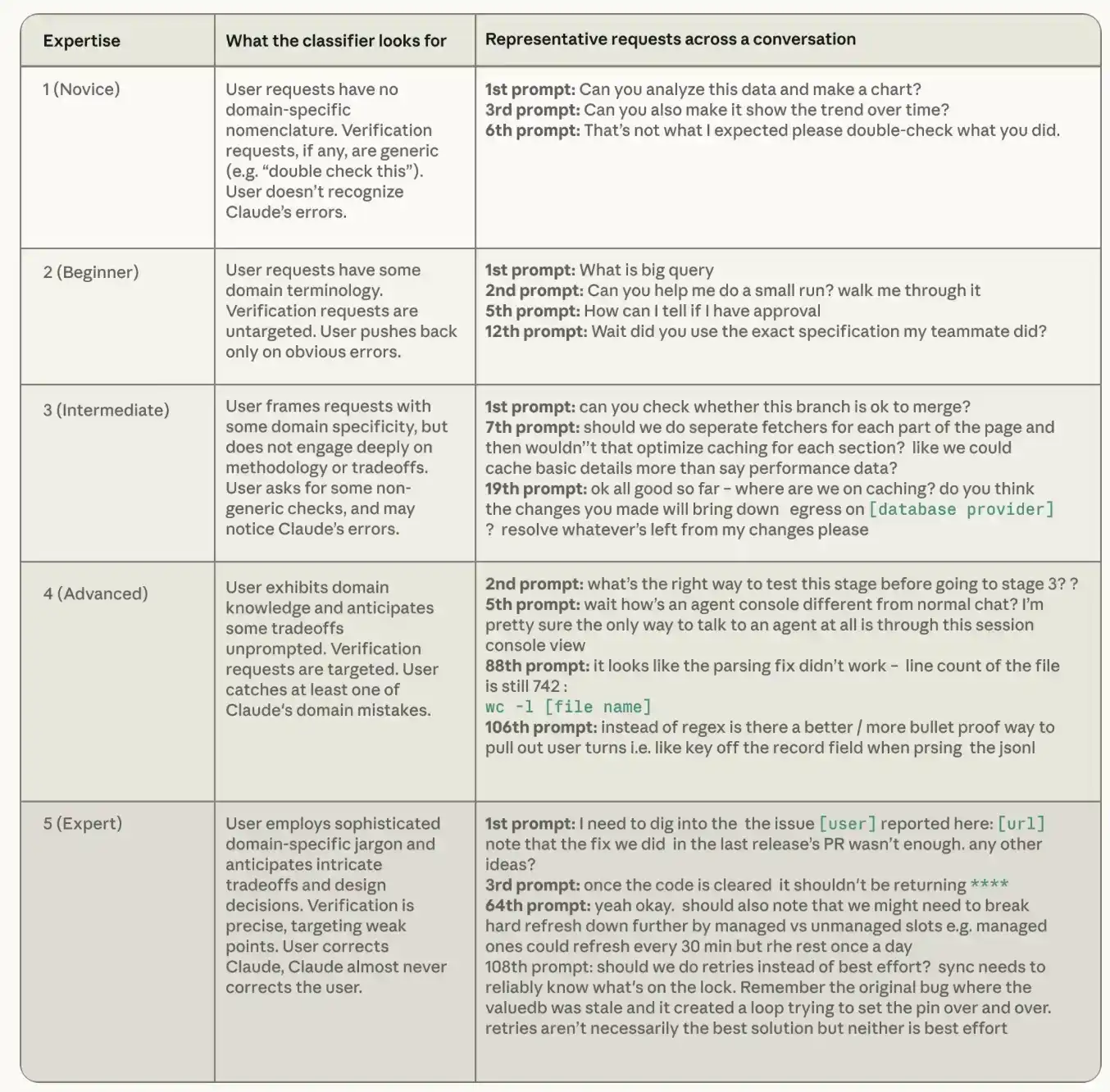
For each session transcript, Claude evaluates the user's apparent expertise level for that task on a five-point scale, from novice to expert. The expertise classifier focuses on three signals: the precision of the user's instructions, what the user asks Claude to verify, and whether the user corrects Claude more often or Claude corrects the user more often. It's important to note that this expertise level is a completely different concept from job title or general capability, and crucially, it is task-specific. A senior engineer asking about Rust for the first time could still be a novice on Rust tasks. An accountant who has never used Python, if they can precisely tell Claude what reconciliation rules a Python script must follow and can catch edge cases it mishandles during month-end closing, is an expert on that task.
The table below shows how we define each expertise level in the classifier, with example prompts from the public coding agent conversation dataset SWE-chat. Conversations categorized as "Novice" provide generic instructions without demonstrating specific domain knowledge; those categorized as "Expert" convey a deep understanding of the codebase and technical environment.
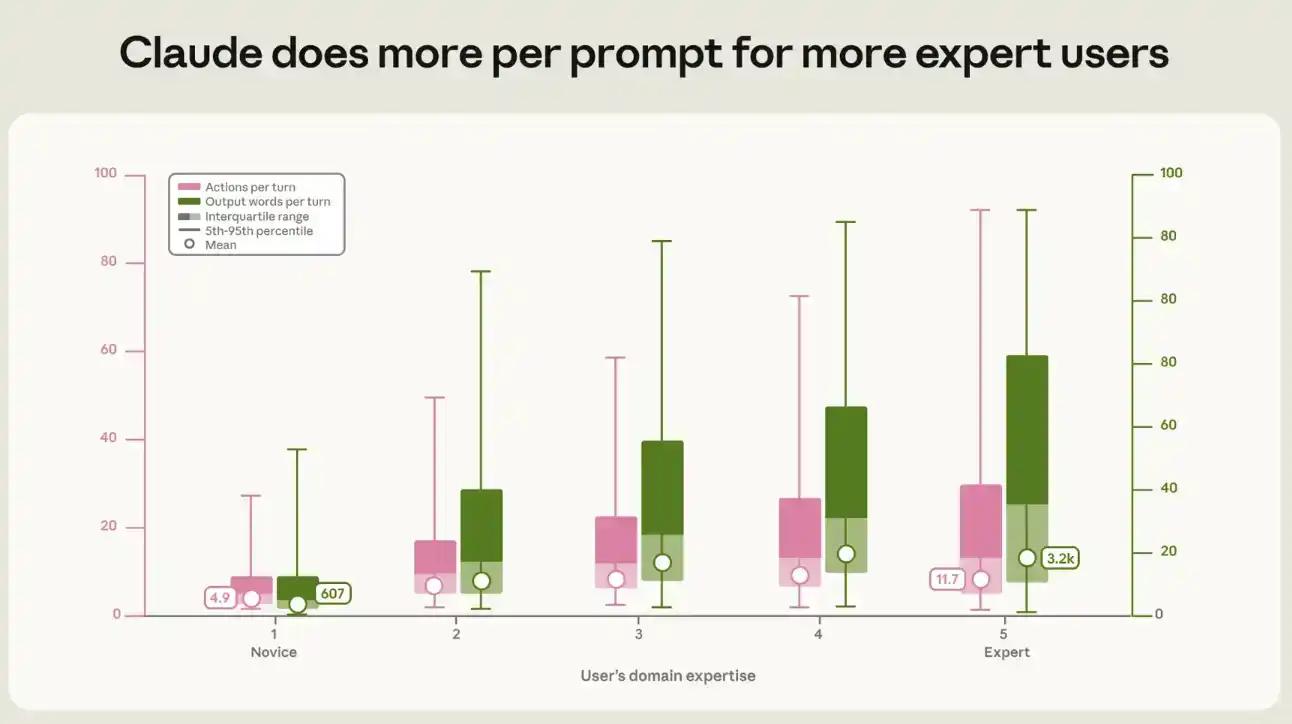
We quantified the relationship between expertise level and the volume of output and activity generated per Claude prompt. In a typical novice session, each prompt triggers Claude to perform about 5 actions and output about 600 words; in an expert session, the action chain length is more than double, about 12 actions, and output reaches about 3,200 words, five times higher (see Figure 3). This novice-expert gap appears across every work type and every task value bracket.
These metrics complement our previous research on Claude Code's autonomy. The earlier study tracked agent run duration and how frequently users auto-approved its actions. In contrast, our decision attribution metric captures who makes substantive decisions throughout the entire session, while output and actions per prompt measure the degree of autonomous activity Claude undertakes per human instruction.
Who Uses Claude Code, and What They Use It For
Users
To understand who is doing this work, we infer each user's occupation from session transcripts and map it to one of the 23 major groups in the US Bureau of Labor Statistics Standard Occupational Classification (SOC) system. The classifier is instructed to judge based only on signals such as: the project context loaded by the agent at session start, file names and structures, materials or artifacts referenced by the user (e.g., legal documents, clinical data, financial reports, course materials), and the user's vocabulary. The classifier is explicitly instructed not to treat "writing code" itself as evidence of a programming occupation. Sessions are only placed in coding-related SOC categories (i.e., "Computer and Mathematical Occupations") if there is a clear signal that software or data work is the user's profession. If a lawyer builds a script to automatically check a set of contracts for missing clauses, even though the session primarily involves writing software, it is still classified under the legal profession. If no signal about the user's occupation exists, the session remains unclassified.
We were able to infer an occupation in about 70% of sessions. Among these classifiable sessions, "Computer and Mathematical Occupations" is the largest group, unsurprisingly, as this category encompasses most software-related work. This is followed by Business and Financial Operations, Arts Design and Media, Management, and Life, Physical, and Social Sciences. The fastest-growing non-software occupational groups in our sample are Management, Sales, and Legal occupations.
Work
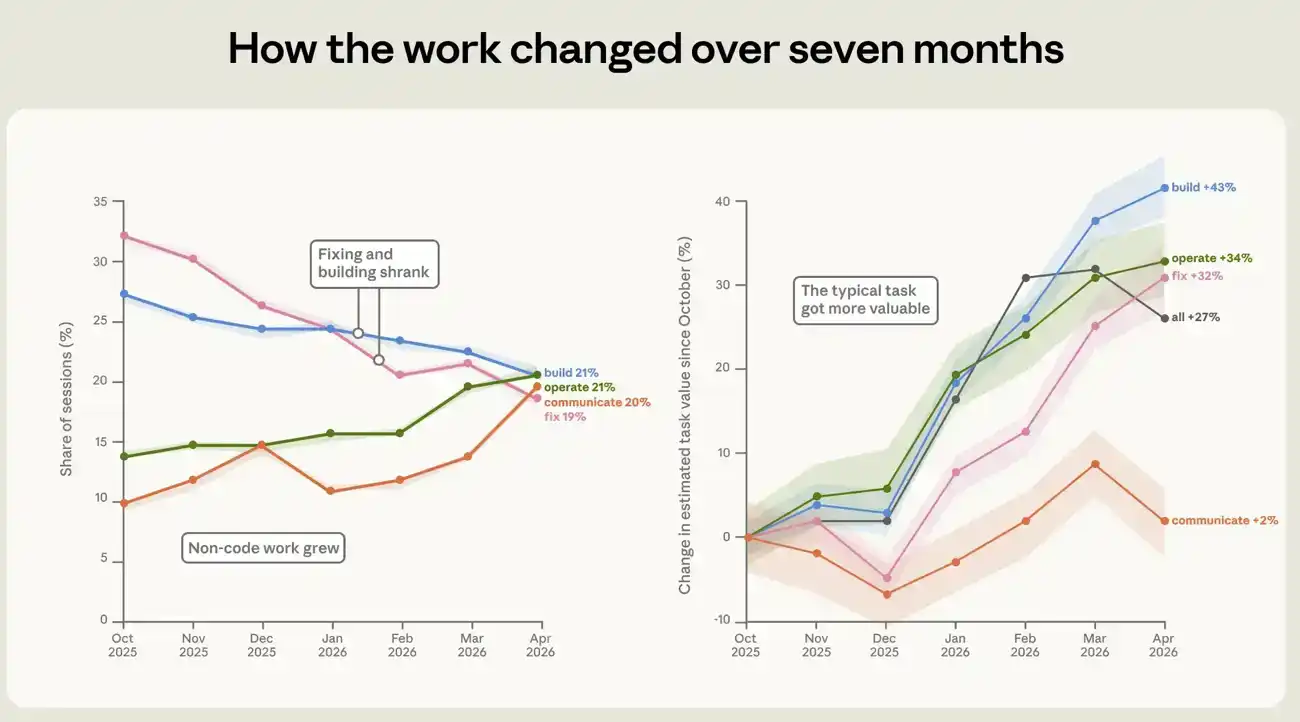
From October 2025 to April 2026, the composition of work people used Claude Code to complete changed significantly. The most pronounced change was a drop in the proportion of sessions used to fix broken code, from 33% to 19% (see Figure 4). This was replaced by more work surrounding code. The share of operating software increased from 14% to 21%. Writing and data analysis roughly doubled, rising from about 10% to about 20%.
The value of the tasks themselves also increased. We approximate the economic value of each session by estimating the cost of similar work on the freelance market, calibrated using a real-world public job posting dataset. By this measure, the estimated value of an average session rose by 27% between October and April. This increase appeared across many work types. The estimated value of building, operating, and fixing tasks grew by approximately 43%, 34%, and 32% respectively. These price estimates are rough, so we primarily use them to compare trends over time across different tasks, not as directly readable dollar values. See the appendix for details on how the task value estimator was constructed.
Success Depends on What the User Brings
Estimating task value is one way to understand how Claude Code helps people get work done. Another angle is to see how many sessions succeed and which session characteristics correlate with success. Across all success metrics, we see a clear pattern: the higher the expertise level exhibited by the user in the session, the more likely the session is to succeed. Most of the gains are concentrated at the lower end of the expertise spectrum, meaning the gap from novice to intermediate is greater than from intermediate to expert.
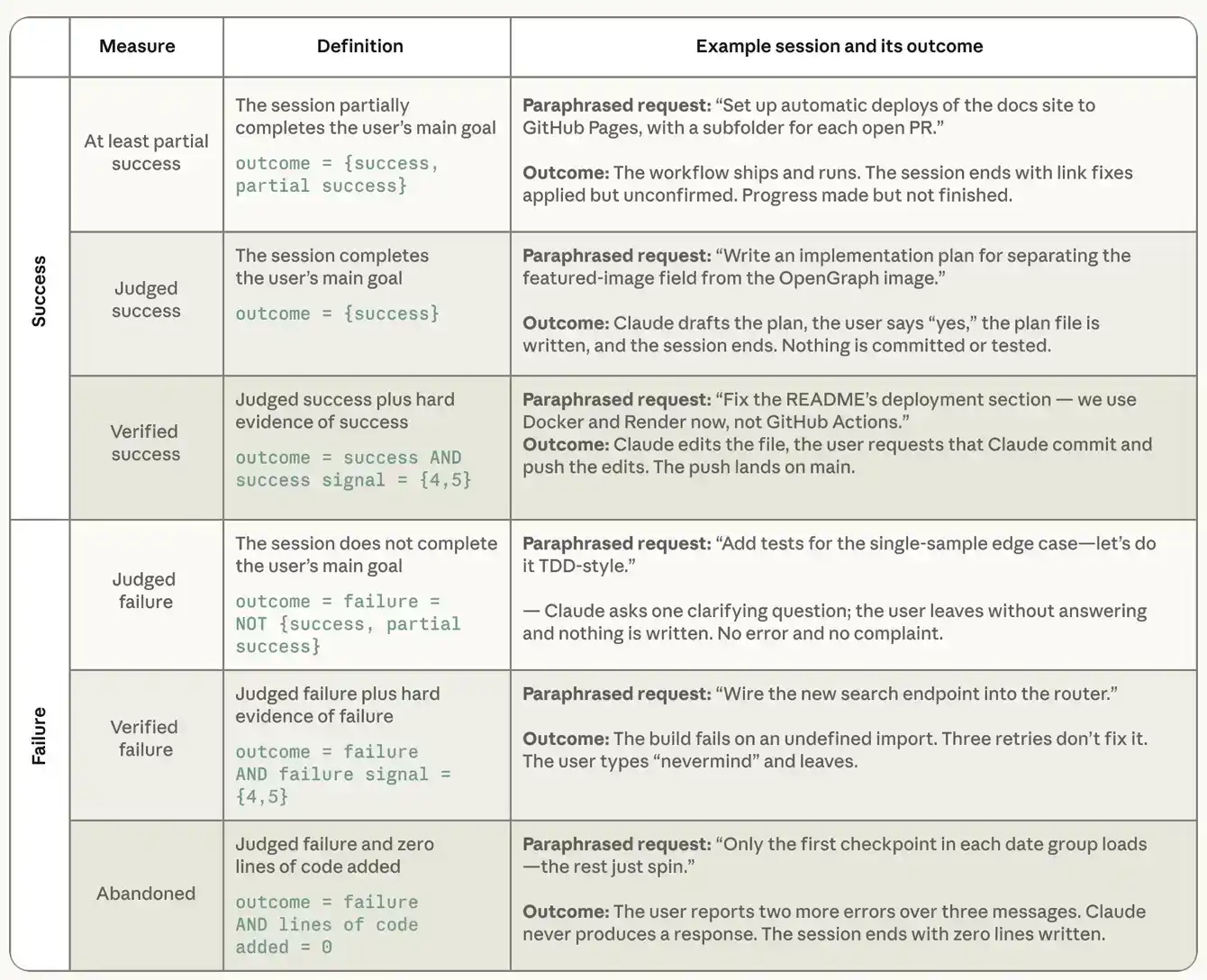
Before analyzing the characteristics of successful sessions, we need to specify precisely how we measure success. We cannot observe real-world outcomes or directly ask users if they accomplished what they intended through Claude. Therefore, we rely on two complementary, session-transcript-based measures. The first is "adjudicated success," where a classifier reads the full session transcript and judges whether the user accomplished their originally stated goal, with options including success, partial success, failure, and no clear goal. Then, two companion classifiers assess the strength of evidence for this judgment to determine "verified success." The success signal classifier looks for verifiable evidence of success, particularly including git activities matching the work, such as commits and pull requests, test suite passes, and explicit user expressions of satisfaction. It scores sessions on a scale from "no signal" to "weak signals" (1 point) up to "multiple hard signals" (5 points). A parallel failure signal classifier scores evidence that things went wrong, including errors, test failures, repeated attempts at the same thing, and user objections to output. Verified success requires two conditions to be met simultaneously: the session is adjudicated as successful, and there is at least one hard, verifiable success signal. The following analysis focuses on the degree of success or failure in sessions, so we exclude sessions adjudicated as "no clear goal" by the success outcome classifier, which constitute about 7.7% of the full sample.
The Returns to Expertise
So, which sessions are most likely to succeed? The results show that the session expertise rating described above has a strong influence on session success.
One might worry that expertise isn't the real driver. Perhaps experts simply choose different tasks or differ in other ways. In this section, we partly address this concern by comparing sessions of the same work type, same estimated value, same month, same topic, and from the same broad occupational group, and examining how results vary with user expertise.
Across all success metrics, the higher the expertise exhibited by the user in a session, the more likely the session is to succeed. Sessions rated as Novice achieved success on our strictest metric, "verified success," 15% of the time, and achieved at least partial success 77% of the time. Sessions rated as Intermediate and above achieved verified success rates of 28% to 33%, and partial success rates of 91% to 92% (see Figure 5).
For each metric, most of the gains come from moving from novice to intermediate; the slope flattens from intermediate to expert. Details on the regression analysis underlying Figure 5 are in the appendix.
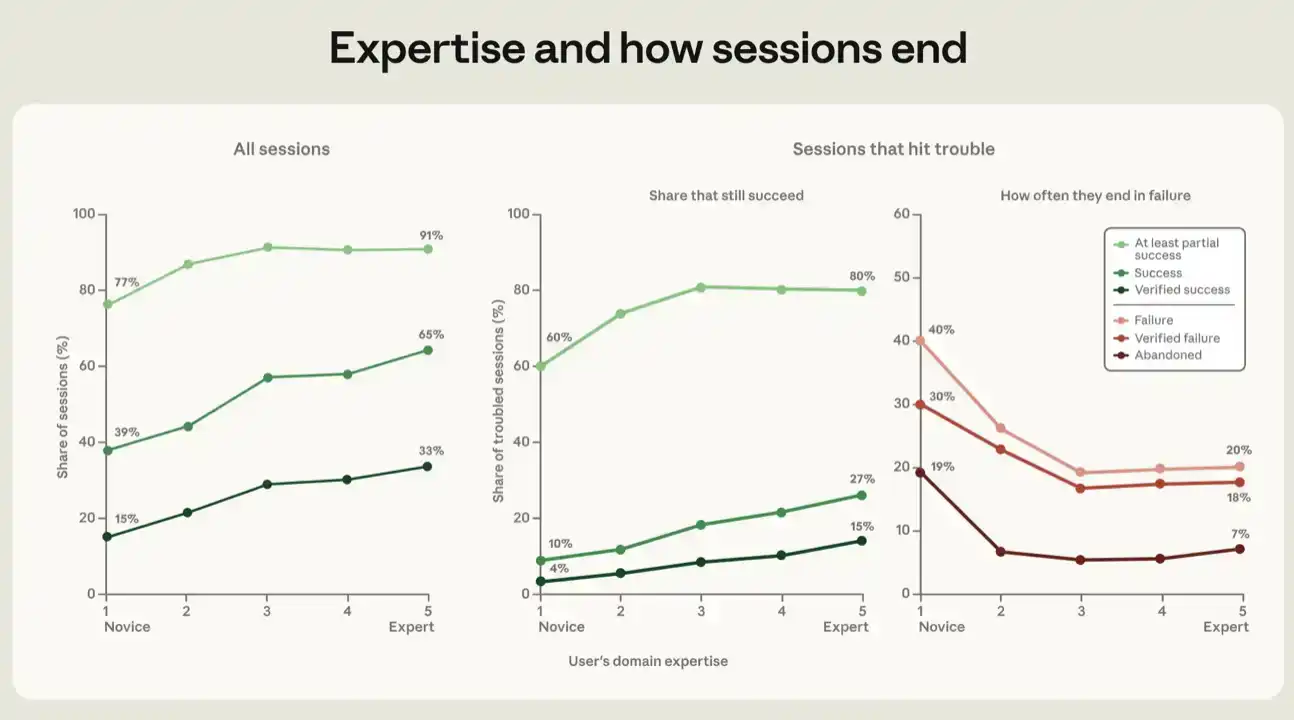
A similar gradient is visible in sessions that run into trouble. When the failure signal records verified evidence of failure, we consider the session as "having problems." This may include errors, test failures, multiple attempts to accomplish the same thing, or user expressions of frustration and dissatisfaction. Among sessions that had problems, after controlling for all the above variables, the proportion achieving verified success rises from 4% for novice sessions to 15% for expert sessions (see Figure 5). Using a more lenient success metric, we find that the proportion achieving at least partial success is 60% for novice users and 80% to 81% for intermediate to expert users.
We also tracked the inverse relationship—between expertise level and various failure metrics. Note that for this analysis, sessions adjudicated as failed are those that did not even achieve partial success. If a session that had problems is adjudicated as failed and also did not write any lines of code, we call it abandoned. In sessions where the user appeared to be a novice, 19% were ultimately abandoned; in other user groups, this figure was 5% to 7%. In other words, the least experienced users were more likely to give up when they encountered difficulties while trying to achieve a goal. Part of the value of professional capability seems to lie in being able to steer the agent back on track.
Occupation May Be Less Important Than Expertise
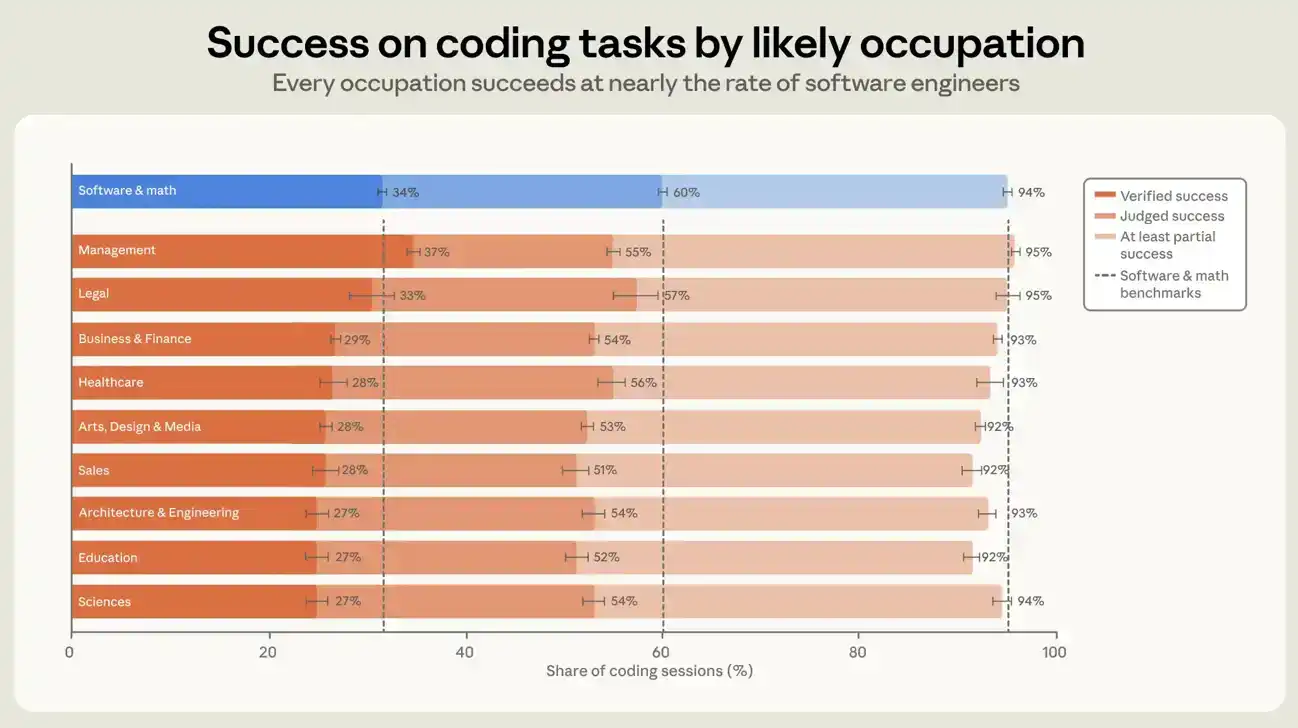
Users in software-related occupations have a verified success rate of about 30% across all sessions, while users in other occupations have about 26%. In sessions that produced code—i.e., added or modified at least one line of code—these figures are 34% and 29% respectively (see Figure 6). The gap between software-related and other occupations narrows further when using a more lenient success definition. In code-producing sessions, the proportions achieving at least partial success are 89% and 88% for the two groups. A five-percentage-point gap is not large, and it neither widened nor narrowed over the seven months, though success rates for both groups increased. In code-producing sessions, each of the ten largest occupational groups in our dataset is within seven percentage points of software engineers in success rate. Management occupations have the highest verified success rate, slightly above software engineering occupations. The higher verified success rate for managers may reflect the transferability of management skills to directing an agent. But it might also partly stem from our measurement approach: verification relies in part on explicit user confirmation within the session, and managers may be more accustomed to expressing when they get the result they want.
Looking Ahead
The results of this report sketch an emerging picture: agentic programming is amplifying certain kinds of knowledge and skills while substituting for others. In sessions that produce code, success rates across major occupations are not far from those of software-related occupations. It seems that coding agents are making a programming background less important for successfully completing programming tasks.
At the same time, successful sessions are more likely to exhibit domain expertise. Sessions rated as Expert are more than twice as likely to achieve verified success as those rated Novice. When sessions run into problems, novices abandon them several times more often than other users. The collaboration pattern itself makes this picture clearer: domain experts can direct Claude to accomplish more work with each instruction. Therefore, the ability to steer Claude toward success comes more from mastery of a domain than from the ability to write code. Anyone possessing such mastery in any domain can now potentially accomplish technical work that was previously out of reach. Those lacking this professional understanding will reap much less benefit, even with the same tools. And the gains come mainly from competence, not from mastery. Having an operational understanding of a domain already yields most of the benefit; deep specialization adds only a modest additional advantage on top of that.
These findings remain preliminary. As with most of our research, we cannot measure real-world outcomes, such as whether the code written in a session is later used or discarded, or whether it produced economically valuable outputs. Furthermore, non-interactive usage excluded from this report constitutes a significant portion of overall activity. Developing a framework to measure such usage is a priority for future work. Also, all our session classifications rely on models reading session transcripts. In the appendix, we show that the classifiers align with independent telemetry data in expected directions and, for most sessions, agree with judgments from strong reference models. However, validating classifiers at scale remains difficult; Claude Code sessions themselves add to the difficulty, as they can be too long and complex for human labeling to serve as a reliable ground truth.
The picture described in this report will continue to evolve as models, users, and the division of labor between them change. We hope these metrics will help us track the major shifts underway. For example, if returns to expertise begin to decline in the future, that would signal models starting to provide the critical judgment users currently bring, and the benefits of these tools would extend from domain experts to a broader population. If the share of coding sessions successfully completed by users outside software occupations continues to rise, it may indicate that software production is becoming part of ordinary work in every field, rather than the output of a single profession. These shifts will change who benefits from agentic programming and by how much, impacting which abilities are most valued in the labor market.





