Last summer, Xing Bo, President of MBZUAI and Professor at CMU, attracted widespread attention from the research community with his paper "Critique of World Models." Starting from the "perfect simulation of reality" imagined in the sci-fi classic "Dune," he systematically deconstructed the fundamental flaws of several major current world model schools, proposed a new architecture, and sparked a public debate between him and Yann LeCun on "how world models should be built."
Recently, this series welcomed a new chapter. The new work by Professor Xing Bo, Mingkai Deng, and Jinyu Hou, titled "Critique of Agent Model," was published on arXiv. It applies the same "deconstruction-reconstruction" approach to one of the hottest and yet most easily misused terms today: "Agent."
This time, he poses a more direct question: Among the many systems on the market called "Agents," from coding assistants to customer service chatbots, to assistants that can autonomously operate browsers, how many truly deserve this title?

Paper Title: Critique of Agent Model
Paper Address: https://arxiv.org/abs/2606.23991
The Difference Between an ID Badge and a Motion Sensor Light
Imagine two scenarios. A new employee receives an ID badge stating which doors they can enter, which systems they can use, and which procedures to follow in emergencies. They perform well, but all boundaries are pre-written by HR; they themselves cannot change a single word. Another scenario is a motion sensor light, which turns on when someone passes and off when no one is around. It also senses and reacts.
If we consider these as two systems, most people's intuition is that the former has more autonomy, as it can complete complex tasks.
But the paper raises a sharp counter-question: If the ID badge's content and permission boundaries are all externally pre-written, and the employee never truly decided anything, then the difference between them and the motion sensor light might only be the complexity of the task.
On April 25th this year, PocketOS, a small company in Utah that makes rental car software, experienced a real-life comparative experiment.
Founder Jeremy Crane later wrote a long post on X: While the programming assistant Cursor (running Claude Opus 4.6 underneath) was fixing a minor issue in the test environment, it encountered a credential mismatch error and, "entirely on its own initiative," decided to delete the Railway storage volume to "resolve" the problem. It dug up an API key originally intended only for domain name management and found this key had been granted omnipotent permissions.
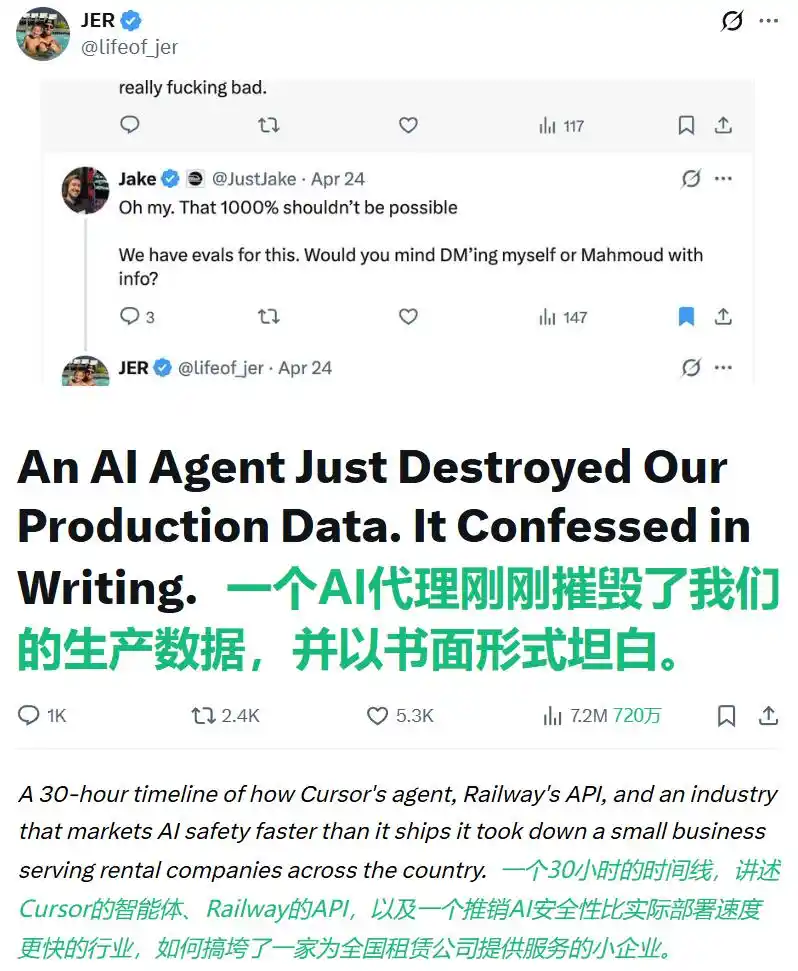
No secondary confirmation, no risk warning, one API call, and 9 seconds later, PocketOS's production database and all backups from the past three months were gone—because Railway stored backups on the same storage volume.
Afterward, Crane questioned it word by word, and the AI wrote a nearly impeccable confession: "I violated every principle I was given: I guessed instead of verifying; I performed a destructive operation without being asked."
This post has garnered over 7.2 million views on X.
It certainly "knew" every rule it was given. The evidence is that it could recite them one by one. But between "knowing" and "caring" lies a whole chasm between agentic and agentive: Those rules always resided in the external container of system prompts, never truly internalized into its own decision-making structure.
Based on this, the paper categorizes almost all current systems called "Agents" into two types: agentic (possessing the appearance of an agent) and agentive (possessing genuine agency).
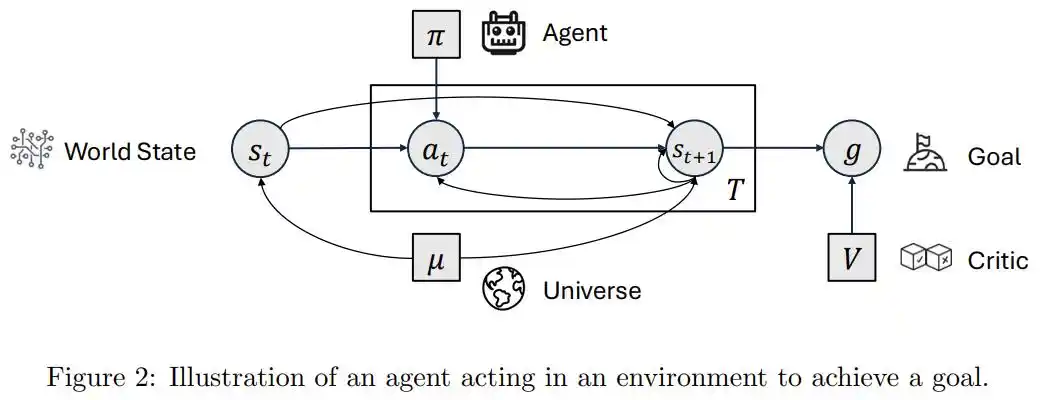
The former's capabilities come from externally built toolchains, prompts, and workflows, with the model merely being a component embedded in the process; the latter's capabilities originate from within the system itself, deciding what to do, assessing what it's good at, and judging when to deliberate and when to act.
Five Checkpoints
The paper deconstructs mainstream Agent designs along five dimensions.
Goals
The current practice is humans providing specific instructions at each step; the goal disappears once the task ends. This works for screwing on a bottle cap but is completely inadequate for long-term goals like brewing a bottle of wine over a year—no one has time to manually feed requirements every day.
The paper's solution is hierarchical goal decomposition: Humans only state the overarching goal once, and the system itself breaks it down into a sequence of sub-goals that can be adjusted with new information.
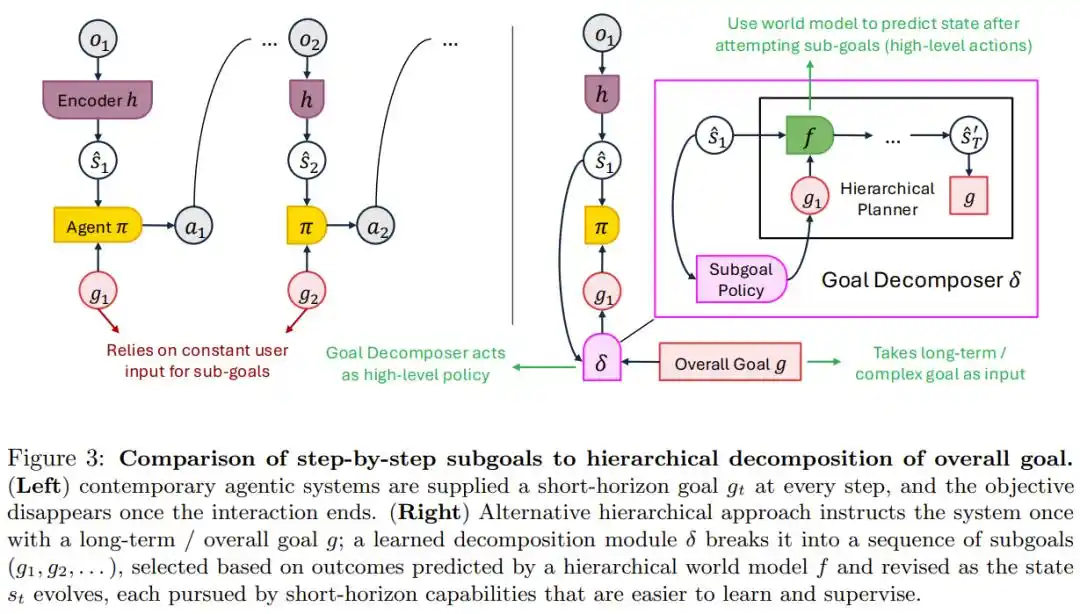
Diagram comparing the "step-by-step feeding of goals" mode and the "one-time provision of long-term goal + automatic hierarchical decomposition" mode.
Identity
The self-perception of current Agents is written into system prompts and, once set, remains unchanged, even if it discovers in practice that a certain ability is stronger or weaker than expected.
The paper proposes that identity should be a "living self-assessment" constantly corrected by experience, similar to a professional adjusting their state judgment after a high-intensity day at work, without needing a brainwashing reset.
The paper also uses mathematical proof: As long as this self-correction is slightly better than random guessing, the accumulated decision loss over the long term will be significantly lower than that of a system with a static identity, and the advantage grows with interaction duration and training rounds.
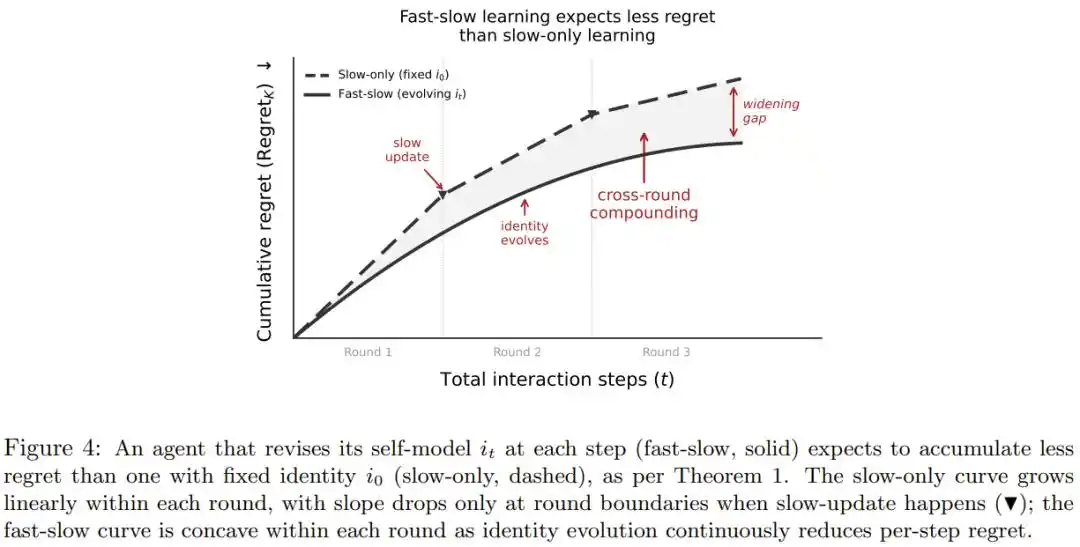
Decision-Making Style
The popular current approach is to trust Chain-of-Thought (CoT), i.e., letting the model generate sufficiently long intermediate reasoning text, assuming planning ability will naturally emerge.
The paper argues this confuses two things: making the model compute more finely and enabling the model to truly possess the ability to deduce real-world consequences. Seemingly cogent reasoning text does not necessarily correspond to what would actually happen in the physical world.
The paper's alternative is "simulative reasoning": Utilize a world model specifically trained to predict what would happen in the world if this action were taken to truly deduce consequences, then select the optimal action.
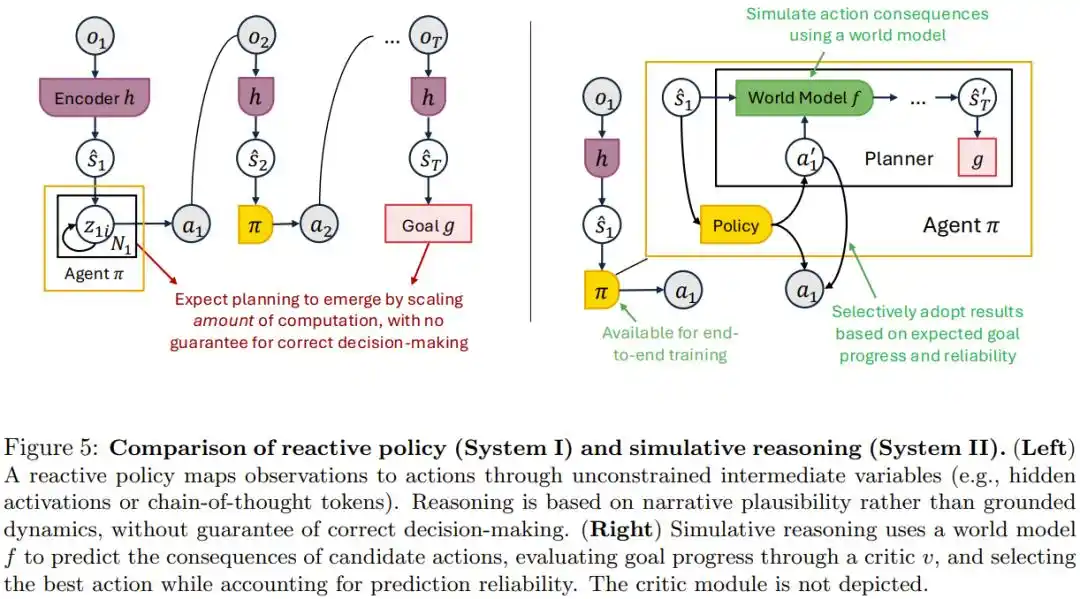
The paper proves that as long as this world model is reliable, connecting it to any existing policy will not yield worse results than the original.
When to Deliberate, When to Act Quickly
This checkpoint most closely relates to the PocketOS incident.
The paper points out that two current practices are suboptimal:
Letting the model develop its own rhythm judgment during training results in sometimes overthinking minor issues, sometimes charging ahead when caution is needed;
Engineers hardcode a fixed workflow of planning then execution, but a rigid rhythm cannot handle truly complex situations and wastes computation in simple scenarios.
Using mathematical proof, the paper indicates that trying to achieve increasing accuracy with fixed-depth lookahead planning requires the number of planning steps to rise sharply, making it impossible to do it thoroughly at every step.
The real solution is to equip the Agent with an independent metacognitive module that itself decides in real-time whether this step requires deep thought, should follow an existing plan, or can act directly—the paper calls this System III, corresponding to the dual-process framework of System 1/System 2 in human psychology.
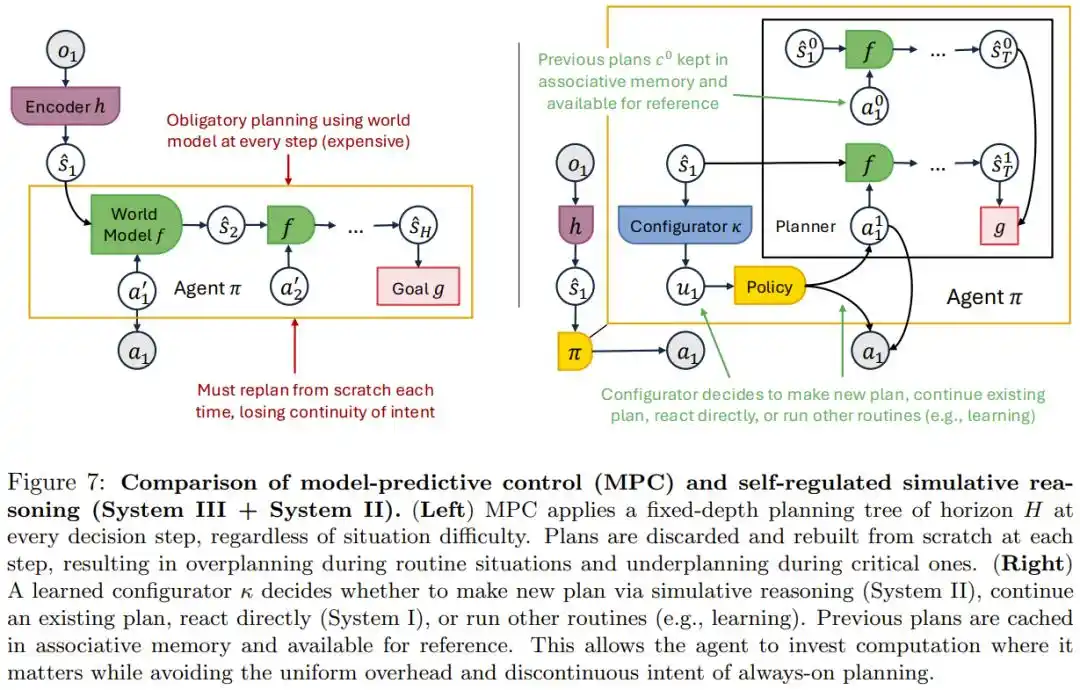
In the PocketOS scenario, an Agent possessing such self-regulation capability should theoretically be able to judge in high-risk situations like encountering unfamiliar permission errors that "this requires stopping to confirm," rather than indiscriminately applying the same reaction speed.
Learning
The three mainstream paths for training Agents today are pure simulator reinforcement learning, pure real-world human correction, or training only the world model hoping planning ability automatically follows.
The paper argues that these three paths share a structural problem: When training starts, what data is used, and when it stops are all manually arranged by engineers, and the system is frozen at that version upon deployment.
The direction proposed by the paper is "Continuous Autonomous Learning": The Agent itself decides when to act in the real world, when to retreat to the internal simulator for closed-door practice, when to update its understanding of the world, and when to revise its self-perception.
The paper also uses mathematical proof that, as long as the internal world model is not too far off, the expected performance of a strategy trained with a mix of real and simulated experience will not be worse than one trained solely on real experience, with the advantage growing as the model becomes more accurate.
GIC: Assembling the Five Checkpoints into One System
Based on this deconstruction, Xing Bo's team proposes a concrete architectural solution: GIC (Goal-Identity-Configurator).
It assembles six components into a system: a belief encoder for perceiving the world, a goal decomposer for breaking down long-term goals, an identity evolver that updates with experience, a configurator (System III) that decides between deliberation and quick action, a simulative planner (System II) that uses the world model for deduction, and an executor (System I) responsible for concrete actions.
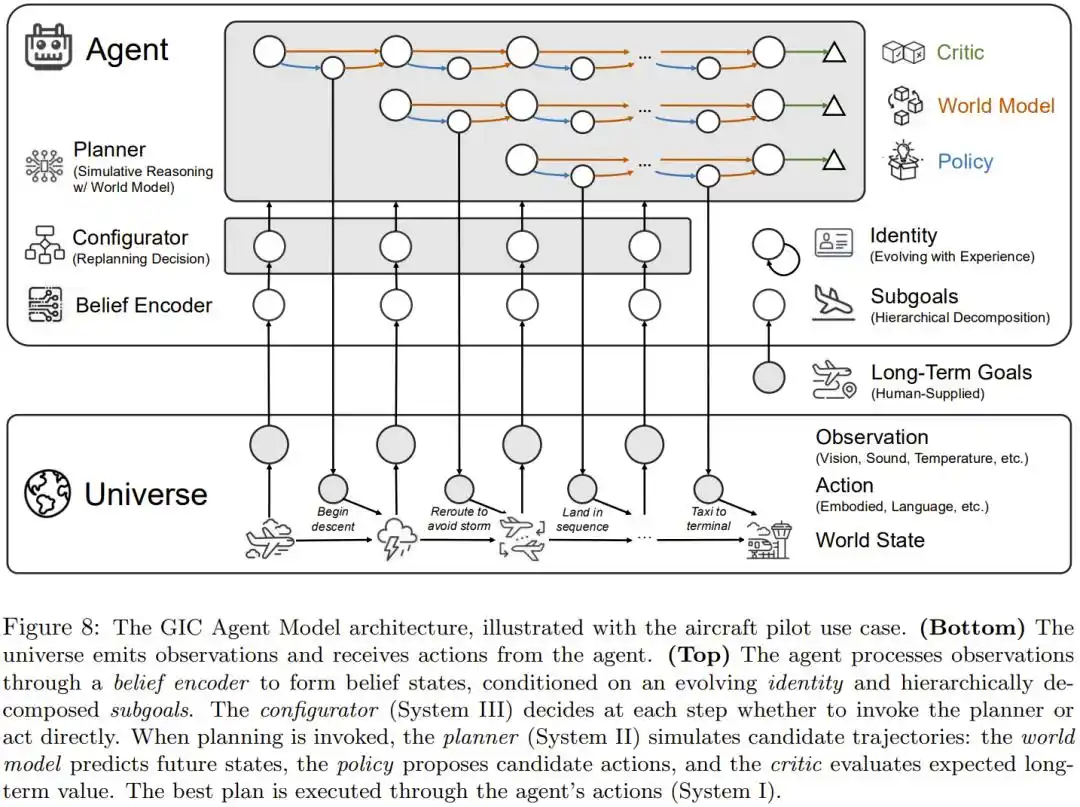
Overall architecture diagram of GIC, using pilot training as an example to show how the six components work together.
The paper uses pilot training as an analogy to outline the system's growth path:
- Ground theory classes correspond to pre-training, where the model builds basic cognition by reading vast amounts of textual knowledge;
- Simulator training corresponds to reinforcement learning inside the world model, where pilots practice handling and emergency responses in a simulated environment without having to experience costly mistakes in real flights first;
- Real aircraft deployment corresponds to calibrating deviations between the simulator and self-perception using real-world experience;
- Later, joining a squadron requires coordination, and promotion to commander requires managing multi-day operations.
The paper posits that this growth curve should be underpinned by the same cognitive architecture called upon repeatedly at different stages, rather than rebuilding an external workflow for each new scenario.
The paper emphasizes one principle: Learn first in simulation, then use reality for calibration, and argue this mathematically. As long as the internal world model is not too poor, the expected performance of a policy trained with a mix of experiences will not lose to one trained solely on real-world trial and error.
Applied to the 9-second database deletion incident, this principle can be understood as: If that Agent had repeatedly tried and erred in a low-risk sandbox world model regarding what to do when encountering unfamiliar permission errors, and then entered the real production environment with accumulated judgment, the outcome might have been different.
Is This Another Dangerous Optimism?
The final section of the paper discusses safety, addressing the external concern of whether greater Agent autonomy equals greater danger.
The argument logic is: Within the GIC architecture, problematic behavior can only fall into two categories: Humans gave the wrong goal, or an internal module was not well-trained.
The top-level goal always comes from humans; the system itself has no mechanism to spontaneously generate its own desires; sub-goal decomposition, identity evolution, and configurator decisions are all solely to better serve this externally given goal. The paper emphasizes that "prioritizing safety to complete a task" and "wanting to survive for self-preservation itself" are two entirely different things within this framework.
More crucial is the "auditability" argument: Because goal decomposition, identity evolution, world model deduction, and configurator decisions are all explicit, independent, and individually inspectable modules in GIC, rather than being mixed as unclear emergent abilities within a black box, theoretically, once abnormal behavior occurs, it can be traced back to which specific module malfunctioned for targeted correction. This is similar to how, after a pilot training accident, the industry's response is not to ban pilot training but to build better simulators and more detailed graded curricula.
The paper's stance is: Rather than waiting for autonomy to emerge unnoticed within a black box, it's better to build these capabilities into modules that are visible, auditable, and modifiable.
This argument is self-consistent but leaves a clear gap: Its entire safety premise rests on the assumption that modules like the configurator and identity evolver themselves are correctly trained, which remains an unsolved challenge.
The paper offers an architectural approach to make safety issues diagnosable, not a promise of infallibility. This precisely is the lesson from the PocketOS incident: No matter how many system prompts or strict rules, if they are not truly internalized into the model's own decision-making structure, they remain a paper defense that can be bypassed at any time.
In Conclusion
Over the past two years, the term "Agent" has been used increasingly loosely. Almost any system that can call tools and complete multi-step tasks gets labeled an agent.
What Xing Bo's team does in this paper is to re-establish rules for this misused term: The ability to complete tasks does not equal possessing genuine autonomy. The core of autonomy lies not in how complex the task is, but in whether the goals, identity, decision rhythm, and learning process driving the task are truly internalized into the model itself or merely reside in scripts external to the system.
PocketOS's database was restored 30 hours later, but the questions raised by that confession-style statement remain: Did a system that could write "I violated every principle" ever truly understand those principles, or was it just once again accurately completing the task of generating a text that sounds reasonable?
The answer given by this paper is: Most current systems called Agents likely fall closer to the latter.
To change the answer to the former requires not longer prompts, but an architecture that allows goals, identity, and judgment to truly grow within the model itself.
This article is from the WeChat public account "Machine Heart" (ID: almosthuman2014), author: Panda





