传统上,具有固定最大供应量的代币称为通货紧缩代币。所有其他的都称为通胀代币。
“”
以太(ETH)没有最大供应量,所以根据这个简单的定义,它是通货膨胀的。但在本周的合并之后,它依然是通货膨胀吗?
“”
如果 ETH 燃烧的代币比它发行的多,那么它实际上有通缩压力。
“”
以下是每天大约发行 ETH 的统计数据(来源:Ethereum[1] 和 Watch The Burn[2])。
“”
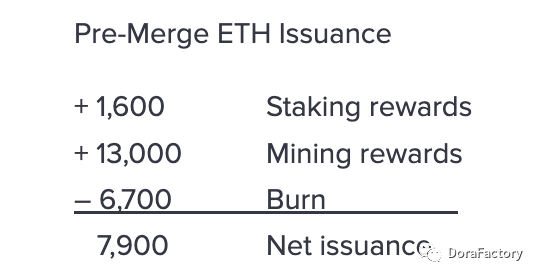
合并前,自 2021 年 8 月 5 日伦敦硬分叉 (EIP-1559) 以来的过去一年中,ETH 平均每天燃烧 6700 个,少于发行的 14,600 个,因此净代币供应量一直增加。
合并后,不再有挖矿奖励:

合并后,6700 的销毁大于1600 的发行。ETH 的净总供应量正在减少。这就不像是“通胀代币”了。
“”
因此,传统定义下的没有最大供应量的“通胀代币”实际上可能具有通缩压力。
“”
也许通货膨胀和通货紧缩代币的定义需要更新。
“”
重新定义通胀和通缩代币
”“
最大代币供应量只是确定代币是否面临通胀或通缩压力的一个因素。
”“
第二个同样重要的因素是循环供应的可预测性。
”“
通胀代币 的特点是:1) 没有最大的代币供应量,以及 2) 流通供应量的增加。
”“
通缩代币 的特点是:1) 固定的最大代币供应量,以及 2) 可预测和/或持续减少的循环供应量。
”“
不具备这两个标准的代币并不是绝对的通货膨胀或通货紧缩。需要进行一些调查,或者可能不适合任何一个类别。
”“
让我们看一些例子。
”“
模因币在设有最大供应时表现更好
”“
模因币在分析最大代币供应方面具有指导意义,因为它们几乎没有基本面。从理论上讲,那些有最大代币供应的应该会更好。让我们看看这是否会奏效。
”“
在 CoinGecko 追踪的 90 个模因代币中,排前 50 的模因代币中有 68% 设置了最大代币供应量。然而,接下来的 40 个代币中只有 36% 这样做了。这验证了我们的理论。
”“
有趣的是,狗狗币是最大的模因币,但它没有设最大供应。当它在 2013 年推出时,它的最大供应量为 100B 个代币,只是后来被取消了。拥有最大的代币供应量肯定会有所帮助,尤其是在早期。
”“
通货膨胀代币
”“
Terra Classic 是过度通货膨胀的代币的完美诠释。在数十亿美元的 UST 和 LUNA 崩盘中,LUNA 的代币供应量从 3.5 亿增加到 6.5 万亿,结果可以预见的是价格下跌超过 99.9%。
”“
有趣的是,为了重振它,LUNA 在与 Terra Classic (LUNC) 不同的链上重新启动。2022 年 9 月 1 日,Terra 宣布将通过在区块链上的每笔交易中燃烧 1.2% 的代币来减少 Terra Classic 庞大的代币供应——就像 1.2% 的税率。在接下来的一周里,LUNC 升值了一倍多。
”“
通货紧缩代币
”“
Ripple (XRP) 进行程序化销毁,但增加了额外的通货紧缩机制。他们将 100B 总供应量中的 55B 锁定在一个特殊的托管账户中,以向市场证明他们不会胡乱释放大量代币(就像 Terra 那样)。他们每月释放一个相对 可预测[4] 份额,这增加了稳定性并强化了代币的通货紧缩特征,即使代币的流通供应量不断增加。据 Messari 初步估计:“按照目前的燃烧速度,XRP Ledger 需要 20 年才能燃烧掉 Ripple 及其创始人每天的分发。”
”“
Ripple 代表了项目管理其代币供应的良好模板。
”“
对 Web3 项目的建议
”“
如果您正在创建一个 Web3 项目或 DAO——或者评估一个用于投资的项目,以下是对创建通货紧缩代币的建议:
1. 以编程方式设置最大代币供应量
2. 发布代币经济学,明确说明如何以及何时分配资金
3. 让社区投票就解锁特定池的释放时间表达成一致
4. 公开释放细节以及影响您的流通代币供应的任何其他内容
5. 设置通过链上智能合约而非口头承诺的程序化销毁机制
6. 在很长一段时间内(例如 20 年)将代币供应量减少到目标数量。





