Depuis le début de cette année, les trois géants américains de l'IA ont successivement collé des étiquettes "futuristes" à leurs produits de modèles.
OpenAI dit que ChatGPT a appris à "rêver" ; Anthropic veut doter Claude d'un "Wiki personnel" intégré ; Google affirme quant à lui que Gemini "possède nativement dix ans de vos souvenirs".
Trois formulations, qui semblent sans lien évident, sont en réalité en compétition pour la même chose – le Contexte (Context).
Initialement, le Contexte n'était qu'un paramètre technique insignifiant, mesurant combien de caractères un modèle pouvait lire en une seule fois. Aujourd'hui, sa signification s'élargit : c'est un actif utilisateur, une autorisation d'outil, l'état en temps réel d'une tâche en cours, et surtout, à quel point l'IA vous comprend vraiment.
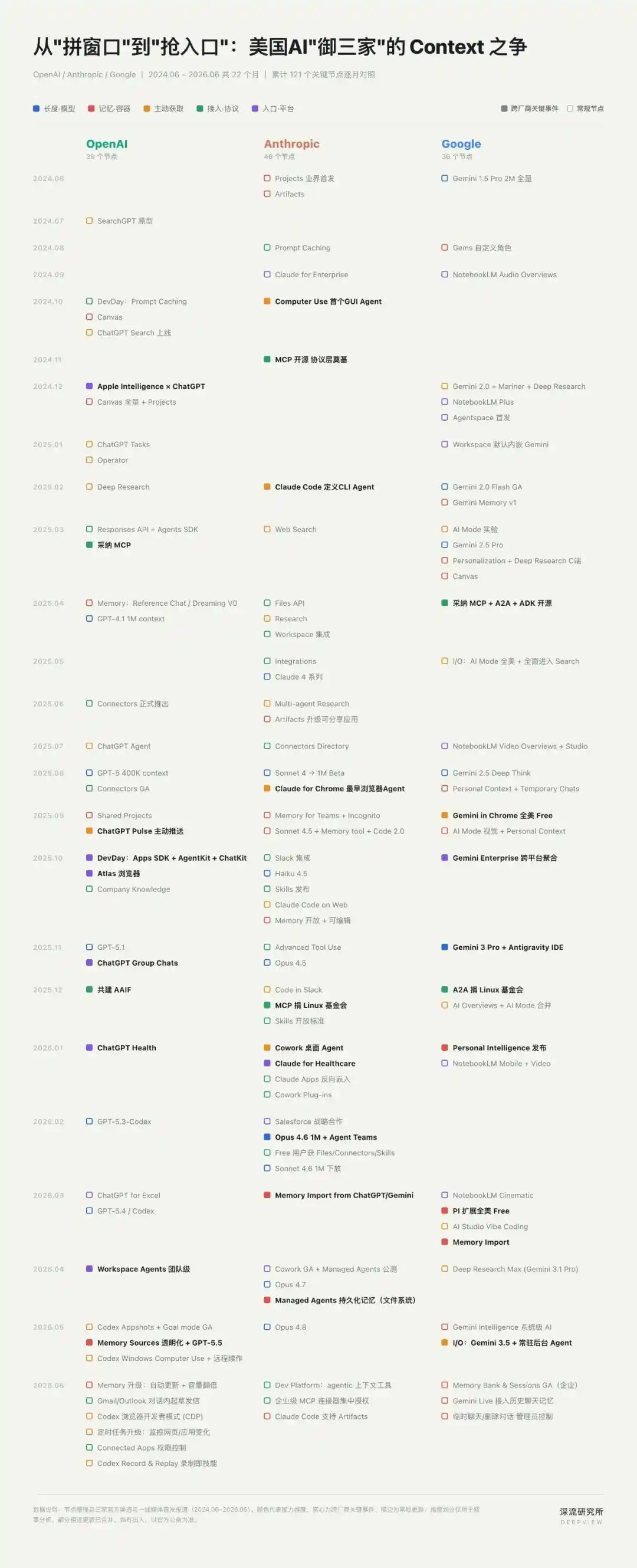
Selon les statistiques du « Deep Flow Research Institute », depuis le début de l'année, OpenAI, Anthropic et Google ont publié plus de 40 produits et mises à jour fonctionnelles majeures autour du Contexte – soit en moyenne une nouvelle capacité mise sur le marché tous les trois ou quatre jours.
De la fenêtre de contexte longue, à la Mémoire (Memory) trans-session, en passant par les capacités d'action dans le navigateur, le bureau et les interfaces graphiques (GUI), les changements les plus importants des produits d'IA ces deux dernières années ont presque tous tourné autour du Contexte.
Une guerre autour du "Contexte" a commencé, et cela reconfigure en silence les douves de l'ère de l'IA.
1. De la fenêtre longue à l'environnement réel, les trois sauts de frontière du Contexte
La première compétition sur le Contexte s'est jouée sur la "longueur du texte".
À l'ère des Chatbots, le Contexte signifiait principalement la quantité d'information qu'un modèle pouvait ingérer en une fois. Plus la fenêtre était longue, plus le modèle pouvait traiter des thèses, des bases de code, voire des documents de projet complets. Ainsi, OpenAI, Anthropic et Google ont déclenché une course aux armements sur la taille du contexte.
En mai 2023, Anthropic a été le premier à passer la fenêtre de contexte de Claude de 9K à 100K, équivalent à environ 75 000 mots, permettant pour la première fois de "télécharger un livre entier". En novembre 2023, OpenAI a suivi avec GPT-4 Turbo à 128K. Trois mois plus tard, Google a poussé la fenêtre au niveau du million avec Gemini 1.5 Pro.
En moins d'un an, le Contexte est passé du niveau cent-mille au niveau million.
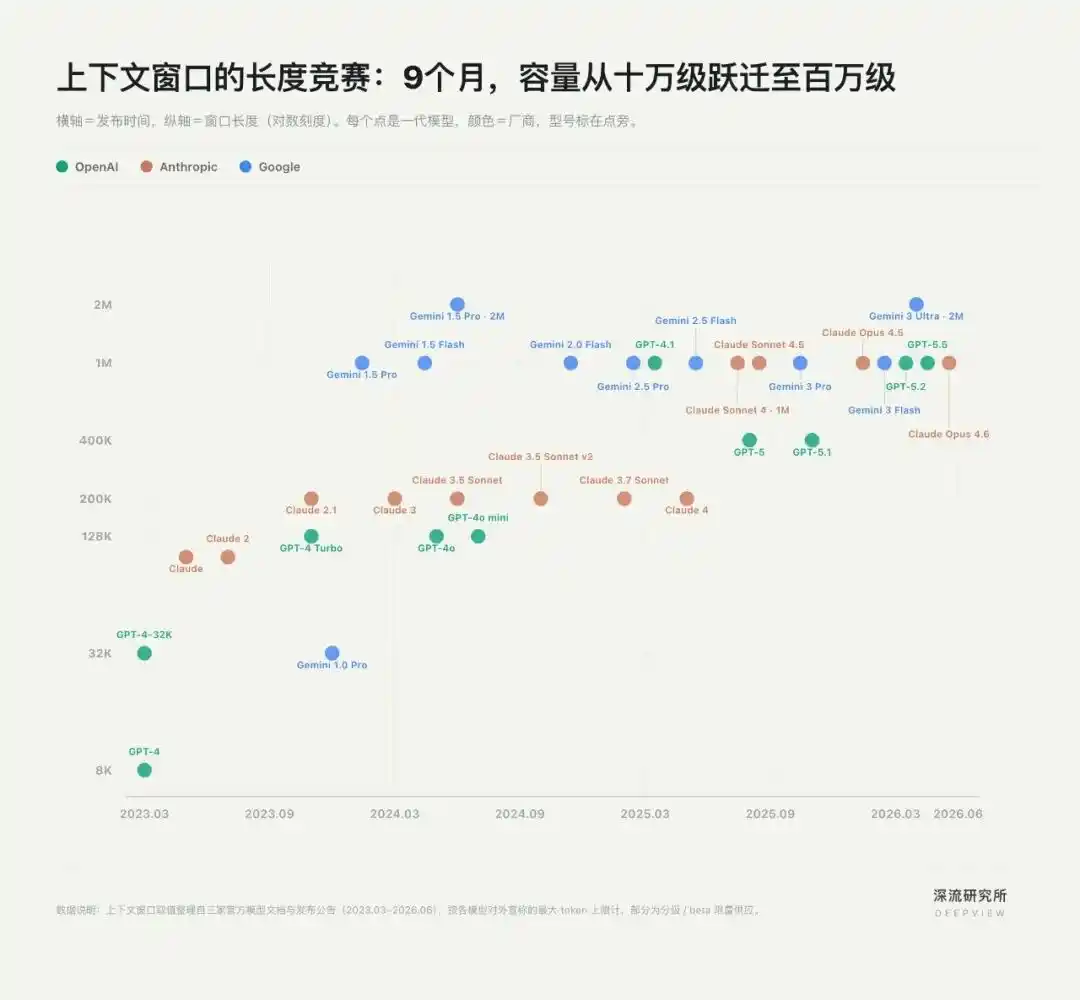
La fenêtre longue a résolu le problème de "débit" de l'IA, mais cette course a rapidement révélé ses limites : le fait que le modèle puisse voir plus d'informations ne signifie pas qu'il comprend mieux la tâche.
Surtout lorsque les produits d'IA sont passés du Chatbot à l'Agent, les frontières du Contexte ont commencé à changer. Il n'est plus seulement le texte d'entrée d'une conversation, mais devient un flux d'état qui s'accumule de manière continue et se met à jour dynamiquement dans le cycle des tâches.
Le point de compétition s'est alors déplacé : de "combien le modèle peut savoir en une fois" à "ce que le modèle peut retenir à long terme". La Mémoire (Memory) est devenue la forme produit typique de cette phase.
Début 2024, OpenAI a été le premier à introduire la mémoire trans-session pour ChatGPT, permettant au modèle de retenir les préférences, le contexte et les besoins à long terme de l'utilisateur. Par la suite, Anthropic et Google ont complété les capacités de mémoire de Claude et Gemini.
Le Contexte a acquis une dimension temporelle. L'IA ne traite plus seulement l'entrée actuelle, elle commence aussi à essayer d'établir une continuité entre les interactions de l'utilisateur d'aujourd'hui, de la semaine dernière, du mois dernier. Seule une IA dotée d'un Contexte à long terme peut potentiellement relier des interactions discrètes en une relation continue.
Cependant, la Mémoire répond à "ce qui s'est passé dans le passé", mais n'aborde pas encore une autre question plus cruciale : que se passe-t-il en ce moment même ?
Le véritable tournant est survenu au second semestre 2025.
À partir d'août de cette année-là, les trois entreprises ont presque simultanément poussé le front du Contexte vers le navigateur : Anthropic a lancé Claude for Chrome, Google a intégré Gemini dans Chrome, et OpenAI a sorti son navigateur IA indépendant ChatGPT Atlas.
Le navigateur est une mine naturelle de Contexte. Le contenu des pages web, l'intention de recherche, l'état de connexion, les formulaires, l'historique, les onglets, ainsi que les tâches que l'utilisateur est en train d'exécuter, tout cela est déposé dans le navigateur. Plus important encore, ce Contexte y est plus en temps réel, plus continu, et plus proche du lieu réel de la tâche.
Auparavant, la façon dont l'IA obtenait le Contexte était essentiellement d'attendre que l'utilisateur lui apporte le matériel : télécharger des fichiers, saisir des instructions, autoriser la mémoire, connecter des sources de données.
Une fois dans le navigateur, la logique a changé. L'IA commence à entrer dans l'environnement de travail de l'utilisateur, à observer l'état des pages, à comprendre la progression des tâches, à saisir l'intention des actions, et à exécuter l'étape suivante dans l'interface réelle.
Voici le troisième saut de frontière du Contexte : il est passé de données statiques en entrée du modèle, à un état dynamique capturé par l'Agent dans les environnements GUI, web et système.
La fenêtre longue détermine la quantité d'informations que le modèle peut contenir en une fois ; la Mémoire détermine si le modèle peut comprendre l'utilisateur à travers le temps ; les capacités liées au navigateur, aux produits bureau et aux GUI, déterminent si le modèle peut entrer sur le lieu réel de la tâche.
Mis ensemble, ces trois éléments constituent la ligne directrice de la compétition des produits d'IA ces deux dernières années : le Contexte n'est plus seulement une question de capacité du modèle, mais devient progressivement une question de point d'entrée produit, de relation utilisateur et de sédimentation des actifs.
2. Le Contexte devient un nouveau champ de bataille, les trois voies des "Trois Maisons Suprêmes" américaines de l'IA
Lorsque le Contexte passe de paramètre de modèle à actif utilisateur, le cœur de la compétition devient : qui peut obtenir, organiser et invoquer le Contexte de manière plus stable.
Autour de cela, OpenAI, Anthropic et Google ont suivi trois chemins différenciés.
ChatGPT est la source de Contexte la plus centrale pour OpenAI.
Les souvenirs, préférences, tâches historiques et historiques d'appels d'outils laissés par l'utilisateur au fil des conversations se sédimentent progressivement sous un même compte ChatGPT.
Ce compte est différent d'un compte Internet traditionnel. Un compte traditionnel enregistre l'état de connexion, les relations d'abonnement et les informations de paiement ; le compte ChatGPT enregistre, lui, l'"historique de l'utilisateur tel que compris par l'IA".
C'est un actif utilisateur natif de l'IA. Sa valeur ne se manifeste pas seulement dans des réponses plus personnalisées, mais aussi dans la réduction des coûts de démarrage à froid, la continuité de l'état des tâches, et la réutilisation d'une même compréhension de l'utilisateur dans différents scénarios produits.
Pour OpenAI, faute d'un écosystème de données natif comme celui de Google, il doit faire en sorte que les utilisateurs génèrent en continu de nouveaux Contextes au sein de l'écosystème ChatGPT.
C'est pourquoi les actions produit d'OpenAI ces deux dernières années ont constamment élargi le rayon des tâches que le compte ChatGPT peut couvrir – le SDK Apps permet à des applications tierces d'entrer dans ChatGPT, Atlas intègre le navigateur à ChatGPT, et le Codex récemment fusionné amène les tâches de programmation dans le même flux de travail.
La voie particulière d'OpenAI est qu'elle ne part pas d'un point d'entrée qu'elle maîtriserait pour y connecter ensuite l'IA ; elle part plutôt de ChatGPT comme point d'origine, et tire à l'inverse les scénarios d'application, de navigation et de programmation vers le même système de comptes.
ChatGPT n'est donc plus seulement un point d'entrée conversationnel, mais un centre nerveux qui agrège, invoque et met à jour le Contexte.
En comparaison, Anthropic manque à la fois de points d'entrée grand public et de données utilisateur massives préexistantes.
Sa voie consiste à s'insérer dans des scénarios verticaux à haute valeur comme le Codage ou les Agents, et à renforcer dans ces scénarios la capacité de Claude à acquérir activement le Contexte.
Pour Claude, le Contexte n'est pas un texte saisi par l'utilisateur, mais l'environnement en évolution dynamique sur le lieu de la tâche : la base de code, le système de fichiers, la sortie terminal, la page du navigateur, la base de données, la documentation du projet, et les retours après chaque étape d'exécution.
Par conséquent, Anthropic met davantage l'accent sur l'activité dans l'acquisition du Contexte. Le modèle ne doit pas seulement attendre l'entrée de l'utilisateur, il doit aussi, au cours de l'exécution de la tâche, entrer activement dans l'environnement, lire l'état et obtenir des retours.
En octobre 2024, Anthropic a lancé Computer Use, permettant à Claude de déplacer la souris, de cliquer sur des boutons, de saisir du texte en fonction de captures d'écran.
Selon les déclarations officielles, Claude 3.5 Sonnet est le premier modèle d'IA de pointe à offrir publiquement une capacité d'utilisation d'ordinateur.
Cela signifie que lorsque le Contexte existe dans une page web, un formulaire, l'interface d'un logiciel local ou d'un système back-office, et non dans une API structurée, Claude peut aussi y accéder via la GUI, observer l'état et exécuter des opérations.
Un mois plus tard, Anthropic a publié le MCP (Model Context Protocol). Ce protocole ouvert connectant les assistants IA à des outils externes et des sources de données est défini officiellement comme le fait de connecter l'assistant IA aux "systèmes où résident les données", y compris les bibliothèques de contenu, les outils métier et les environnements de développement.
Sa valeur réside dans le fait qu'il permet à Claude de ne plus dépendre du copier-coller de l'utilisateur, mais de pouvoir accéder via un moyen standardisé à des outils et sources de données externes.
Ces deux types de capacités correspondent aux deux voies d'acquisition du Contexte par Anthropic :
Computer Use entre dans l'interface via la GUI, MCP connecte les systèmes via le protocole. L'un entre sur le lieu de la tâche, l'autre interconnecte les outils externes, permettant ensemble à Claude d'obtenir un Contexte dynamique.
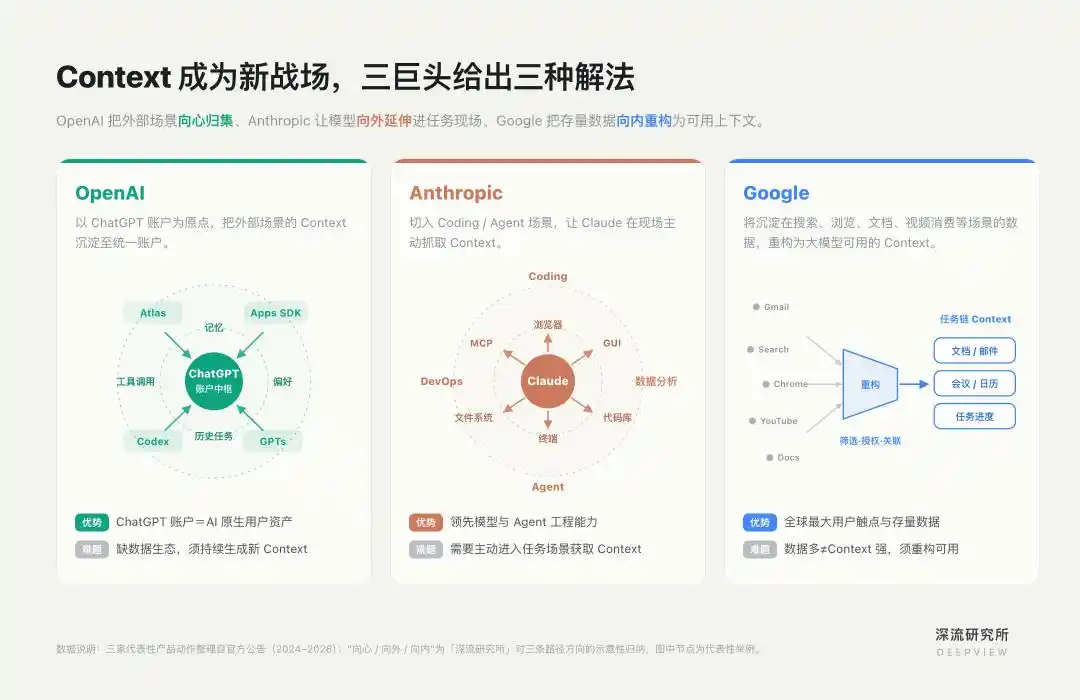
Regardons maintenant Google. On dit souvent que Google est l'une des entreprises possédant le plus de Contexte. Il ne manque pas de points d'entrée, ni de données. Chrome, Gmail, YouTube, Search et autres produits constituent l'un des plus grands points de contact utilisateur au monde.
Mais du point de vue de l'IA, avoir beaucoup de données n'équivaut pas à avoir un Contexte fort.
Les données accumulées par Google dans le passé concernent la recherche, la navigation, les emails, les documents, la localisation, la consommation vidéo, etc., servant principalement au classement des recherches, au ciblage publicitaire, à la recommandation de contenu et à la collaboration bureautique. Elles sont essentiellement des signaux comportementaux nécessaires au fonctionnement du système.
Or, un Agent a besoin d'un contexte de tâche compréhensible, raisonnable et invocable par le modèle.
Ce n'est que lorsque le modèle peut juger quelles informations sont pertinentes pour la tâche en cours, lesquelles sont obsolètes, lesquelles peuvent être invoquées, et comment ces informations sont liées entre elles, que les données deviennent véritablement un Contexte.
Google ne fait pas face à un simple "accès aux données", mais à une reconstruction des données. Il doit filtrer, relier, autoriser à nouveau les anciennes données dispersées dans différents produits et servant différents objectifs système, pour les transformer en contexte personnel utilisable par Gemini.
La difficulté de cet ingénierie n'est pas moindre que celle pour OpenAI de sédimenter un nouveau Contexte, ou pour Anthropic d'entrer sur le lieu de la tâche.
Ces deux dernières années, les actions produit de Google n'ont pas consisté à repartir de zéro, mais à transformer de l'intérieur ses positions existantes. Le cœur de cette voie est d'organiser des données fragmentées en chaînes de tâches.
En mai 2024, Gemini 1.5 Pro est entré dans la barre latérale de Workspace, permettant au modèle d'invoquer d'abord le contexte actuel dans des scénarios de travail comme Gmail, Docs, Drive.
En juillet 2025, l'application Gemini a commencé à connecter des outils comme Gmail, Drive, Calendar, étendant le Contexte d'une application unique à des tâches transversales.
En janvier 2026, Personal Intelligence a lancé une version bêta, intégrant davantage les données personnelles comme Gmail, Photos dans le contexte personnalisé de Gemini.
La stratégie Contextuelle de Google n'est pas "nous avons beaucoup de données, donc nous sommes naturellement en avance".
Ce qu'elle doit réellement accomplir, c'est un chantier d'ingénierie de "mise à disposition des données" : transformer les données comportementales sédimentées par le passé, qui servaient des objectifs système comme la recherche, la publicité et la recommandation, en un Contexte compréhensible, autorisable et actionnable pour l'ère de l'IA.
3. De l'"échelle du réseau" à la "profondeur individuelle", les douves de l'ère de l'IA changent
Ces deux dernières années, OpenAI, Anthropic et Google ont tous accéléré la sédimentation et l'exploitation du Contexte, et ont construit autour de lui des capacités d'acquisition, d'organisation et d'invocation, tentant de former de nouvelles barrières concurrentielles.
Mais un changement en apparence paradoxal se produit simultanément : cette année, les trois entreprises ont, d'un commun accord, rendu la Mémoire transparente, explicable, voire transférable.
En mars 2026, Anthropic et Google ont successivement lancé Memory Import, permettant aux utilisateurs de transférer leurs souvenirs entre ChatGPT, Gemini et Claude.
Peu après, OpenAI a introduit Memory Sources, permettant à l'utilisateur de voir quels souvenirs, quelles conversations historiques ou quelles sources de données externes sont invoqués derrière une réponse personnalisée.
Si le Contexte est l'actif le plus important de l'ère de l'IA, pourquoi les plateformes commencent-elles à ouvrir ses droits d'accès ?
La réponse est que Memory Import n'ouvre en réalité qu'un Contexte de surface : les préférences utilisateur, les résumés de souvenirs historiques, les versions compressées de l'historique des conversations.
Ces informations sont hautement structurées et facilement décrites en langage naturel. Les transférer ne présente pas une barrière technique élevée.
Ce qui est vraiment difficile à transférer, c'est un autre type de Contexte : l'état de la tâche, les autorisations d'outil, l'accès aux systèmes d'entreprise, les retours en temps réel du lieu d'exécution.
Ces Contextes sont profondément intégrés aux produits et environnements système, et ne peuvent être déplacés de manière complète par une simple incitation textuelle (prompt).
Cela montre aussi que la logique concurrentielle de l'ère de l'IA diffère de celle de l'ère Internet.
La forme basique d'Internet est le réseau. Il connecte les personnes, les contenus, les marchandises, les services et l'information en nœuds. Plus les nœuds sont nombreux, plus les connexions sont denses, plus le produit a de la valeur. Ainsi, la douve la plus forte de l'ère Internet est l'effet de réseau, la valeur venant du fait que plus de personnes l'utilisent.
La forme basique de l'IA se rapproche davantage d'un nouveau type d'ordinateur, ou d'un nouveau système de traitement de l'information.
Sa valeur première n'est pas de connecter plus de personnes, mais de comprendre l'information, traiter des tâches, invoquer des outils et accomplir des actions. Une IA, même si elle ne sert qu'un seul utilisateur, peut potentiellement créer une énorme valeur.
Par conséquent, les douves de l'ère de l'IA sont en train de passer, sur la base de "l'échelle du réseau", à une "profondeur individuelle". Cette barrière de "profondeur individuelle" provient principalement de trois niveaux :
Premièrement, l'effet cumulatif ("intérêts composés") du Contexte. Chaque fois que l'IA accomplit une tâche, elle comprend mieux les habitudes d'expression, les critères de jugement, les sources d'information et les flux de travail de l'utilisateur. Lors de l'exécution suivante, le coût de démarrage à froid sera donc plus faible.
Deuxièmement, l'intégration des autorisations et de la chaîne d'outils. Lorsque l'utilisateur autorise l'IA à accéder à sa boîte mail, ses documents, sa base de code, etc., l'IA n'est plus seulement un outil de questions-réponses remplaçable, mais entre sur le lieu réel de la tâche.
Troisièmement, la formation d'une relation de confiance. Plus une tâche est complexe et de haute valeur, moins l'utilisateur la confiera facilement à une IA inconnue. Seule une IA qui le comprend à long terme, connaît ses limites et peut poursuivre le contexte a des chances d'être autorisée à exécuter l'étape suivante.
Si les produits Internet se disputent l'entrée de l'attention, alors les produits d'IA se disputent l'entrée de la tâche.
Une fois qu'une IA entre de manière continue dans le flux de travail de l'utilisateur, accumule le contexte et obtient des droits d'exécution, le coût de migration n'est pas seulement de changer d'application, mais de reconstruire une relation de tâche basée sur la compréhension, l'autorisation et la confiance.
Les changements des produits chinois peuvent aussi être compris dans cette logique.
Prenons l'exemple de Tencent. À l'ère Internet, il a accumulé des chaînes relationnelles, du contenu, un écosystème de services et des points d'entrée à haute fréquence ; à l'ère de l'IA, la valeur de ces actifs réside précisément dans la possibilité de les réorganiser en un Contexte compréhensible, invocable et exécutable par un Agent.
Que ce soit WorkBuddy accédant à des scénarios de travail comme les documents, les réunions, WeChat Work, ou WeChat "Xiaowei" essayant d'invoquer des mini-programmes et services dans l'écosystème WeChat, l'essence est de transformer le contenu, les relations et les processus qui servaient originellement l'humain, en un environnement de tâche où l'IA peut entrer.
Comme l'a jugé Yao Shunyu, scientifique en chef de l'IA chez Tencent : le Contexte, en apparence un actif de données, est en réalité une manifestation intégrée des capacités produit, des capacités d'ingénierie et des capacités de coordination organisationnelle.
À l'ère Internet, les douves regardaient l'échelle. À l'ère de l'IA, les douves devraient davantage regarder l'efficacité de conversion :
Celui qui peut convertir plus vite son écosystème existant en environnement de travail pour l'IA, celui qui permet à l'IA d'accumuler une compréhension plus profonde de l'utilisateur à chaque tâche, a plus de chances d'établir de nouvelles barrières.
C'est aussi là que réside l'intérêt véritablement digne d'attention de la guerre du Contexte.
Cet article provient du compte WeChat officiel "Deep Flow Research Institute" (深流研究所), auteur : Jiang Feng (绛枫)






