亮点
- 随着交易所流入量的增加,Pi Network 价格面临大幅崩盘的风险。
- 投资者在过去 24 小时内向交易所净转移了 200 万个 Pi 币。
- Pi 币已形成看跌旗形形态,预示着进一步下跌。
5月26日,即使比特币价格回升至11万美元以上,Pi Network的价格依然面临巨大压力。该代币交易价格为0.7752美元,较本月最高价下跌逾53%,成为表现最差的主要加密货币之一。随着投资者将200万枚Pi币转移到交易所,Pi币价格面临大幅下跌的风险。
Pi Network 价格技术分析指向更深层次的探讨
八小时图显示,Pi 的价值在 5 月 12 日飙升至两个月高点 1.6692 美元后遭遇大幅逆转。尽管比特币徘徊在历史高点附近,但它已下跌超过 53%,至目前的 0.7773 美元。
Pi 币的价格略低于 50 周期指数移动平均线 (EMA) 的 0.7910。它还形成了一个看跌旗形形态,这种形态发生在资产价格暴跌后盘整或在通道形态中向上移动。
它已经跌破了该形态旗形部分的下沿。因此,该货币存在跌至5月17日最低点0.6584美元的风险。跌破该水平将意味着进一步下跌,可能跌至本月低点0.5545美元,较当前水平下跌30%。
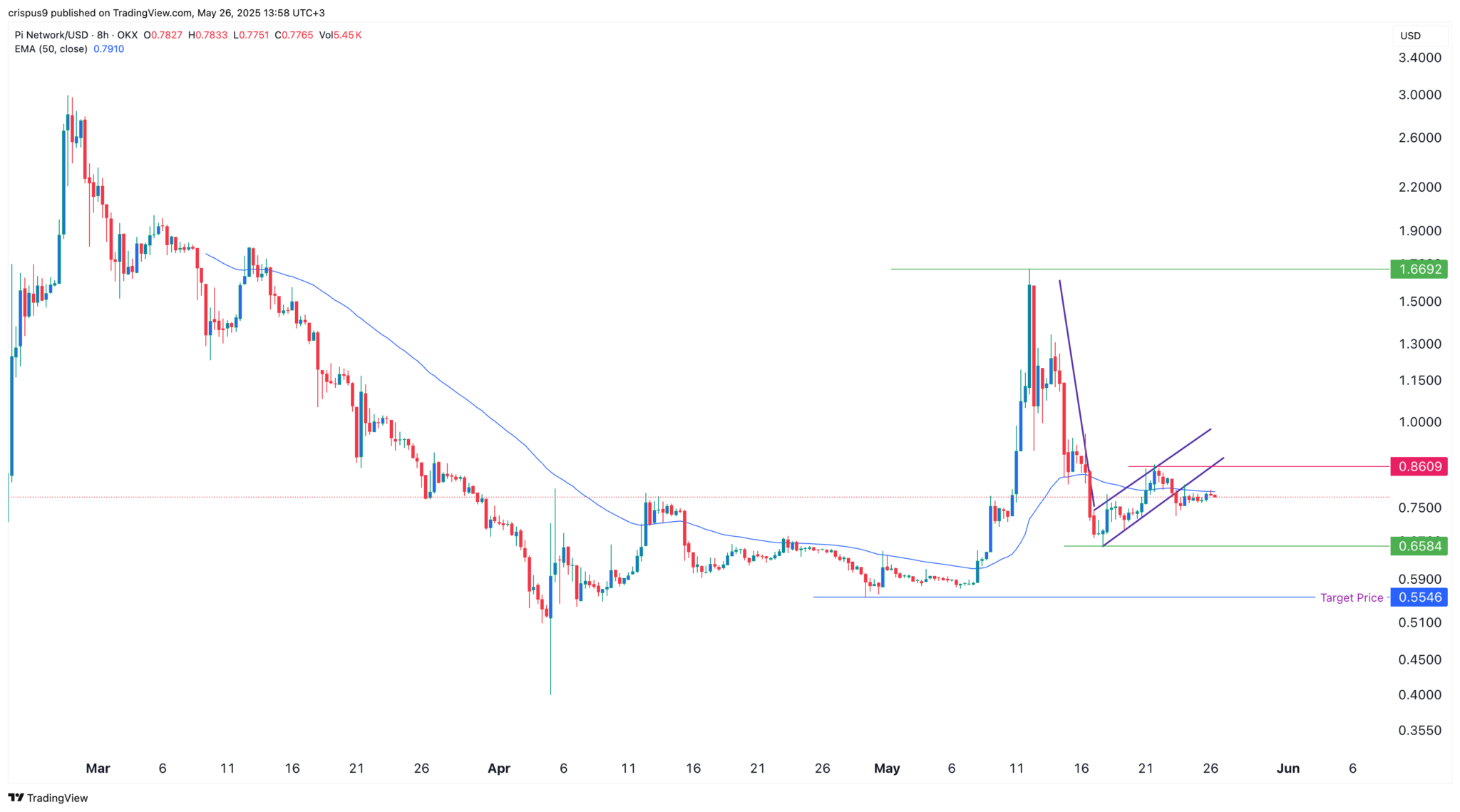
如果Pi 币价格突破上周最高点 0.8600 美元,那么看跌Pi 币价格的预测将失效。突破该水平将预示着进一步上涨,甚至可能触及 1 美元的心理关口。
随着交易所流入量的增加,Pi 币价格可能暴跌
PiScan数据显示,随着投资者将代币转入交易所,Pi Network的价格可能面临大幅下跌的风险。过去24小时内,投资者向OKX转入了410万枚代币,而提现量为220万枚,净流量达到188万枚。
Bitget 净流入 712,097 枚,Pionex 净流入 2,176 枚。过去 24 小时内,只有 MEXC 和 Gate 出现净流出。总计交易所总流入量超过 204 万枚。
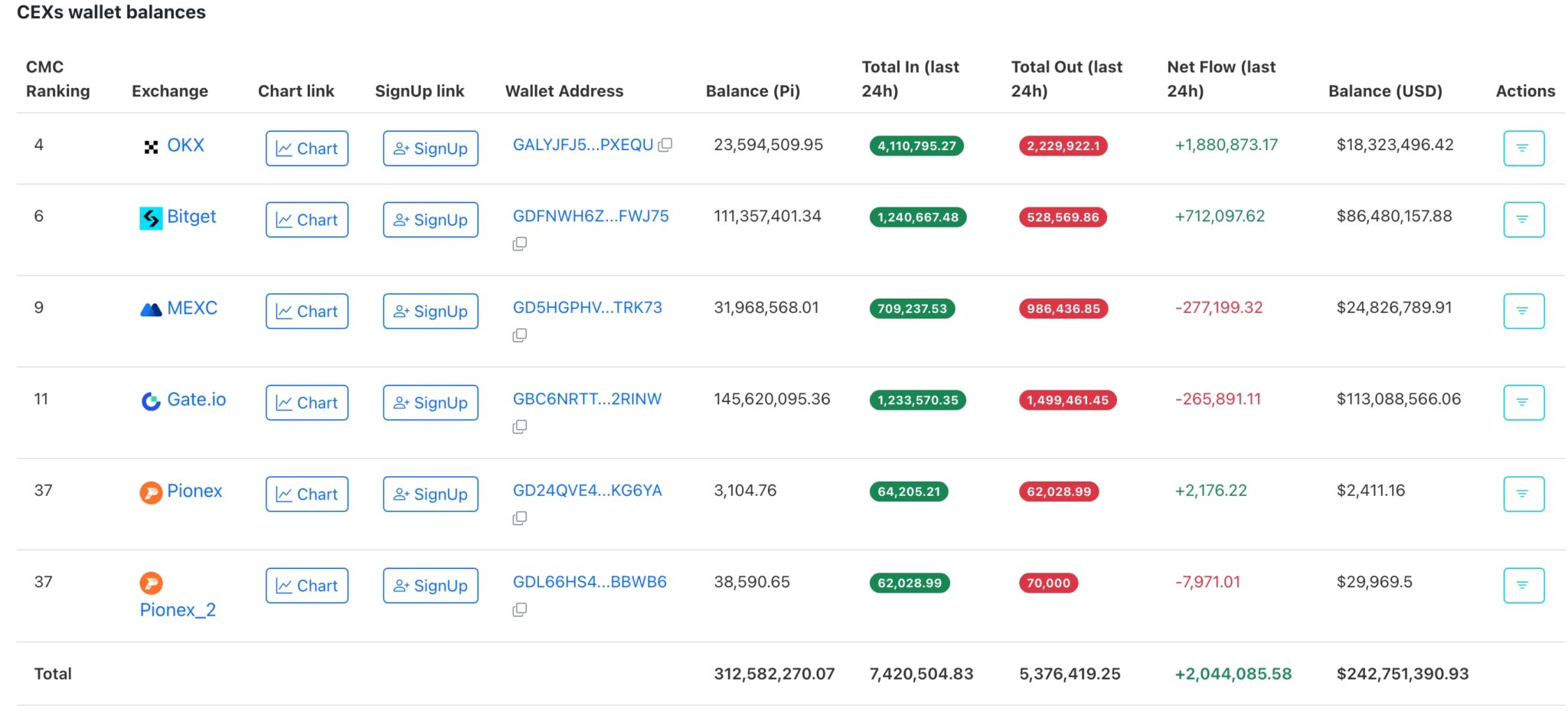
交易所资金流入是加密货币分析中最危险的信号之一。这是因为它表明投资者正在将加密货币从自托管钱包中转移并出售。这些数据表明,在近期暴跌之后,对加密货币的需求仍然有限。
由于本周将有更多代币解锁, Pi 币价格本周可能继续下跌。今天将解锁 990 万枚 Pi 币,未来三天将分别解锁 1200 万枚、1520 万枚和 1320 万枚。本周将有超过 7200 万枚、价值超过 5000 万美元的 Pi 币上线,未来 30 天内将有 2.8 亿枚 Pi 币上线。
由于目前流通量为111亿,而发行上限为1000亿,这种解锁趋势将持续一段时间。如果另一方没有相应的需求,这些解锁可能会影响其价格。如需详细了解Pi币2025-2023年的价格预测,





