Когда на рынках начинается качка, золото, как водится, лезет в топ. Инвесторы, почуяв неладное, тут же пытаются перелиться в надежный актив — и снова вспоминают про «жёлтый металл». Но фишка не только в привычных слитках — на сцену вышли его цифровые двойники. Да, золото теперь на блокчейне.
Цифровые активы вроде Paxos Gold (PAXG) и Tether Gold (XAUT) подросли уже больше чем на 23% с начала года. И народ переливает свои средства туда, ища спокойствия в хаосе. Эти токены прикручены напрямую к настоящему золоту — их курс двигается вместе с ценой на металл. Поэтому они смотрятся куда симпатичнее в нестабильные времена.
В начале года и PAXG, и XAUT вышли на новые исторические хаи — выше $3,300, прежде чем слегка подсползти. А биток, тем временем, сдал на больше чем 11%, и в целом крипторынок сел на минус 30%, если верить индексу CoinDesk 20.
При такой лихорадке не удивительно, что всё больше игроков перебегает в токенизированное золото, чтобы хоть как-то защитить свои вложения.
Особо помог тут и свежая партия пошлин от Трампа, который тряхнул традиционные рынки и добил крипту. Но золото, как ни странно, держится крепко. Золотые ETF-ы тоже не подвели — остались на плаву.
Почему PAXG и XAUT так заходят? Потому что это сразу и надёжность настоящего золота, и шарм цифрового актива. Они стопроцентно подкреплены настоящим золотом, которое лежит в надёжных хранилищах. Но в отличие от классических слитков, эти токены можно гонять по блокчейну почти моментально. Гибкость в движениях и проверенная ценность — два в одном.
На фоне нового витка напряжёнки между США и Китаем, плюс общих страхов за глобальную экономику, инвесторы снова начинают искать, как бы пересидеть бурю. Золото всегда было тем самым «запасным аэродромом», а теперь ещё и с цифровым апгрейдом — удобно и в духе времени.
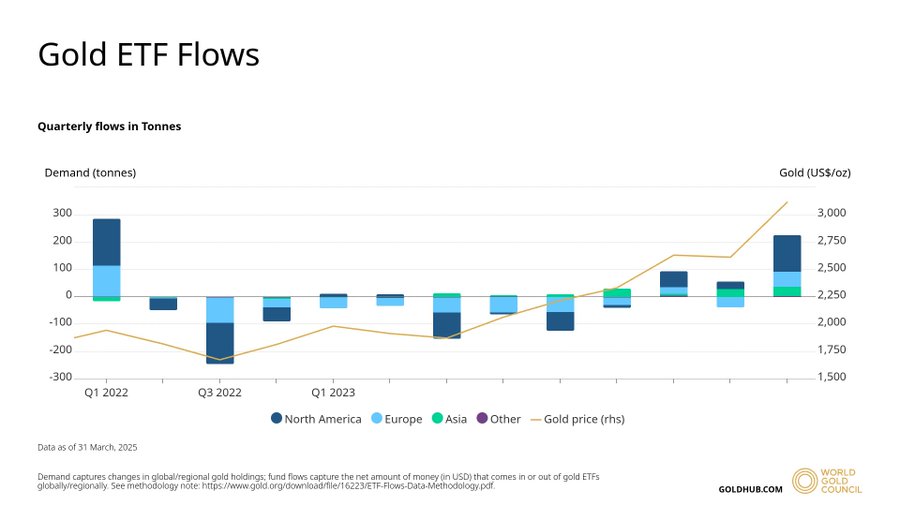
Но не только блокчейн-версии золота на подъёме — и старые добрые ETF-ы в топе. За первый квартал 2025 года в них влетело 226,5 тонны — максимум за три года, по данным Всемирного совета по золоту. Почти 60% спроса — это Северная Америка. То есть тренд очевидный: народ выходит из рисковых активов в то, что не падает на каждом твите президента США.
А ещё интерес к токенизированному золоту подогревается резким ростом новых выпусков. Только за первый квартал было намайнено больше $42,7 млн в токенах PAXG и XAUT — по данным RWA.xyz. Это подняло общую капитализацию этих активов почти до $1,4 миллиарда.
С учётом того, что и традиционный, и крипторынок в лихорадке, токенизированное золото стало тем самым «планом Б» — надёжным и при этом гибким.