经过 11 天的运营(包括短暂的停机时间),memecoin 平台 SunPump 已帮助创建了超过 18,000 个代币。
Tron 区块链上的新 memecoin 部署平台 SunPump 自首次推出以来的 11 天内已创造超过 110 万美元的收入。
根据网络分析平台 Dune 的数据,自 8 月 9 日推出以来,孙宇晨支持的平台总收入为 700 万 Tron
到目前为止,SunPump 最大的收入日是 8 月 20 日,收入近 278 万 TRX,相当于 40 万美元,创造了 6,000 多个 memecoin
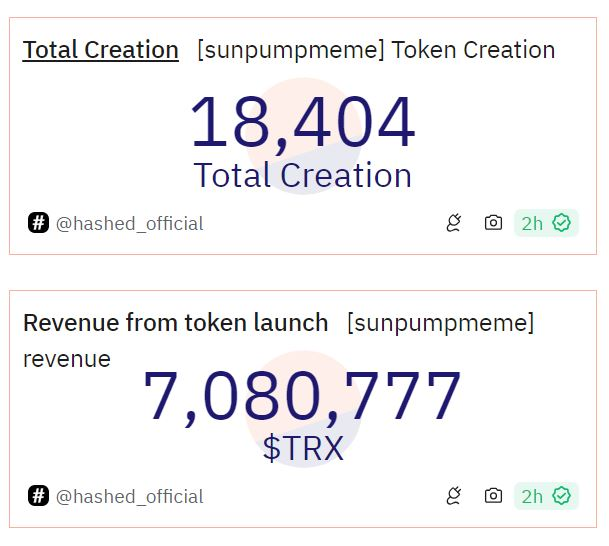 SunPump 运营 11 天后收入已超过 100 万美元。来源:Dune
SunPump 运营 11 天后收入已超过 100 万美元。来源:Dune
在 8 月 20 日的 X 帖子中,Sun 表示 SunPump 在“遭遇前所未有的流量”后瘫痪,开发人员正在“紧急扩大规模”以恢复服务,该平台在大约一小时后恢复上线。
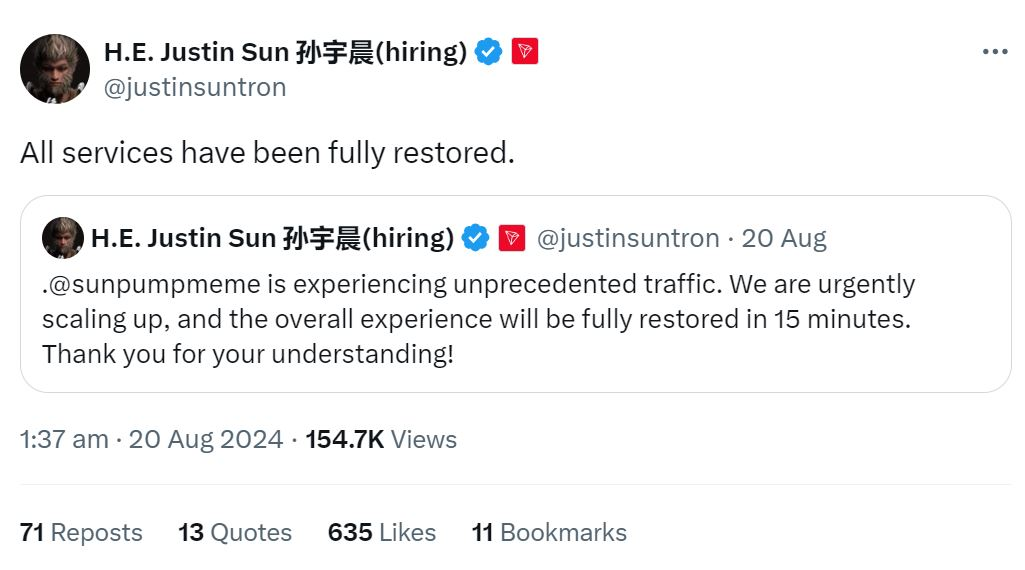
来源:孙宇晨
自 SunPump 推出以来,在 Sun 的 Meme 生态系统促进激励计划提供的 1000 万美元拨款的帮助下,流动性一直流入 Tron 区块链。
稳定币发行商 Tether 还于 8 月 20 日在 Tron 区块链上另外铸造了 10 亿个Tether(USDT )代币。
DefiLlama 的数据显示,Tron 在过去 24 小时内创造了 217 万美元的收入,比前一天 106 万美元增长了一倍。
关于 memecoin 价值的争论仍在继续
由于基于 Solana 的 memecoin 交易量下降,并且最近有争议的数据显示,Solana memecoin 启动平台 pump.fun 上的大多数交易者都亏损,怀疑论者对memecoin 对加密货币行业的价值提出了质疑。
自今年 1 月份推出以来,已有超过 170 万个代币通过 pump.fun发行,其中不到 1.5% 的总价值超过 63,000 美元。
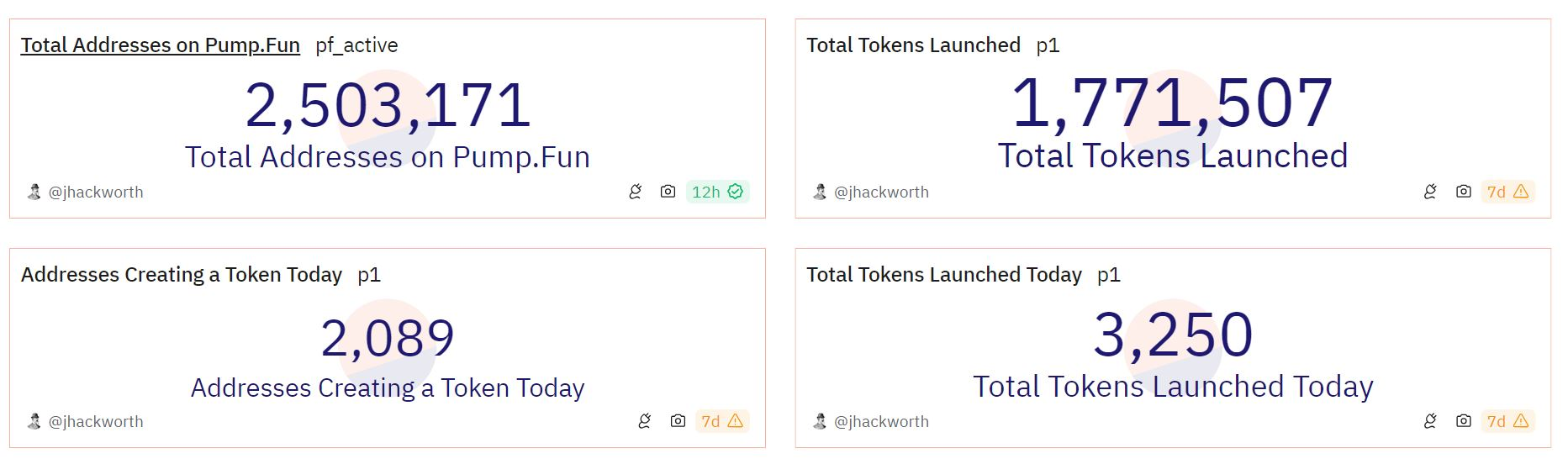
Pump.fun 自推出以来已促成了超过 170 万个 memcoin 的创建。来源:Dune
在 8 月 13 日加拿大未来学家会议的小组讨论中,Appchain Noble 首席执行官 Jelena Djuric表示,尽管 memecoin 季节仍在向前发展,但她对其寿命表示怀疑。
Messari 数据工程师 Mike Kremer 在 8 月 19 日的新闻通讯中表达了类似的观点,声称 memecoin 具有“破坏性动态”,因为许多人看到它们的价格膨胀,导致内部人员抛售代币,使其失去任何实际价值或效用。
与此同时,孙宇晨仍然看好memecoin,他在 X 上发文称,他认为memecoin 的成功“并非偶然”。
孙宇晨写道:“当每个开发者都能够通过公平发布建立一个社区,获得所有人的支持,并培养热情和忠诚度时,社区就可以分享加密货币的成功。”
去中心化发行平台 BullPerks 的联合创始人 Constantin Kogan 也认为memecoin 在加密货币领域发挥着重要作用,称其为“该领域增长最快的行业”之一。





