原创 | Odaily星球日报
作者 | Azuma

最近几天,围绕着 zkSync 即将发币并空投的猜测甚嚣尘上。
究其缘由,除了一些团队成员在社交媒体上持续不停的谜语发言之外,最大的“线索”则是有社区成员在 Matter Labs 近期更新过的 Github 代码库内发现了“zkPorter 已可用”(zkPorteris available)的字样。
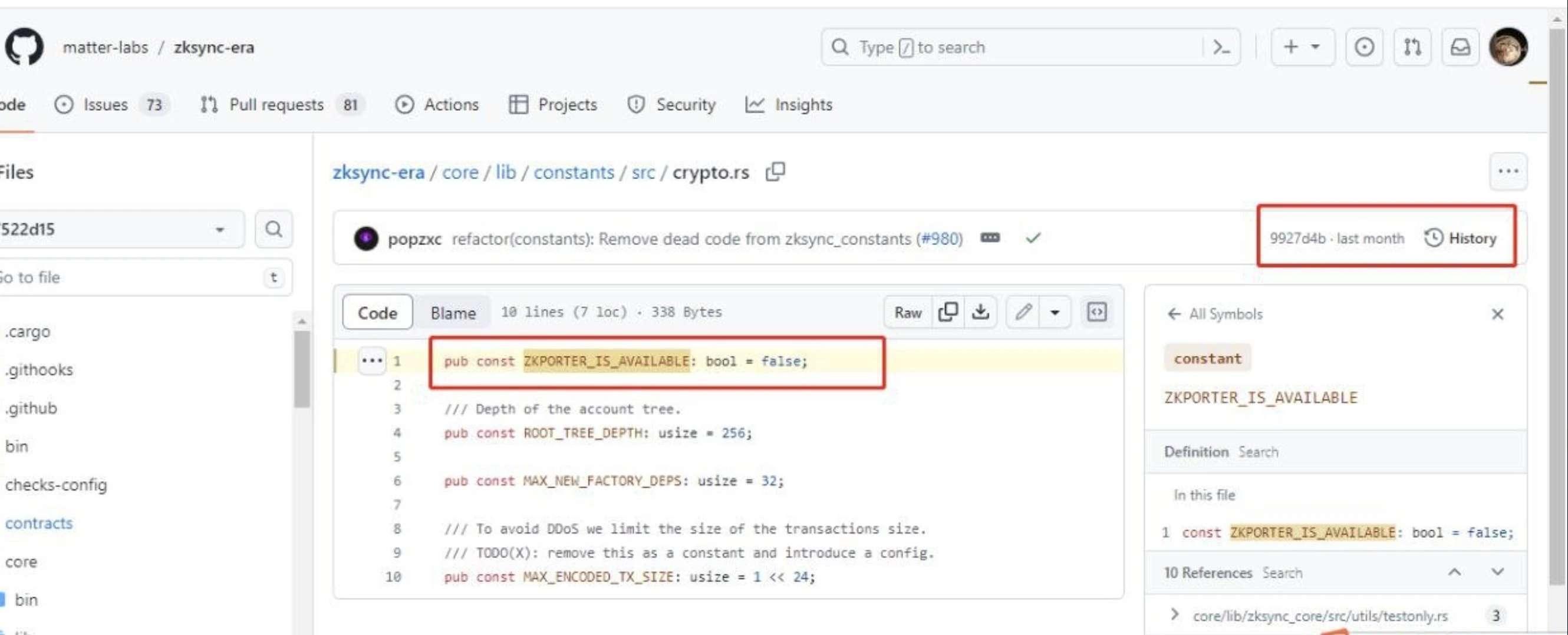
随后,在 X 上拥有逾 8 万粉丝的 Ethereum Daily 以“zkPorter 已可用”为根据,在 X 上发布了一则内容为 “准备好迎接 ZK Endgame 了吗”的推文,并配上了暗示空投可能性的“降落伞”图样。
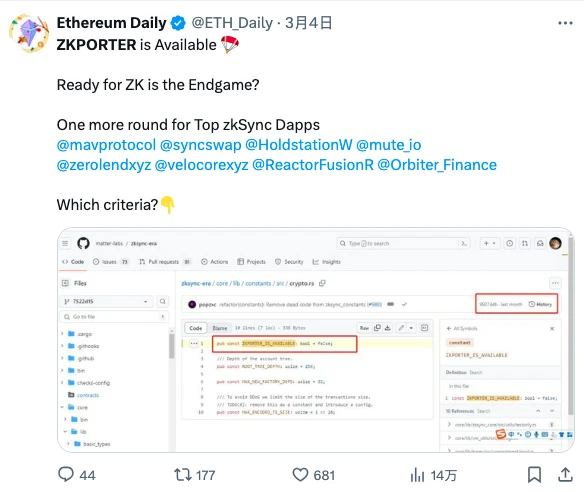
或是由于看到了 zkPorter、Endgame 等关键词,zkSync 创始人 Alex Gluchowski 随后转发了 Ethereum Daily 的推文,此举也一度被社区视作 Alex 承认了 zkSync 即将进行空投,但或许是后来又意识到了该行为存在较大的诱导性质,Alex 随后又撤销了对该条推文的转发。
综合上述信息,本轮针对 zkSync 空投猜测的主要依据聚焦于 zkPorter 之上,那么 zkPorter 究竟是什么呢?为什么说 zkPorter 的上线会与 zkSync 的代币挂钩?
zkPorter 的首次亮相可追溯至 2020 年 8 月,Matter Labs 当时提出了该项基于 zkSNARK 的全新扩容技术,希望通过更灵活的数据可用性(DA)来帮助 Layer 2 实现更明显的扩容效果。
在 2021 年的一篇详解 zkPorter 的文章中,Matter Labs 曾提到,Rollup 只能提供线性增长的扩容效果,因为所有数据仍然需要被广播至所有的完整节点,但为了迎接海量的用户增长,业界需要实现指数级增长的扩容效果。
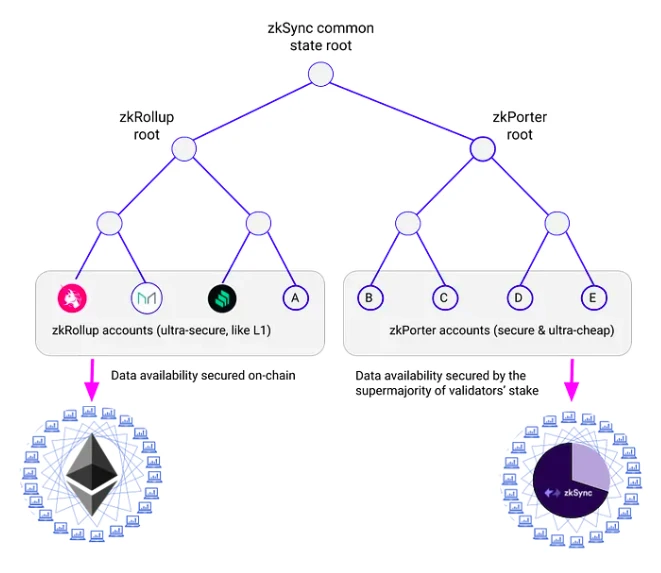
为此,Matter Labs 设计了一个安全性介于 zkRollup 与 Optimistic Rollup 之间,但可实现超 20000 TPS 的全新扩容解决方案,即本文的主角 zkPorter。
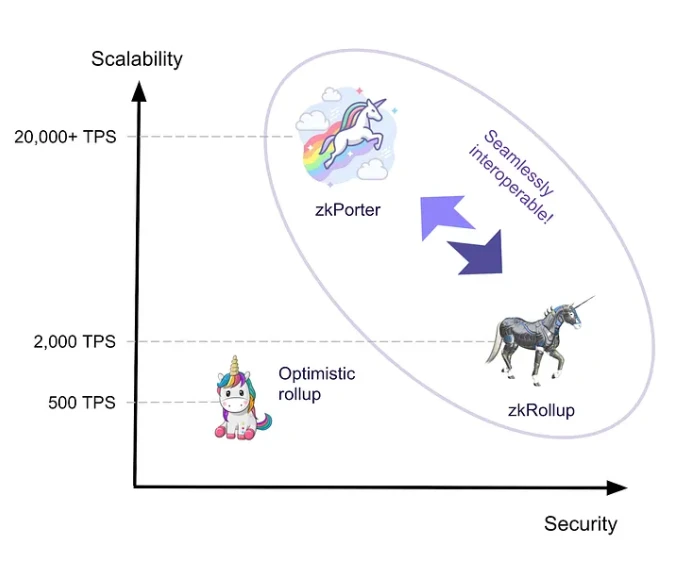
与采用了 zkRollup 解决方案的 zkSync Era 一样,zkPorter 同样支持 EVM,二者的合约和账户也能够无缝交互。
二者之间的核心区别在于,zkPorter 会将数据可用性置于链下(以太坊之外),从而解放了来自于数据需广播至完整节点的限制,也可大幅降低交易所需的 gas 成本 —— 可将数千笔交易打包成一次更新发布至主网。
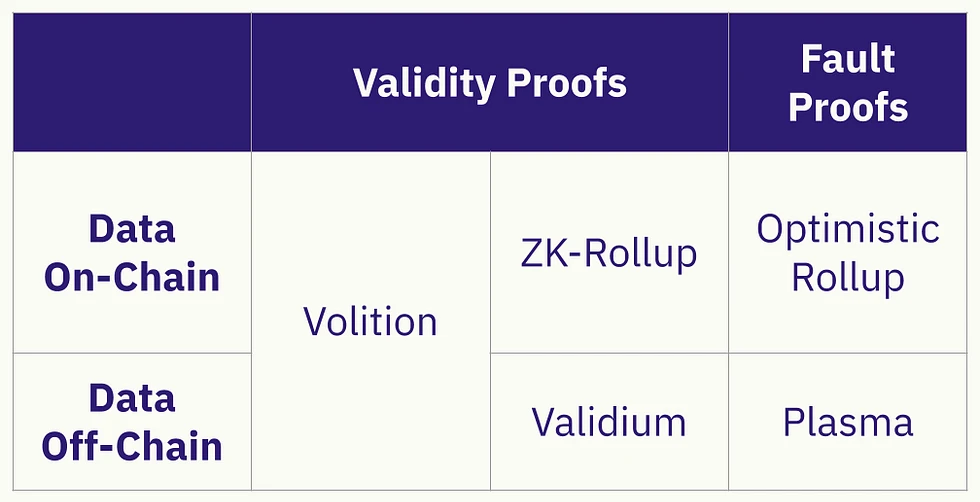
从早年间的 Layer 2 定义来看,zkPorter 在解决方案上应归属为 Volition,更适用于那些在经济效应上不适合以太坊主网或传统 Rollup 的高并发项目。
关键性的设计来了,为了确保 zkPorter 的稳定,zkPorter 的数据可用性需要由 zkSync 代币持有者(在此被称监护人)保证。监护人可使用 zkSync 代币参与 PoS 证明,通过签署区块来跟踪 zkPorter 端的状态,以确认 zkPorter 帐户的数据可用性。
这也是为什么,社区会将“zkPorter 已可用”这一信息与“zkSync 即将发币”挂钩。
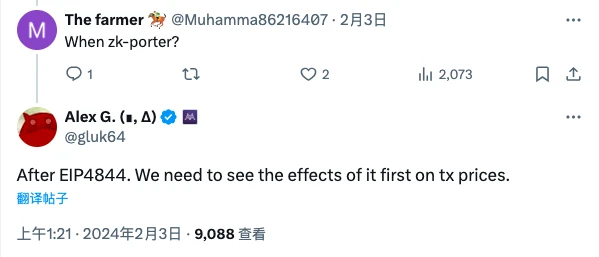
那么,zkPorter 到底什么时候会上线呢?Alex 本人今年 2 月曾在回复社区提问时提到会在 EIP-4844 执行之后,因为需要观察该升级对交易费用变化的潜在影响。鉴于 EIP-4844 (Proto-danksharding)将于 3 月 13 日的 Dencun 升级中执行,因此可预计距离 zkPorter 也不会太远了。
最后需要强调的是,与广大社区一样,我们也不知道 zkSync 具体的发币与空投规划,上述关于 zkPorter 的上线时间也仅有一个单向范围,无法提供更为精准的猜测。
基于安全和稳定考虑,Matter Labs 只会在一切准备就绪后才会推进相关动作,所以在 EIP-4844 之后不排除还会有一段时间的观察、测试周期。
“福报”终会到来,还请耐心等待。





