原文作者:CapitalismLab
Magpie 针对 LRT 的 subDAO @Eigenpiexyz_io 今天开启了积分活动,这是目前为止 LRT 项目中给 TVL 提供者最大蛋糕的,项目有特色外加此前 Magpie 的 subDAO 有着不菲的收益,配置价值恒奥。
本 Thread 将分析 Eigenpie 的空投玩法,机制,前景,和收益预期,帮你明明白白地取得最大化收益。

A. 空投玩法
当前存 stETH 等 LST 进去可以获取三重收益:
Eigenpie 积分,对应总量 10% 的空投
Eigenlayer 积分 ( 2 月 5 日 Eigenlayer 开放存款后)
Eigenpie 对应总量 24% IDO 份额, 3 M FDV 低估值
所存 LST 的基础收益(比如 mETH APR 是 7% 那你可以继续享受 7% )
积分会根据车队总规模提供增益,越大的车队增幅越大,最高两倍,所以最好抱团取暖。
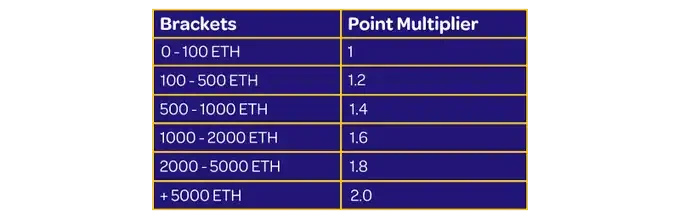
B. 机制
Eigenpie 做的是为 isolate LRT(ILRT),每个 LST 发一个对应的 Token 隔离风险,参见下表
当前 Eigenlayer 上了这么多 LST,如果一个 LRT 项目笼统接受的话,那么这个项目要承担所有底层 LST 的风险,一旦某一个 LST 出现安全问题可能就会对其造成毁灭性的打击
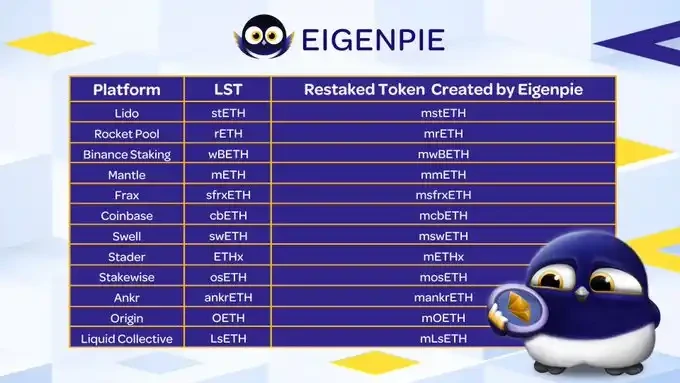
所以就有了 Eigenpie 的 ILRT 可以隔离风险
隔离了风险也隔离了流动性,这是否会有问题呢?其实也不染,支持 LST 的 LRT 相比 支持 Native Staking 的 LRT,优势之一便在于可以充分利用底层 LST 的流动性。mrETH/rETH,mmETH/mETH 这些单独的 pair 其实更有利于和 LST 项目方合作激励流动性
C. 前景
这个项目有什么优势?毕竟发的的确晚了一些,但是目前的确有一块需求空缺尚未被填补:上了 Eigenlayer 的 LST 都迫切希望参与到 LRT 叙事中,而 Eigenpie 目前来看是最好的方案,每个 LST 又有独立的 LRT 不用担心给其他人做了嫁衣。像 mETH 这种利率更高的 LST,也可以继续发挥其优势。
Mint 出来的 mstETH 这些什么时候可以在 DEX 交易?是否会上 Pendle?
显而易见的是项目方有极大意愿和能力推进这些,无他,这些都可以带给 Magpie 旗下的 Cakepie,Penpie 这些 subDAO 丰厚的贿赂收益
如果你对 Magpie 的架构不了解的话,可以参考我们此前的推文。
D. 收益预期
收益这边我们先看下代币经济:
• IDO: 40%
• 空投: 10%
• 激励 35%
• Magpie Treasury: 15% (按照惯例不出售,staking 分红给 vlMGP)
基本是一个 FairLaunch 的操作,不同之处在于目前大部分 Fairlaunch 白名单内定比较多,而这个的 IDO 白名单大部分都明牌给 TVL 提供者
给到 TVL 提供者的权益是
总量 10% 的空投
60% 的 IDO 份额,IDO 占总量的 40% ,$ 3 M FDV 估值
就是说总量的 10% + 60% * 40% = 34% 都会给到 TVL 提供者,这占了初始流通的 34% / 50% = ~ 70% ,今后也没有 VC 抛压这些
目前 LRT 叙事非常火热,仅有 $ 7 M TVL 的 $RSTK 都有 $ 35 M mcap 和 $ 180 M FDV,目前已经发布其他几个项目的估值也非常之高
Eigenpie 最终的 TVL 多半会远高于 RSTK,如果按照 $RSTK 的 FDV 对标的话,TVL 提供者的总利润也可达: 10% * 180+ 60% * 40% *( 180-3)= $ 60 M
假设两个月后发币,平均 TVL 为 $ 200 M 的话,也是可以达到 ( 60/2)/200* 12 = 180% 的 APR,这还不包括底层 Eigenlayer points 的收益,在前 15 天作为早期提供者参与还有 2 倍的点数增幅
我们再看下此前 magpie 的 subDAO IDO 至今的涨幅
Penpie,IDO 3 M FDV, 14 倍
Radpie,两轮 IDO 平均 7.5 M FDV, 1.4 倍
Cakepie,IDO 20 M FDV, 2.4 倍
此番进军市场更大的 LRT 赛道,不但拿出了 3 M FDV,给到 TVL 提供者的空投和 IDO 份额均是当年 PNP 的数倍,不知收益是否会复刻甚至超越
总结:
1. 空投需要抱团取暖获取更大增幅,抱团链接:https://eigenlayer.magpiexyz.io/?ref=0x307225Bc52ef0fEDAa67b626996c0E74cEA924Ee
2. 特色机制为 ILRT 隔离各个 LST 的风险
3. 优势还有可以充分利用 Magpie 积累的 Pendle/Pancake 资源加速发展
4. 绝大部分权益明牌给到 TVL 提供者,IDO 额度透明的 Fairlaunch





