On March 18 and 19, two Chinese companies successively released their major models in the Agent direction. Domestic AI startup MiniMax launched M2.7, while Xiaomi's large model team MiMo introduced V2-Pro. Both models have entered the global top tier on the Agent benchmark, but their API output pricing is 1/21 and 1/8 of Claude Opus 4.6, respectively.
They played their cards in the same week, but with completely different hands. They represent two截然不同的 technical routes, betting on two different futures for the Agent era.
The Same Exam, 1/17 the Tuition
First, let's look at the most直观 comparison.
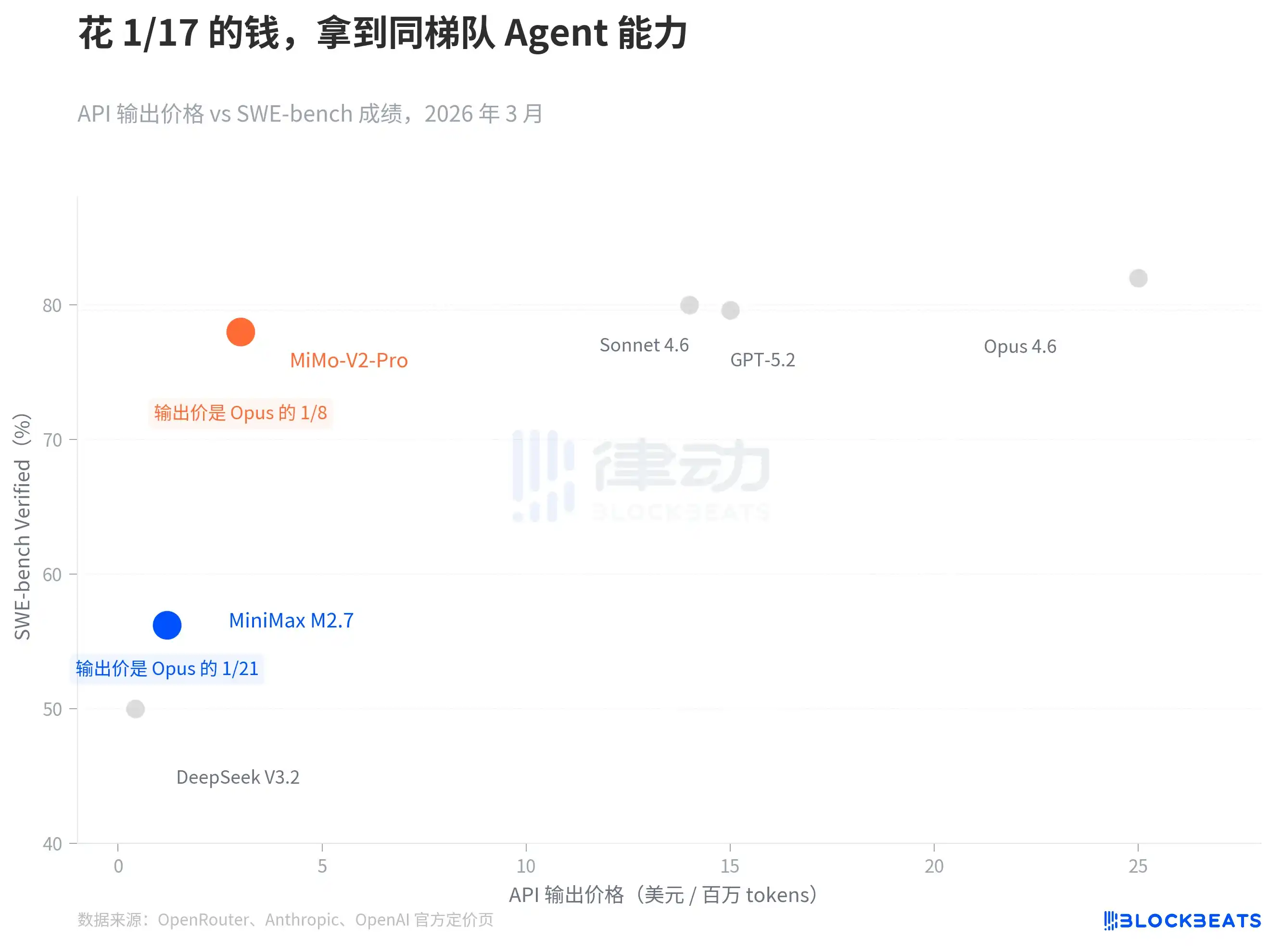
According to data from OpenRouter and the official pricing pages of various companies, based on API output price (per million tokens), MiniMax M2.7 is $1.2, and MiMo-V2-Pro is $3. As a reference, Claude Opus 4.6's output price is $25, GPT-5.2 is $14, and Claude Sonnet 4.6 is $15.
The price gap is by an order of magnitude, but the capability gap is not. On SWE-bench Verified (the current mainstream benchmark for measuring code engineering capabilities), MiMo-V2-Pro scored 78%, while Sonnet 4.6 scored 79.6%, a difference of less than two percentage points. M2.7's SWE-Pro score was 56.22%, on par with GPT-5.3-Codex. On VIBE-Pro (end-to-end project delivery capability), M2.7 scored 55.6%,接近 the level of Opus 4.6.
The key point of this chart is not who is higher or lower—the benchmark systems of various companies are not fully aligned, so direct comparisons should be made cautiously. The key point is that "price-performance剪刀差": domestic Agent models have already挤进 the same capability band but stand in completely different price ranges.
Trillion Parameters vs. Self-Evolution
Price is only the表象. The two companies have revealed two completely different底牌.
MiMo-V2-Pro follows the "more is better" route. According to Xiaomi's official announcement, V2-Pro has over 1 trillion total parameters, 42B activated parameters, and supports an ultra-long context of 1 million tokens. Its core innovation is the Hybrid Attention mechanism, adjusting the ratio of Sliding Window Attention (SWA) to Global Attention (GA) to 7:1—the previous generation V2-Flash was 5:1. This architecture makes the model more stable when handling long documents and multi-tool parallel calling Agent scenarios. On PinchBench (Agent tool calling capability evaluation), MiMo-V2-Pro scored 84%.
M2.7 takes a completely different path. According to the official technical blog released by MiniMax on March 18, M2.7's parameter count is not公开, but it demonstrates a "self-iterative evolution" mechanism: the model autonomously runs over 100 rounds of optimization cycles, including analyzing failure trajectories, planning modifications, modifying its own code architecture, running evaluations, and cycling again, ultimately achieving a 30% performance improvement on the internal evaluation set. On the MLE Bench Lite (machine learning competition difficulty evaluation) with 22 high-difficulty problems, M2.7 won 9 gold, 5 silver, and 1 bronze, with an average medal rate of 66.6%.
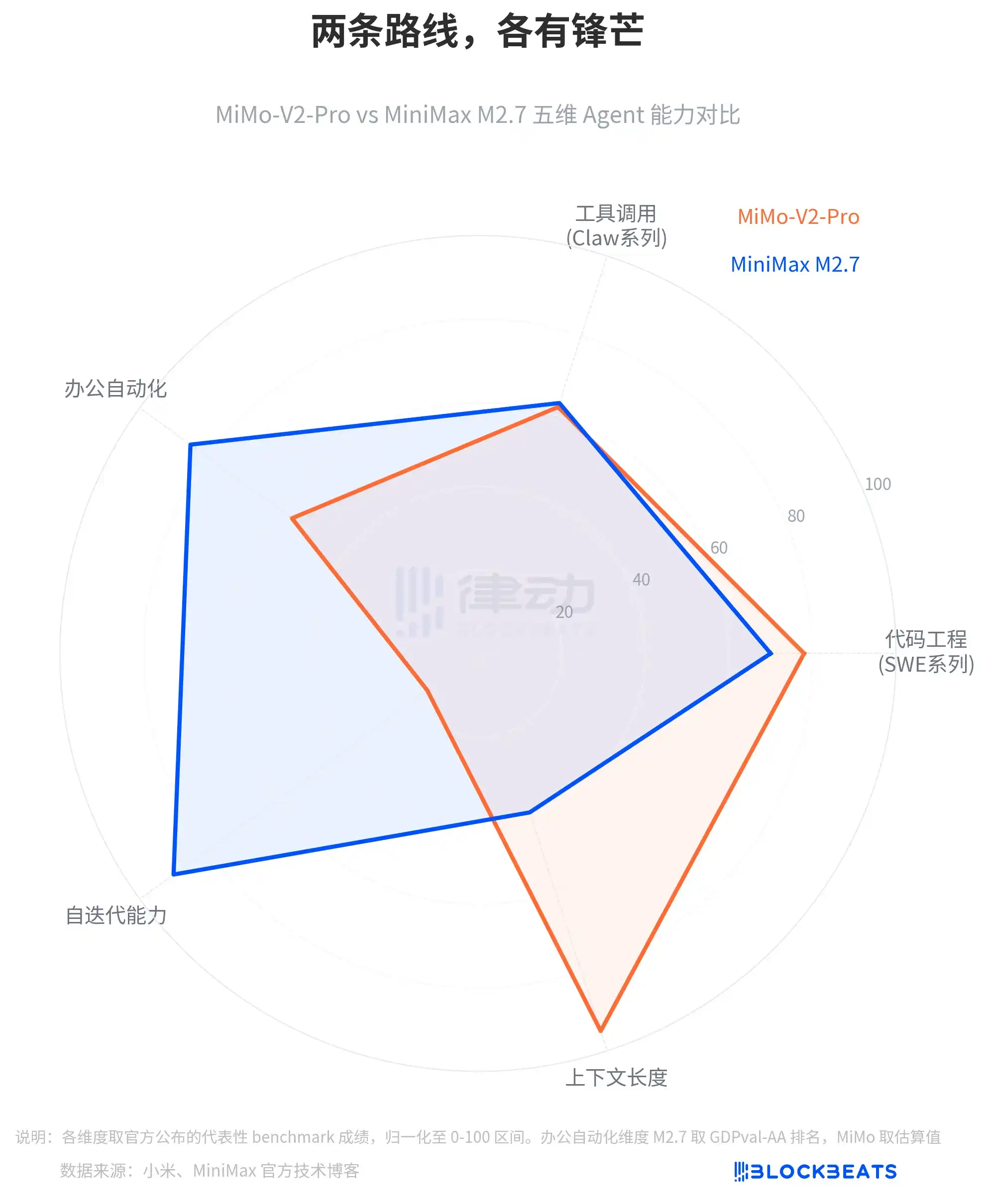
Looking from five dimensions, the锋芒 of the two routes朝向 completely different directions: MiMo-V2-Pro has obvious advantages in context length and code engineering dimensions, while M2.7 pulls ahead in office automation and self-iterative capabilities. According to the same MiniMax technical blog, M2.7 scored ELO 1495 on GDPval-AA (office document processing evaluation), ranking first among open-source models, and maintained a 97% skill adherence rate in the MM-Claw test covering over 40 complex skills.
Four Versions in Five Months
The two companies not only have different technical routes but also completely different iteration rhythms.
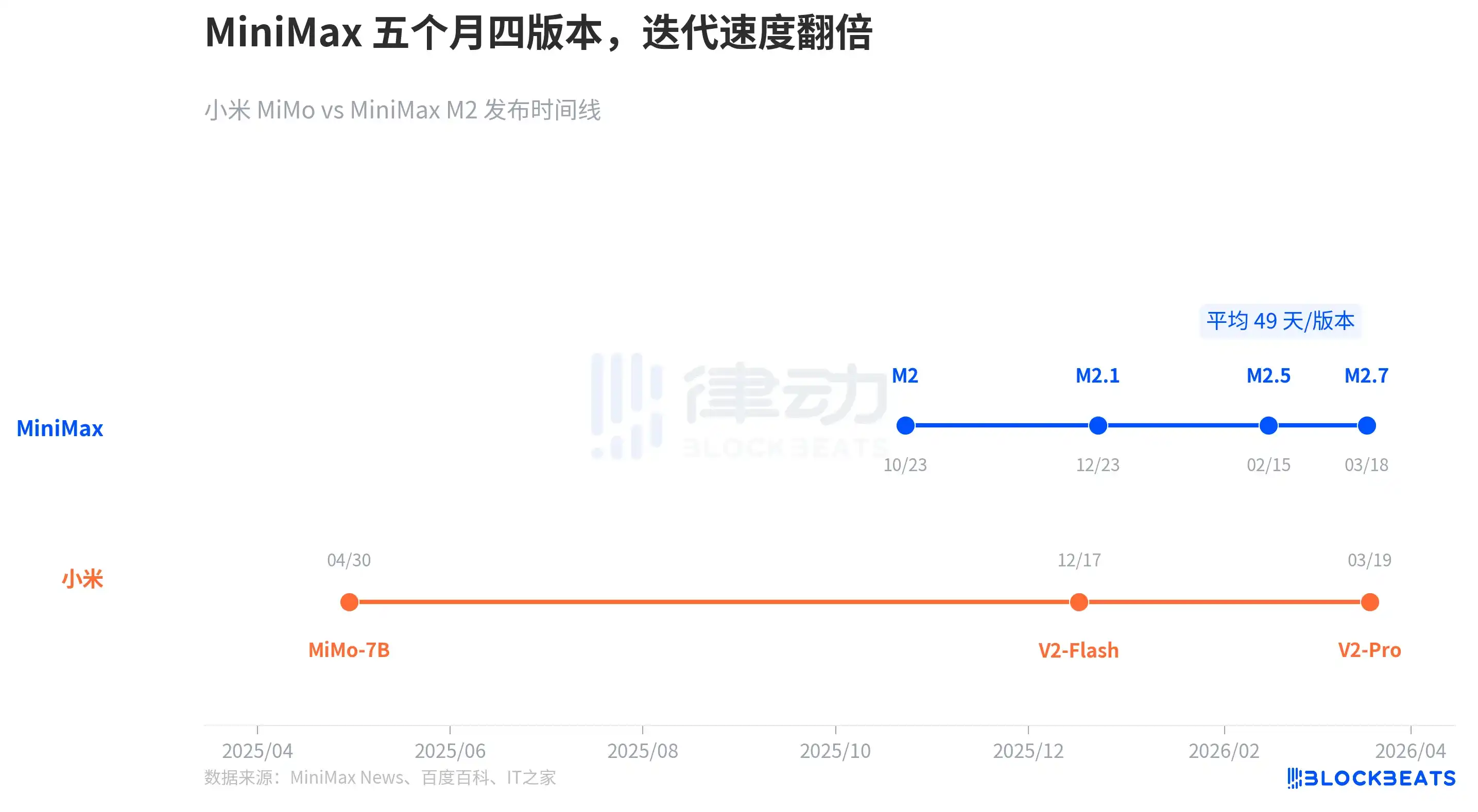
According to public release records, MiniMax iterated four major versions from the release of M2 in October 2025 to the release of M2.7 in March 2026—a new version every 49 days on average. The interval between M2.5 and M2.7 was only about 30 days.
Xiaomi MiMo's rhythm is different: MiMo-7B (a 7B parameter open-source inference model) was released in April 2025, V2-Flash (309B total parameters) in December 2025, and V2-Pro (1T total parameters) in March 2026. The parameter scale leap between each generation is larger, but the version intervals are also longer.
MiniMax chose small steps and quick runs, with small iteration amplitudes but extremely high frequency; M2.7's self-iterative mechanism is itself designed for "continuous evolution." Xiaomi chose蓄力一击, with each version representing a major leap in parameter scale and architecture.
Anonymous for 8 Days, Topping OpenRouter
Beyond the technical route, Xiaomi's release strategy also broke industry conventions.
According to a Reuters report, on March 11, an anonymous model named Hunter Alpha appeared on OpenRouter, the world's largest API aggregation platform. No brand endorsement, no launch event, no technical blog. Its API pricing was extremely low, yet its performance was surprisingly strong.
The community began speculating about its origin. According to Republic World and multiple tech media reports, the most mainstream guess was DeepSeek V4, as MiMo team leader Luo Fuli had previously conducted research at DeepSeek. Call volume surged rapidly, exceeding 1 trillion tokens during the anonymous period, topping the OpenRouter weekly chart.
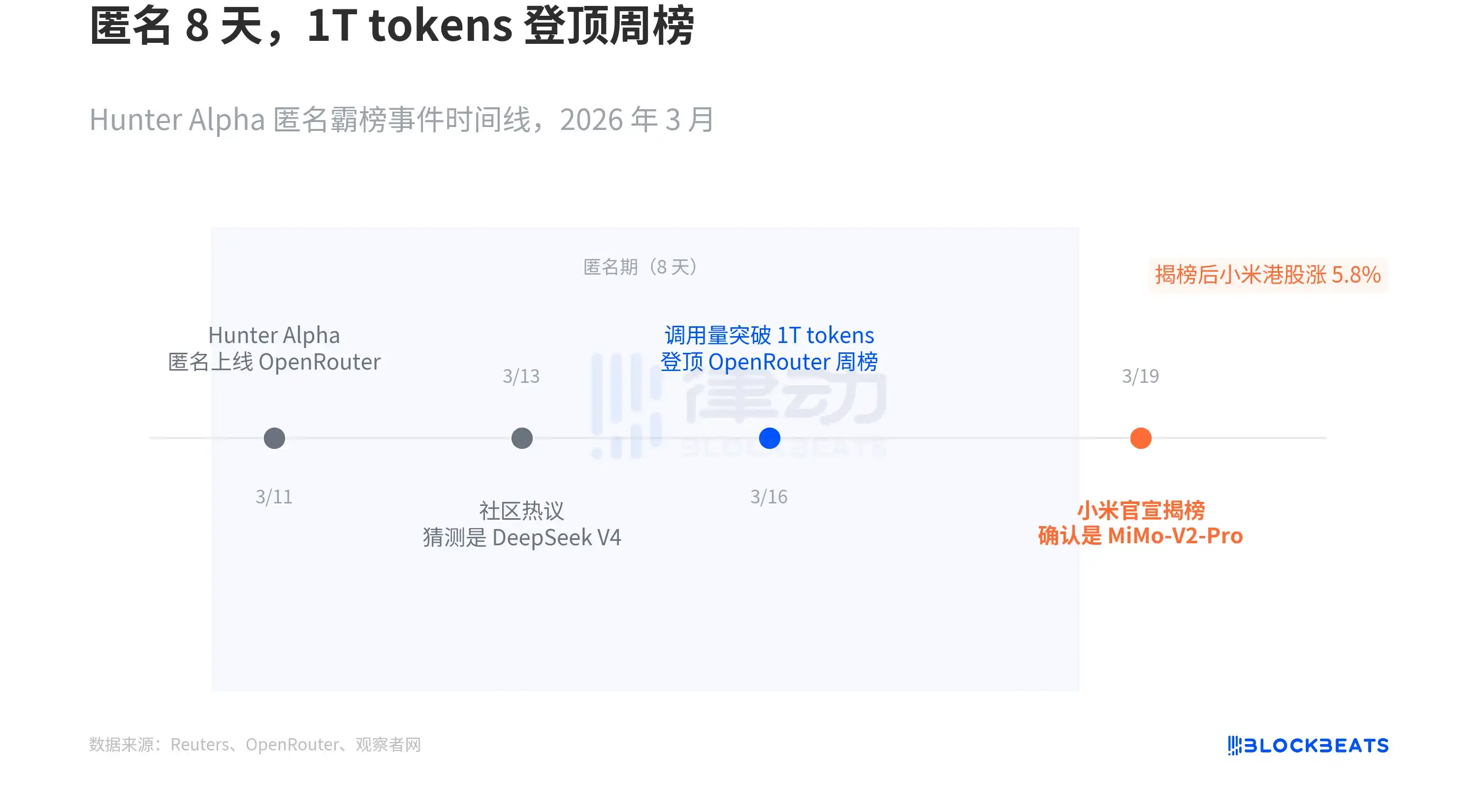
In the early hours of March 19, Xiaomi revealed the answer: Hunter Alpha was MiMo-V2-Pro. According to the same Reuters report, Xiaomi's Hong Kong stock saw a gain of up to 5.8% after the reveal.
This was the first time a domestic large model proved itself on a global platform through pure blind testing. Relying not on brand or宣传, but letting developers vote with their feet over 8 days.






