By AIDeepDive
Today, Zhipu (02513.HK), hailed as the "world's first listed large language model company," surged once again.
Its intraday increase once exceeded 30%. It closed at HK$1,282, up over 26% for the day, with its market capitalization reaching HK$571.57 billion, setting another historical high.
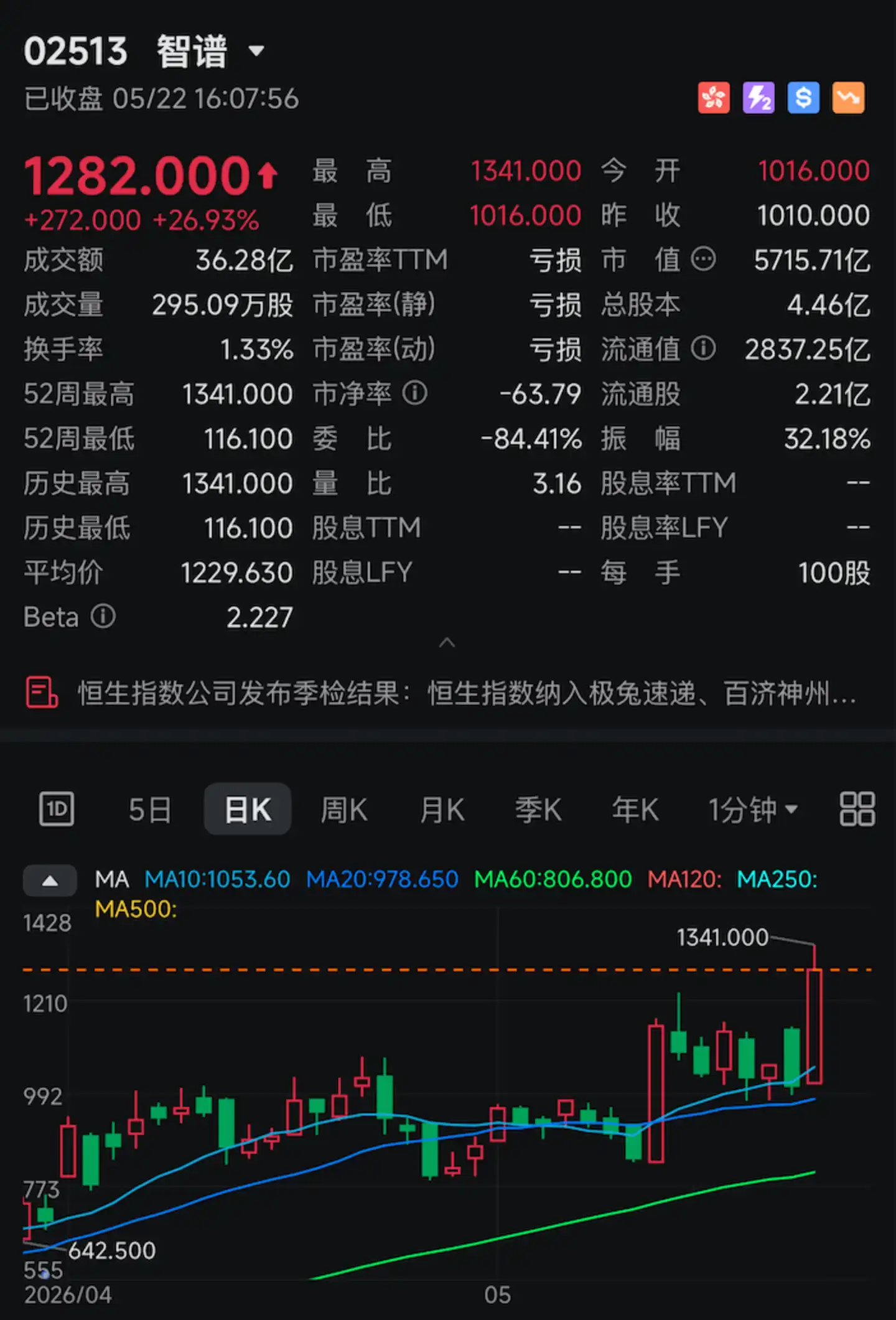
The trigger for this surge was a specific technical metric: 400 tokens/s.
On May 22, Zhipu officially opened access to the GLM-5.1 Highspeed API (GLM-5.1-highspeed) for enterprise clients. The most critical core parameter is just one: model output speed reaching 400 tokens per second, setting a new global upper limit for API speed among major LLM providers.
I initially thought this was just another public relations stunt by a domestic LLM company, but after examining the technical details, I finally understood the logic behind the capital market's reaction.
What does 400 tokens/s mean?
The model can generate approximately 200 Chinese characters per second, equivalent to the high-intensity output of a professional writer in one minute, compressed into just one second.
A volume of text that would take a creator several days of desk work to complete can be delivered by the GLM-5.1 Highspeed in just 1 minute; a system refactoring task that would occupy an engineer for 3 days can be completed in the time it takes to drink a cup of coffee.
01 Speed Is More Important Than You Think
Speed has historically been the most easily overlooked dimension in AI model competition.
Over the past three years, the LLM arms race has centered on two tracks: parameter scale (making models larger and smarter) and price wars (making tokens cheaper and more accessible). "Speed" was never the protagonist.
This is because, in the past, "speed" was typically achieved by reducing model parameters. To increase speed, one had to use smaller, more streamlined models, at the cost of diminished capabilities.
The significance of the GLM-5.1 Highspeed lies in its achievement of pushing speed to 400 tokens/s while retaining the capabilities of the flagship full-size base model.
For both domestic and international models, "flagship-level capability" and "ultra-low latency" have been achieved without compromise for the first time.

Why is speed so critical? Because the main battlefield for AI is undergoing a fundamental shift.
As AI moves from the ChatBot era into the Agent era, Q&A is no longer the primary scenario. For an Agent to complete a task, it often requires the model to make dozens or even hundreds of self-calls: writing code, calling APIs, searching for information, utilizing tools...
In this operational mode, the latency between each call is mercilessly magnified. For a task requiring 50 calls, saving 1 second per call speeds up the entire task by nearly 1 minute. For AI programming assistants, voice interaction, and commercial decision systems, this difference can be a matter of life or death.
At a deeper level, within a fixed time budget, faster inference means the model can explore deeper reasoning paths and perform more rounds of self-verification. Speed is transforming from a system metric into an upper limit of intelligence itself.
02 How Difficult Is Achieving Speed?
So, what's the current industry standard for speed?
Among leading providers, OpenAI's GPT-4o is around 100–150 tokens/s, Anthropic's Claude Sonnet series around 80–120 tokens/s, while mainstream domestic flagship model APIs mostly fall within the 50–100 tokens/s range. 400 tokens/s is approximately 3 to 5 times the industry average.
More crucially, this gap cannot be bridged simply by throwing more computing power at it.
A server equipped with 8 H200 GPUs can theoretically move up to 38TB of data per second. For GLM-5.1, generating a single token only requires reading about 42GB of activation parameters. Purely theoretical calculation suggests it should approach 1000 tokens/s.
But real-world systems often only achieve a few dozen tokens/s.
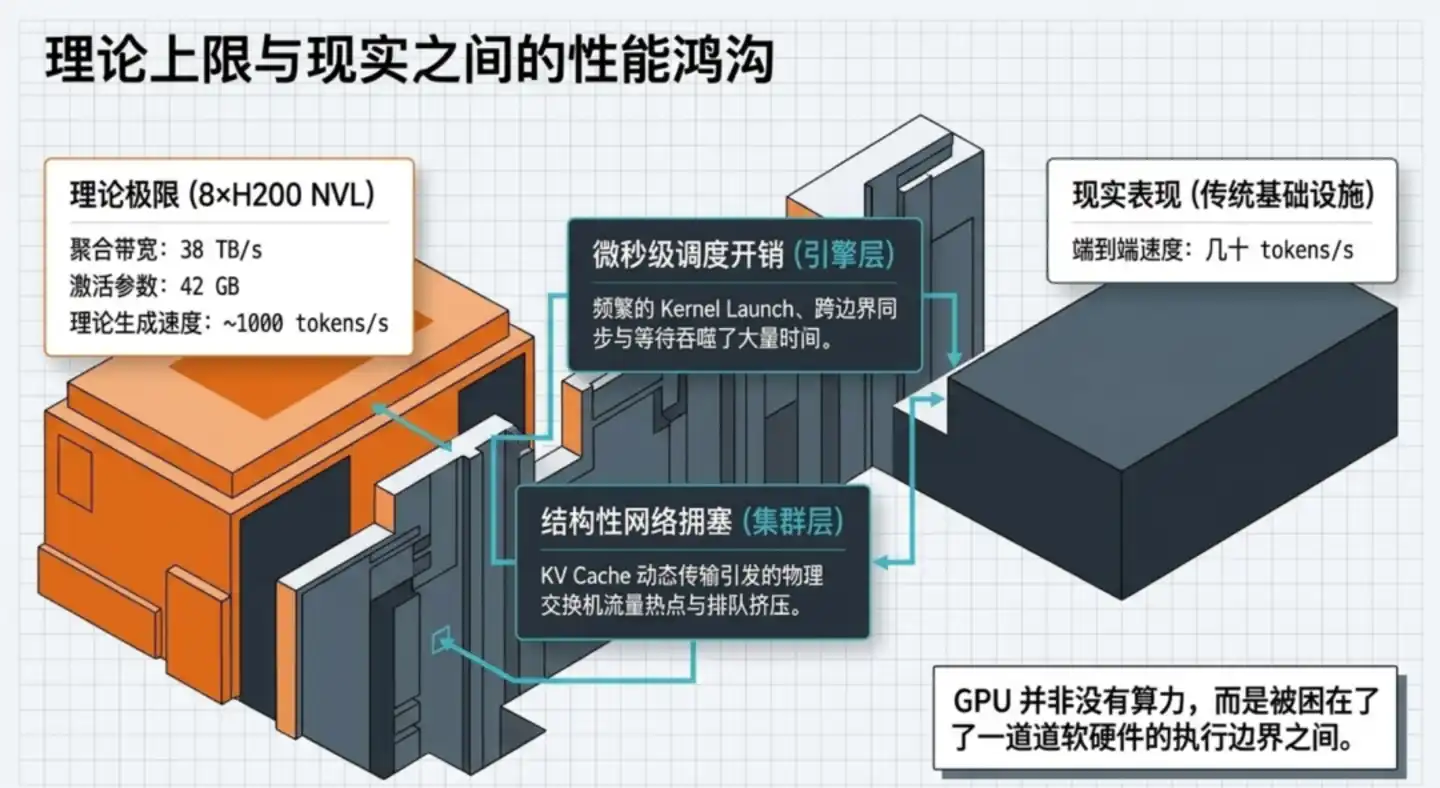
This is a gap of an order of magnitude. The GPUs aren't inherently too slow; rather, a significant amount of time is wasted on waiting, idling, and inefficient scheduling.
Zhipu's breakthrough this time stems from simultaneous innovations at three levels: the inference engine, parallelization strategy, and network architecture.
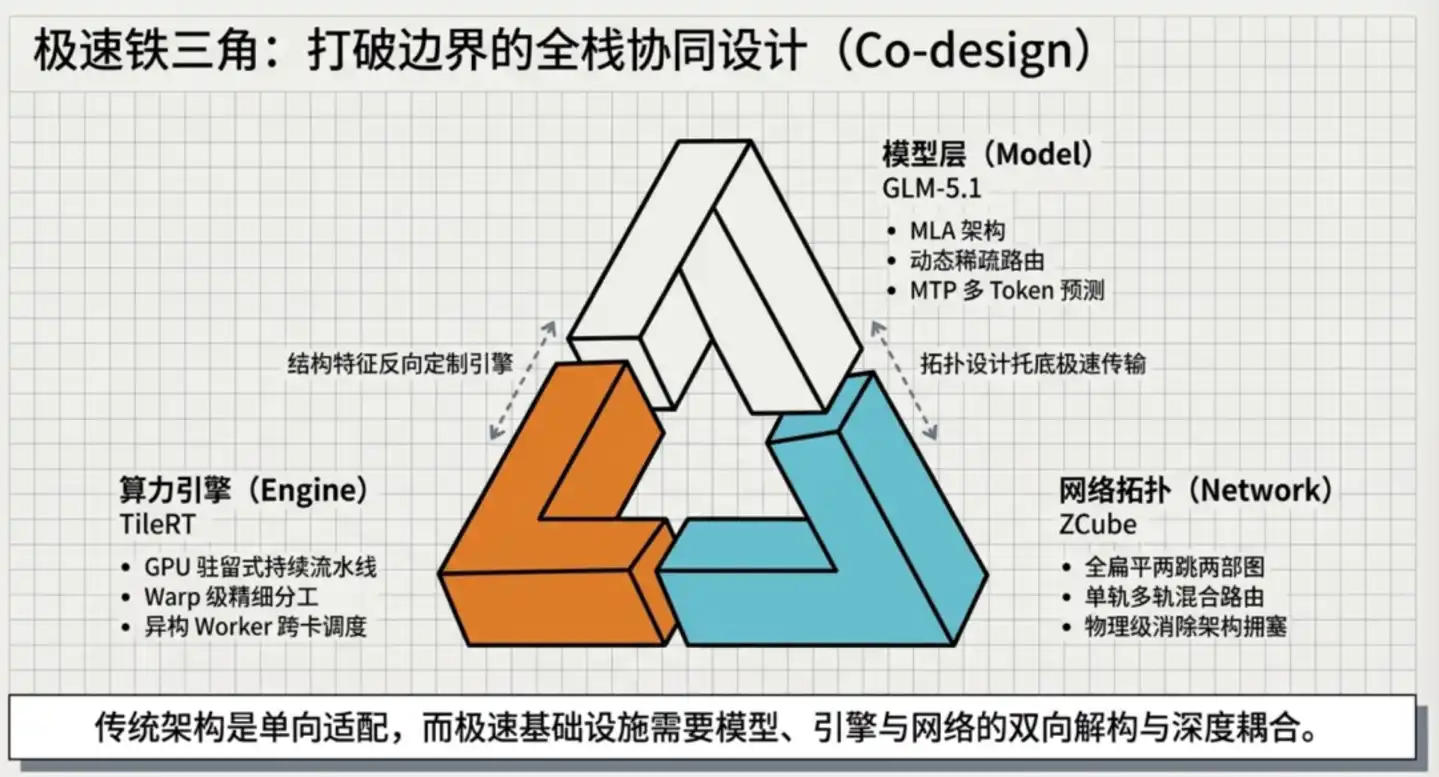
03 Three-Layer Technology Stack, Approaching Hardware Physical Limits
Here's how traditional LLMs operate: the model is decomposed into independent operators (kernels). Each operator launches a computing kernel, computes, stops, synchronizes and waits, then launches the next one.
During the training phase, each computation takes seconds or even minutes, making these startup and wait overheads negligible. But during inference, generating a single token, a key step might only require tens of microseconds, making the startup and wait overheads proportionally significant.
TileRT's Core Idea: Compile the entire model into a continuously running engine, start once, run perpetually.
TileRT statically unfolds all of the model's computational logic into a continuous pipeline during the code compilation phase. At runtime, the GPU maintains high-speed operation, with computation, data movement, and communication proceeding in parallel. Intermediate results are kept within the GPU's high-speed cache as much as possible, avoiding repeated writes to slow VRAM and subsequent re-reads.
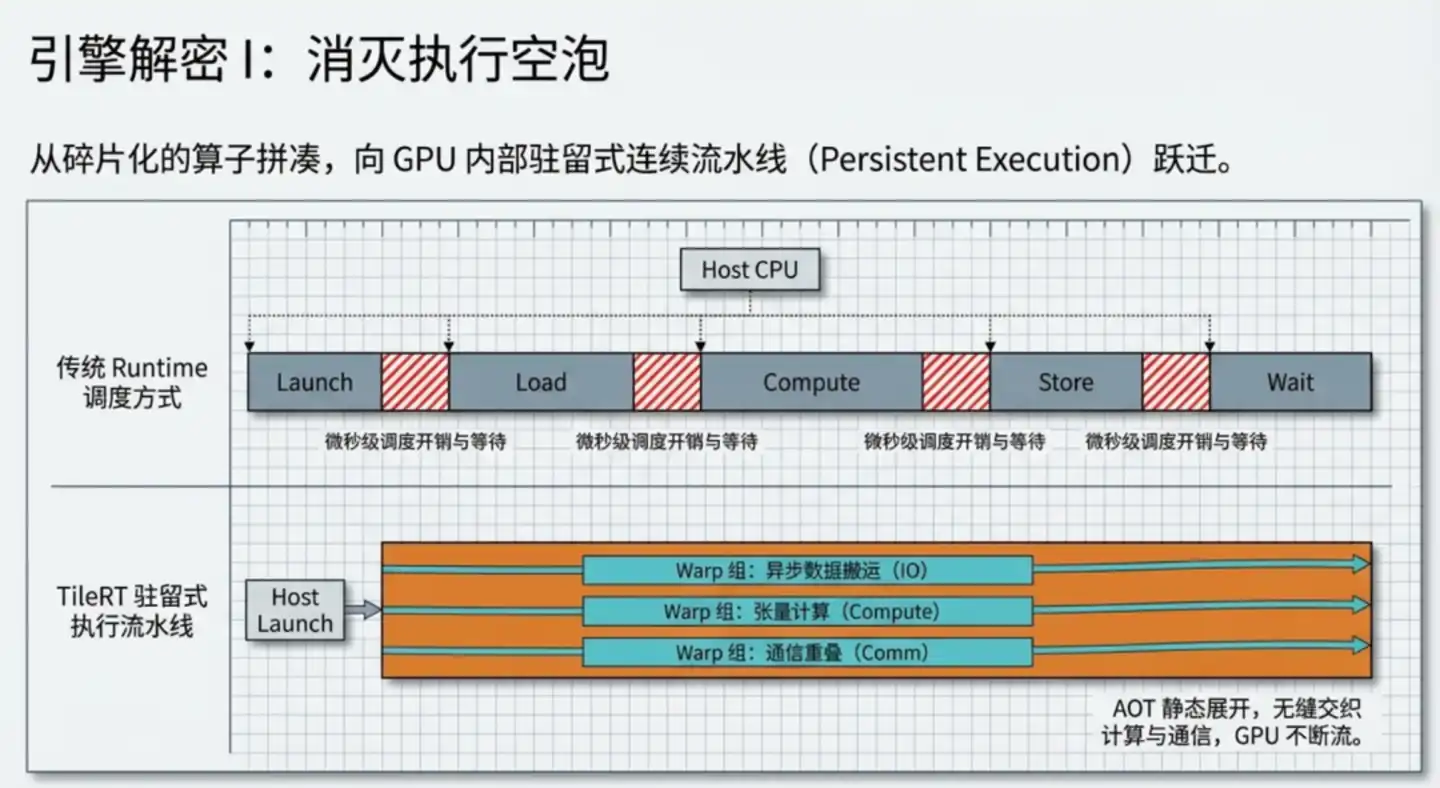
There's a crucial design detail here: Warp Specialization.
Understanding Warp requires first understanding GPU operation. The biggest difference between a GPU and a CPU is that a GPU contains thousands of relatively simple computing units, bundled together in groups of 32. This group is called a Warp.
All 32 units within the same Warp must always act synchronously, executing the same instruction, like a squad in the army where the squad leader orders everyone to perform the same action simultaneously.
In traditional frameworks, all Warps execute the same sequence of instructions. TileRT assigns different Warp groups different responsibilities: some specialize in prefetching the next batch of data, some in mathematical computation, some in communicating with other GPUs. The three groups work simultaneously, pipelining seamlessly without waiting for each other.
It's akin to moving from "one worker moving bricks, laying walls, and inspecting serially" to "a brick-moving group, a wall-laying group, and an inspection group operating concurrently."
With single-GPU efficiency solved, multi-GPU parallelism presents a new challenge.
The industry standard approach is Tensor Parallelism (TP): Split the model's weight matrices into several parts, with each GPU responsible for one part. After computing, results are aggregated via high-speed interconnects (NVLink).
This solution works well for regular, dense computations like matrix multiplication and is the standard multi-GPU solution for almost all current LLM inference frameworks.
GLM-5.1 employs **MLA (Multi-head Latent Attention), an attention mechanism proposed by DeepSeek.
Traditional attention mechanisms require storing large amounts of intermediate data (KV Cache) generated at each step for later use, which consumes significant VRAM. MLA's approach is to first compress this intermediate data into a compact "latent vector" for storage, then expand and restore it when needed, drastically reducing VRAM requirements and improving inference efficiency.
However, MLA's computational flow has a special step: performing sparse indexing from a large amount of historical information: similar to quickly finding the most relevant few books in a vast library before carefully reading them.
The "book-finding" step relies on global information and is not well-suited for distribution across multiple GPUs; the "careful reading" is the dense computation suitable for multi-GPU parallelism. If all 8 GPUs are forced to participate in "book-finding," a lot of time would be wasted on inter-GPU synchronization communication.
TileRT's solution is to have GPUs operate heterogeneously: GPU 0 specializes as the "library retriever," handling sparse indexing and routing decisions; GPUs 1–7 act as "detailed analysts," responsible for dense attention computation and matrix operations. The two types of workers each adopt the parallelization strategy best suited to them, collaborating to complete the entire computational layer.
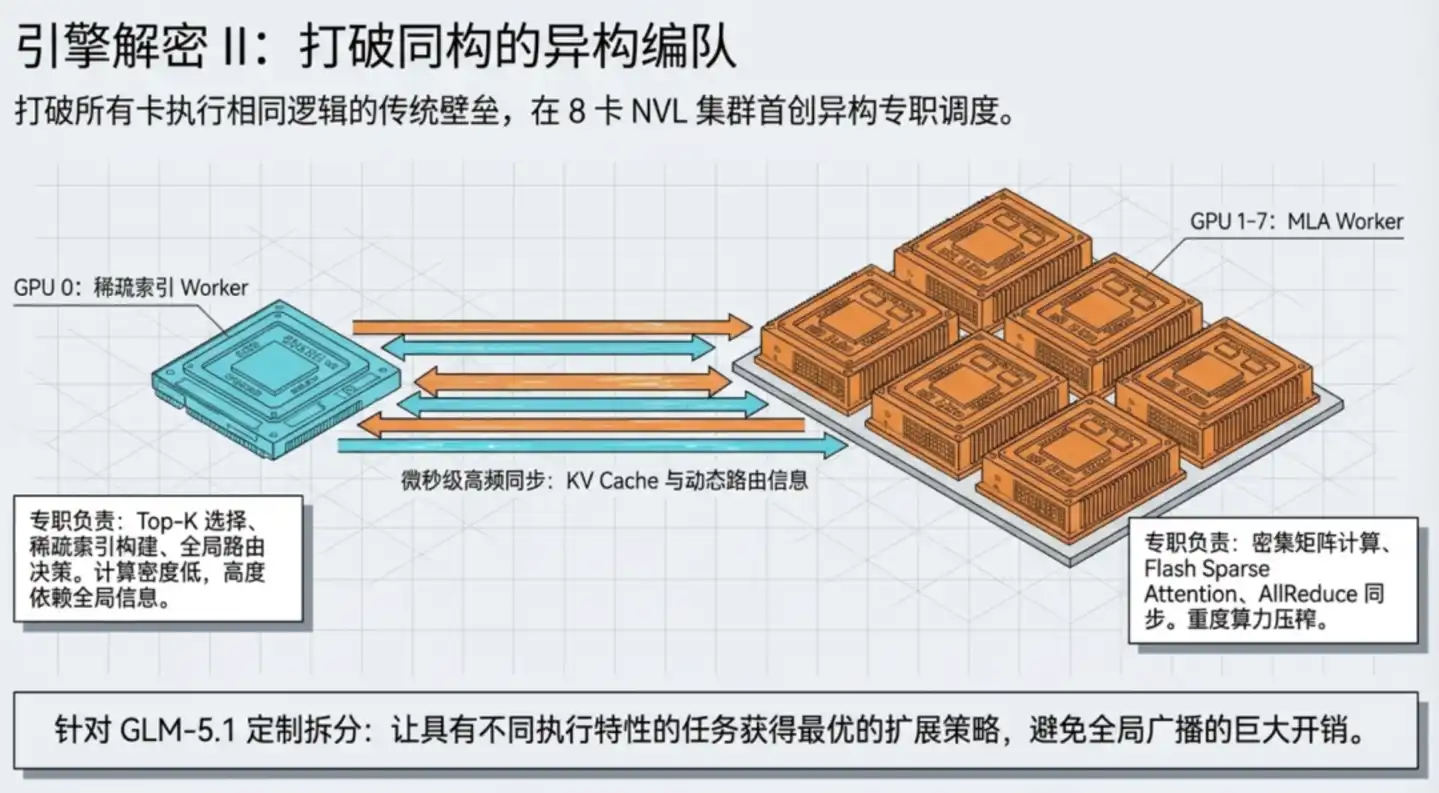
Next, TileRT embeds inter-GPU communication operations directly into the execution pipeline, no longer treating them as separate steps. Externally, the entire 8-GPU system completing one layer of attention computation requires only one kernel launch; internal communication and computation are all seamlessly completed within the continuous pipeline.
The above two layers address problems within a single server. When scaling clusters to hundreds or thousands of GPUs, data transmission between GPUs itself becomes the new bottleneck.
The industry standard approach is ROFT (Rail-Optimized Fat-Tree), NVIDIA's officially recommended solution and the absolute industry standard.
Its structure is like a tree: servers connect first to underlying Leaf switches (access layer, directly facing servers). Leaf switches then connect upward to Spine switches (backbone layer, responsible for interconnecting different Leafs, like highway hubs). Data transmission between two GPUs must "go up to a Spine, then down to the target Leaf," traversing at least 3 hops.
To prevent traffic from concentrating on a few links, this architecture relies on the ECMP algorithm to distribute data across multiple paths, functioning well under the premise of "statistically uniform" internet traffic.
But inference traffic is completely non-uniform. Context lengths between different requests can vary by tens of times, and the direction of KV Cache transmission between GPUs is almost random. A few Leaf switches periodically become hotspots, triggering backpressure mechanisms that spread congestion from local to the entire link. This congestion cannot be solved by protocol parameter tuning; it's inherent to the topology structure.
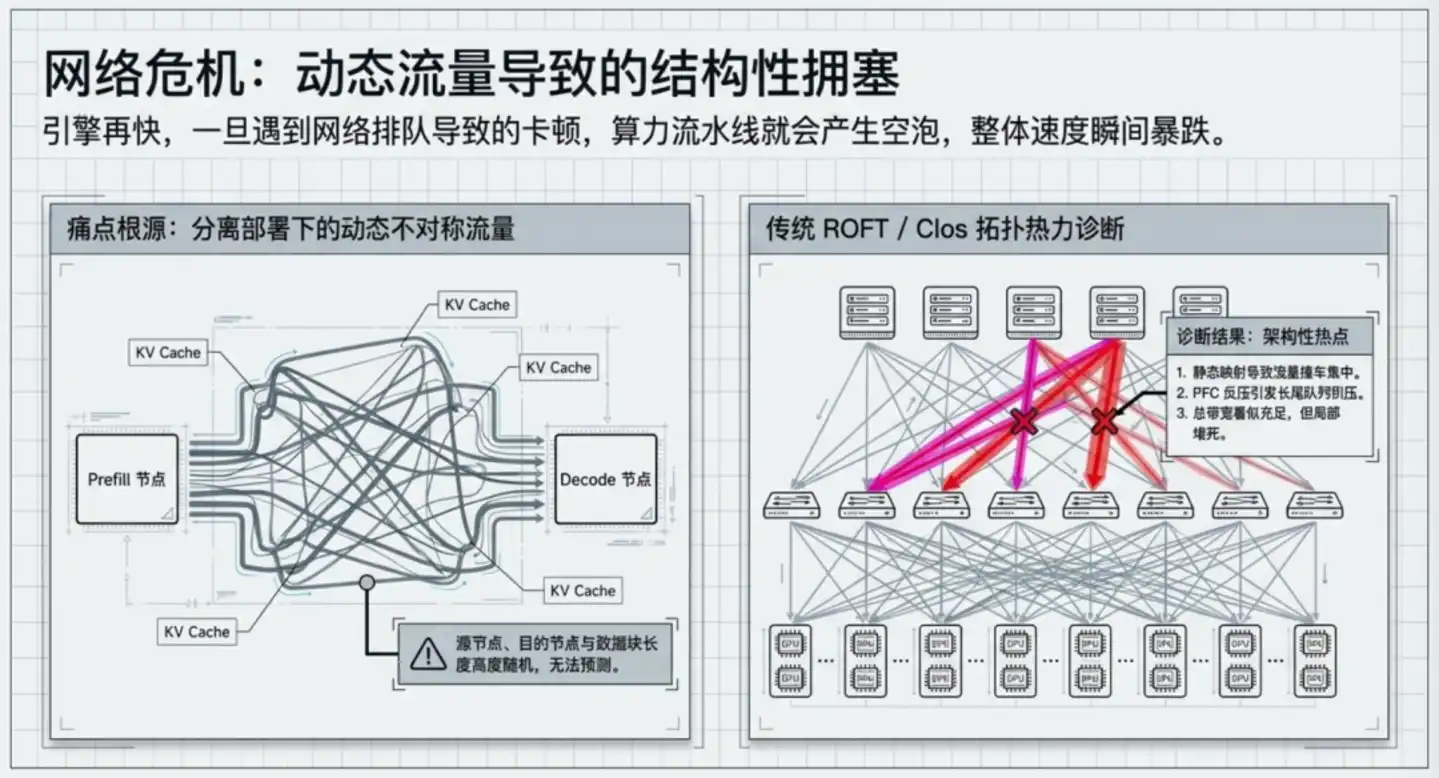
ZCube's fundamental breakthrough: Architecturally preventing this type of congestion from physically occurring.
The core design consists of two steps:
First, eliminate the Spine backbone layer, flatten the entire network. Divide all Leaf switches into two groups based on odd/even numbering, with the two groups fully interconnected. Any odd-numbered switch connects to all even-numbered switches, and vice versa. Any two GPUs can reach each other via at most two switches, reducing hops from 3 to 2.
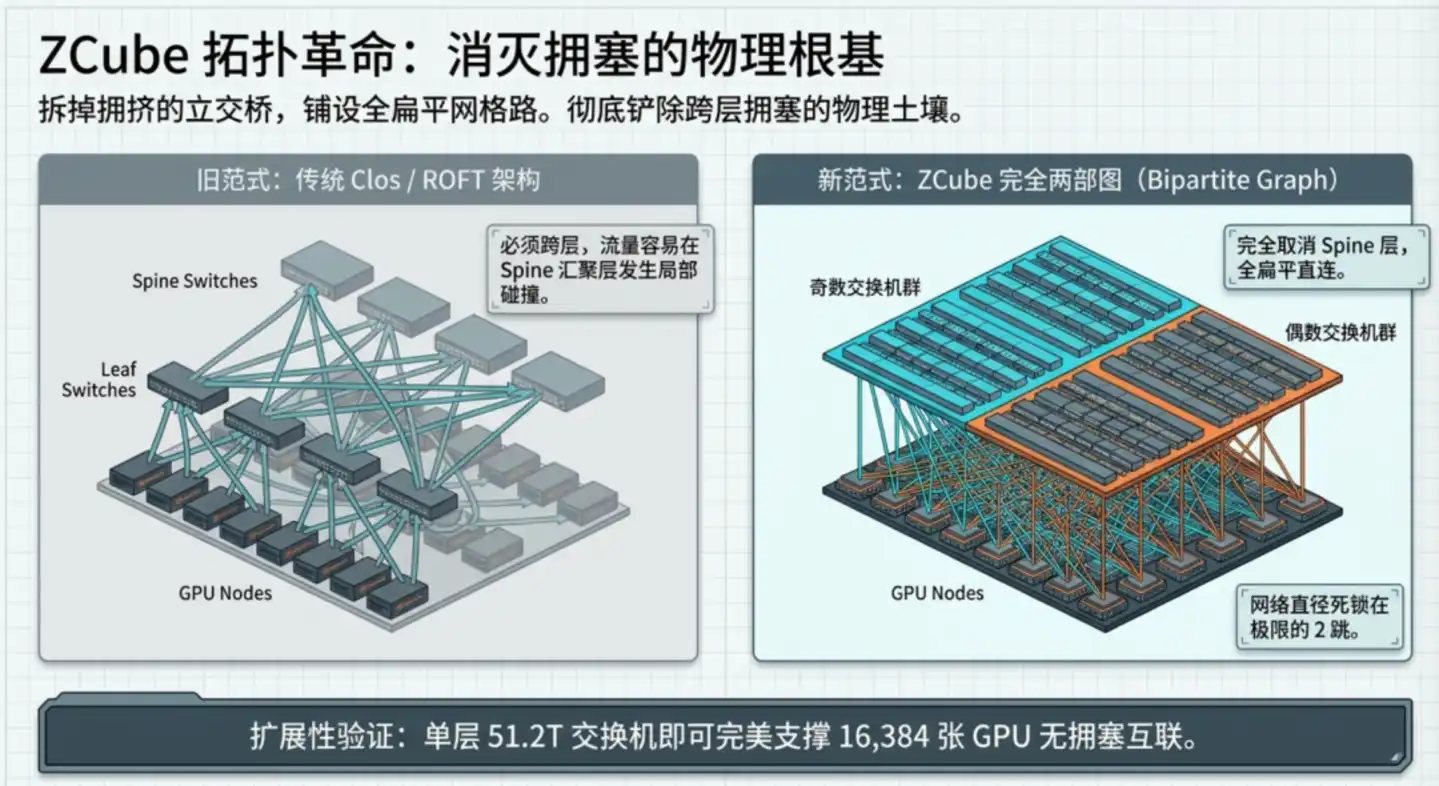
The second step, and the most ingenious part: Connect each GPU network card to the two groups of switches in two completely different ways. This special topology yields a key mathematical property: Between any two GPUs in the entire network, there is one and only one optimal path.
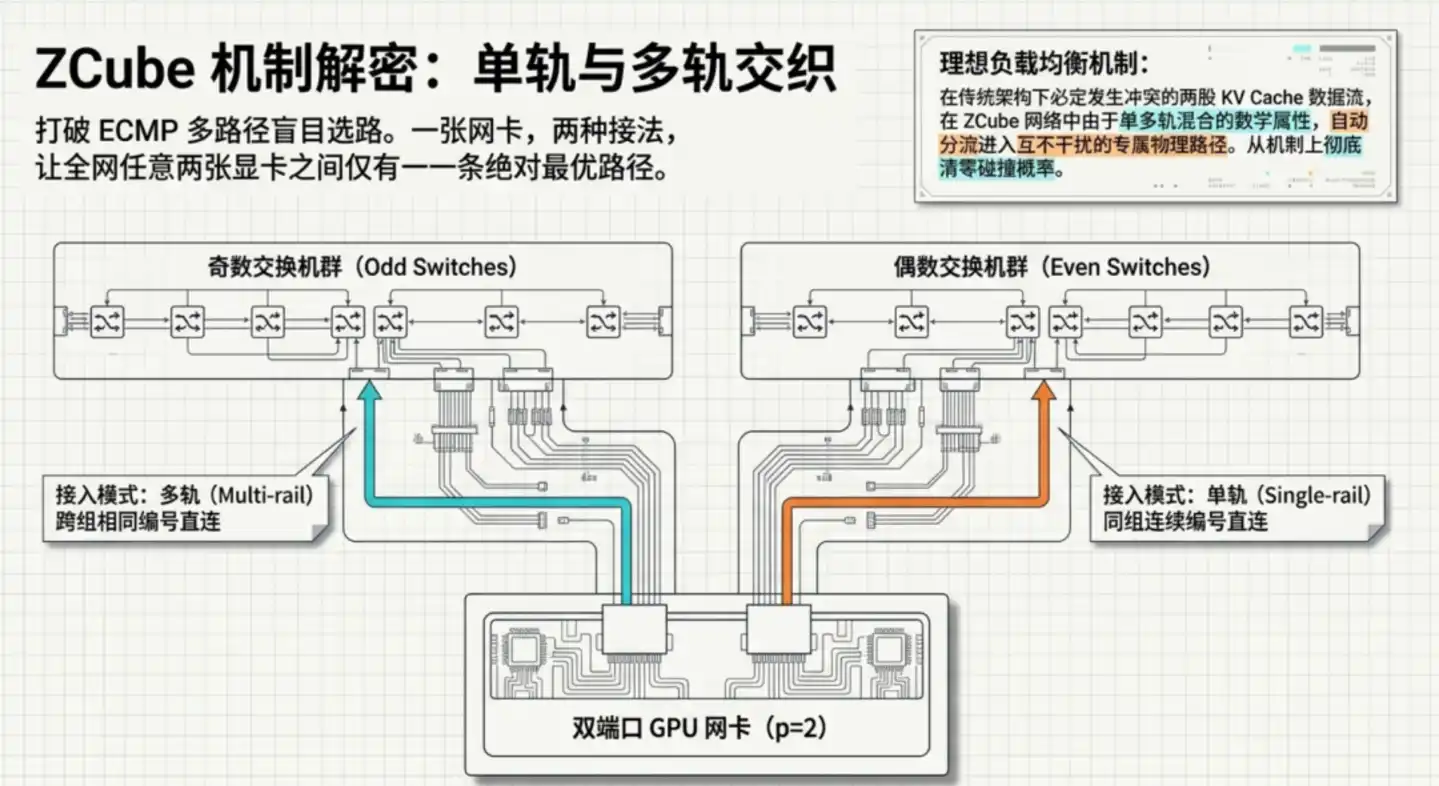
The "single path" directly eliminates the root cause of congestion. Traditional architectures are prone to hotspots precisely because there are multiple paths to choose from; if the load-balancing algorithm makes a wrong choice, traffic concentrates. ZCube eliminates "choice" itself by design: no balancing is needed because there are no forks.
04 Under the Same Hardware Conditions, How Does the Math Work?
After upgrading the GLM-5.1 production cluster from traditional ROFT to ZCube, Zhipu obtained three key numbers:
In summary, with the same GPU investment, the cluster can serve more users; with the same user experience requirements, the cluster can purchase one-third fewer network devices. Efficiency and cost are improved in both directions.
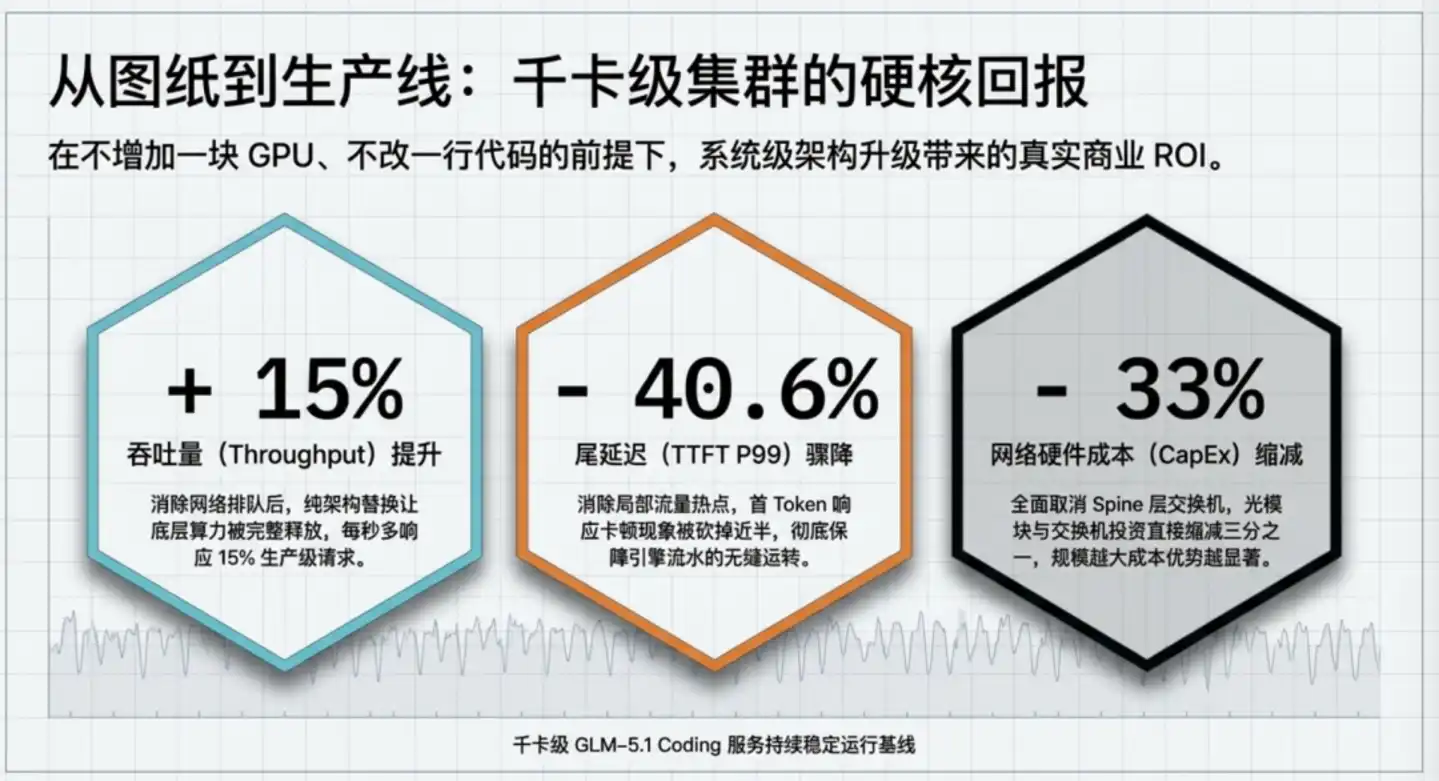
Specifically, throughput increased by 15%, equivalent to gaining 15% more computing power for free. With the same number of GPUs, a 15% higher throughput is equivalent to approximately a 13% reduction in the amortized hardware cost per token, or the ability to serve 15% more users at the same cost.
If a cluster has 1000 GPUs, this upgrade is equivalent to gaining the productive capacity of 150 additional cards for free. Based on current high-end inference GPU market prices, this represents computing power value in the billions of yuan.
A 40.6% reduction in tail latency addresses stability, not average speed. For an Agent task requiring 50 calls, if tail latency is reduced by 1 second per call, the worst-case completion time for the entire task is compressed by nearly 1 minute.
A one-third cost reduction is a direct saving at the construction level. ZCube eliminates the Spine layer, directly reducing the number of switches and optical modules required for the same cluster scale by one-third. According to Zhipu's calculations, in a ten-thousand-GPU scale cluster, this alone could save approximately 210 million to 640 million yuan.
In the long term, as cluster sizes expand exponentially, the complexity of inter-GPU communication grows manifold, and the probability and impact of congestion amplify accordingly. This means the value of architectural innovations like ZCube will accelerate as inference clusters continue to expand. The gains for tomorrow's ten-thousand-GPU clusters may far exceed today's 15%.
05 Final Thoughts
After reading Zhipu's technical report, I wondered: Could this bring a storm to the industry, much like DeepSeek's sudden emergence?
Upon careful consideration, their impacts seem to lie in different aspects. When DeepSeek emerged, it proved that the same level of intelligence could be achieved with far less computing power. The market worried that "fewer GPUs would be needed," causing NVIDIA's market cap to evaporate nearly $600 billion that day.
But Zhipu's technology today proves: The same computing power can produce more output. It is reshaping "what other infrastructure outside of GPUs should look like."
In the short term, NVIDIA may not be affected. But in the long run, the moat of GPU + NVLink interconnect + InfiniBand network + CUDA software ecosystem is being "loosened," especially the InfiniBand technology NVIDIA acquired with its $6.9 billion purchase of Mellanox in 2019. NVIDIA's premium on the network side will be significantly eroded.
Furthermore, while ZCube eliminates the Spine layer, it actually imposes higher requirements on the port density of Leaf switches. This benefits manufacturers capable of producing high-density, large-port Leaf switches (like Ruijie, Arista, Broadcom switching chips) and disadvantages those who primarily rely on high-end Spine layer switches for premium pricing.
In 2025, Celestica and NVIDIA together held about 50% of the AI backend network switch market share. This landscape faces a potential reshuffle if the ZCube paradigm proliferates.
Optical modules are the most directly beneficial segment in this industry chain change, with a very clear logic. For domestic optical module manufacturers (like Zhongji Innolight, Tianfu Communications, etc.), this is a structural positive: not only is the total volume growing, but the demand for high-speed optical modules (800G, 1.6T) under the ZCube paradigm is more concentrated and urgent compared to traditional architectures.
Whether it's TileRT or the ZCube architecture, this is a set of pure software inference engines running on standard GPUs, not reliant on NVIDIA's proprietary hardware features. In theory, they can be ported to domestic chips like Huawei's Ascend. Once this direction is viable, it will significantly lower the software stack barrier for domestic AI chips in inference scenarios.
This is perhaps the even greater significance behind this technological innovation.