Machine Heart Editorial Department
Google's newly open-sourced model, Gemma 4, released a few days ago, gave the industry a huge surprise.
It adopts the same technological architecture as Gemini 3, supports native full-modality, ranked third globally on the Arena AI leaderboard, and comes in multiple model sizes. Several smaller models — E2B (2.3B effective parameters) and E4B (4.5B effective parameters) — can be deployed directly to run locally on mobile devices, with a context window of 128K. They can be described as a "Gemini alternative that fits in your pocket".
As expected, the model quickly became a new toy for mobile users after its release.
Among them, a post by an X user was viewed hundreds of thousands of times. In the post, he shared a video demonstrating how he ran Gemma 4 locally on an iPhone, including processing images, audio, and controlling the flashlight. He stated that Gemma 4 is incredibly fast, feeling like magic.

Someone quantified this speed on an iPhone 17 Pro, pointing out that if the phone uses Apple silicon, the model's inference speed can exceed 40 tokens per second with the help of MLX (Apple's machine learning framework) optimized for this chipset.

Others achieved similar speeds on a Samsung Galaxy, even with a 'thinking mode' enabled. This led people to exclaim that it's "unbelievably fast".
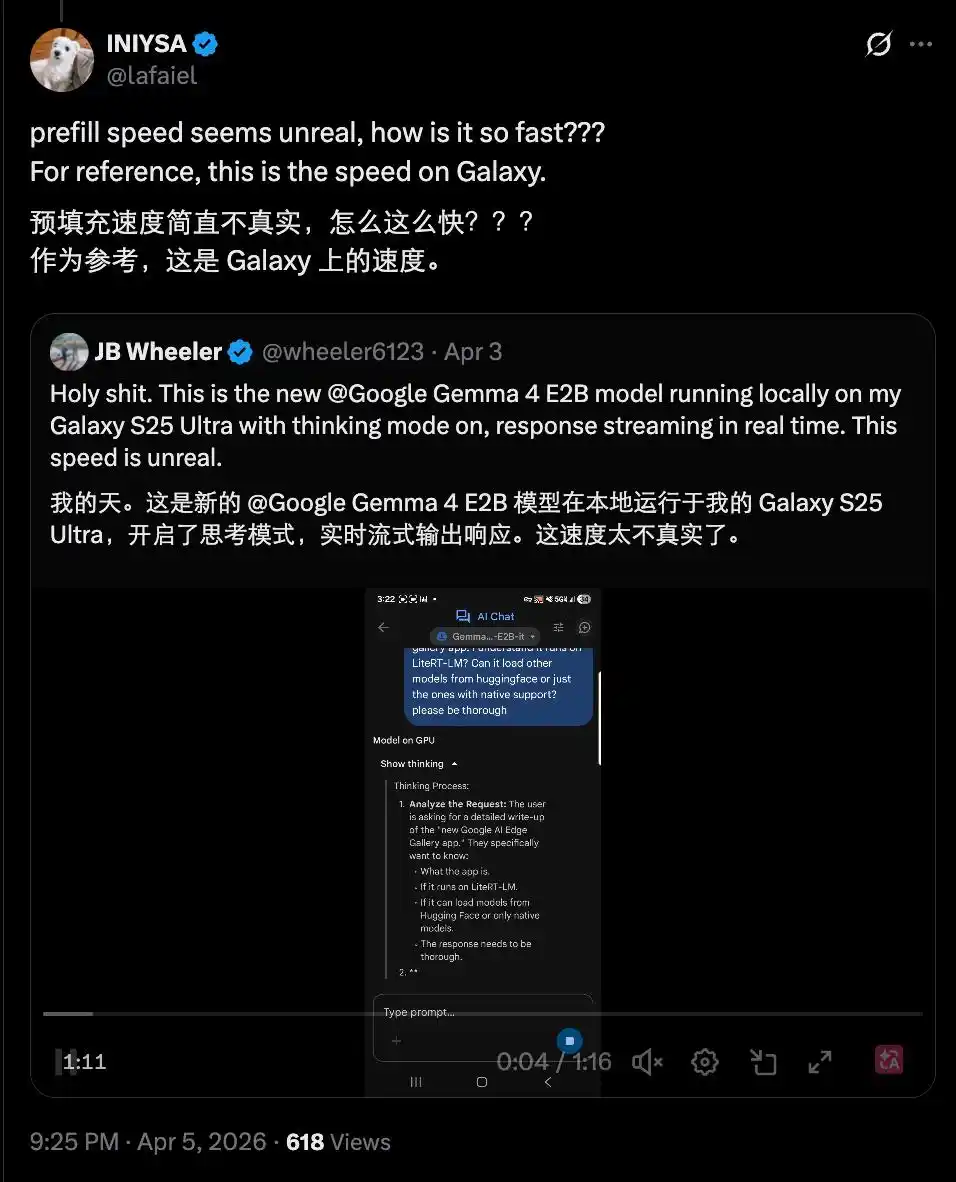
Such speeds make running AI models on mobile devices a viable option for the future, and are particularly useful in sensitive scenarios like healthcare.
The 128k context window also makes these small models more attractive.
So how do you run it? It's actually very simple and not exclusive to geeks, because Google released an official App — Google AI Edge Gallery. Those who want to experience it on their phone can directly download this App, then download the desired model version, and open it to run.

Moreover, since it's officially released by Google, security concerns are naturally less of an issue.
Beyond these small models running on phones, some have tried larger versions of Gemma 4 on more powerful hardware, such as running Gemma 4 Mixture-of-Experts 26B on a MacBook Pro with an M5 Pro chip.

For direct conversation, this model is still very fast, with smooth text generation and code explanation.

But when he actually tried to use Gemma 4 as a coding agent, problems arose. Because running an agent requires a large context (Gemma 4 26B has a 256k context window), complex prompts, and stable tool calls, Gemma 4 clearly couldn't handle it, often freezing, reporting errors, or outputting incorrect structures.

The turning point came when he switched the model to qwen3-coder. In the same environment, file creation, command execution, and multi-step tasks all ran normally. He believes the problem lies not with the agent framework, but with whether the model itself has been optimized for "tool calling + structured output". In this regard, Gemma 4 might not be sufficient, or perhaps this developer hasn't found the correct method yet.

Additionally, some say that Gemma 4's intelligence level is still somewhat lacking.
Even so, the emergence of a "performance powerhouse" like Gemma 4 should not be underestimated. If in the future, a large number of daily queries, chats, simple reasoning, code generation, and image understanding tasks can all be run locally without needing to buy tokens, wouldn't vendors who sell tokens be in an awkward position?
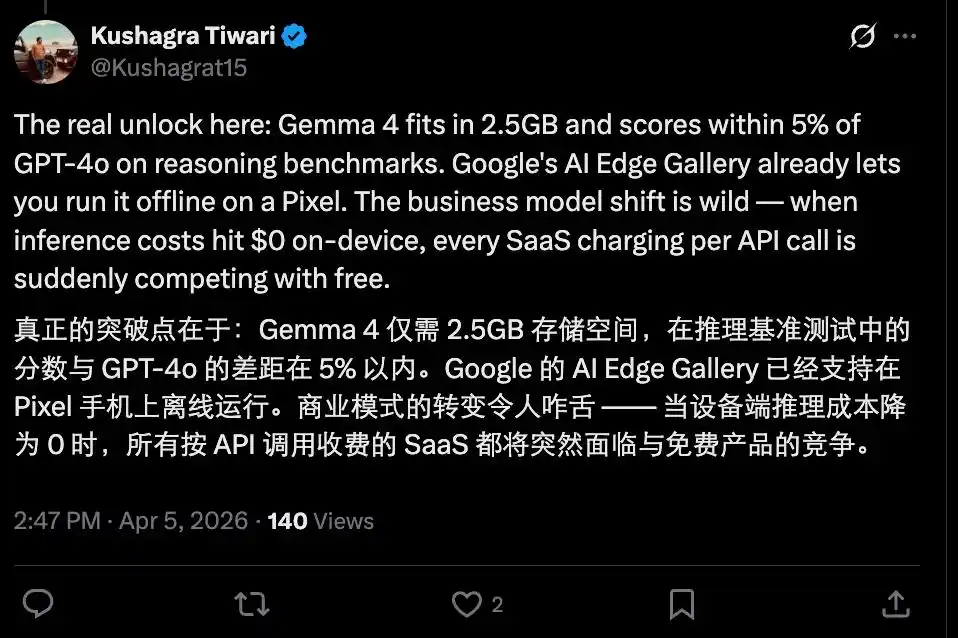
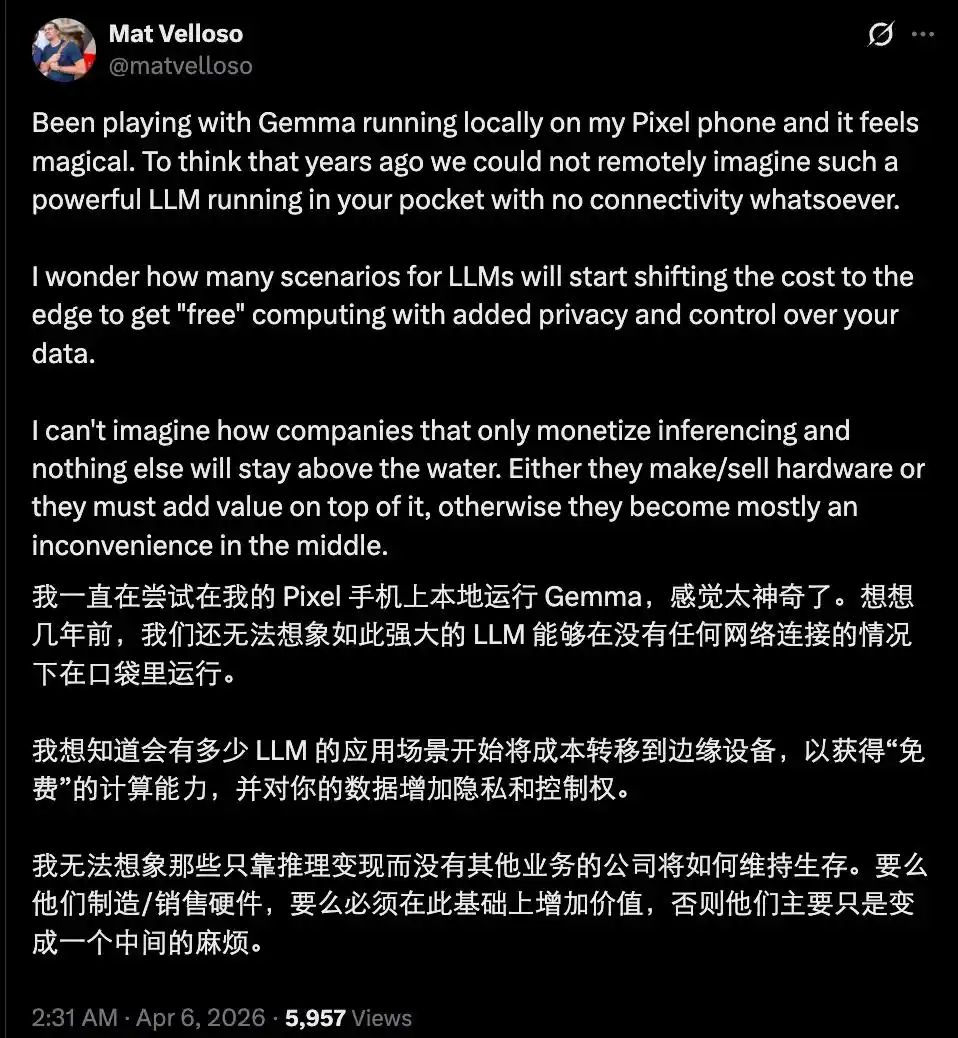
Of course, the current situation is not that pessimistic yet. After all, there is still a gap between the currently open-sourced models and the cutting-edge closed-source flagship models. Furthermore, most capable open-source models are still constrained by hardware capabilities and暂时 (zànshí - temporarily) haven't reached a usable level on the device side.

But the future trend is clear. In the short term, cloud-based closed-source models will still lead in cutting-edge complex reasoning and ultra-large-scale multi-agent collaboration. But in the long term, as hardware continues to advance and quantization techniques continue to optimize, on-device models will gradually encroach on the cloud's high-frequency simple tasks.
Those vendors who rely solely on selling tokens and API subscriptions will have to compete more fiercely on the "truly tough" parts — super-powered Agents, ultra-long reliable context, and specialized capabilities requiring massive real-time data.
Gemma 4 is just the beginning. The next surprise might be an on-device model that, in daily use, completely makes users unaware of the difference between "local" and "cloud". When that day comes, the entire AI industry's business model will undergo a real reshuffle.
This article is from the WeChat public account "Machine Heart" (ID: almosthuman2014), author: Machine Heart






