Authors: Li Hailun, Su Yang
On January 6th, Beijing time, NVIDIA CEO Jensen Huang, clad in his signature leather jacket, once again took the main stage at CES 2026.
At CES 2025, NVIDIA showcased the mass-produced Blackwell chip and a full-stack physical AI technology suite. During the event, Huang emphasized that an "era of Physical AI" was dawning. He painted a future full of imagination: autonomous vehicles with reasoning capabilities, robots that can understand and think, and AI Agents capable of handling long-context tasks involving millions of tokens.
A year has passed in a flash, and the AI industry has undergone significant evolution and change. Reviewing these changes at the launch event, Huang specifically highlighted open-source models.
He stated that open-source reasoning models like DeepSeek R1 have made the entire industry realize: when true openness and global collaboration kick in, the diffusion speed of AI becomes extremely rapid. Although open-source models still lag behind the most advanced models by about six months in overall capability, they close the gap every six months, and their downloads and usage have already seen explosive growth.

Compared to 2025's focus more on vision and possibilities, this time NVIDIA began systematically addressing the question of "how to achieve it":围绕推理型 AI (focusing on reasoning AI), it is bolstering the compute, networking, and storage infrastructure required for long-term operation, significantly reducing inference costs, and embedding these capabilities directly into real-world scenarios like autonomous driving and robotics.
Huang's CES keynote this year unfolded along three main lines:
● At the system and infrastructure level, NVIDIA redesigned the compute, networking, and storage architecture around long-term inference needs. With the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the Inference Context Memory Storage platform at the core, these updates directly target bottlenecks like high inference costs, difficulty in sustaining context, and scalability limitations, solving the problems of letting AI 'think a bit longer', 'afford to compute', and 'run persistently'.
● At the model level, NVIDIA placed Reasoning / Agentic AI at the core. Through models and tools like Alpamayo, Nemotron, and Cosmos Reason, it is pushing AI from "generating content" towards "continuous thinking", and from "one-time response models" to "agents that can work long-term".
● At the application and deployment level, these capabilities are being directly integrated into Physical AI scenarios like autonomous driving and robotics. Whether it's the Alpamayo-powered autonomous driving system or the GR00T and Jetson robotics ecosystem, they are driving scaled deployment through partnerships with cloud providers and enterprise platforms.

01 From Roadmap to Mass Production: Rubin's Full Performance Data Revealed for the First Time
At this CES, NVIDIA fully disclosed the technical details of the Rubin architecture for the first time.
In his speech, Huang started with the concept of Test-time Scaling. This concept can be understood as: making AI smarter isn't just about making it "study harder" during training anymore, but rather letting it "think a bit longer when encountering a problem".
In the past, improvements in AI capability relied mainly on throwing more compute power at the training stage, making models larger and larger; now, the new change is that even if the model stops growing, simply giving it a bit more time and compute power to think during each use can significantly improve the results.
How to make "AI thinking a bit longer" economically feasible? The Rubin architecture's next-generation AI computing platform is here to solve this problem.
Huang introduced it as a complete next-generation AI computing system, achieving a revolutionary drop in inference costs through the co-design of the Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, and Spectrum-6.

The NVIDIA Rubin GPU is the core chip responsible for AI compute in the Rubin architecture, aiming to significantly reduce the unit cost of inference and training.
Simply put, the Rubin GPU's core mission is to "make AI cheaper and smarter to use".
The core capability of the Rubin GPU lies in: the same GPU can handle more work. It can process more inference tasks at once, remember longer context, and communicate faster with other GPUs. This means many scenarios that previously required "stacking multiple cards" can now be accomplished with fewer GPUs.
The result is that inference is not only faster, but also significantly cheaper.
Huang recapped the hardware specs of the Rubin architecture's NVL72 for the audience: it contains 220 trillion transistors, with a bandwidth of 260 TB/s, and is the industry's first platform supporting rack-scale confidential computing.

Overall, compared to Blackwell, the Rubin GPU achieves a generational leap in key metrics: NVFP4 inference performance increases to 50 PFLOPS (5x), training performance to 35 PFLOPS (3.5x), HBM4 memory bandwidth to 22 TB/s (2.8x), and single GPU NVLink interconnect bandwidth doubles to 3.6 TB/s.
These improvements work together to enable a single GPU to handle more inference tasks and longer context, fundamentally reducing the reliance on the number of GPUs.

The Vera CPU is a core component designed specifically for data movement and Agentic processing, featuring 88 NVIDIA-designed Olympus cores, equipped with 1.5 TB of system memory (3x that of the previous Grace CPU), and achieving coherent memory access between CPU and GPU through 1.8 TB/s NVLink-C2C technology.
Unlike traditional general-purpose CPUs, Vera focuses on data scheduling and multi-step reasoning logic processing in AI inference scenarios, essentially acting as the system coordinator that enables "AI thinking a bit longer" to run efficiently.
NVLink 6, with its 3.6 TB/s bandwidth and in-network computing capability, allows the 72 GPUs in the Rubin architecture to work together like a single super GPU, which is key infrastructure for reducing inference costs.
This way, the data and intermediate results needed by AI during inference can quickly circulate between GPUs, without repeatedly waiting, copying, or recalculating.


In the Rubin architecture, NVLink-6 handles internal collaborative computing between GPUs, BlueField-4 handles context and data scheduling, and ConnectX-9 undertakes the system's high-speed external network connectivity. It ensures the Rubin system can communicate efficiently with other racks, data centers, and cloud platforms, a prerequisite for the smooth operation of large-scale training and inference tasks.
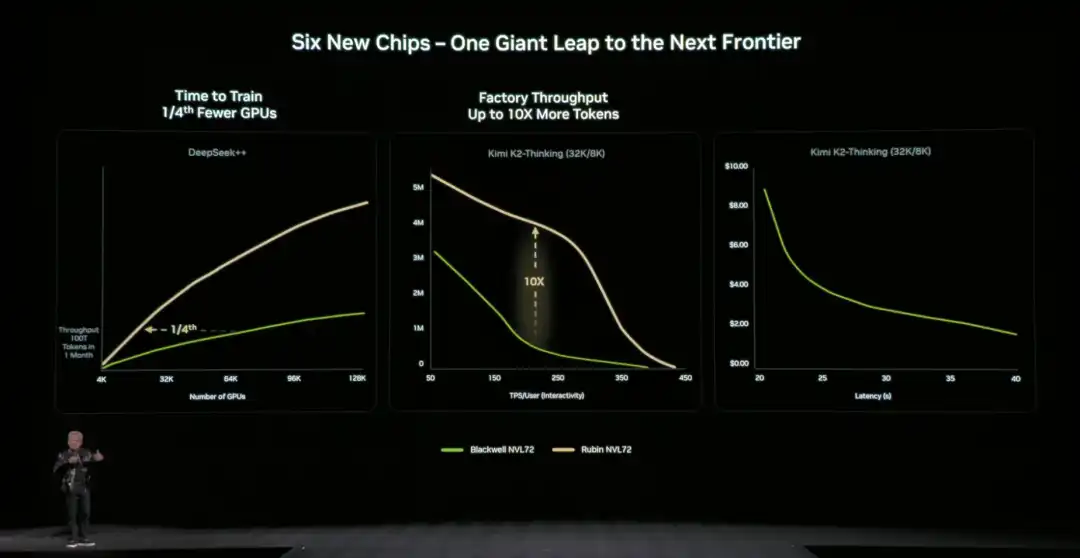
Compared to the previous generation architecture, NVIDIA also provided specific,直观的数据 (intuitive data): compared to the NVIDIA Blackwell platform, it can reduce token costs in the inference phase by up to 10 times, and reduce the number of GPUs required for training Mixture of Experts (MoE) models to 1/4 of the original.
NVIDIA officially stated that Microsoft has already committed to deploying hundreds of thousands of Vera Rubin chips in its next-generation Fairwater AI super factory, and cloud service providers like CoreWeave will offer Rubin instances in the second half of 2026. This infrastructure for "letting AI think a bit longer" is moving from technical demonstration to scaled commercial use.

02 How is the "Storage Bottleneck" Solved?
Letting AI "think a bit longer" also faces a key technical challenge: where should the context data be stored?
When AI handles complex tasks requiring multi-turn dialogue or multi-step reasoning, it generates a large amount of context data (KV Cache). Traditional architectures either cram it into expensive and capacity-limited GPU memory or put it in ordinary storage (which is too slow to access). If this "storage bottleneck" isn't solved, even the most powerful GPU will be hampered.
To address this issue, NVIDIA fully disclosed the BlueField-4 powered Inference Context Memory Storage Platform for the first time at this CES. The core goal is to create a "third layer" between GPU memory and traditional storage. It's fast enough, has ample capacity, and can support AI's long-term operation.
From a technical implementation perspective, this platform isn't the result of a single component working alone, but rather a set of co-designed elements:
- BlueField-4 is responsible for accelerating the management and access of context data at the hardware level, reducing data movement and system overhead;
- Spectrum-X Ethernet provides high-performance networking, supporting high-speed data sharing based on RDMA;
- Software components like DOCA, NIXL, and Dynamo are responsible for optimizing scheduling, reducing latency, and improving overall throughput at the system level.
We can understand this platform's approach as extending the context data, which originally could only reside in GPU memory, to an independent, high-speed, shareable "memory layer". This一方面 (on one hand) relieves pressure on the GPU, and另一方面 (on the other hand) allows for rapid sharing of this context information between multiple nodes and multiple AI agents.
In terms of actual效果 (effects), the data provided by NVIDIA官方 (officially) is: in specific scenarios, this method can increase the number of tokens processed per second by up to 5 times, and achieve同等水平的 (equivalent levels of) energy efficiency optimization.
Huang emphasized多次 (repeatedly) during the presentation that AI is evolving from "one-time dialogue chatbots" to true intelligent collaborators: they need to understand the real world, reason continuously, call tools to complete tasks, and retain both short-term and long-term memory. This is the core characteristic of Agentic AI. The Inference Context Memory Storage Platform is designed precisely for this long-running,反复思考的 (repeatedly thinking) form of AI. By expanding context capacity and speeding up cross-node sharing, it makes multi-turn conversations and multi-agent collaboration more stable, no longer "slowing down the longer it runs".

03 The New Generation DGX SuperPOD: Enabling 576 GPUs to Work Together
NVIDIA announced the new generation DGX SuperPOD (Super Pod) based on the Rubin architecture at this CES, expanding Rubin from a single rack to a complete data center solution.
What is a DGX SuperPOD?
If the Rubin NVL72 is a "super rack" containing 72 GPUs, then the DGX SuperPOD connects multiple such racks together to form a larger-scale AI computing cluster. This released version consists of 8 Vera Rubin NVL72 racks, equivalent to 576 GPUs working together.
When AI task scales continue to expand, the 576 GPUs of a single SuperPOD might not be enough. For example, training ultra-large-scale models, simultaneously serving thousands of Agentic AI agents, or processing complex tasks requiring millions of tokens of context. This requires multiple SuperPODs working together, and the DGX SuperPOD is the standardized solution for this scenario.
For enterprises and cloud service providers, the DGX SuperPOD provides an "out-of-the-box" large-scale AI infrastructure solution. There's no need to figure out how to connect hundreds of GPUs, configure networks, manage storage, etc., themselves.
The five core components of the new generation DGX SuperPOD:
○ 8 Vera Rubin NVL72 Racks - The core providing computing power, 72 GPUs per rack, 576 GPUs total;
○ NVLink 6 Expansion Network - Allows the 576 GPUs across these 8 racks to work together like one超大 (super large) GPU;
○ Spectrum-X Ethernet Expansion Network - Connects different SuperPODs, and to storage and external networks;
○ Inference Context Memory Storage Platform - Provides shared context data storage for long-running inference tasks;
○ NVIDIA Mission Control Software - Manages scheduling, monitoring, and optimization of the entire system.
With this upgrade, the foundation of the SuperPOD is the DGX Vera Rubin NVL72 rack-scale system at its core. Each NVL72 is itself a complete AI supercomputer, internally connecting 72 Rubin GPUs via NVLink 6, capable of handling large-scale inference and training tasks within a single rack. The new DGX SuperPOD consists of multiple NVL72 units, forming a system-level cluster capable of long-term operation.
When the compute scale expands from "single rack" to "multi-rack", new bottlenecks emerge: how to stably and efficiently传输海量数据 (transfer massive amounts of data) between racks.围绕这一问题 (Around this issue), NVIDIA simultaneously announced the new generation Ethernet switch based on the Spectrum-6 chip at this CES, and introduced "Co-Packaged Optics" (CPO) technology for the first time.
Simply put, this involves packaging the originally pluggable optical modules directly next to the switch chip, reducing the signal transmission distance from meters to millimeters, thereby significantly reducing power consumption and latency, and also improving the overall stability of the system.
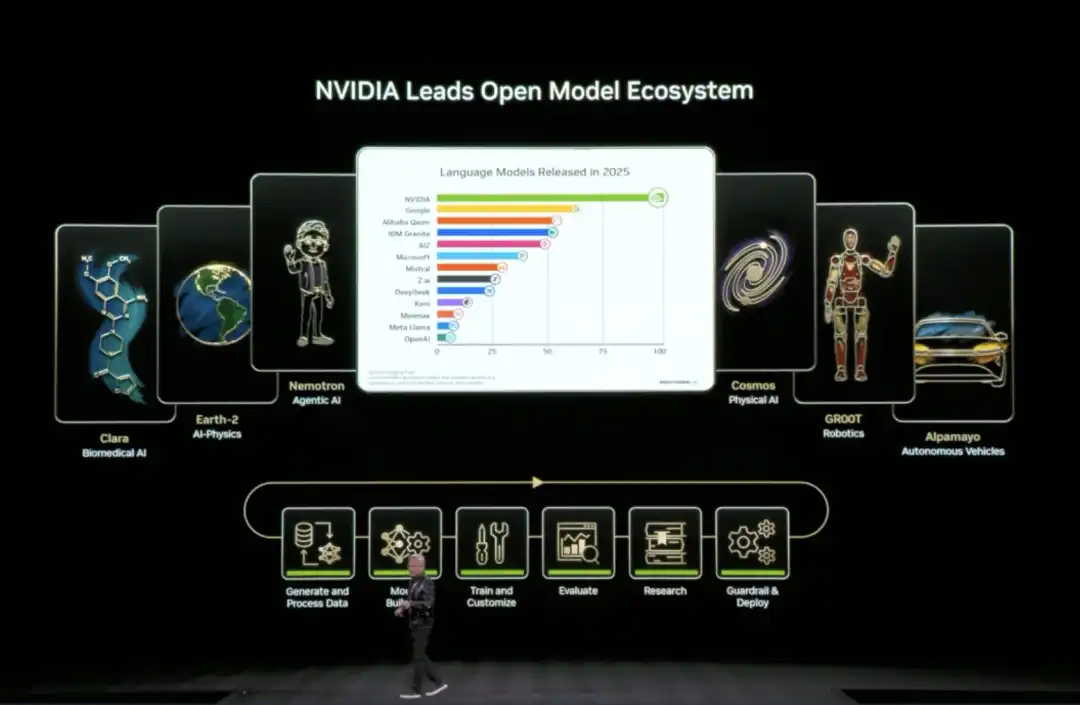
04 NVIDIA's Open Source AI "Full Stack": Everything from Data to Code
At this CES, Huang announced the expansion of its open-source model ecosystem (Open Model Universe), adding and updating a series of models, datasets, code libraries, and tools. This ecosystem covers six areas: Biomedical AI (Clara), AI Physics Simulation (Earth-2), Agentic AI (Nemotron), Physical AI (Cosmos), Robotics (GR00T), and Autonomous Driving (Alpamayo).
Training an AI model requires not just compute power, but also high-quality datasets, pre-trained models, training code, evaluation tools, and a whole set of infrastructure. For most companies and research institutions, building these from scratch is too time-consuming.
Specifically, NVIDIA has open-sourced six layers of content: compute platforms (DGX, HGX, etc.), training datasets for various domains, pre-trained foundation models, inference and training code libraries, complete training process scripts, and end-to-end solution templates.
The Nemotron series was a key focus of this update, covering four application directions.
In the reasoning direction, it includes small-scale reasoning models like Nemotron 3 Nano, Nemotron 2 Nano VL, as well as reinforcement learning training tools like NeMo RL and NeMo Gym. In the RAG (Retrieval-Augmented Generation) direction, it provides Nemotron Embed VL (vector embedding model), Nemotron Rerank VL (re-ranking model), relevant datasets, and the NeMo Retriever Library. In the safety direction, there is the Nemotron Content Safety model and its配套数据集 (matching dataset), and the NeMo Guardrails library.
In the speech direction, it includes Nemotron ASR for automatic speech recognition, the Granary Dataset for speech, and the NeMo Library for speech processing. This means if a company wants to build an AI customer service system with RAG, it doesn't need to train its own embedding and re-ranking models; it can directly use the code NVIDIA has already trained and open-sourced.
05 Physical AI Domain Moves Towards Commercial Deployment
The Physical AI domain also saw model updates—Cosmos for understanding and generating videos of the physical world, the general-purpose robotics foundation model Isaac GR00T, and the vision-language-action model for autonomous driving, Alpamayo.

Huang claimed at CES that the "ChatGPT moment" for Physical AI is approaching, but there are many challenges: the physical world is too complex and variable, collecting real data is slow and expensive, and there's never enough.
What's the solution? Synthetic data is one path. Hence, NVIDIA introduced Cosmos.
This is an open-source foundational model for the physical AI world, already pre-trained on massive amounts of video, real driving and robotics data, and 3D simulation. It can understand how the world works and connect language, images, 3D, and actions.
Huang stated that Cosmos can achieve several physical AI skills, such as generating content, performing reasoning, and predicting trajectories (even if only given a single image). It can generate realistic videos based on 3D scenes, generate physically plausible motion based on driving data, and even generate panoramic videos from simulators, multi-camera footage, or text descriptions. It can even还原 (recreate) rare scenarios.
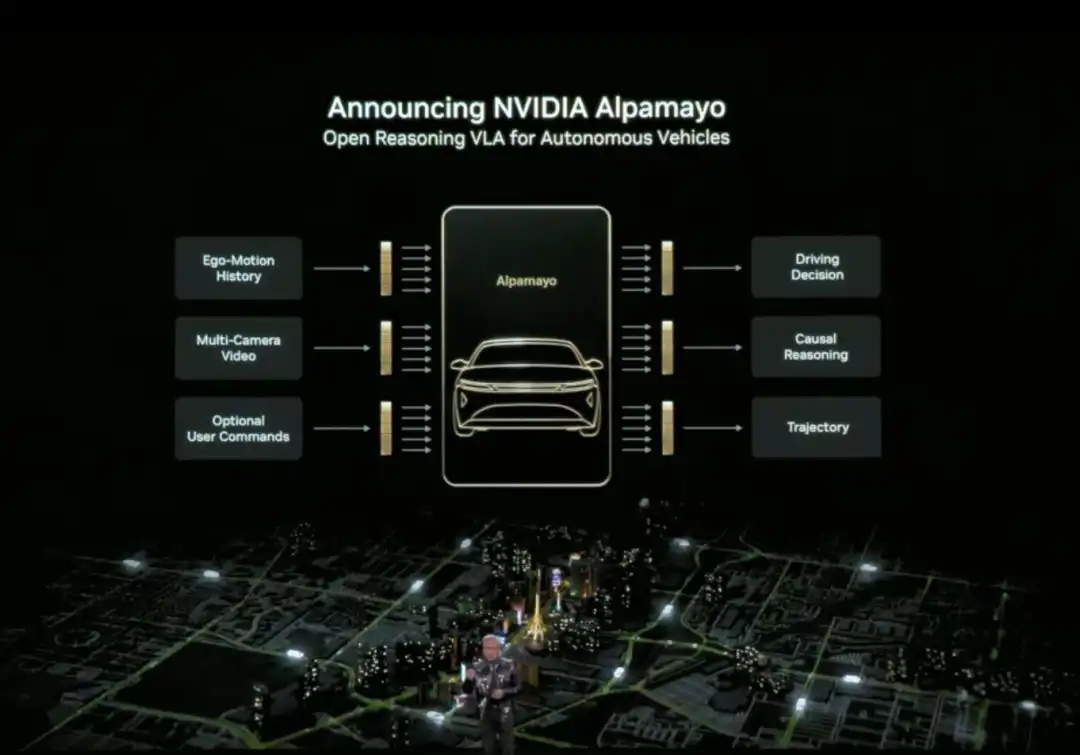
Huang also officially released Alpamayo. Alpamayo is an open-source toolchain for the autonomous driving domain, and the first open-source vision-language-action (VLA) reasoning model. Unlike previous open-sourcing of only code, NVIDIA this time open-sourced the complete development resources from data to deployment.
Alpamayo's biggest breakthrough is that it is a "reasoning" autonomous driving model. Traditional autonomous driving systems follow a "perception-planning-control" pipeline architecture—see a red light and brake, see a pedestrian and slow down, following preset rules. Alpamayo introduces "reasoning" capability, understanding causal relationships in complex scenes, predicting the intentions of other vehicles and pedestrians, and even handling decisions requiring multi-step thinking.
For example, at an intersection, it doesn't just recognize "there's a car ahead", but can reason "that car might be turning left, so I should wait for it to go first". This capability upgrades autonomous driving from "driving by rules" to "thinking like a human".
Huang announced that the NVIDIA DRIVE system has officially entered the mass production phase, with the first application being the new Mercedes-Benz CLA, planned to hit US roads in 2026. This vehicle will be equipped with an L2++ level autonomous driving system, adopting a hybrid architecture of "end-to-end AI model + traditional pipeline".
The robotics field also saw substantial progress.
Huang stated that leading global robotics companies, including Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics, and XRlabs, are developing products based on the NVIDIA Isaac platform and the GR00T foundation model, covering various fields from industrial robots and surgical robots to humanoid robots and consumer robots.

During the launch event, Huang stood in front of a stage filled with robots of different forms and用途 (purposes), displayed on a tiered platform: from humanoid robots, bipedal and wheeled service robots, to industrial robotic arms, engineering machinery, drones, and surgical assist devices, presenting a "robotics ecosystem landscape".
From Physical AI applications to the Rubin AI computing platform, to the Inference Context Memory Storage platform and the open-source AI "full stack".
These actions showcased by NVIDIA at CES constitute NVIDIA's narrative for推理时代 AI 基础设施 (AI infrastructure for the reasoning era). As Huang repeatedly emphasized, when Physical AI needs to think continuously, run persistently, and truly enter the real world, the problem is no longer just about whether there's enough compute power, but about who can actually build the entire system.
At CES 2026, NVIDIA has provided an answer.
Trend Kriptolar
İlgili Sorular
QWhat are the three main topics of Jensen Huang's CES 2026 keynote?![]()
AThe three main topics are: 1) Reconstructing computing, networking, and storage architecture around long-term inference needs with the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the inference context memory storage platform. 2) Placing reasoning/agentic AI at the core through models and tools like Alpamayo, Nemotron, and Cosmos Reason. 3) Directly applying these capabilities to physical AI scenarios like autonomous driving and robotics.
QWhat is the key innovation of the Rubin GPU architecture and its primary goal?![]()
AThe key innovation of the Rubin GPU architecture is its ability to handle more inference tasks and longer context within a single GPU, facilitated by a significant performance leap over Blackwell. Its primary goal is to 'make AI cheaper and smarter to use' by dramatically reducing the cost of inference and the number of GPUs required for many tasks.
QWhat problem does the Inference Context Memory Storage Platform solve, and what are its core components?![]()
AIt solves the 'storage bottleneck' problem, where context data (KV Cache) from multi-step AI reasoning tasks traditionally had to be stored in expensive, limited GPU memory or slow conventional storage. Its core components are the BlueField-4 DPU (for hardware-accelerated data management), Spectrum-X Ethernet (for high-performance networking), and software components like DOCA, NIXL, and Dynamo for system optimization.
QWhat major advancement did NVIDIA announce for the autonomous driving sector?![]()
ANVIDIA announced the official entry of its DRIVE system into mass production, with the first application being the new Mercedes-Benz CLA, planned for US roads in 2026. They also open-sourced Alpamayo, the first visual-language-action (VLA) reasoning model for autonomous driving, which introduces causal reasoning and multi-step decision-making capabilities.
QWhat is the significance of the new DGX SuperPOD based on the Rubin architecture?![]()
AThe new DGX SuperPOD scales the Rubin architecture from a single rack (NVL72 with 72 GPUs) to a data-center-scale solution. Composed of 8 NVL72 racks for a total of 576 GPUs, it provides an 'out-of-the-box' massive AI computing cluster for training ultra-large models or serving thousands of Agentic AI agents, managed by the NVIDIA Mission Control software.
İlgili Okumalar




İşlemler
Popüler Makaleler
$S$ Nedir
SPERO'yu Anlamak: Kapsamlı Bir Genel Bakış SPERO'ya Giriş İnovasyonun manzarası gelişmeye devam ederken, web3 teknolojilerinin ve kripto para projelerinin ortaya çıkışı dijital geleceği şekillendirmede önemli bir rol oynamaktadır. Bu dinamik alanda dikkat çeken projelerden biri SPERO, $$s$$ olarak adlandırılmaktadır. Bu makale, SPERO hakkında ayrıntılı bilgi toplamak ve sunmak amacıyla, meraklılar ve yatırımcıların web3 ve kripto alanlarındaki temellerini, hedeflerini ve yeniliklerini anlamalarına yardımcı olmayı amaçlamaktadır. SPERO,$$s$$ Nedir? SPERO,$$s$$, kripto alanında merkeziyetsizlik ve blok zinciri teknolojisi ilkelerini kullanarak etkileşimi, faydayı ve finansal kapsayıcılığı teşvik eden bir ekosistem yaratmayı amaçlayan benzersiz bir projedir. Proje, kullanıcıların yenilikçi finansal çözümler ve hizmetler sunarak eşler arası etkileşimleri yeni yollarla kolaylaştırmayı hedeflemektedir. SPERO,$$s$$'nin temel amacı, bireyleri güçlendirmek ve kripto para alanındaki kullanıcı deneyimini artıran araçlar ve platformlar sağlamaktır. Bu, daha esnek işlem yöntemlerini mümkün kılmayı, topluluk odaklı girişimleri teşvik etmeyi ve merkeziyetsiz uygulamalar (dApp'ler) aracılığıyla finansal fırsatlar yaratmayı içermektedir. SPERO,$$s$$'nin temel vizyonu kapsayıcılık etrafında dönmekte olup, geleneksel finansal sistemlerdeki boşlukları kapatmayı ve blok zinciri teknolojisinin faydalarından yararlanmayı hedeflemektedir. SPERO,$$s$$'nin Yaratıcısı Kimdir? SPERO,$$s$$'nin yaratıcısının kimliği bir miktar belirsizdir, çünkü kurucusu(ları) hakkında ayrıntılı arka plan bilgisi sağlayan sınırlı kamuya açık kaynaklar bulunmaktadır. Bu şeffaflık eksikliği, projenin merkeziyetsizlik taahhüdünden kaynaklanabilir—birçok web3 projesinin paylaştığı bir etik anlayışı, bireysel tanınmanın yerine kolektif katkıları önceliklendirmektedir. Topluluk ve onun kolektif hedefleri etrafında tartışmaları merkezileştirerek, SPERO,$$s$$, belirli bireyleri öne çıkarmadan güçlendirme özünü taşımaktadır. Bu nedenle, SPERO'nun etik anlayışını ve misyonunu anlamak, tek bir yaratıcının kimliğini belirlemekten daha önemlidir. SPERO,$$s$$'nin Yatırımcıları Kimlerdir? SPERO,$$s$$, kripto sektöründe yeniliği teşvik etmeye adanmış girişim sermayedarlarından melek yatırımcılara kadar çeşitli yatırımcılar tarafından desteklenmektedir. Bu yatırımcıların odak noktası genellikle SPERO'nun misyonuyla uyumlu olup, toplumsal teknolojik ilerlemeyi, finansal kapsayıcılığı ve merkeziyetsiz yönetimi vaat eden projeleri önceliklendirmektedir. Bu yatırımcı temelleri, yalnızca yenilikçi ürünler sunan projelere değil, aynı zamanda blok zinciri topluluğuna ve ekosistemlerine olumlu katkılarda bulunan projelere de ilgi duymaktadır. Bu yatırımcıların desteği, SPERO,$$s$$'yi hızla gelişen kripto projeleri alanında dikkate değer bir rakip haline getirmektedir. SPERO,$$s$$ Nasıl Çalışır? SPERO,$$s$$, onu geleneksel kripto para projelerinden ayıran çok yönlü bir çerçeve kullanmaktadır. İşte benzersizliğini ve yeniliğini vurgulayan bazı temel özellikler: Merkeziyetsiz Yönetim: SPERO,$$s$$, kullanıcıların projenin geleceğiyle ilgili karar alma süreçlerine aktif olarak katılmalarını sağlayan merkeziyetsiz yönetim modellerini entegre etmektedir. Bu yaklaşım, topluluk üyeleri arasında sahiplik ve hesap verebilirlik duygusunu teşvik etmektedir. Token Kullanımı: SPERO,$$s$$, ekosistem içinde çeşitli işlevler sunmak üzere tasarlanmış kendi kripto para token'ını kullanmaktadır. Bu token'lar, işlemleri, ödülleri ve platformda sunulan hizmetlerin kolaylaştırılmasını sağlayarak genel etkileşimi ve faydayı artırmaktadır. Katmanlı Mimari: SPERO,$$s$$'nin teknik mimarisi, modülerlik ve ölçeklenebilirliği destekleyerek projenin evrimi sırasında ek özelliklerin ve uygulamaların sorunsuz bir şekilde entegrasyonuna olanak tanımaktadır. Bu uyum sağlama yeteneği, sürekli değişen kripto manzarasında geçerliliği sürdürmek için hayati öneme sahiptir. Topluluk Katılımı: Proje, işbirliği ve geri bildirim teşvik eden mekanizmalar kullanarak topluluk odaklı girişimlere vurgu yapmaktadır. Güçlü bir topluluk oluşturarak, SPERO,$$s$$, kullanıcı ihtiyaçlarını daha iyi karşılayabilir ve piyasa trendlerine uyum sağlayabilir. Kapsayıcılığa Odaklanma: Düşük işlem ücretleri ve kullanıcı dostu arayüzler sunarak, SPERO,$$s$$, daha önce kripto alanında yer almamış bireyler de dahil olmak üzere çeşitli bir kullanıcı tabanını çekmeyi hedeflemektedir. Bu kapsayıcılık taahhüdü, erişilebilirlik yoluyla güçlendirme misyonuyla uyumludur. SPERO,$$s$$ Zaman Çizelgesi Bir projenin tarihini anlamak, gelişim yolculuğu ve kilometre taşları hakkında kritik bilgiler sağlar. Aşağıda, SPERO,$$s$$'nin evriminde önemli olayları haritalayan önerilen bir zaman çizelgesi bulunmaktadır: Kavram Geliştirme ve Fikir Aşaması: SPERO,$$s$$'nin temelini oluşturan ilk fikirler, blok zinciri endüstrisindeki merkeziyetsizlik ve topluluk odaklılık ilkeleriyle yakından uyumlu olarak geliştirildi. Proje Beyaz Kağıdının Yayınlanması: Kavramsal aşamayı takiben, SPERO,$$s$$'nin vizyonunu, hedeflerini ve teknolojik altyapısını ayrıntılı bir şekilde açıklayan kapsamlı bir beyaz kağıt yayımlandı ve topluluk ilgisini ve geri bildirimini toplamak amacıyla sunuldu. Topluluk Oluşturma ve Erken Katılımlar: Projenin hedefleri etrafında tartışmalar yürüterek destek toplamak ve erken benimseyenler ile potansiyel yatırımcılar için bir topluluk oluşturmak amacıyla aktif iletişim çabaları gerçekleştirildi. Token Üretim Etkinliği: SPERO,$$s$$, yerel token'larını erken destekçilere dağıtmak ve ekosistem içinde başlangıç likiditesini sağlamak amacıyla bir token üretim etkinliği (TGE) gerçekleştirdi. İlk dApp'in Yayınlanması: SPERO,$$s$$ ile ilişkili ilk merkeziyetsiz uygulama (dApp) faaliyete geçti ve kullanıcıların platformun temel işlevleriyle etkileşimde bulunmalarını sağladı. Sürekli Gelişim ve Ortaklıklar: Projenin tekliflerine sürekli güncellemeler ve iyileştirmeler yapılmakta olup, blok zinciri alanındaki diğer oyuncularla stratejik ortaklıklar, SPERO,$$s$$'yi rekabetçi ve gelişen bir oyuncu haline getirmiştir. Sonuç SPERO,$$s$$, web3 ve kripto paranın finansal sistemleri devrim niteliğinde dönüştürme ve bireyleri güçlendirme potansiyelinin bir kanıtıdır. Merkeziyetsiz yönetime, topluluk katılımına ve yenilikçi tasarlanmış işlevselliğe olan bağlılığıyla, daha kapsayıcı bir finansal manzaraya doğru bir yol açmaktadır. Hızla gelişen kripto alanındaki herhangi bir yatırımda olduğu gibi, potansiyel yatırımcılar ve kullanıcılar, SPERO,$$s$$ içindeki devam eden gelişmelerle ilgili olarak kapsamlı bir araştırma yapmaları ve düşünceli bir şekilde katılmaları teşvik edilmektedir. Proje, kripto endüstrisinin yenilikçi ruhunu sergileyerek, sayısız olasılığını keşfetmeye davet etmektedir. SPERO,$$s$$'nin yolculuğu hala devam ederken, temel ilkeleri, teknoloji, finans ve birbirimizle etkileşim biçimimizi etkileyebilir.
315 Toplam GörüntülenmeYayınlanma 2024.12.17Güncellenme 2024.12.17

AGENT S Nedir
Agent S: Web3'te Otonom Etkileşimin Geleceği Giriş Web3 ve kripto para dünyasında sürekli gelişen manzarada, yenilikler bireylerin dijital platformlarla etkileşim biçimlerini sürekli olarak yeniden tanımlıyor. Bu tür öncü projelerden biri olan Agent S, açık ajans çerçevesi aracılığıyla insan-bilgisayar etkileşimini devrim niteliğinde değiştirmeyi vaat ediyor. Otonom etkileşimlerin yolunu açarak, Agent S karmaşık görevleri basitleştirmeyi ve yapay zeka (AI) alanında dönüştürücü uygulamalar sunmayı hedefliyor. Bu detaylı inceleme, projenin karmaşıklıklarına, benzersiz özelliklerine ve kripto para alanındaki etkilerine dalacaktır. Agent S Nedir? Agent S, bilgisayar görevlerinin otomasyonunda üç temel zorluğu ele almak üzere özel olarak tasarlanmış çığır açıcı bir açık ajans çerçevesidir: Alan Spesifik Bilgi Edinimi: Çerçeve, çeşitli dış bilgi kaynaklarından ve iç deneyimlerden akıllıca öğrenir. Bu çift yönlü yaklaşım, alan spesifik bilgi açısından zengin bir veri havuzu oluşturmasını sağlar ve görev yürütmedeki performansını artırır. Uzun Görev Ufukları Üzerinde Planlama: Agent S, karmaşık görevlerin verimli bir şekilde parçalanmasını ve yürütülmesini kolaylaştıran deneyim artırımlı hiyerarşik planlama kullanır. Bu özellik, çoklu alt görevleri etkili ve verimli bir şekilde yönetme yeteneğini önemli ölçüde artırır. Dinamik, Homojen Olmayan Arayüzlerle Başlama: Proje, ajanlar ve kullanıcılar arasındaki etkileşimi geliştiren yenilikçi bir çözüm olan Ajan-Bilgisayar Arayüzü'ni (ACI) tanıtmaktadır. Çok Modlu Büyük Dil Modellerini (MLLM'ler) kullanarak, Agent S çeşitli grafik kullanıcı arayüzlerini sorunsuz bir şekilde gezinebilir ve manipüle edebilir. Bu öncü özellikler aracılığıyla, Agent S, makinelerle insan etkileşimini otomatikleştirmede karşılaşılan karmaşıklıkları ele alan sağlam bir çerçeve sunarak, AI ve ötesinde birçok uygulama için zemin hazırlıyor. Agent S'nin Yaratıcısı Kimdir? Agent S'nin kavramı temelde yenilikçi olsa da, yaratıcısı hakkında spesifik bilgiler belirsizliğini koruyor. Yaratıcı şu anda bilinmiyor, bu da projenin yeni aşamasını veya kurucu üyeleri gizli tutma stratejik tercihini vurguluyor. Anonimlikten bağımsız olarak, odak çerçevenin yetenekleri ve potansiyeli üzerinde kalıyor. Agent S'nin Yatırımcıları Kimlerdir? Agent S, kriptografik ekosistemde oldukça yeni olduğundan, yatırımcıları ve finansal destekçileri hakkında ayrıntılı bilgiler açıkça belgelenmemiştir. Projeyi destekleyen yatırım temelleri veya organizasyonları hakkında kamuya açık bilgilerdeki eksiklik, finansman yapısı ve gelişim yol haritası hakkında sorular doğuruyor. Destekleyicilerin anlaşılması, projenin sürdürülebilirliğini ve potansiyel pazar etkisini değerlendirmek için kritik öneme sahiptir. Agent S Nasıl Çalışır? Agent S'nin temelinde, çeşitli ortamlarda etkili bir şekilde çalışmasını sağlayan son teknoloji bir sistem yatmaktadır. İşleyiş modeli birkaç ana özellik etrafında inşa edilmiştir: İnsan Benzeri Bilgisayar Etkileşimi: Çerçeve, bilgisayarlarla etkileşimleri daha sezgisel hale getirmeyi amaçlayan gelişmiş AI planlaması sunar. Görev yürütmedeki insan davranışını taklit ederek, kullanıcı deneyimlerini yükseltmeyi vaat eder. Anlatı Belleği: Yüksek düzeyde deneyimlerden yararlanmak için kullanılan Agent S, görev geçmişlerini takip etmek amacıyla anlatı belleğini kullanarak karar verme süreçlerini geliştirir. Episodik Bellek: Bu özellik, kullanıcılara adım adım rehberlik sağlayarak, çerçevenin görevler gelişirken bağlamsal destek sunmasına olanak tanır. OpenACI Desteği: Yerel olarak çalışabilme yeteneği ile Agent S, kullanıcıların etkileşimleri ve iş akışları üzerinde kontrol sağlamasına olanak tanır ve Web3'ün merkeziyetsiz felsefesiyle uyumlu hale gelir. Dış API'lerle Kolay Entegrasyon: Çeşitli AI platformlarıyla uyumluluğu ve çok yönlülüğü, Agent S'nin mevcut teknolojik ekosistemlere sorunsuz bir şekilde entegre olmasını sağlar ve geliştiriciler ile organizasyonlar için cazip bir seçenek haline getirir. Bu işlevsellikler, Agent S'nin kripto alanındaki benzersiz konumuna katkıda bulunarak, karmaşık, çok aşamalı görevleri minimum insan müdahalesi ile otomatikleştirir. Proje geliştikçe, Web3'teki potansiyel uygulamaları dijital etkileşimlerin nasıl gelişeceğini yeniden tanımlayabilir. Agent S'nin Zaman Çizelgesi Agent S'nin gelişimi ve kilometre taşları, önemli olaylarını vurgulayan bir zaman çizelgesinde özetlenebilir: 27 Eylül 2024: Agent S'nin kavramı, “Bilgisayarları İnsan Gibi Kullanan Açık Bir Ajans Çerçevesi” başlıklı kapsamlı bir araştırma makalesi ile tanıtıldı ve projenin temelini sergiledi. 10 Ekim 2024: Araştırma makalesi arXiv'de kamuya açık olarak yayınlandı ve çerçevenin derinlemesine bir incelemesini ve OSWorld benchmark'ına dayalı performans değerlendirmesini sundu. 12 Ekim 2024: Agent S'nin yetenekleri ve özellikleri hakkında görsel bir içgörü sağlayan bir video sunumu yayımlandı ve potansiyel kullanıcılar ve yatırımcılarla daha fazla etkileşim sağlandı. Bu zaman çizelgesindeki işaretler, sadece Agent S'nin ilerlemesini değil, aynı zamanda şeffaflık ve topluluk katılımına olan bağlılığını da göstermektedir. Agent S Hakkında Ana Noktalar Agent S çerçevesi gelişmeye devam ederken, birkaç ana özellik öne çıkmakta ve yenilikçi doğasını ve potansiyelini vurgulamaktadır: Yenilikçi Çerçeve: İnsan etkileşimine benzer bir bilgisayar kullanımı sağlamak üzere tasarlanan Agent S, görev otomasyonuna yeni bir yaklaşım getiriyor. Otonom Etkileşim: GUI aracılığıyla bilgisayarlarla otonom olarak etkileşim kurabilme yeteneği, daha akıllı ve verimli hesaplama çözümlerine doğru bir sıçrama anlamına geliyor. Karmaşık Görev Otomasyonu: Sağlam metodolojisi ile karmaşık, çok aşamalı görevleri otomatikleştirerek süreçleri daha hızlı ve daha az hata payı ile gerçekleştirebilir. Sürekli İyileştirme: Öğrenme mekanizmaları, Agent S'nin geçmiş deneyimlerden öğrenmesini sağlar ve sürekli olarak performansını ve etkinliğini artırır. Çok Yönlülük: OSWorld ve WindowsAgentArena gibi farklı işletim ortamlarında uyumlu olması, geniş bir uygulama yelpazesine hizmet edebilmesini sağlar. Agent S, Web3 ve kripto alanında kendini konumlandırırken, etkileşim yeteneklerini artırma ve süreçleri otomatikleştirme potansiyeli, AI teknolojilerinde önemli bir ilerlemeyi temsil etmektedir. Yenilikçi çerçevesi aracılığıyla, Agent S dijital etkileşimlerin geleceğini örneklemekte ve çeşitli sektörlerde kullanıcılar için daha sorunsuz ve verimli bir deneyim vaat etmektedir. Sonuç Agent S, AI ve Web3'ün birleşiminde cesur bir sıçramayı temsil ediyor ve teknoloji ile etkileşim biçimimizi yeniden tanımlama kapasitesine sahip. Henüz erken aşamalarında olmasına rağmen, uygulama olanakları geniş ve çekici. Kritik zorlukları ele alan kapsamlı çerçevesi ile Agent S, otonom etkileşimleri dijital deneyimin ön plana çıkmasına taşımayı hedefliyor. Kripto para ve merkeziyetsizlik alanlarına daha derinlemesine girdikçe, Agent S gibi projelerin teknoloji ve insan-bilgisayar işbirliğinin geleceğini şekillendirmede önemli bir rol oynayacağı kesin.
762 Toplam GörüntülenmeYayınlanma 2025.01.14Güncellenme 2025.01.14
S Nasıl Satın Alınır
HTX.com’a hoş geldiniz! Sonic (S) satın alma işlemlerini basit ve kullanışlı bir hâle getirdik. Adım adım açıkladığımız rehberimizi takip ederek kripto yolculuğunuza başlayın. 1. Adım: HTX Hesabınızı OluşturunHTX'te ücretsiz bir hesap açmak için e-posta adresinizi veya telefon numaranızı kullanın. Sorunsuzca kaydolun ve tüm özelliklerin kilidini açın. Hesabımı Aç2. Adım: Kripto Satın Al Bölümüne Gidin ve Ödeme Yönteminizi SeçinKredi/Banka Kartı: Visa veya Mastercard'ınızı kullanarak anında Sonic (S) satın alın.Bakiye: Sorunsuz bir şekilde işlem yapmak için HTX hesap bakiyenizdeki fonları kullanın.Üçüncü Taraflar: Kullanımı kolaylaştırmak için Google Pay ve Apple Pay gibi popüler ödeme yöntemlerini ekledik.P2P: HTX'teki diğer kullanıcılarla doğrudan işlem yapın.Borsa Dışı (OTC): Yatırımcılar için kişiye özel hizmetler ve rekabetçi döviz kurları sunuyoruz.3. Adım: Sonic (S) Varlıklarınızı SaklayınSonic (S) satın aldıktan sonra HTX hesabınızda saklayın. Alternatif olarak, blok zinciri transferi yoluyla başka bir yere gönderebilir veya diğer kripto para birimlerini takas etmek için kullanabilirsiniz.4. Adım: Sonic (S) Varlıklarınızla İşlem YapınHTX'in spot piyasasında Sonic (S) ile kolayca işlemler yapın.Hesabınıza erişin, işlem çiftinizi seçin, işlemlerinizi gerçekleştirin ve gerçek zamanlı olarak izleyin. Hem yeni başlayanlar hem de deneyimli yatırımcılar için kullanıcı dostu bir deneyim sunuyoruz.
2.0k Toplam GörüntülenmeYayınlanma 2025.01.15Güncellenme 2026.06.02

