"Deep Think has defeated/matched competitors in all competitions"!
Just now, Google DeepMind senior researcher Conglong Li posted 12 messages on the X platform, revealing an unprecedented scorecard.

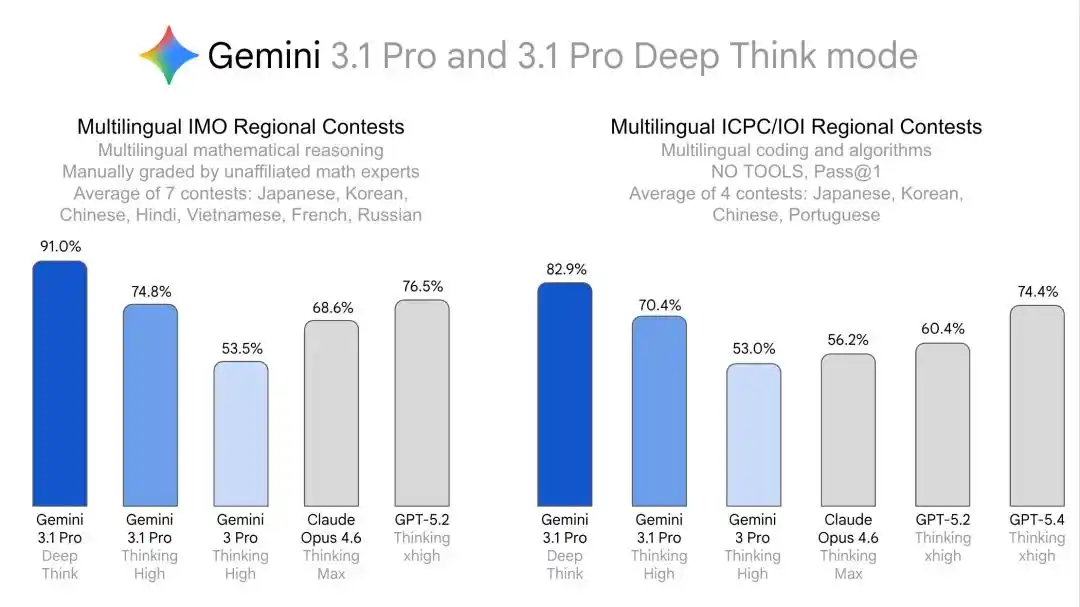
One AI, the same brain, eight exam papers in different languages, all submitted with high scores.
Such results are rare for any model.
From IMO Gold Medals to Full Coverage of Regional Competitions
Deep Think's high scores across multiple leaderboards are not a sudden breakthrough but part of a nearly year-long evolution of capabilities.
First, it topped the most rigorous reasoning competitions.
In July 2025, Gemini Deep Think achieved the gold medal standard at the International Mathematical Olympiad (IMO) for the first time, scoring 35 out of 42 points. It also achieved similarly high-level performance at the ICPC World Finals around the same time.
These two achievements have been officially announced in the DeepMind blog.
Google DeepMind subsequently included these two results in its official blog, marking Deep Think's crossing of the "world-class competition threshold" in mathematics and programming.
Next, Deep Think began moving from "world-champion-level individual breakthroughs" to "systematic validation across languages, disciplines, and scenarios."
In February 2026, Google published three blog posts.
One introduced the Gemini 3.1 Pro model itself, one detailed a major upgrade to the Deep Think specialized reasoning mode, and one from the DeepMind scientific discovery team directly positioned Deep Think as a "human intelligence multiplier."
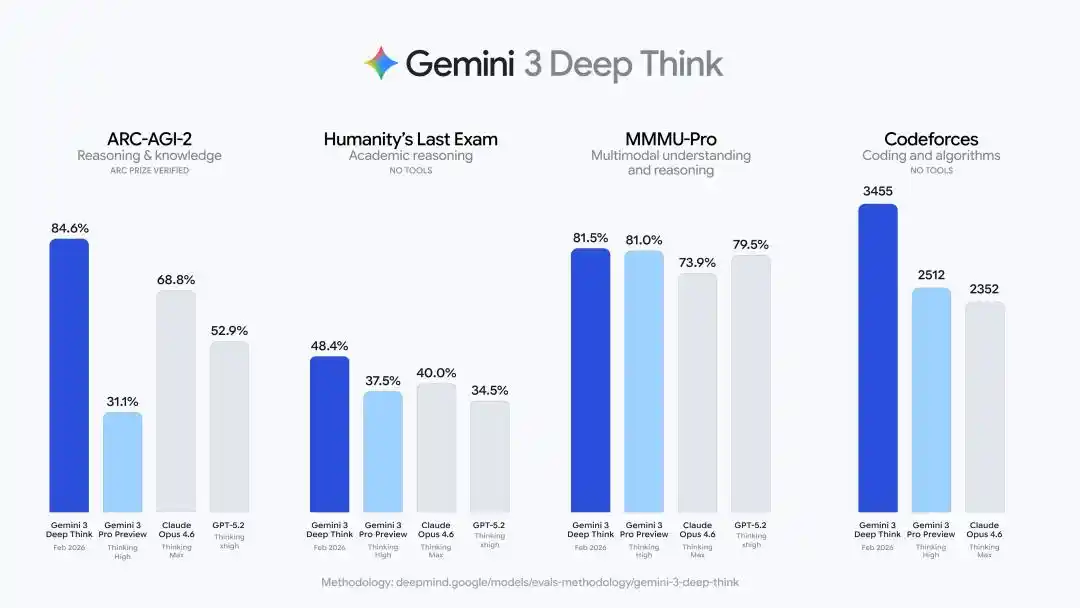
The upgraded Deep Think delivered a series of hard metrics:
48.4% on Humanity's Last Exam (without tool assistance), 84.6% on ARC-AGI-2 (officially verified by the ARC Prize Foundation), a Codeforces competitive programming Elo rating of 3455, and gold medal-level performance on the written portions of the 2025 International Physics and Chemistry Olympiads.
The strategy is very clear: first use world-class competitions like the IMO and ICPC to prove its powerful reasoning abilities, then use multi-language, regional competition, and cross-disciplinary Olympiad results to prove its general, deep reasoning ability that stably transfers across languages and domains.
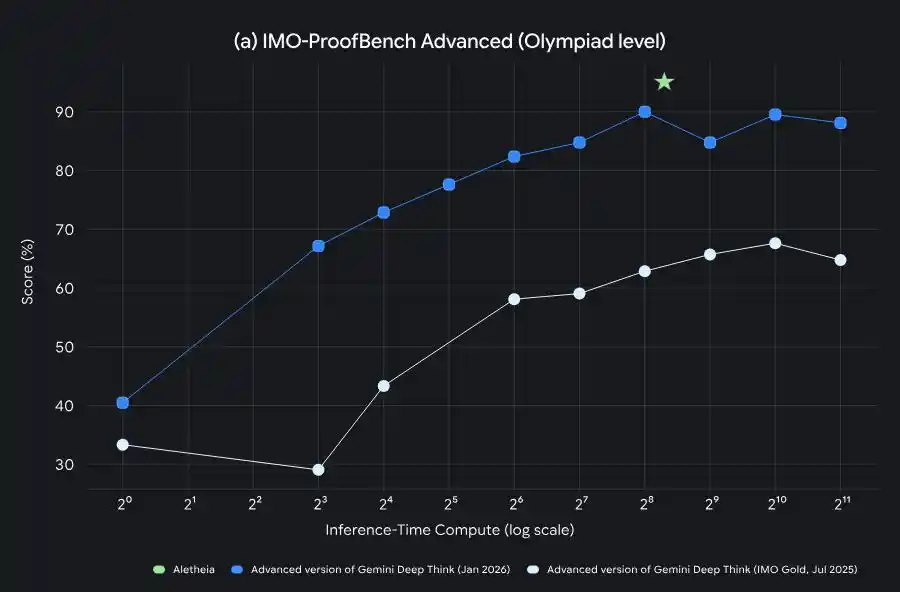
Gemini Deep Think's capability evolution from IMO gold medals to PhD-level research acceleration
A Detailed Look at the 8-Language Scorecard
Now, let's take a closer look at this scorecard.
Japanese results are the most impressive.
2025 35th Japanese Mathematical Olympiad Finals (JMO Finals), perfect score.
ICPC Asia Japan Preliminary Contest, perfect score.
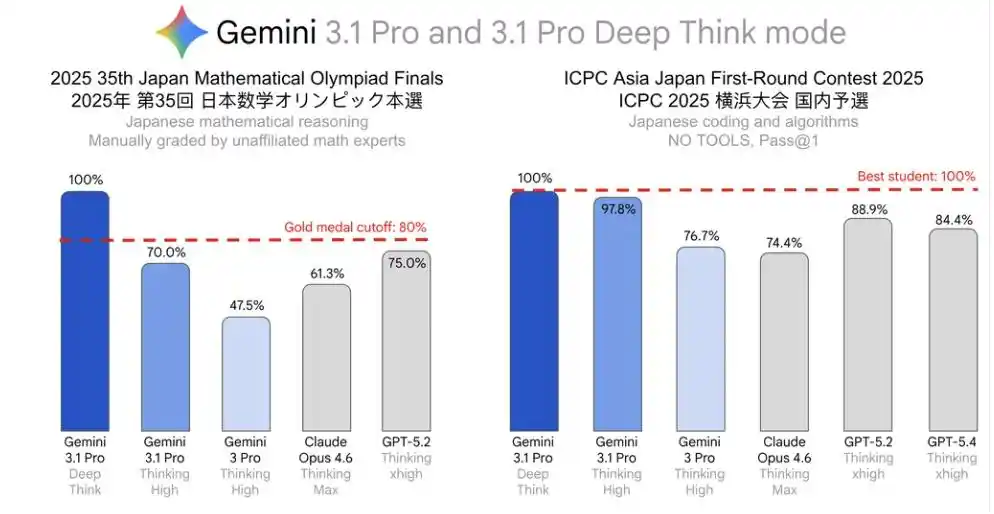
Among these, the JMO Finals score even exceeded the level corresponding to the top 80% of scores that year, meeting the official "gold medal equivalent" standard.
French results were also a perfect 100%.
The Chinese results are interesting.
At the 41st Chinese Mathematical Olympiad (CMO), Deep Think scored 86.3%, which is quite outstanding. But at the Chinese National Olympiad in Informatics (NOI), it only scored 63.3%.
The gap between 86.3% and 63.3% outlines the real boundaries of AI reasoning ability.
In math competitions, the model faces abstract deduction, proof construction, and multi-step reasoning, which happens to be Deep Think's strongest suit.
But in informatics competitions, the problem is not just "figuring it out," but also translating logic into executable code, controlling boundary conditions, considering complexity constraints, and avoiding implementation errors.
The former is closer to pure reasoning, while the latter requires "reasoning + algorithm design + engineering implementation" to be successful simultaneously.
In the other languages—Korean, Hindi, Vietnamese, Russian, Portuguese—Deep Think also achieved results that either defeated competitors or at least matched them.
Looking at Japanese, French, and Chinese together, the most unusual aspect this time is not necessarily scoring a perfect mark in any single subject, but rather that the same model, the same Deep Think reasoning system, delivered first-tier results on exam papers in multiple languages.
Is This Scorecard Reliable?
But there is a key omission:
Conglong Li did not list specific comparative data from competitors: all results come from Google evaluations. There is no independent third-party replication, no official certification from the competitions, and the evaluation methodology is completely undisclosed.
Was each problem attempted once or many times with the best score taken? How much computational power was used during reasoning? Was there any manual prompt engineering involved?
These details, which directly affect the credibility of the results, were also not mentioned.
Another easily overlooked point: these exams are all regional selection competitions, not international finals.
There is an order of magnitude difference in difficulty between regional competition problems and international finals.
The researcher explicitly stated that these results "will be included in the model card." As of publication, the model card has not been officially updated.
So, for now, this still seems like a scorecard graded by the examinee themselves, announced by themselves, and not yet stamped by the academic affairs office.
Multilingual Research Equity: The Overlooked Real Battlefield
Why did Google specifically invest effort in evaluating 8 different regional languages?
Current evaluations of AI reasoning ability are almost entirely based on English.
MATH, GSM8K, HumanEval, ARC-AGI... these are all in English.
Mathematicians, physicists, and engineers worldwide whose native language is not English must first overcome a language barrier when using AI research tools.
Google's selection of these 8 languages is not random.
Japanese, Korean, and Chinese cover East Asian research powerhouses; Hindi and Vietnamese cover emerging markets; French, Russian, and Portuguese cover Europe and South America.
Together, this represents the majority of global research output.
In its official blog, DeepMind positioned Deep Think as a "human intelligence multiplier," saying it can "handle knowledge retrieval and rigorous verification, allowing scientists to focus on conceptual depth and creative direction."
Combined with these multi-language results, the subtext of this statement is not hard to understand: this multiplier is not just for scientists who use English.
More notably is how far Deep Think has already gone in research落地 (landing/application).
DeepMind announced a mathematical research agent called Aletheia, powered by Deep Think, capable of autonomously generating, verifying, and revising solutions to research-level mathematical problems.
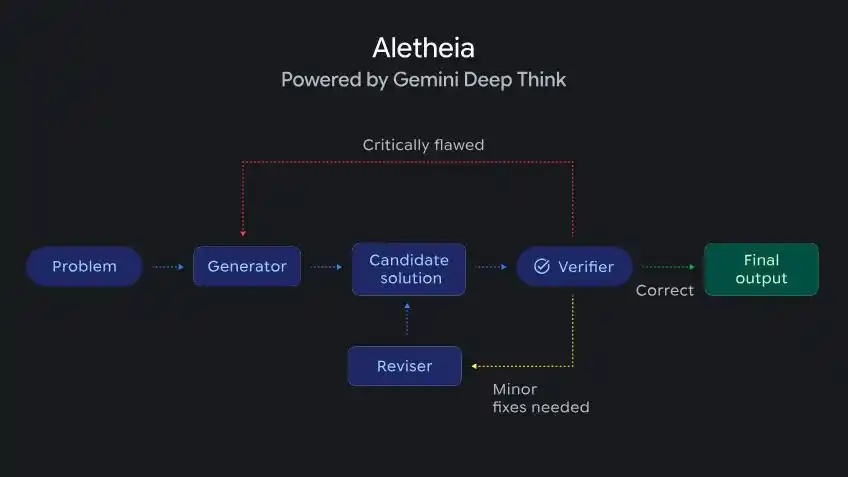
Aletheia, driven by Deep Think, capable of iterative generation, verification, and correction for research-level mathematical problems
Aletheia has already contributed to multiple research papers, one of which was completed entirely autonomously by the AI, calculating specific structural constants in arithmetic geometry.

Furthermore, in a semi-autonomous evaluation of 700 open mathematical problems, it independently solved 4 previously unsolved problems.
The Gemini Deep Think mode also shows great potential in computer science, physics, economics, and other fields.
In computer science, Deep Think helped refute a conjecture that had remained open for a decade; in physics, it found a new analytical solution for gravitational radiation from cosmic strings; in economics, it extended an auction theory theorem.
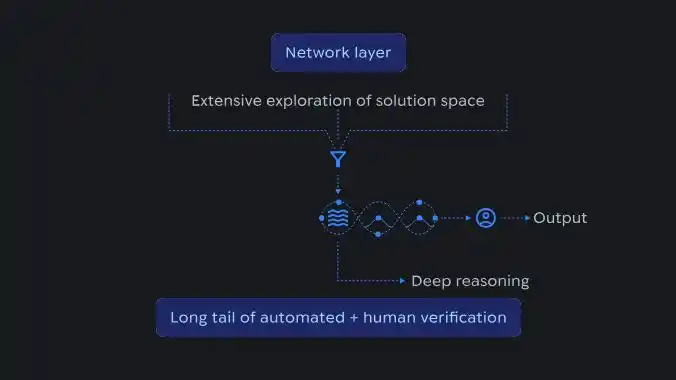
Schematic diagram of the AI reasoning process, showing how large-scale exploration of the solution space at the network layer is aggregated into structured reasoning and confirmed through automated and manual verification.
By collaborating with experts to solve 18 research challenges, the advanced version of Gemini Deep Think helped break through long-standing bottlenecks in algorithms, machine learning and combinatorial optimization, information theory, and economics.
This goes far beyond "solving competition problems."
While competitors are still competing on English benchmark leaderboards, Google has already found a new battlefield in the "AI research accelerator" field.
The most important thing about this is not the scores; the real signal behind it is: the language barrier for AI research tools is being treated as an engineering problem to be solved.
If this path succeeds, scientists conducting research in Japanese, Korean, Chinese, Hindi, and other languages will, for the first time, stand on the same starting line as native English speakers.
This time, Google has laid its cards on the table.
As for which competitors will follow suit, we believe we will see soon.
References:
https://blog.google/intl/ja-jp/company-news/technology/gemini-31-pro-gemini-31-pro-deep-think/%20
https://deepmind.google/blog/accelerating-mathematical-and-scientific-discovery-with-gemini-deep-think/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-deep-think/
This article is from the WeChat public account "新智元" (New Zhiyuan), author: 新智元





